
들어가는 말
다 읽기는 귀찮은 글을 요약하거나, 빈약한 글을 더 길게 늘리는 용도로 chatGPT를 활용하고 있는 게 현실입니다. 기업이 돈을 지불하기에는 좀 약하지요. AI Agent가 활발히 논의되는 배경입니다.

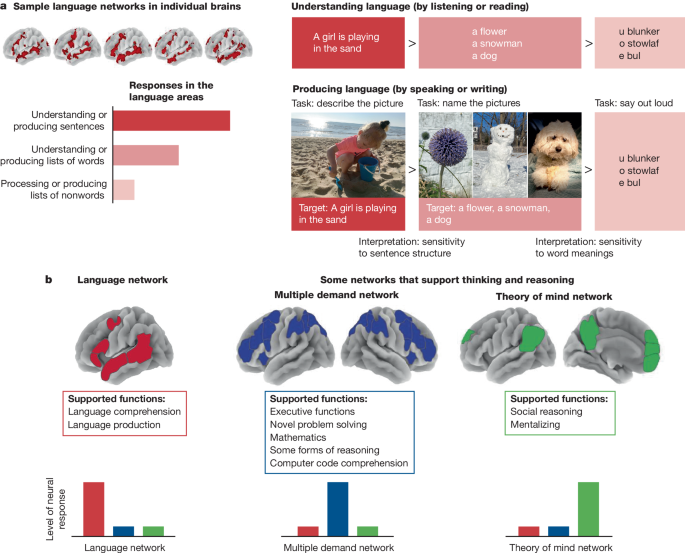
아래 그림은 인간 뇌의 진화 과정을 통해 AI의 미래에 대해 이야기하는 "a brief history of intelligence"라는 책에서 가져온 그림입니다.

제가 위 그림을 통해 공유하고 싶은 작가의 메시지는 언어 능력과 지능은 밀접하게 연관되어 있지만, 동일한 개념은 아니라는 것입니다. 언어 능력은 뇌의 특정 영역(좌측 신피질의 브로카 영역과 베르니케 영역)에서 주로 담당하고 이들 영역이 손상되면 언어 생성이나 이해에 문제가 생길 수 있지만, 다른 지적 기능은 정상적으로 유지될 수 있다고 합니다.
지능은 언어 이해와 생성 능력뿐만 아니라 문제 해결 능력, 추론 및 추상화, 기억(episodic memory)등 다양한 인지 기능을 포함하는 포괄적인 개념입니다.
AI Agent도 결국, LLM의 기존 언어 이해와 생성 능력에 추가적인 능력(계획과 추론)을 더하고 외부 도구(Memory, Search 등)와 결합하여 보다 유용한 도구(faster result or net new result)를 만들려는 시도라고 생각할 수 있습니다.
인간의 언어와 두뇌: 브로카와 베르니케의 발견
아래는 "a brief history of intelligence" 책의 "‘Language in the Brain" 챕터에서 발췌한 내용을 chatGPT를 통해 번역한 내용입니다.
1. 브로카 영역과 언어 생산: 1830년, 프랑스인 루이 빅토르 르보른은 말을 하지 못하게 되었지만, 지적 능력은 정상적이었다. 그는 단 한 마디, “탄(tan)“만 반복할 수 있었으며, 이후 ‘탄’이라는 별명으로 불렸다. 20년 후, 신경학자 폴 브로카가 그의 뇌를 부검한 결과, 좌측 전두엽의 특정 부위에 손상이 있음을 발견했다. 브로카는 언어를 담당하는 특정 뇌 영역이 있을 것이라고 가정했고, 이후 유사한 환자들을 연구한 끝에, 이 영역이 언어 생산을 담당한다는 사실을 입증했다. 이 부위는 오늘날 ‘브로카 영역’으로 불리며, 손상될 경우 말을 할 수 없는 브로카 실어증이 발생한다.
2. 베르니케 영역과 언어 이해: 브로카 이후, 독일 의사 카를 베르니케는 정반대의 증상을 보이는 환자들을 발견했다. 이들은 말을 유창하게 했지만, 문장이 전혀 의미를 이루지 못했다. 예를 들어, “스무들 핑커드가 필요해서 돌봐주고 싶어” 같은 말이 나왔다. 베르니케는 이 환자들의 뇌에서 좌측 후방 신피질에 손상이 있음을 확인했다. 이후 이 부위는 ‘베르니케 영역’으로 명명되었으며, 이곳이 손상되면 언어 이해가 불가능해지는 베르니케 실어증이 나타난다.
3. 언어의 보편적 기능과 독립성: 브로카와 베르니케 영역은 특정한 언어 형태(말하기, 글쓰기, 수화 등)에 국한되지 않고, 언어 자체를 담당한다. 예를 들어, 브로카 영역이 손상된 청각장애인은 수화를 유창하게 사용할 수 없으며, 베르니케 영역이 손상되면 음성뿐만 아니라 문자도 이해할 수 없게 된다. 즉, 인간의 언어는 특정한 뇌 영역에 의해 처리되며, 전체적인 지능과는 별개로 작동할 수 있다.
4. 인간과 유인원의 차이: 인간은 후두와 성대의 운동을 직접 제어할 수 있는 독특한 신경 구조를 가지고 있지만, 이것이 언어를 가능하게 한 핵심 요소는 아니다. 인간은 구어뿐만 아니라 수화와 같은 비언어적 방식으로도 언어를 익힐 수 있기 때문이다. 즉, 언어는 단순한 신체적 적응이 아니라, 특정한 뇌 기능의 결과다.
5. 언어는 뇌의 독립된 기능: 브로카와 베르니케의 연구는 언어가 좌측 신피질의 특정 네트워크에서 발생한다는 사실을 밝혀냈다. 이는 언어 능력이 다른 인지 능력과 분리될 수 있음을 설명해 준다. 예를 들어, 1995년 연구에 따르면, 심각한 지적 장애가 있는 크리스토퍼라는 소년은 15개 이상의 언어를 구사할 수 있었다. 이는 언어가 단순한 뇌 용량 증가의 결과가 아니라, 진화 과정에서 독립적으로 발달한 기능임을 시사한다.
6. 아직 끝나지 않은 이야기: 언어의 기원이 브로카와 베르니케 영역의 발달 덕분이라고 할 수 있을까? 언뜻 보면 그렇지만, 진화적 과정이 단순하지 않듯이, 언어의 기원도 단순한 문제는 아니다. 인간이 언어를 갖게 된 이유를 완전히 밝혀내려면, 아직 더 많은 연구가 필요하다.
위 논문 다운받으려면 여기 클릭
AI Agent의 개념과 핵심 기술
Goldilocks Introduction to AI 에이전트
너무 길지도 짧지도 않은(Goldilocks) AI 에이전트 소개로 시작합니다.
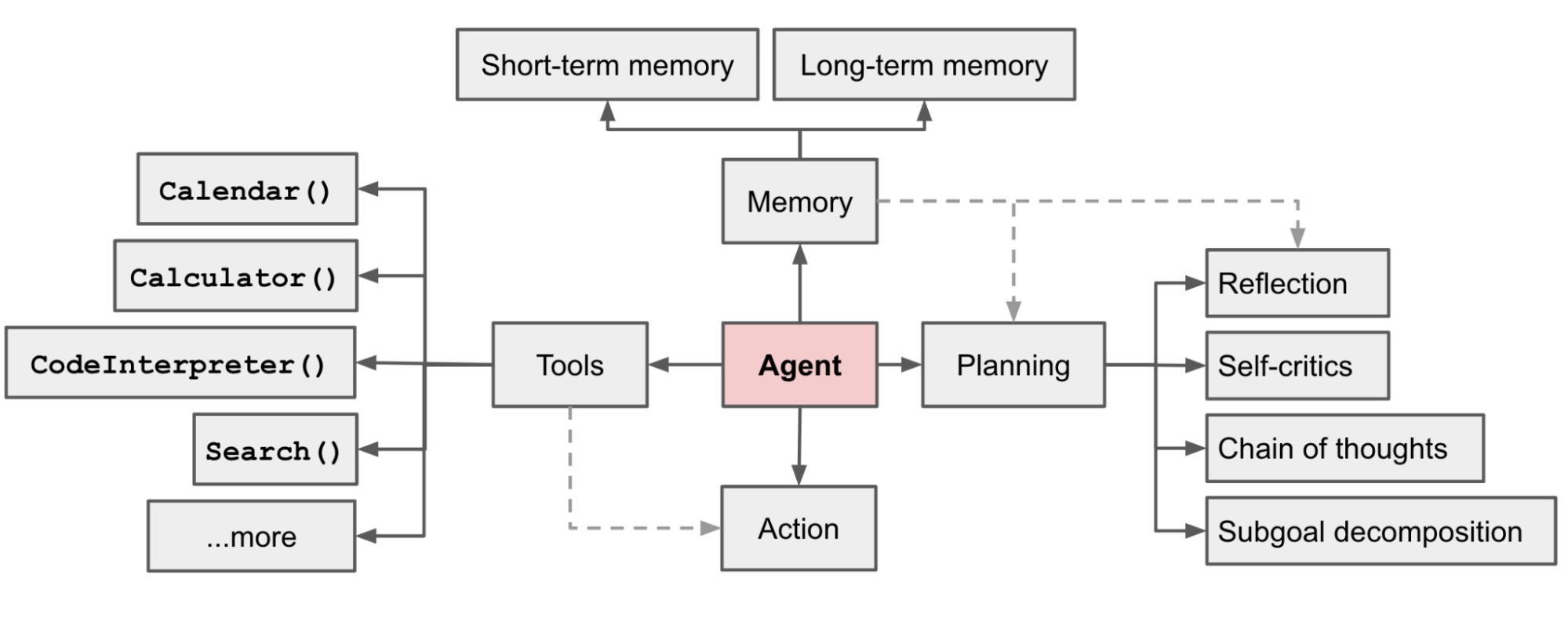
LLM 기반의 자율성을 가진 AI Agent System에서 LLM은 언어/문맥 이해 및 생성 능력에 추론/계획(Planning) 능력을 장착한 후, 과거에 대한 기억(Memory)과 여러 도구(Tool)를 활용하여 보다 지능적이고 능동적인 행동(Action)을 하게 됩니다.
계획(Planning)
- 하위 목표 설정: 복잡한 문제를 작고 관리하기 쉬운 하위 목표들로 세분화 (프롬프트 예: What are the subgoals for achieving XYZ?)
- 성찰(self-reflection): 과거 행동을 스스로 평가하고 반성, 실수를 통해 배운 내용을 다음 단계에서 개선 (ReACT 프롬프트 예: Thought: ... Action: ... Observation: ... Repeats N Times)
기억(Memory)
- 단기 메모리(Working Memory): 프롬프트에 구체적 지시 사항이나 예시(few-shot/in-context learning)를 제공하는 것
- 장기 메모리: 과거의 모든 정보를 저장(기억)한 후 문맥에 맞는 기억을 추출하는 것

도구 사용(Tool use)
- 잘 모르는(model weights에 없는) 최신/추가/내부 정보를 얻고, 코드 등을 실행하며 외부 환경과 상호작용하기 위해 도구 사용(주로 API 호출)
참고) DeepSeek은 어떻게 Reasoning Model 만들었나 - (이글을 참고했습니다.)
아래 인용 글처럼 base 모델이 충분히 똘똘하다면, 사람의 (큰) 개입 없이도 추론 능력을 끌어낼 수 있다는 것을 DeepSeek R1이 입증하였습니다.
“What R1 shows is that with a strong enough base model, reinforcement learning is sufficient to elicit reasoning from a language model without any human supervision,” says Lewis Tunstall, a scientist at Hugging Face.
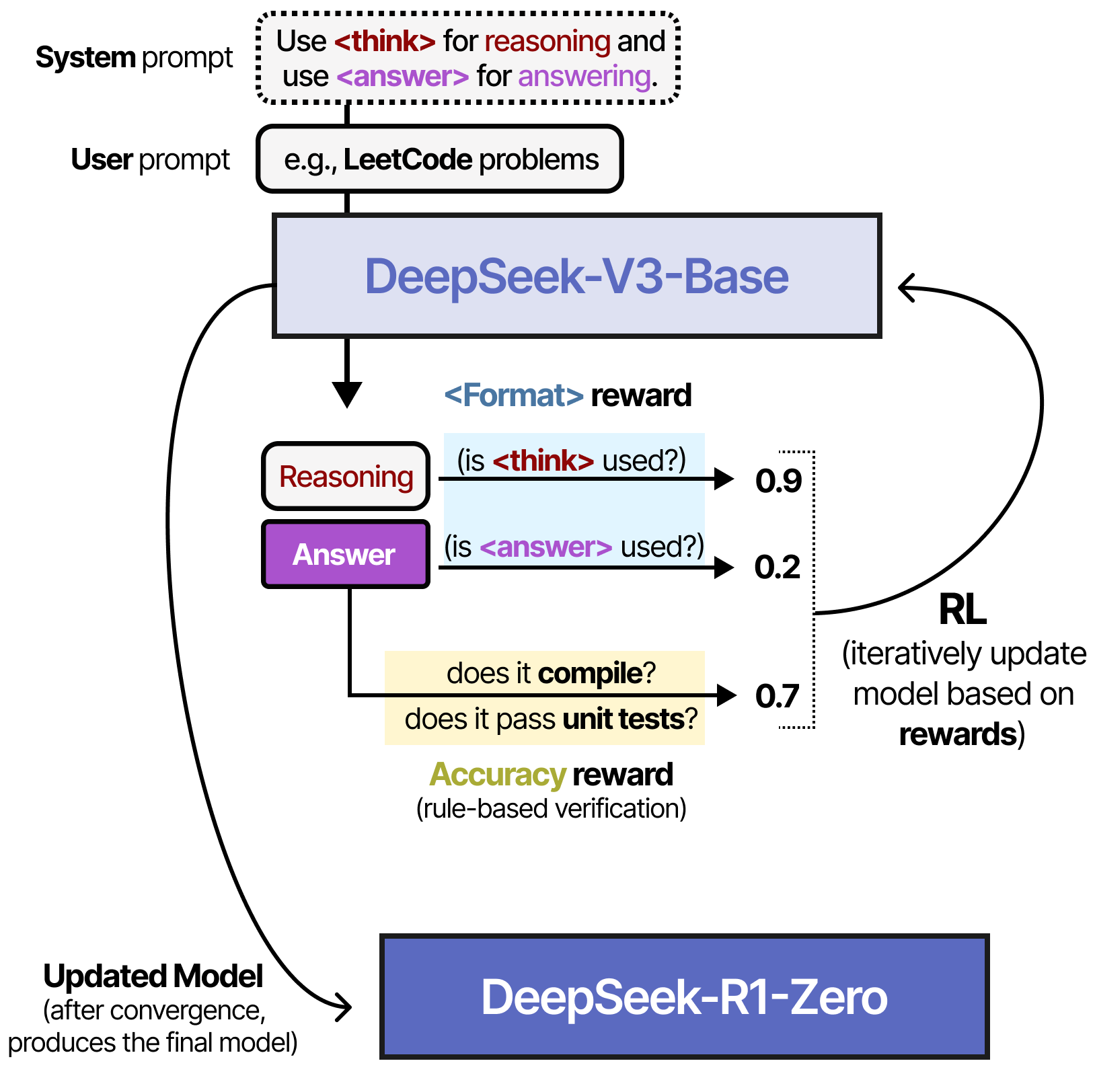
DeepSeek-R1 모델의 초석이 된 DeepSeek-R1 Zero 모델의 제작 방식을 간단히 살펴봅시다.
DeepSeek-V3-Base 모델을 기반으로, 다량의 추론 학습 데이터로 Supervised Fine-Tuning을 수행하는 대신, 오직 강화 학습(RL)만을 사용하여 추론 능력을 학습시켰습니다.
추론 모델 개발에 사용된 아래 Prompt를 보면 "추론 과정을 수행해야 한다."고만 명시되어 있지 실제 추론 과정이 어떻게 이루어져야 하는지에 대한 구체적인 지침은 제공되지 않았습니다.

강화 학습 과정에는 두 가지 규칙 기반 보상 시스템이 도입되었습니다.
- 정확도 보상(Accuracy rewards): 정답을 테스트하여 올바른 답변을 제공하면 보상합니다.
- 형식 보상(Format rewards) - 태그를 올바르게 사용하면 또 보상합니다.
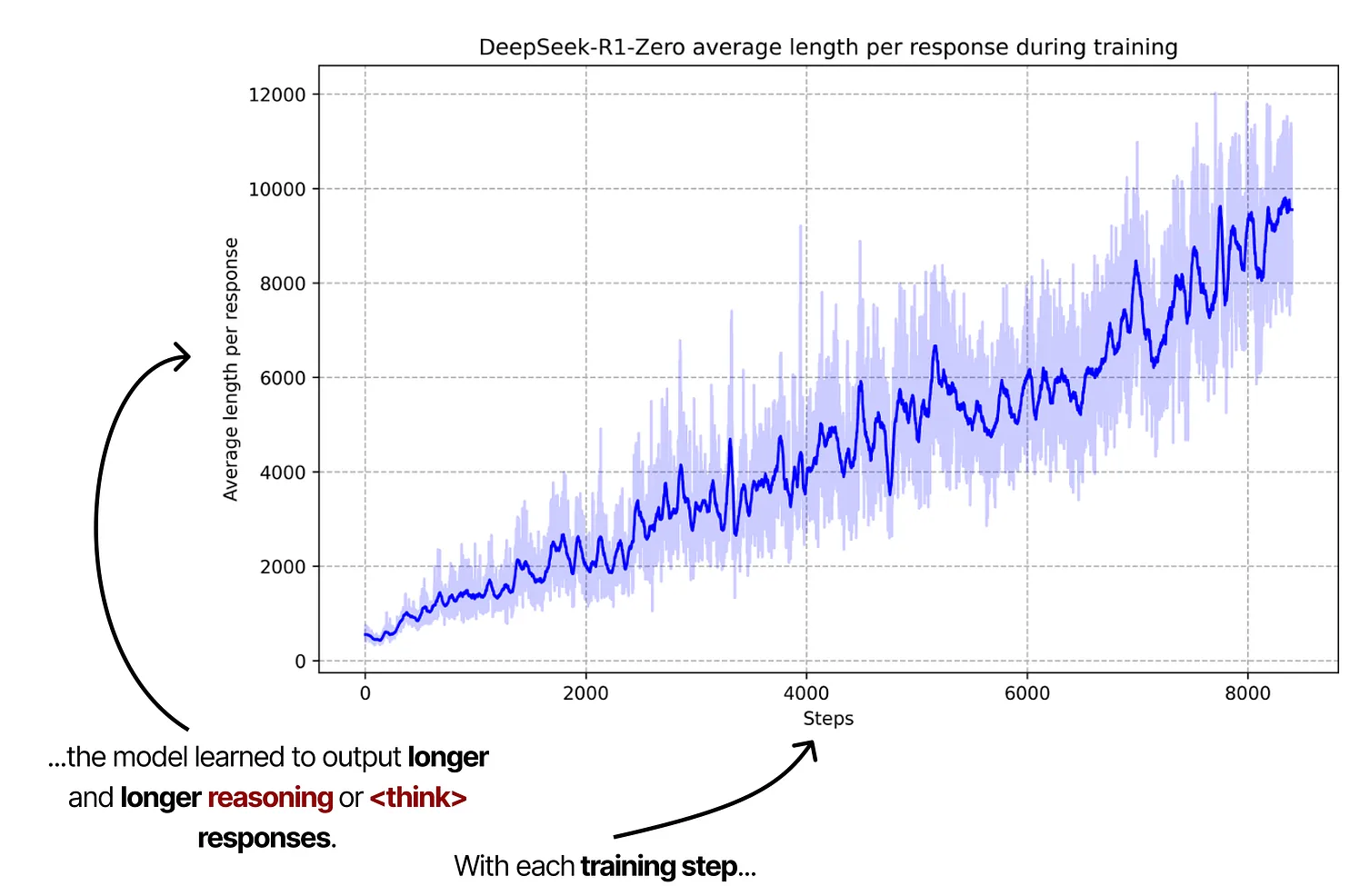
Reasoning Process에 대한 구체적인 가이드나 예시 없이도, 단순히 <think> 태그를 사용하는 행동을 보상했더니, 모델이 스스로 학습하여 아래 차트처럼 더 복잡하고 긴 추론(Chain-of-Thought)을 수행할수록 정답률이 높아진다는 것을 깨닫게 되었습니다.
 David Gu
David Gu구글 AI Agents 백서 소개
이제 Google의 백서를 바탕으로 AI 에이전트의 기본 개념과 구조를 살펴보겠습니다.
아래에서 원본과 요약본 pdf를 다운로드할 수 있습니다.
AI 에이전트란?
AI 에이전트는 세상을 관찰하고, 도구를 활용하여 세상에 개입함으로써 특정 목적을 이루려 합니다. 구체적인 목적이 주어지면 인간의 개입 없이도 자율적이고 능동적으로 행동할 수 있습니다.
an application that attempts to achieve a goal by observing the world and acting upon it using the tools that it has at its disposal. Agents are autonomous and can act independently of human intervention, especially when provided with proper goals or objectives they are meant to achieve. Agents can also be proactive in their approach to reaching their goals. Even in the absence of explicit instruction sets from a human, an agent can reason about what it should do next to achieve its ultimate goal.
에이전트의 핵심 구성 요소
아래 그림처럼 세가지 요소로 구성되어 있습니다.
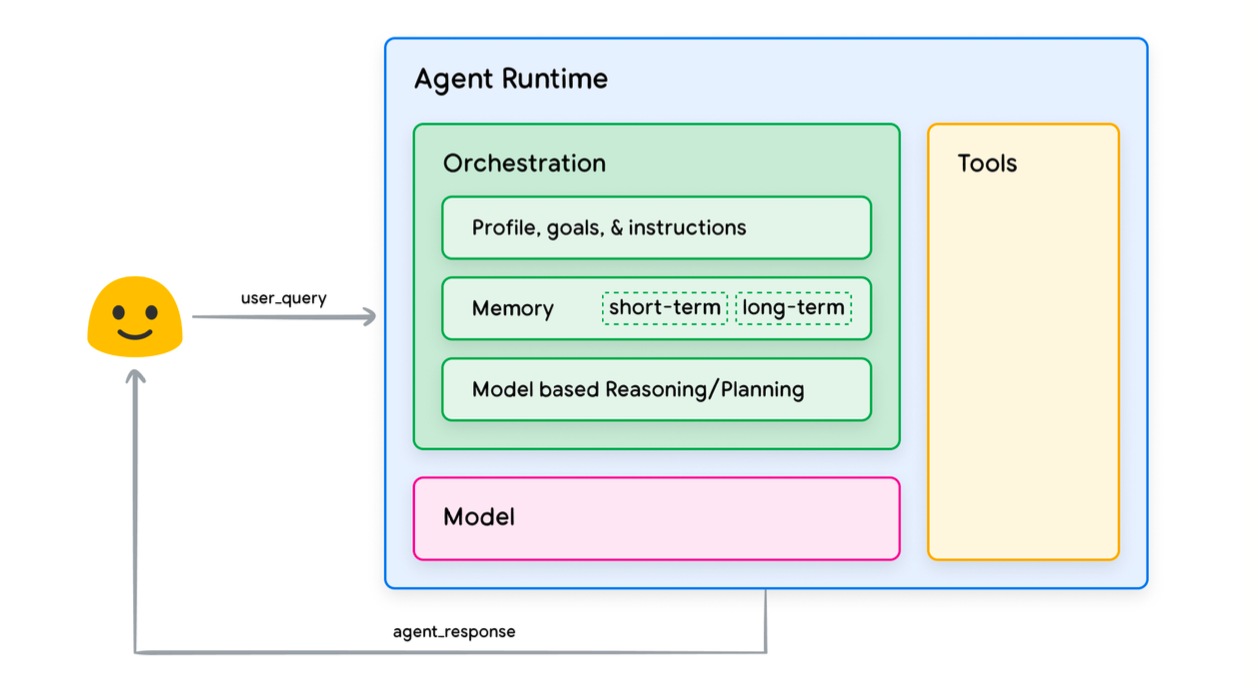
1. 모델 (Model): 언어 모델(Language Model)로서, 논리적 추론 과정(ReAct, Chain-of-Thought)을 수행하며 의사결정을 담당합니다.
2. 도구 (Tools): API 호출을 통해 언어 모델이 외부 세계(데이터, 서비스 등)와 상호작용하게 해줍니다.
3. 오케스트레이터 (Orchestrator): 모델이 추론 과정과 도구를 활용하여 모델 밖 세상과 상호작용하며 목적을 달성하는 과정을 통제하고 조율하는 역할을 합니다.
에이전트 vs. 언어 모델
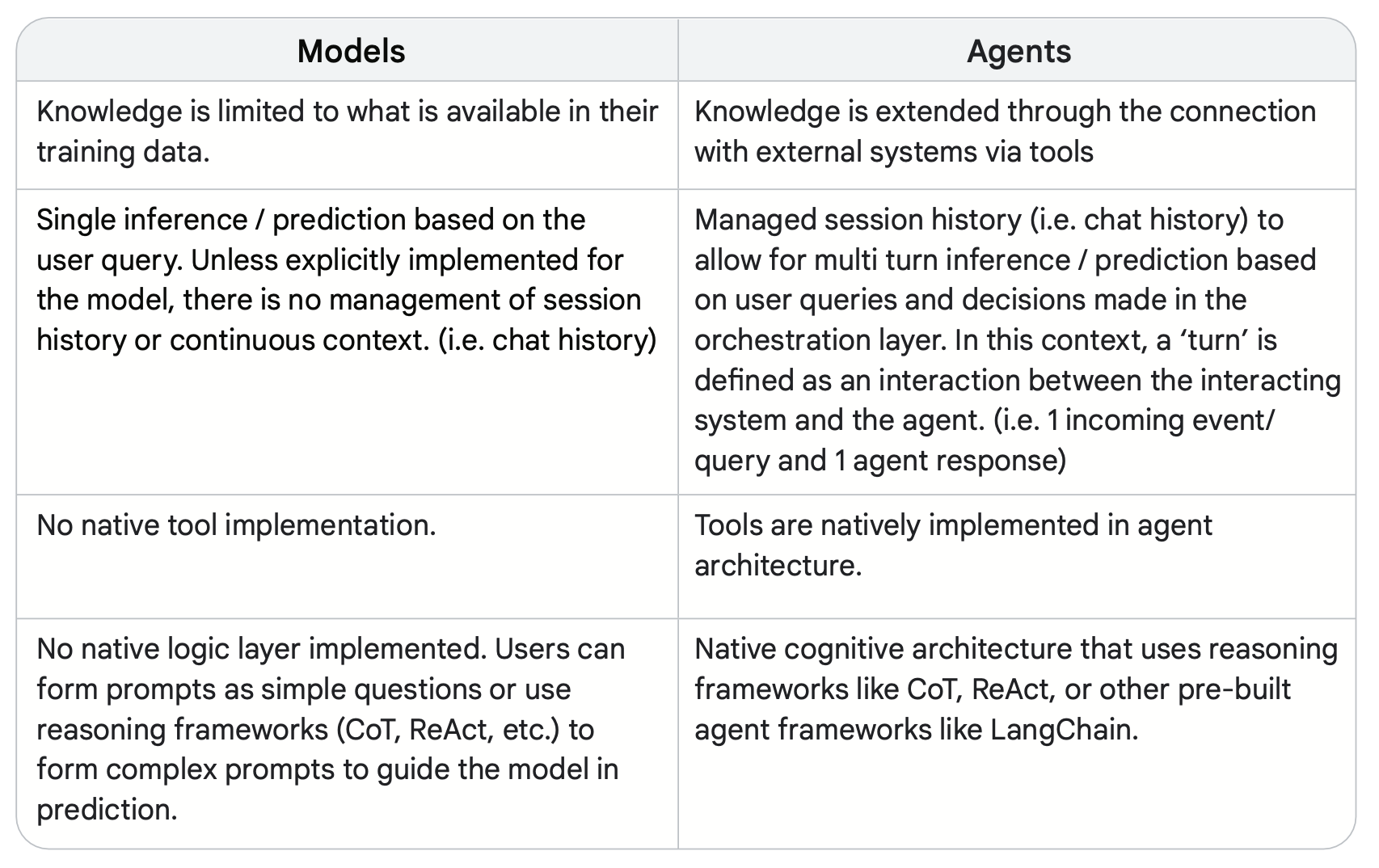
아래 표를 통해 언어 모델과 에이전트가 어떤 차이가 있는지 알아봅시다.
- Agent는 모델과 달리 외부 시스템과 연동으로 지식을 확장할 수 있음
- Agent는 세션 내에서 발생한 이전 대화 이력이 관리되어 다단계(multi-turn) 추론작업이 가능함
- Agent는 외부 도구와 연동될 수 있음
- CoT나 ReAct와 같은 추론 프레임워크가 내재화되어 있음 (사용자가 직접 복잡한 프롬프트를 작성할 필요 없음)
추론 프레임워크(Reasoning Framework)
대표적 추론 프레임워크인 ReAct (Reasoning + Acting)의 작동 방식을 살펴 봅시다.
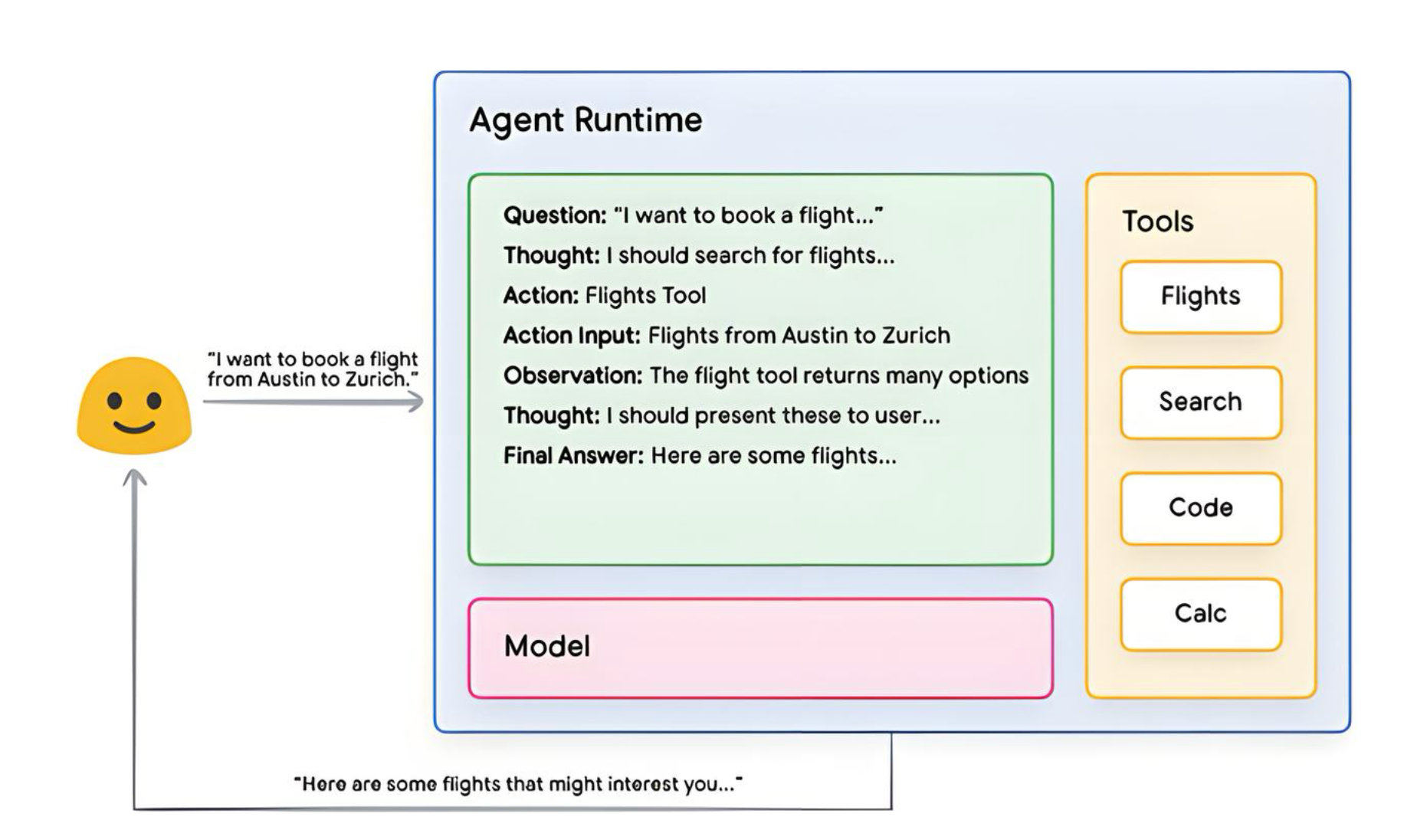
1. 사용자: 에이전트에게 질문
2. 에이전트: ReAct sequence 시작 - 모델에게 프롬프트 제공, 아래 ReAct 단계 수행
- 질문(Question): 사용자 입력 질의가 포함된 프롬프트
- 생각(Thought): 다음에 뭘 해야 할지 생각
- 행동(Action): 모델이 다음에 취할 행동 결정 - 이 단계에서 도구 [Flights, Search, Code, None] 선택과 도구에 제공할 값들이 결정됨
- 관찰(Observation): 행동의 결과를 관찰
- 생각-행동-관찰 과정을 반복 후 최종 답변 생성
- ReAct loop이 종료되고 최종 답변이 사용자에게 제공됨
이외에도 Chain-of-Thought(CoT), Tree-of-Thoughts (ToT)와 같은 Reasoning Framework가 있습니다.
Tool - Data Store
위의 ReAct 예제에서는 API 방식의 도구(비행편 검색 등)가 사용되었다면, 여기서는 Data Store를 도구로 사용하는 예시를 설명해 보겠습니다.
AI 에이전트 맥락에서 데이터 저장소(Data Store) 는 벡터 데이터베이스 형태로 구현됩니다. 벡터 데이터베이스는 데이터를 고차원의 벡터(embedding)로 저장하게 됩합니다. 벡터 방식의 데이터 저장소를 활용하는 대표적 예로 RAG(Retrieval-Augmented Generation, 검색 증강 생성) 기반 애플리케이션이 있습니다.
RAG 기반 애플리케이션이 접근할 수 있는 데이터 형식은 웹사이트(블로그 등), csv/엑셀과 같은 구조화된 자료, 그리고 워드 문서와 같은 비정형 문서가 있습니다.

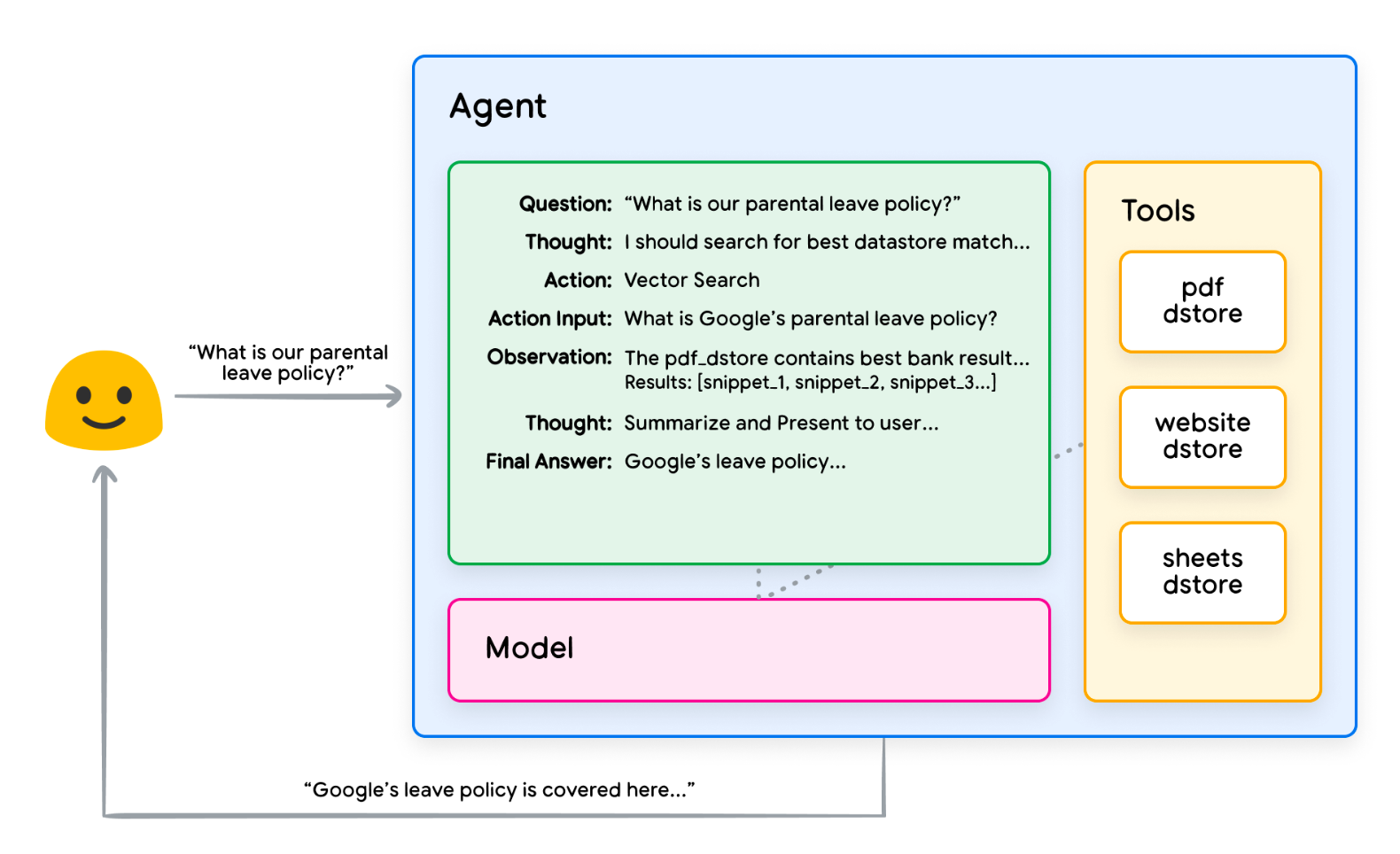
사용자 질문에 에이전트가 답변하는 처리 과정은 다음과 같습니다:
- 사용자 질문(Query)으로 쿼리 임베딩(벡터) 생성
- 쿼리 임베딩으로 벡터 데이터베이스 내에 저장된 유사 콘텐츠 검색
- 추출된 유사 콘텐츠 에이전트 전달
- 에이전트가 답변 생성
- 최종 응답 사용자 전달
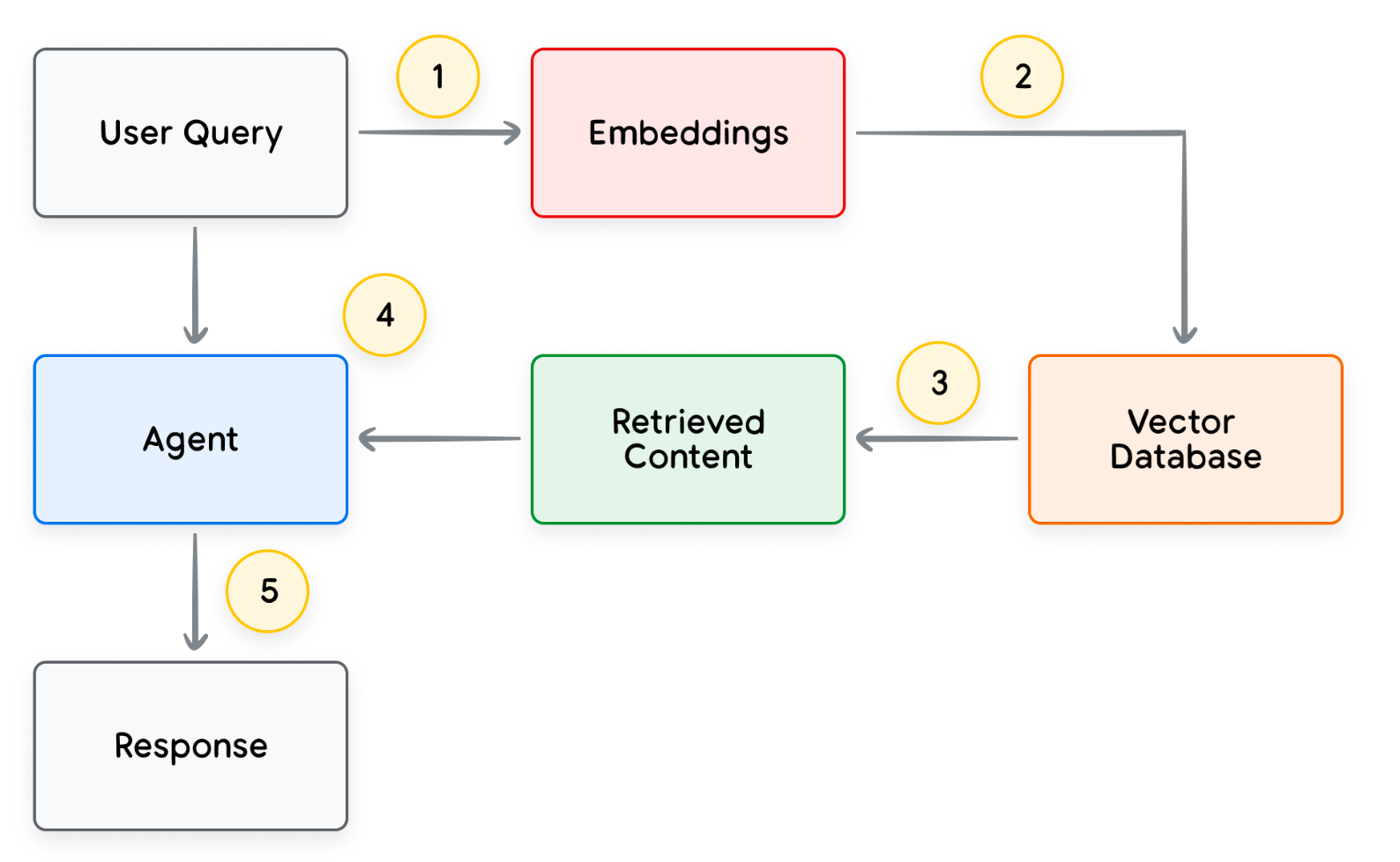
아래 그림은 RAG 기반 사내 문서 검색 시스템의 예시입니다.
참고) 효과적인 Agent 만드는 법 by Anthropic
Anthropic 직원이 쓴 "효과적 Agent 만드는 법"이라는 글도 잠시 살펴보겠습니다. 주요 내용만 아래 발췌했습니다.
LLM 활용하여 복잡한 업무를 자동화하는 한 앱을 만들 때, 일관되고 정확한 결과를 기대한다면 현재로서는 미리 정의된 절차를 선형적으로 따르는 workflow 방식이 좋습니다. RAG 방식으로 in-context 예제를 잘 제공해 주는 것이 정확한 답변 생성을 위한 최고의 방법입니다.
When more complexity is warranted, workflows offer predictability and consistency for well-defined tasks, whereas agents are the better option when flexibility and model-driven decision-making are needed at scale. For many applications, however, optimizing single LLM calls with retrieval and in-context examples is usually enough.
우리는 agentic systems(AI Agent)를 그 구조에 따라 아래 두가지 범주로 나누고 있습니다.
- Workflows are systems where LLMs and tools are orchestrated through predefined code paths.
- Agents, on the other hand, are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks.
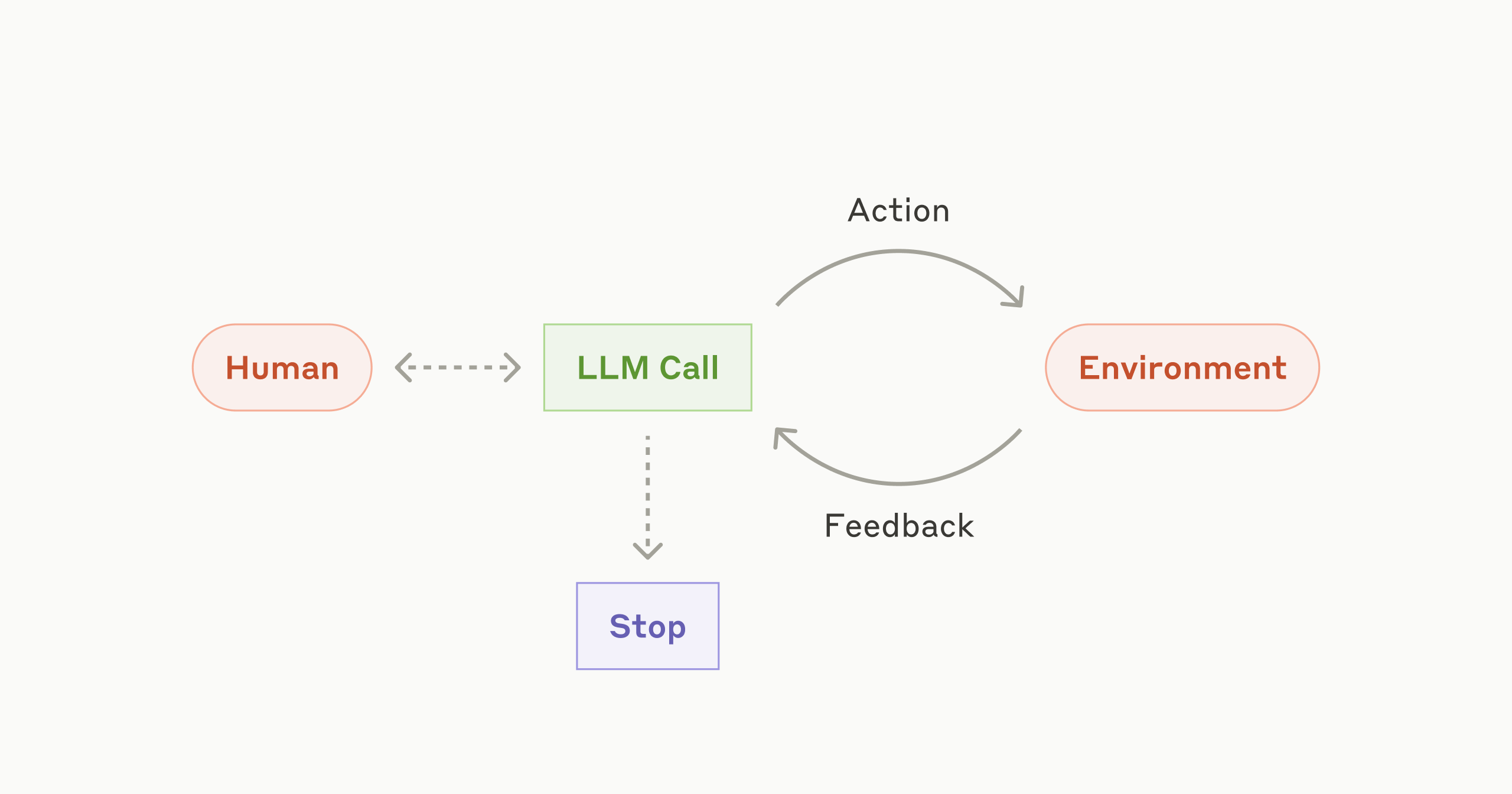
위 내용을 도식으로 살펴보면 아래와 같습니다.
- AI Agent의 building block 도식입니다.
- building block(LLM call)을 이용해 workflow를 설계한 도식입니다. 이전 단계의 LLM call의 결과가 다음 단계의 LLM call에 순차적으로 전달되는 구조입니다. 중간 중간 작업이 잘 진행되고 있는지 확인하는 gate(관문) 단계를 추가할 수 있습니다.
chain workflow 코드 예제 - 데이터 추출 후 formatting하는 작업
# Example 1: Chain workflow for structured data extraction and formatting
# Each step progressively transforms raw text into a formatted table
data_processing_steps = [
"""Extract only the numerical values and their associated metrics from the text.
Format each as 'value: metric' on a new line.
Example format:
92: customer satisfaction
45%: revenue growth""",
"""Convert all numerical values to percentages where possible.
If not a percentage or points, convert to decimal (e.g., 92 points -> 92%).
Keep one number per line.
Example format:
92%: customer satisfaction
45%: revenue growth""",
"""Sort all lines in descending order by numerical value.
Keep the format 'value: metric' on each line.
Example:
92%: customer satisfaction
87%: employee satisfaction""",
"""Format the sorted data as a markdown table with columns:
| Metric | Value |
|:--|--:|
| Customer Satisfaction | 92% |"""
]
report = """
Q3 Performance Summary:
Our customer satisfaction score rose to 92 points this quarter.
Revenue grew by 45% compared to last year.
Market share is now at 23% in our primary market.
Customer churn decreased to 5% from 8%.
New user acquisition cost is $43 per user.
Product adoption rate increased to 78%.
Employee satisfaction is at 87 points.
Operating margin improved to 34%.
"""
print("\nInput text:")
print(report)
formatted_result = chain(report, data_processing_steps)
print(formatted_result)
------------------------------------------------------------------------
Input text:
Q3 Performance Summary:
Our customer satisfaction score rose to 92 points this quarter.
Revenue grew by 45% compared to last year.
Market share is now at 23% in our primary market.
Customer churn decreased to 5% from 8%.
New user acquisition cost is $43 per user.
Product adoption rate increased to 78%.
Employee satisfaction is at 87 points.
Operating margin improved to 34%.
Step 1:
92: customer satisfaction points
45%: revenue growth
23%: market share
5%: customer churn
8%: previous customer churn
$43: user acquisition cost
78%: product adoption rate
87: employee satisfaction points
34%: operating margin
Step 2:
92%: customer satisfaction
45%: revenue growth
23%: market share
5%: customer churn
8%: previous customer churn
43.00: user acquisition cost
78%: product adoption rate
87%: employee satisfaction
34%: operating margin
Step 3:
Here are the lines sorted in descending order by numerical value:
92%: customer satisfaction
87%: employee satisfaction
78%: product adoption rate
45%: revenue growth
43.00: user acquisition cost
34%: operating margin
23%: market share
8%: previous customer churn
5%: customer churn
Step 4:
| Metric | Value |
|:--|--:|
| Customer Satisfaction | 92% |
| Employee Satisfaction | 87% |
| Product Adoption Rate | 78% |
| Revenue Growth | 45% |
| User Acquisition Cost | 43.00 |
| Operating Margin | 34% |
| Market Share | 23% |
| Previous Customer Churn | 8% |
| Customer Churn | 5% |
| Metric | Value |
|:--|--:|
| Customer Satisfaction | 92% |
| Employee Satisfaction | 87% |
| Product Adoption Rate | 78% |
| Revenue Growth | 45% |
| User Acquisition Cost | 43.00 |
| Operating Margin | 34% |
| Market Share | 23% |
| Previous Customer Churn | 8% |
| Customer Churn | 5% |
- 아래 모델은 Orchestrator 모델의 도식입니다. 중앙의 LLM이 복잡한 작업을 세분화하여 하위 일꾼(worker) LLM에게 할당한 후, 각 작업 결과를 종합하여 결과를 만드는 구조입니다.
Orchestrator 구조로 AI Agent를 구현한 코드 예제를 보시려면 여기를 참고해 주세요.
AI Agent에 대해 여전히 부정적 입장이시고, 본인과 비슷한 생각을 가진 사람의 글을 읽고 싶으시면 여기를 참고해 주세요.
Tool 사용 관련 Prompt Engineering 유의점에 대해 언급한 내용을 인용하고 본 섹션을 마무리하겠습니다.
Put yourself in the model's shoes. Is it obvious how to use this tool, based on the description and parameters, or would you need to think carefully about it? If so, then it’s probably also true for the model. A good tool definition often includes example usage, edge cases, input format requirements, and clear boundaries from other tools.
Sell Work, Not Tools
Service as a Software - AI Digital Worker
현재 AI 에이전트 분야에서 (일단은) 성공적으로 성장하고 있는 대표적 미국 스타트업들입니다
- 업무 자동화 플랫폼 Glean은 설립 4년이 채 못 되어 연 매출 4천만 달러를 달성
- AI 변호사 Harvey는 3년 만에 5천만 달러의 매출을 기록
- AI 코딩 도구 Cursor는 월 매출이 6개월 만에 35만 달러에서 400만 달러로 증가
- Digital Worker를 개발하는 스타트업 11x는 2023년 말에 서비스 출시(아래 그림) 후, 2024년에 1천만 달러 매출(ARR)을 달성

하지만, 강력한 영업 기반을 보유한 Salesfoce의 Agentforce와 비교하여, 이들 스타트업들이 지속적으로 차별점을 보여줄 수 있을지는 의문입니다.

이메일 자동으로 보내주는 에이전트가 과연 미래에도 유용할까?
이메일 마케팅 캠페인의 주요 목표는 사람들이 직접 이메일을 열고, 내용을 읽고, 링크를 클릭하도록 유도하는 것입니다. 하지만 만약 에이전트가 이메일을 대신 확인하고, 주요 내용을 요약해 주며, 간단한 회신까지 자동으로 처리해 준다면 어떻게 될까요? 개인화 마케팅 에이전트의 존재 이유가 고민되는 지점입니다.

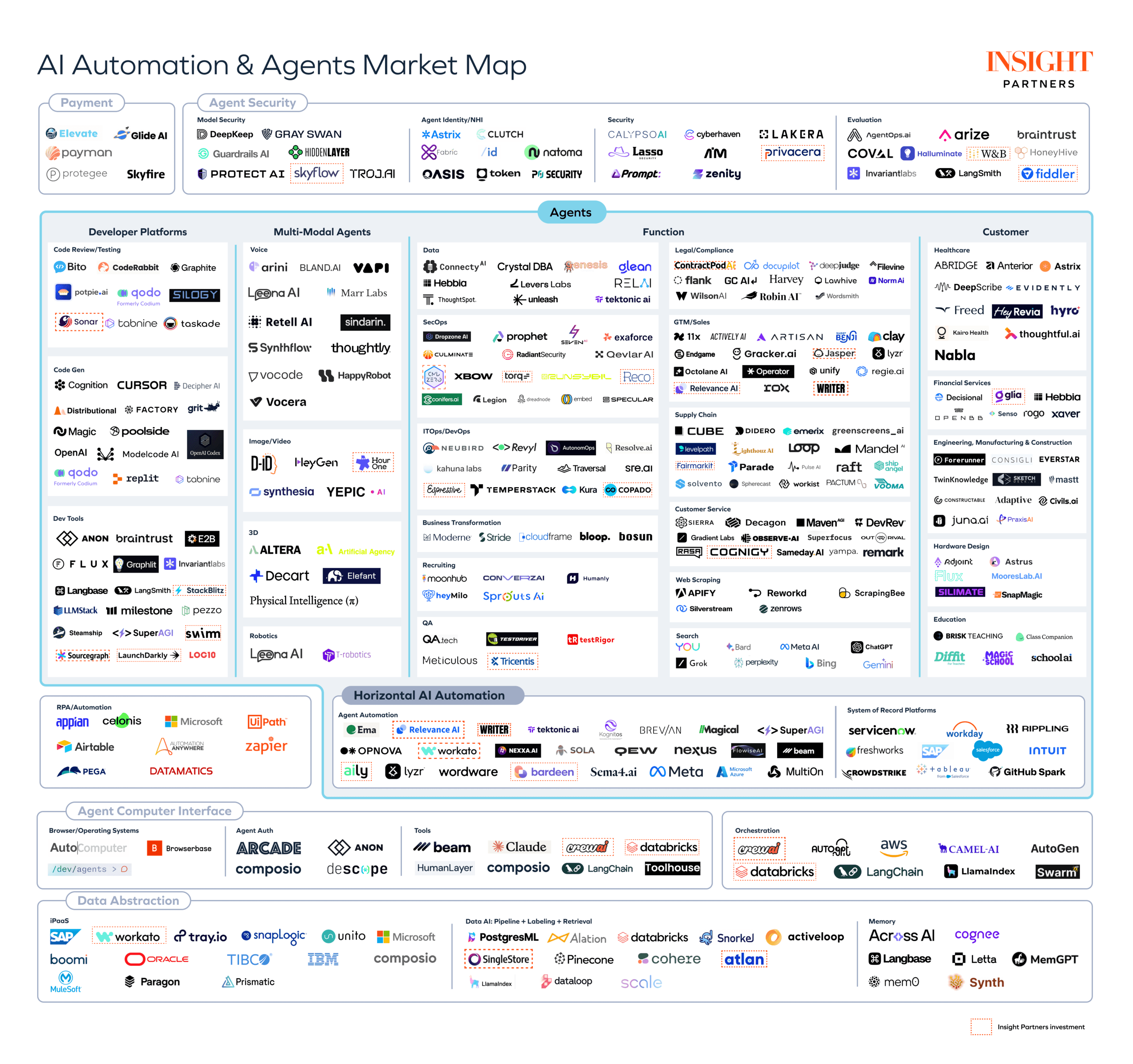
참고) AI Agent Market Map

HEARTCOUNT, Analytical AI Agent
"실무자에게 데이터 분석이란 지표와 관련한 그때 그때의 질문(ad-hoc questions)에 (정형) 데이터를 사용하여 빠르고 정확하게 답변하는 일"이고, "HEARTCOUNT가 실무자들이 이 일을 해내는데 제법 요긴한 도구"라는 이야기를 처음 한 것이 벌써 3년 전입니다.
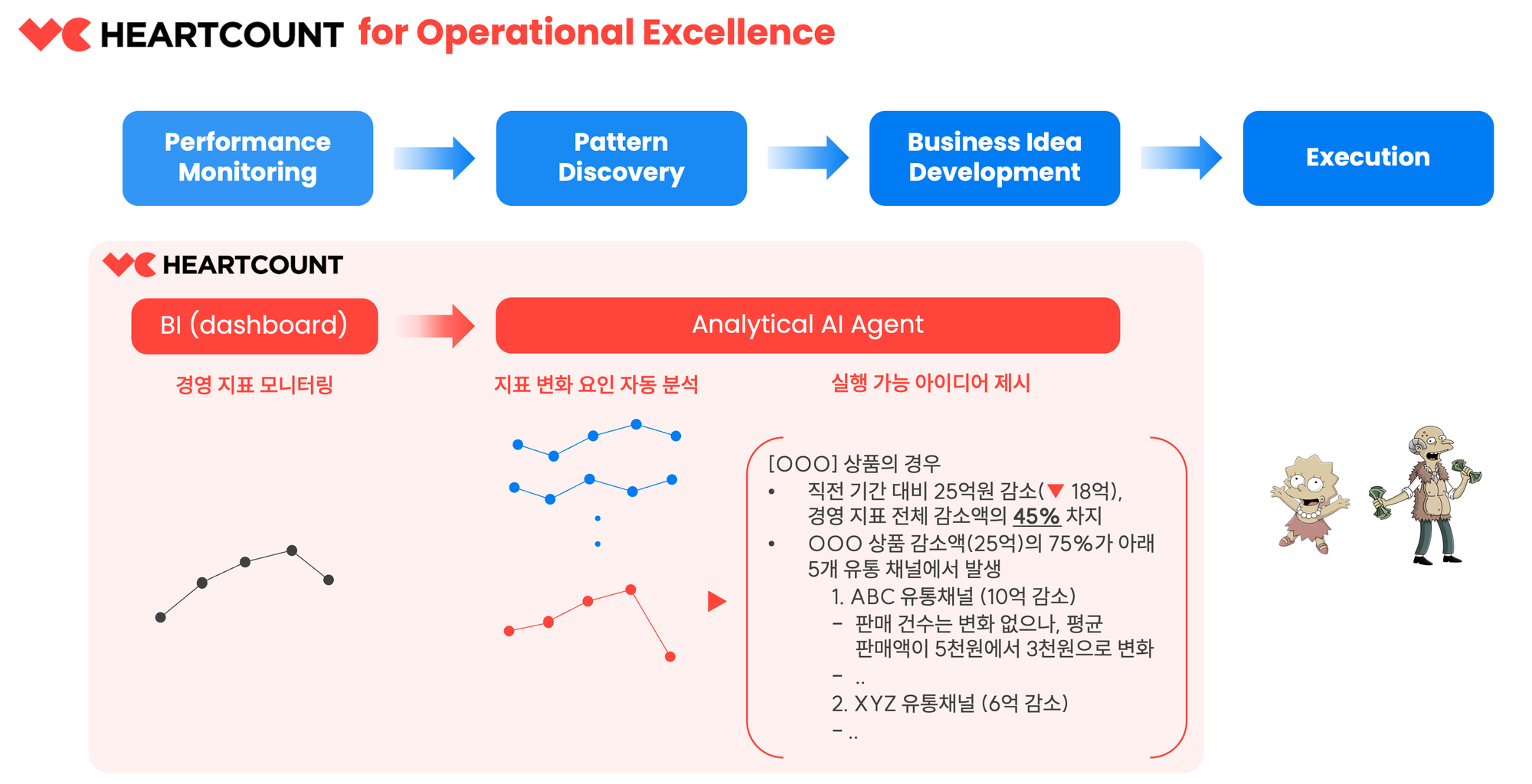
우리 앞에 놓인 "답변"이 질문에 대해 (정형) 데이터가 답할 수 있는 최선의 답변이고, 그 사실을 우리가 신뢰할 수 있다면, "답변"이 생성되는 과정은 몰라도 되는, 알고 싶지도 않은 일일 수도 있겠다는 생각을 요즘 하고 있습니다. 데이터 분석이 실무자가 모두 익혀야 마땅한 스킬(data literacy)이 아니라 AI가 대신할 수 있는 지루한 기계적 절차일 수도 있겠다는 생각입니다.
실무자의 일을 도와주는(augmentation) 데이터 도구와 실무자의 일을 대신하는(automation) 데이터 도구 사이의 경계가 당장은 모호합니다. 하지만, 기술과 산업은 우리의 생산성보다는 회사의 생산성을 높이는 방향으로 발전할 것이고, 결국 실무자들이 전통적인 방식으로 데이터를 분석하고 보고서를 작성하는 일은 사라질 것입니다. 그리고, 답변이 생성되는 과정에는 무심한 채 그 결과만을 소비하게 되었을 때 우리가 치러야 할 대가가 무엇일지 잘 모르겠습니다. 그래도 우리는 어떻게든 잘 적응하겠지요.
데이터 분석 질문에 답변을 척척 해주는 AI 도구를 요즘 유행하는 AI Agent에 Analytical을 더해 "Analytical AI Agent"라고 명명해 봅니다. 우리가 AI Agent에 백지위임장(Carte Blanche)과 같은 전권을 부여할 수 있기까지는 아직 시간이 좀 더 필요할 것입니다. 하지만, 하나의 정답이 없는 복잡하고 어려운 질문(hard question)을 하위 질문들로 분해(Planning/Reasoning)하고, 외부 도구(SQL, 분석 알고리즘 등)을 활용하여 답변을 생성해내는 AI Agent는 이미 당장 실현 가능한 기술이 되었습니다.
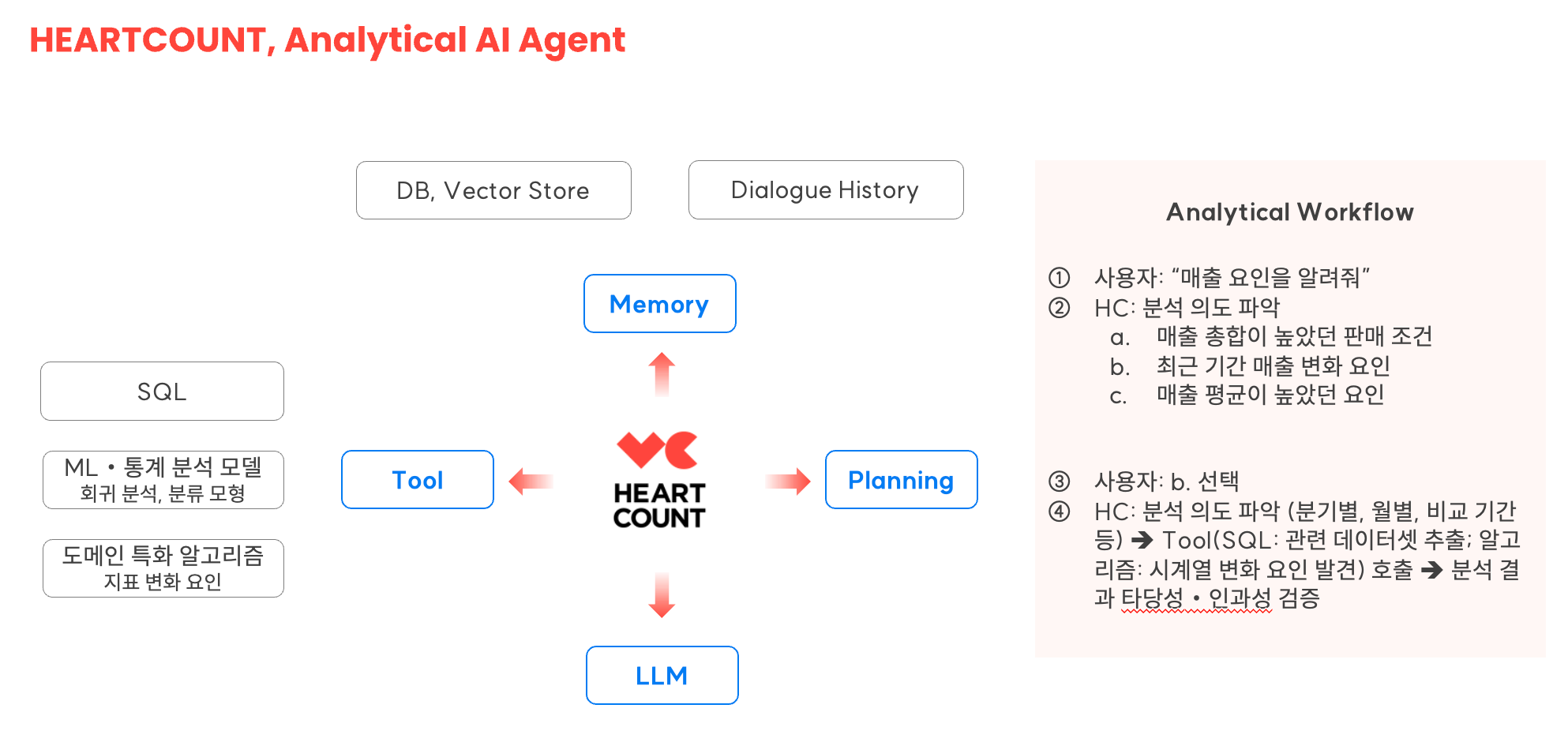
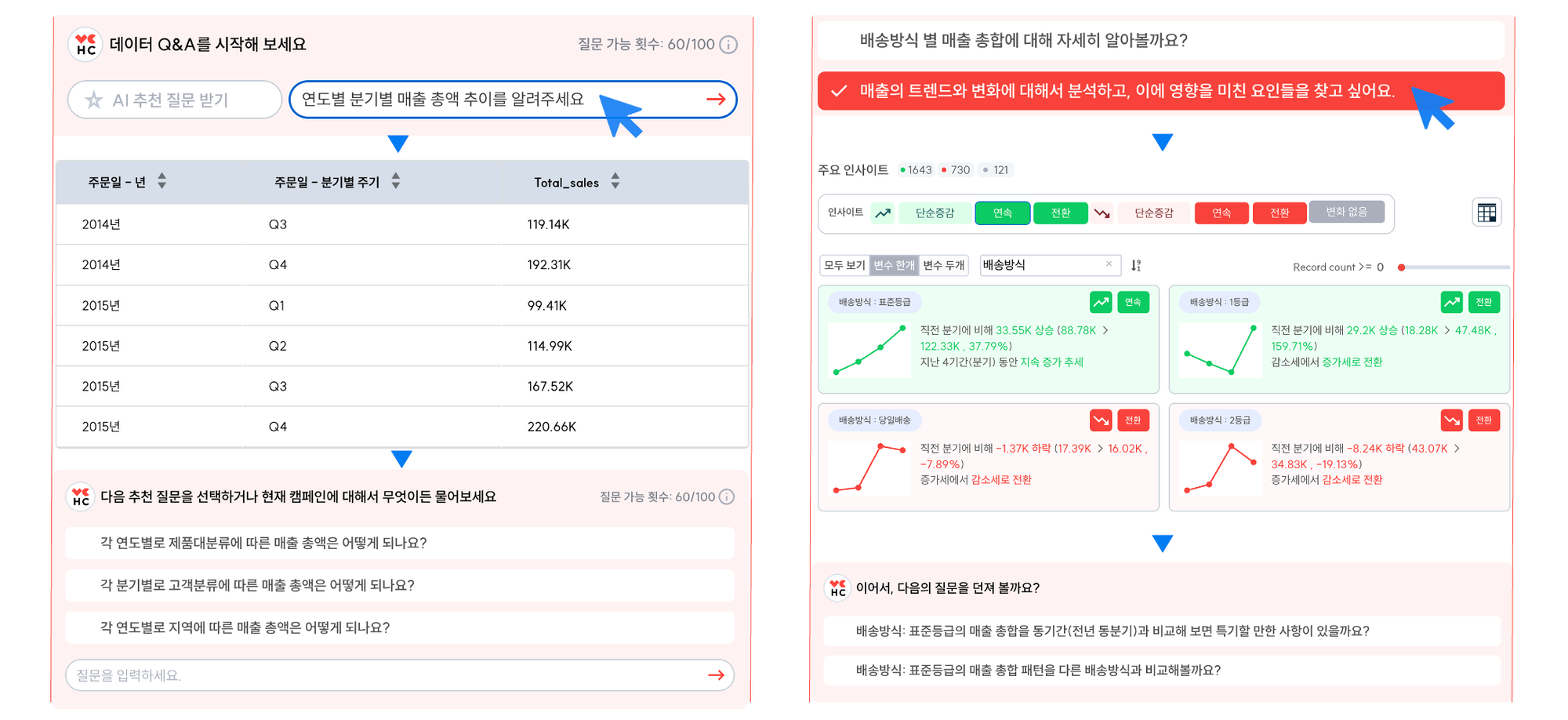
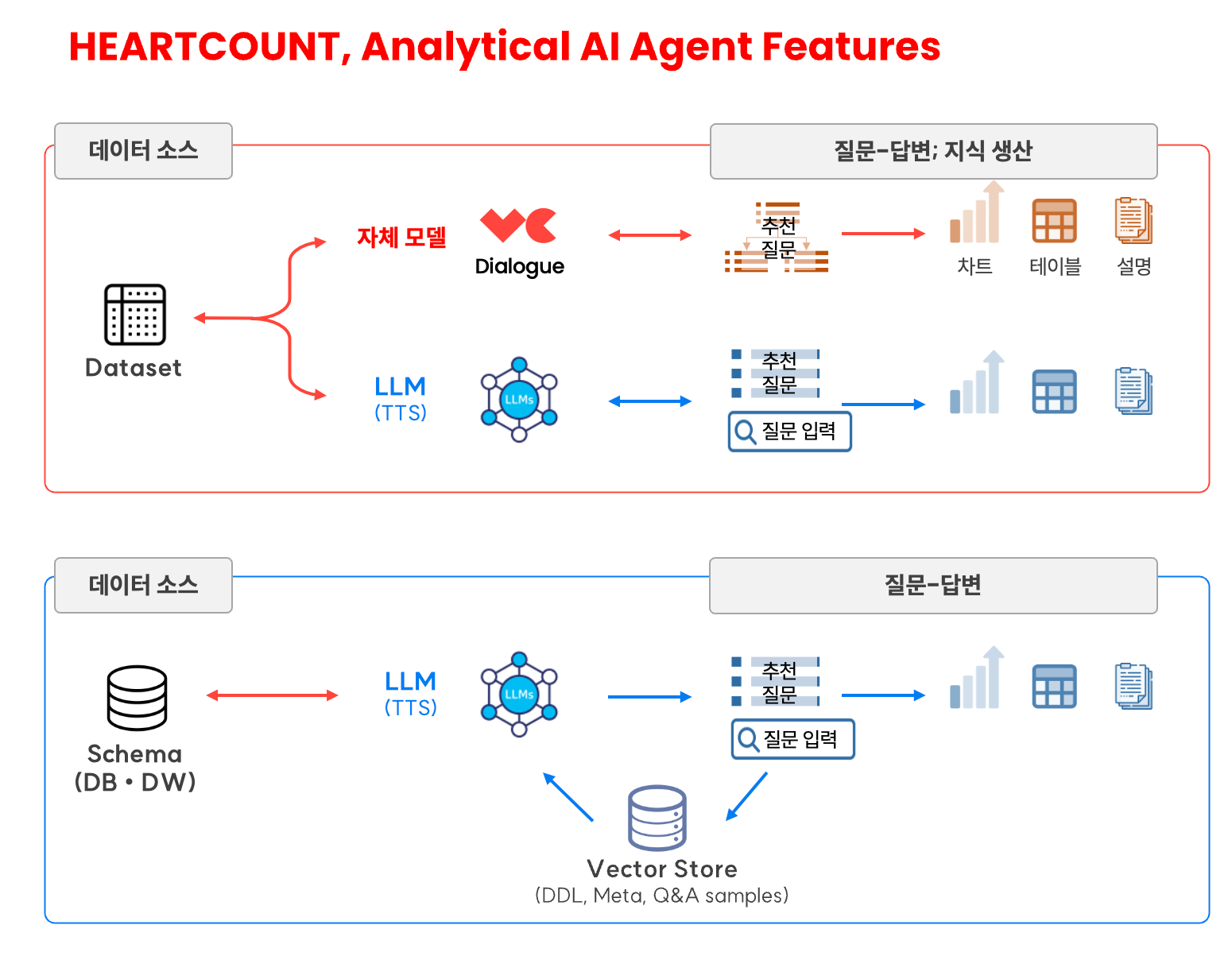
HEARTCOUNT에는 이미 아래와 같은 Analytical AI Agent 기능이 구현되어 있습니다.
데이터셋(엑셀, csv)을 연동하는 경우
- Data Q&A: 간단한 집계성 질문(descriptive analytics)에 대한 답변 자동화 기능. 개방형 질문을 이해하고 문맥에 맞는 질문을 추천하기 위해 LLM과 TTS(Text-to-SQL) 기술을 사용.
- Dialogue: 왜, 어떻게와 같은 하나의 정답이 없는 hard questions에 답하기 위한 기능. 분석 의도를 파악한 후 분석 목적에 맞는 최적의 패턴을 제공하기 위해 ML, 자체 통계분석 알고리즘을 사용.
DW(DB)와 연동하는 경우 (ABI 고객)
- RAG-based TTS: 복잡한 스키마에 대한 개방형 질문에 답할 수 있는 SQL 생성 정확도를 높이기 위해 RAG 기술을 사용
- Data Q&A for Schema: RAG 기반 TTS 엔진을 사용하여 특정 스키마(관련된 DB 테이블 집합)에 대한 개방형 질문에 차트, 결과 테이블, 설명을 제공하는 기능 (25년 3월 공식 출시 예정)
지금 바로 시작해 보세요. 관련 문의 사항이 있다면 support@idk2.co.kr로 연락주세요.
[기타 참고 자료]
![[Webinar VOD] 2025 AI Agent의 모든 것](/ko/content/images/size/w360/2025/02/2---_---------------------1080_1080.png)
![[무료 웨비나] AI Agent 데이터 분석 - HEARTCOUNT 2.0 출시 웨비나 (3/25, 2pm)](/ko/content/images/size/w540/2026/03/3---__------_1280_720-1.png)

![[Webinar VOD] 2025 AI Agent의 모든 것](/ko/content/images/size/w540/2025/02/2---_---------------------1080_1080.png)