숫자는 맞는데 이상한 이유: 집계의 함정
집계의 함정: 부분은 좋은데 전체는 나쁜 사례
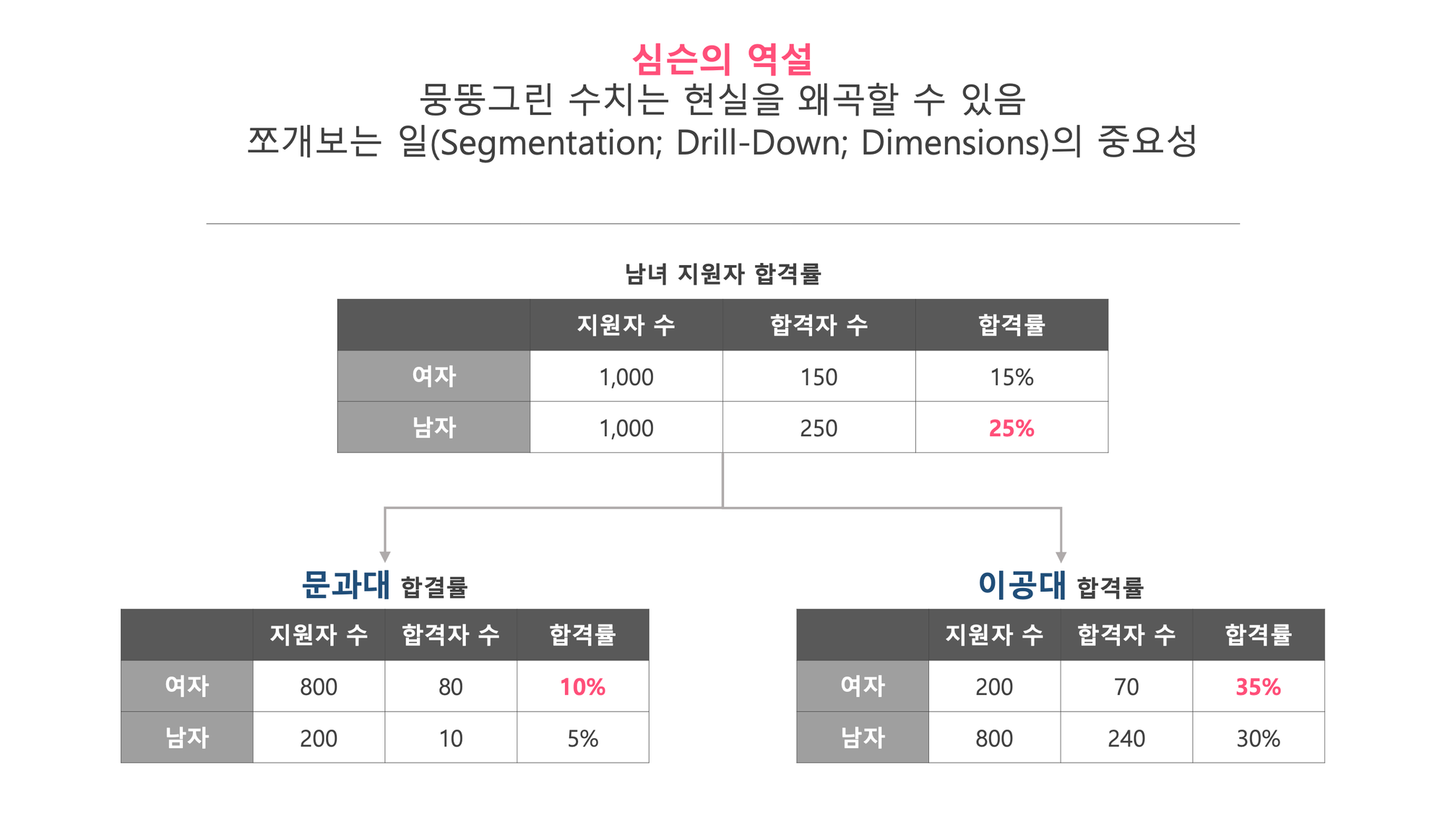
데이터 분석에서 ‘평균’은 가장 흔하고 익숙한 대표값이지만, 때로는 중요한 사실을 감추거나 왜곡할 수 있습니다. 예를 들어, 남녀 지원자 합격률이 각각 25%, 15%라고 가정해봅시다. 대시보드에 표시된 평균만 보면 남성 지원자의 합격율이 높다고 판단할 수 있습니다.
그런데 이걸 계열별로 나눠 보면 상황이 달라집니다. 문과대에서는 여성의 합격률이 10%로 남성(5%)보다 높고, 이공대에서도 여성(35%)이 남성(30%)보다 더 높게 나타납니다. 아래 그림에서 이유를 한번 찾아볼까요? (힌트는, 합격자 수 입니다.)
사례를 하나 더 들어보면, 마케팅 채널별 고객 획득 비용(CAC) 분석에서도 유사한 문제가 발생합니다. 기업 전체의 평균 CAC는 문제가 없어 보이지만, 채널별로 쪼개보면 특정 채널에서는 고객 한 명을 획득하는 비용이 수익보다 훨씬 높아 실제 손해를 보고 있는 상황을 놓칠 수 있겠죠.
심슨의 역설이란?
이처럼, 평균이나 비율과 같은 통계 수치가 하위그룹으로 쪼개졌을 때 역전되는 현상을 심슨의 역설(Simpson's Paradox)이라고 말합니다.
부분만 보면 틀리지 않지만 전체로 합쳤을 때 결론이 뒤바뀌며 대표값이 실제 맥락을 왜곡할 수 있기 때문에, 데이터 기반으로 현상을 정확하게 파악하고 업무적 의사결정의 기준으로 활용하고자 하는 실무자에게는 평균의 함정을 이해하고 다양한 차원으로 데이터를 쪼개어 보는 것이 중요합니다.
이번 글을 통해 단순한 평균을 넘어 데이터가 의미하는 바를 한층 명확하게 파악하는 실무자로 한 걸음 나아갈 수 있기를 바랍니다.
우리는 왜 늘 평균만 봐왔을까?
평균은 쉽고 익숙하다
평균은 계산하기 쉽고 직관적으로 이해하기 편리한 지표입니다. 많은 사람들이 익숙하게 사용하며, 복잡한 설명을 필요로 하지 않기 때문에 데이터 분석 결과를 공유하거나 보고할 때 자주 활용됩니다.
대시보드 역시 복잡한 데이터를 단순화하여 시각적으로 표현함으로써 실무자들이 쉽게 이해하고 활용하도록 돕는데, 이때 평균과 같은 집계된 지표들이 중요한 역할을 합니다. 나아가, 엑셀에서도 선택한 셀의 평균값을 자동으로 제공하며, 많은 데이터를 가장 쉽게 이해하는 방식으로 자리잡았습니다.
평균은 틀리진 않았지만, 왜곡될 수 있다
극단값이 평균을 흔드는 메커니즘
평균의 가장 큰 문제점 중 하나는 극단값(outlier)에 매우 민감하다는 것입니다. 예를 들어, 한 버스에 타고 있는 사람들의 평균 소득이 빌 게이츠 한 명이 타는 순간 급격히 변하는 것처럼, 극단적인 값이 샘플에 포함될 경우 평균은 전체 데이터의 대표성을 잃게 됩니다.
왜 분포를 함께 봐야 하는가?
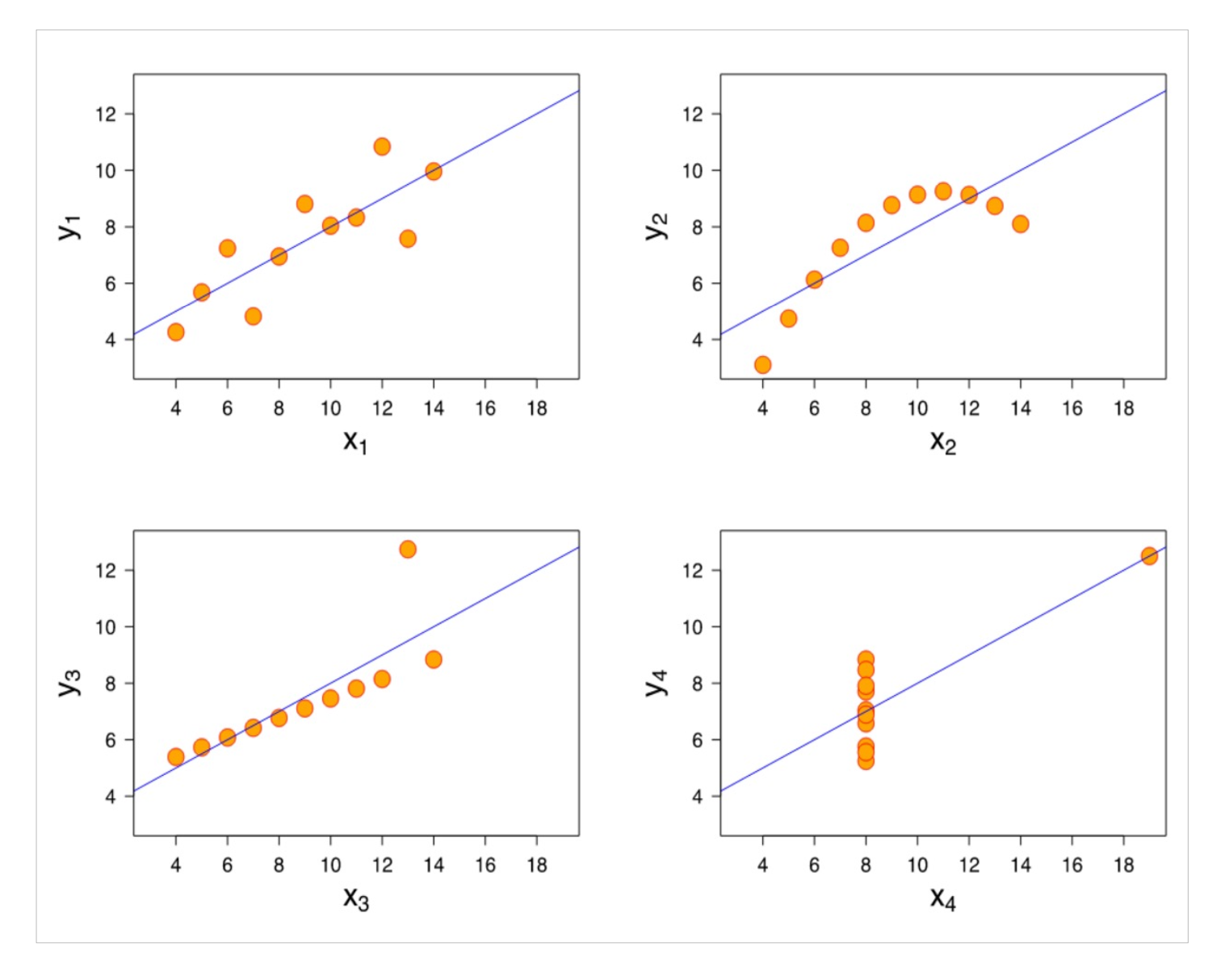
"평균만 보지 말고 분포를 봐라"는 데이터 분석가들 사이에서 격언처럼 통합니다. 이는 뭉뚱그려진 평균값만으로는 개별 데이터들이 어떤 위치에 있는지, 즉 데이터의 퍼진 정도나 모양을 알 수 없기 때문입니다. 통계학의 유명한 예시인 '앤스컴의 콰르텟(Anscombe's Quartet)'처럼 동일한 평균과 분산, 상관관계를 가진 네 가지 데이터셋도 시각화했을 때 서로 다른 양상을 보일 수 있듯이, 분포를 함께 보는 것은 데이터의 진정한 특성을 파악하는 데 필수적입니다.
그럴 땐 중앙값이 말해준다
중앙값은 어떤 값을 대표하는가?
주어진 자료를 크기 순으로 나열했을 때 정중앙에 위치하는 값을 중앙값(Median)이라고 합니다. 중앙값은 평균과 달리 극단값의 영향을 적게 받습니다.
중앙값이 평균보다 더 유용한 상황
평균이 극단값에 의해 쉽게 왜곡되는 상황에서 중앙값은 데이터의 중심을 더 정확하게 대표할 수 있습니다. 특히 소득 분포나 부동산 가격처럼 소수의 극단적인 값이 존재하는 경우, 평균보다는 중앙값이 해당 데이터셋의 '일반적인' 경향을 더 잘 보여줄 수 있습니다.
평균 vs 중앙값, 언제 어떤 걸 봐야 할까?
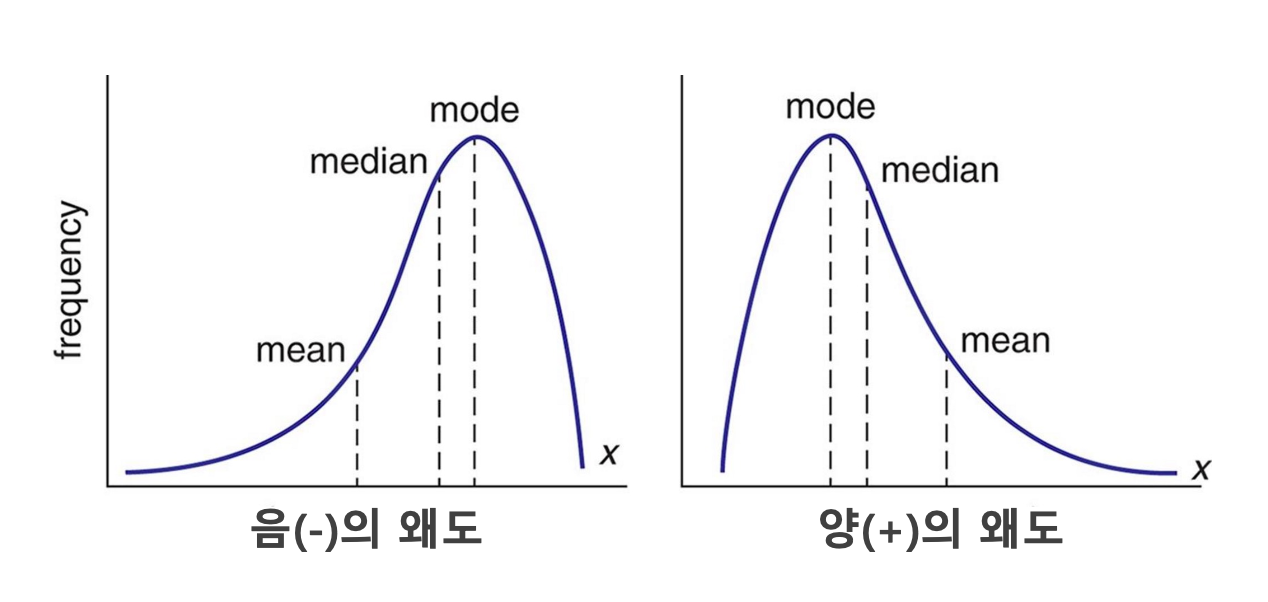
정규분포 vs 왜도 있는 분포
데이터의 분포가 좌우 대칭인 정규분포에 가까울 때는 평균과 중앙값이 유사하므로 평균을 사용해도 무방합니다. 그러나 소득처럼 특정 방향으로 꼬리가 길게 늘어진 왜도(skewness) 있는 분포의 경우, 극단값이 평균을 한쪽으로 치우치게 만들므로 중앙값이 더 적절한 대표값이 됩니다.
대표값 선택 기준
- 평균: 데이터가 정규분포에 가깝거나, 극단값의 영향을 크게 받지 않는 경우. 모든 데이터 값의 정보를 활용할 때.
- 중앙값: 데이터에 극단값이 존재하거나, 분포가 한쪽으로 치우쳐져 있을 때. 데이터의 '중간' 지점을 파악하는 것이 중요할 때.
꼭 중앙값만 봐야 할까?
최빈값의 개념과 활용 예시
최빈값(Mode)은 데이터셋에서 가장 자주 등장하는 값을 의미합니다. 예를 들어, 설문조사에서 가장 많이 선택된 응답이나, 의류 판매에서 가장 많이 팔린 사이즈 등을 나타낼 때 유용합니다. 최빈값은 주로 범주형 데이터나 특정 값이 집중되어 나타나는 경우에 활용됩니다.
세 가지 대표값을 함께 보는 전략
평균, 중앙값, 최빈값을 함께 고려하는 것이 데이터의 특성을 포괄적으로 이해하는 데 도움이 됩니다. 하나의 대표값만으로는 데이터의 전체적인 모습을 파악하기 어렵기 때문에, 세 가지 값을 모두 살펴보면서 데이터가 어떻게 분포되어 있는지, 극단값의 영향은 없는지 등을 파악하여 보다 정확한 인사이트를 도출할 수 있습니다.
예를 들어, 상품별 반품률 데이터를 보면, 평균은 15%지만 중앙값은 8%, 최빈값은 5%일 수 있습니다. 이럴 경우 평균만 보면 “우린 반품이 심각하다”고 판단할 수 있지만 실제 절반 이상의 상품은 반품률이 10% 미만이고, 가장 흔한 반품률은 5%이므로 문제는 일부 특정 상품이나 케이스에 집중돼 있다는 걸 알 수 있습니다.
이렇게 세 가지 대표값을 함께 보면 ‘어디가 문제인지’까지 감이 잡힙니다.
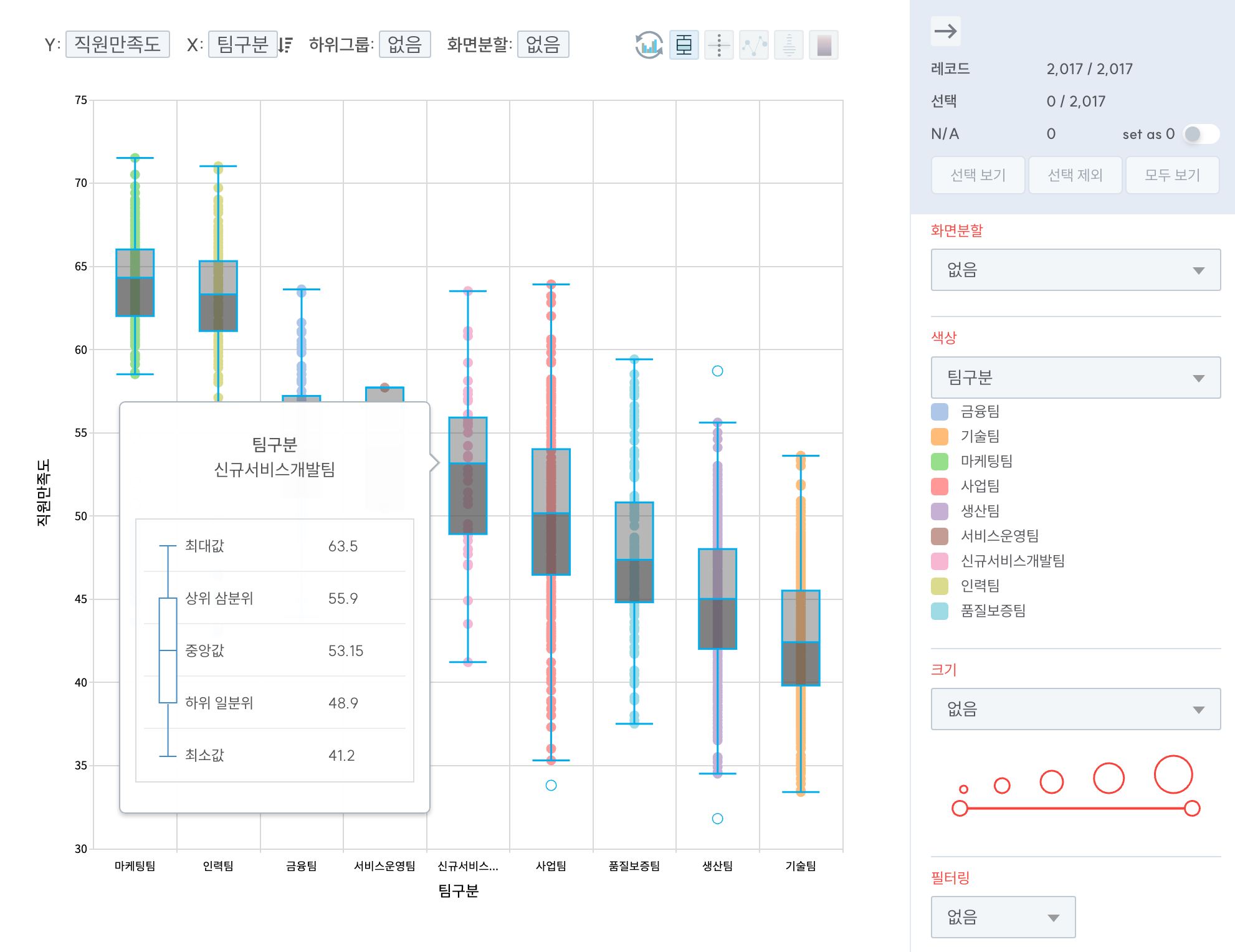
박스플롯: 숫자를 시각적으로 한눈에 보기
박스플롯의 구성 요소 설명
박스플롯(Box Plot)은 데이터의 분포를 시각적으로 한눈에 보여주는 강력한 도구입니다. 박스플롯은 다음 요소들로 구성됩니다:
- 중앙선: 중앙값을 나타냅니다.
- 상자(Box): 중앙 50%의 데이터를 포함하며, 1사분위수(Q1)와 3사분위수(Q3)를 나타냅니다.
- 수염(Whiskers): 상자 밖의 데이터 범위를 나타내며, 이상치(outlier)를 제외한 데이터의 최대/최소값을 보여줍니다.
이상치(Outliers): 수염 밖에 점으로 표시되며, 통상적인 분포에서 벗어나는 극단적인 값들을 의미합니다.
박스플롯으로 볼 수 있는 인사이트
박스플롯을 통해 데이터의 중심 경향, 퍼진 정도(분포), 대칭성, 그리고 이상치 존재 여부를 쉽게 파악할 수 있는데요. 여러 집단의 박스플롯을 나란히 놓고 비교하면, 각 집단 간의 상대적인 차이와 분포의 특성을 직관적으로 이해할 수 있습니다.
예를 들어, 광고 채널별 ROAS를 박스플롯으로 그려보면, 평균은 비슷하지만 어떤 채널은 수익이 안정적이고 일관된 반면, 다른 채널은 극단적으로 높은 ROAS 며칠이 전체 평균을 끌어올리고 있을 뿐, 대부분은 손해 보는 구조라는 걸 시각적으로 바로 알 수 있습니다. 숫자로는 안 보이던 위험 요소들이 박스플롯에선 드러납니다.
실무에서 바로 써먹는 대표값 해석 팁
엑셀에서 평균·중앙값·최빈값 구하기
엑셀의 기본적인 함수를 통해 평균, 중앙값, 최빈값을 쉽게 구할 수 있습니다.
평균
=AVERAGE(range)
중앙값
=MEDIAN(range)
최빈값
=MODE.SNGL(range)
엑셀 피벗 테이블과 같은 기능을 활용하여 데이터를 요약하고 집계하는 것도 일반적인 방법입니다.
데이터 수가 적을 때 중앙값 해석 주의점
중앙값은 데이터의 크기 순 정렬을 기반으로 하므로 '없을' 수는 없습니다. 다만, 데이터 수가 매우 적을 경우에는 중앙값 하나만으로 전체를 판단하기에는 어려움이 있을 수 있습니다.
예를 들어, 단 3개의 데이터만 있다면 중앙값이 전체 경향을 대표한다고 보기 어려울 수 있습니다. 이럴 때는 다른 대표값이나 전체적인 맥락, 또는 더 많은 데이터를 확보하여 분석하는 것이 중요합니다.
대표값은 숫자가 아니라 관점이다
데이터 해석은 사람의 사고에서 출발한다
데이터는 문제 해결의 도구이며, 데이터 해석은 결국 사람의 사고에서 출발합니다. 데이터는 현상의 '무엇(What)'을 보여줄 수는 있지만, '왜(Why)'라는 원인을 항상 직접적으로 담고 있지는 않습니다. 따라서 실무자는 날카로운 질문을 던지고, 문제를 구조화하며, 가설을 세워 검증하는 과정을 통해 데이터에 숨겨진 '유용한 새로운 사실'을 발견해야 합니다.
평균을 넘어서기 위한 실무자의 시선
단순히 숫자를 나열하거나 요약하는 것을 넘어, 데이터의 분포를 깊이 이해하고 다양한 대표값을 활용하는 것은 실무자의 분석적 사고력을 한 단계 높이는 길입니다. 이는 데이터를 통해 조직의 의사결정을 개선하고 비즈니스 성장에 기여하는 핵심 역량이 될 것입니다.
함께 보면 좋은 글
 Sidney Yang
Sidney Yang HEARTCOUNT
HEARTCOUNT HEARTCOUNT
HEARTCOUNT
![[HEARTCOUNT팀 시리즈(2)]혁신의 최전선에서, HEARTCOUNT Front-end Dev 팀을 만나다!](/ko/content/images/size/w360/2025/06/----1-1.png)