1.2024年、Data & Analytics市場の全体的な流れと最新トレンドを把握したい方。
2.生成型AIがデータ分析業務をどのように変えるのか知りたい方。
人間固有の3つの能力は思考(thinking)、意志(wanting)、感情(feeling)である、と何かの本で読んだ記憶があります。今や思考はもはや人間のみの能力ではないようです。言語で表現された思考が私たちの原始的で曖昧な感覚を合理化するための手段であると考えれば、感情が排除された機械的な思考方式ならではのメリットもあるようです。
生成AI技術が「Data and Analytics」を扱う製品と人々にもたらす変化について、感じたこと、考えたことを共有するために短い文章でまとめてみました。できるだけ間違いのない予測をするために、生成AI技術が直線的に発展するというやや甘い仮定で2024年を展望しました。
2023年の1年だけで判断すると、生成型AIが「仕事としての」データ分析を大きく変えたことはないようです。「仕事としての」データ分析と限定した理由は、企業内で仕事としてデータを分析することは非常に目的指向的な行為だからです。そして、その目的は他ならぬ「知識の生産」です(であるべきです)。
Baseline Model と Baseline Shift
企業内の主要な意思決定にデータを活用する時にする(すべき)ことは以下の2つです。
- まず、データとして理解している(mental model)ビジネスの構造(指標を構成している変数 - 顧客特性、商品特性、販売地域/時間帯など - の寄与度と指標に影響を与える制御可能な要因に対する因果関係)と、データに含まれるビジネスの構造と因果関係とを比較し、ビジネスを取り巻く現実/実態に対する知識(baseline model)を正確かつ精巧にすることが必要です。
- 次に、ビジネスの主要指標の推移を観察し、変化(variation)をモニタリングします。指標に変化がある場合、この変化が運(noise, randomness)による偶発的な変化なのか、それともビジネスを取り巻く内外の環境に根本的な変化があり、新しい現実(reality)が構築されたのかを判断しなければなりません。新しい現実が構築された場合(baseline shift)、変更された構造と秩序、因果的な連鎖を定量的に理解し、知識(baseline mental model)をアップデートし、それによって新しい戦略的、戦術的、運営的な意思決定をしなければなりません。
もちろん、データで精緻化された baseline model は自分たちが行っていない道、場所までは教えてくれないという限界があります。ボタンの色を濃い黄色からレンガ色に変更したらコンバージョン率が 0.1% 増えたということは教えてくれるかもしれませんが、もっと大きなインパクトをもたらすことができる他の可能性(ゴールド色のボタン)については教えてくれません。これはまだ 直感 の領域であり、直感 が人間だけの天賦の能力なのか、機械も習得できる能力なのかは時間が解決してくれるでしょう。

結局、実務者の観点から仕事としてデータを活用する上で重要なのは、意思決定者が良い意思決定を行えるように、私たちのビジネスの構造、順序、因果関係に対するインスピレーションと知識の生産に貢献することです。「ようやく見えてきた、Now, I See It!」、「これでいいんだ!」、「こうすればいいんだ!」といった瞬間を作り出すことです。
データがお金になるインスピレーションと知識の源泉にならない理由
しかし、私たちがデータを媒介にして知識を生産する仕事がまだうまくできていない理由は、既存のデータ言語/ツールの「言語理解」能力やデータアナリスト/実務者の「コード生成」能力の不足によるものではないでしょう。
データがお金になるインスピレーションと知識の源泉にならない3つの理由と解決策のヒントは以下のような内容です。
- データに尋ねるべき質問とそうでない質問を区別することの難しさ: baselineの変化はないものの、運の影響で指標が動揺した場合、データからその動揺の原因を探してみなければ、新たに知ることができません。3歳の子供がクレヨンで描いた落書きのようなグラフを見ながら一喜一憂しないように、注目すべき変化とそうでない変化を技術とツールが区別してくれる必要があります。(signalとnoiseとを区別するアルゴリズムについての考えは、別のブログで説明します)。
- 質問に関連するデータセットにタイムリーにアクセスすることの手間: データアクセスに関連する技術的、手続き的な困難さが、質問にデータで答える必要がない適当な言い訳になることがありますが、この苦しい現実は変わりません。データアクセスの民主化のために、TTS (Text-to-SQL)が解決策になる可能性があります。(Text-to-SQLのセクションを参照)。
- 与えられたデータセットから知識の生産に至るまでのコツがわからない: コツがわからない状況がデータリテラシー教育で解決されないことは、過去10年の経験がよく物語っています。これは、データで問題が解決される経験を提供する新しいツールの発明によって解決する必要があります。しっかりとしたデータツールが、与えられた質問の文脈で分析的推論の手順を提示し、データセットが教えてくれるパターン/秩序の全体像を展開することができれば、実務者はパターンを適切に選択し、総合して「知識が詰め込まれた」データレポートを作成することができるでしょう。(星空に導かれた探検家のように...)
そのため、2024年に 生成AI (LLM)が Data and Analytics関連のツールや職種に及ぼす影響は、上記の3つの本当の問題に対する根本的な解決策を提示するのではなく、データツールのユーザビリティやデータを扱う人の生産性の向上にとどまる可能性が高いです。ただ、来年のこの時期にも同じような主張ができるかは分かりません。
生成AIが「仕事としての」データ分析業務に及ぼす影響
データ分析に伴うサブタスク(データセットへのアクセス、分析的推論、レポート作成など)は不便で難しいものです。同じような文脈で誰がやっても同じような手順で処理できるのであれば、そのタスクは自動化されるのが当然です。
LLMのような生成型AI技術が「仕事としての」データ分析の自動化にもたらす変化を、データ分析タスク、データ活用ツール、データ職種の観点から見てみましょう。
以下は、MDS (Modern Data Stack)と呼ばれる、真面目にデータを活用する企業が通常備えているデータインフラとツールをいくつかの段階に区分して図式化したものです。
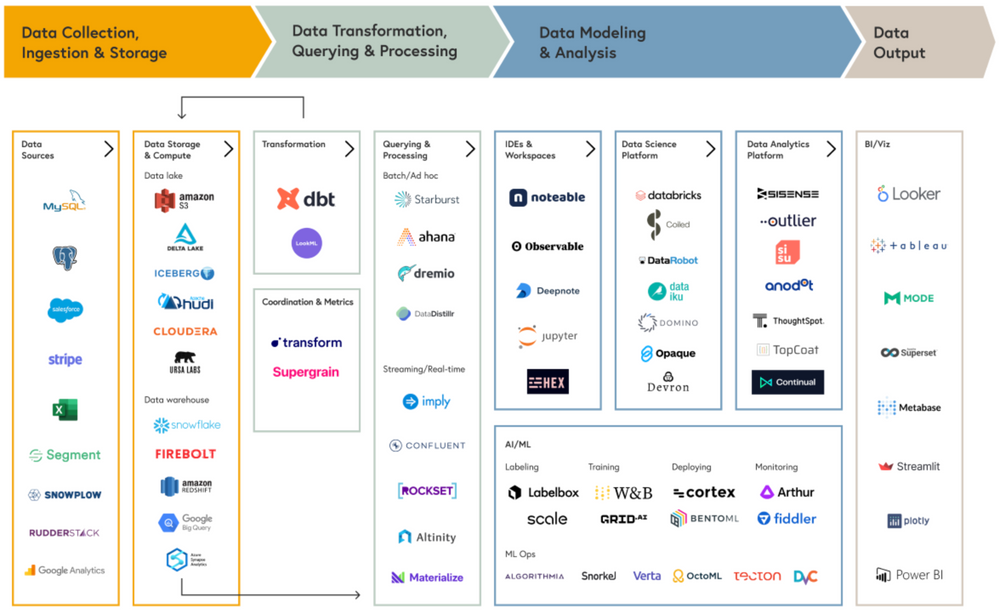
図の一番左側に位置する Data Engineerが主に行うデータ収集/保存から加工/変換段階から始まり、Data Scientistが行うモデリング段階、Data Analystの主な役割であるデータ分析/報告段階から構成されます。そして、実務者は Data(BI) Analystが実装したBIやデータセットを通じてデータを消費することになります。
ほとんどのData Analyst、Data Scientist、Data Engineer、Analytics Engineerは、ChatGPTのような生成型AI技術とツールを使用して自分の業務に実質的な変化を経験していません。LLMを通じてデータ分析の新世界を経験したのは、残念ながら、ストリーマーや講師などコンテンツビジネスをする人たちだけのようです。
開発者(software engineer)たちが Github Copilotを使って実質的なコーディング生産性の向上を経験しているのに対し、同様に code (SQL、R、Python)を扱うデータ職種の従事者やデータツールを使う実務者たちが新しい技術の恩恵を受けられないのはなぜでしょうか?
データ分析、コンテキスト、コードは緊密に結びついている
その理由は、ほとんどのアプリケーションコードはロジックのみで構成され、データとは密接にリンクされていない(code and data decoupling)ため、コーディング目的/意図が与えられる場合には関連するコードを生成することが比較的容易だからです。
一方、データに関連するコーディングはコードが実行されるデータセットの構造とコンテキストを考慮しなければ、適切なコード生成ができません。データ分析は context (DB schema、data catalogue、dataset semantics)とコードが密接に連動しているため、データセットの structure と semantics に対する理解がなければ、分析目的/意図が与えられる場合にデータ分析関連のコードを自動で生成することに大きな制約が生じます。
それでも、1~2年以内に言語の天才 LLMの活躍を期待できる分析作業は Text Analytics、Text-to-SQL程度だと思います。期待とは異なり LLMが実質的な価値を提供するのが難しい分野は Data Engineering と Data Reportingの業務です。以下でそれぞれについて説明します。
LLMがすぐに使える分析作業: Text Analytics、TTS
Text Analytics: テキスト分析が難しかった理由は、avg (売上)は誰でも合意された方法で確定的に行うことができますが、avg (顧客意見)はそうすることができなかったからです。実務者がテキストデータに含まれる主要なトピックや肯定/否定的な感情などを理解し、文書を要約するのに使用する適切な技術とツールがなかった状況で、LLMが使えそうな解決策になっているようです。
以下は、朝鮮の最後の皇女に関する映画「徳恵王女」のレビューテキストとそのテキストを持って chatGPTを利用して分析してみた内容です。なかなかいい感じですね。(元のデータは映画評価が一緒に含まれていましたが、評価が含まれているデータを使用した場合、否定的な評価を探す場合に内容より評価に重点を置いて文章を探すことになるという問題があり、以下の例では、映画評価を削除したデータを使用しました)。

もちろん、tf-idfのような形態素の頻度(frequency)を中心に行うテキスト分析は依然として伝統的な統計分析方式を使用しなければなりませんが、実務者が センチメント や コンセプトを基準に文章を分類したり、セマンティックを考慮した キーワード/トピック抽出などの業務を行う上で、chatGPTが既存のツールが提供できなかった価値(高速かつ高品質の成果物)を提供できると思います。
Text-to-SQL: LLMを活用して自然言語の質問をSQLに置き変えてくれる TTS (Text-to-SQL)の場合、HEARTCOUNTでも、昨年、関連する機能を商用リリースしたことがあります。ただし、機能には明らかな制約があります。
企業内にTTSを導入するためには、セキュリティ(権限管理、Self-Hosted LLM)、内部の セマンティックレイヤーとの連動(RAG)、コスト/パフォーマンス管理を含む LLMOpsなど、少なくはない努力が必要なのも事実です。(そのためか、まだ成功した企業導入事例を聞いたことがありません)。
TTSは コードと コンテキストが密接に結合されている(上で言及した)特性のため、開発者が githubの copilotを使用してコーディングの生産性を高める方法と同様に、Data EngineerのSQLの生産性を高めてくれる可能性は大きくないように思います。
このような制限にもかかわらず、私が LLMを活用した TTSの有用性を慎重に予想する理由は、実務者のデータアクセスに関する問題を相当部分解決してくれると信じているためです。
実務者が頻繁に要求するデータセットを事前に編成して準備しておくことは可能です(dataset curation)。しかし、実際の現場で発生するすべての質問(ad-hoc questions)に対応するデータセットをあらかじめ用意しておくことは物理的に不可能です。
データアクセスの民主化のため、制御されたスキーマ(例えば、売上関連の トランザクションテーブルと関連する ディメンジョンテーブルで構成)内では、簡単な メタデータ (テーブル、項目定義)と プロンプトエンジニアリングを通じて、実務者が望むデータセットを抽出することが現在の技術でも可能です。(弊社の企業顧客の中でその有用な機能を使用している実務者がいます)。
ただし、TTSをうまく使うためには、実務者が生成されたSQLの構造と文法を検証できるスキルが依然として必要です。

LLMがすぐに役に立たない分析作業: データエンジニアリング、データレポーティング
Data Engineering: データクレンジング、前処理に関連するルーチン的な作業が自動化され、データを扱う仕事をする人々がより戦略的で価値の高い仕事に集中できるようになるという期待と予測には共感しにくいです。データを活用しやすく処理することが難しいのは、関連技術とツールの不在によって引き起こされた問題ではなく、企業内で標準化された方法で生成、保存されていないアップストリームアプリケーションの生データ(raw data)を標準化し、確定的な方法で組み合わせて分析しやすい形や構造に加工してくれる自動化技術が存在しにくいためです。
もちろん、データが収集、保存、加工された コンテキストを メタデータ、カタログ、セマンティックレイヤー、ナレッジグラフなどの形で管理することは、現在の技術でも十分に可能です。ただしデータコンテキストをを 生成AIが活用できるレベルにして維持するためにかかる全社的な努力(data contract参照)などを考慮したROIを検討する必要があります。
Data Reporting: データレポートの作成にもLLMは現時点ではあまり役に立たないようです。「データレポートを書くための有効な方法」というタイトルの別のブログでも説明したように、分析に必要な質問が私に与えられた場合、関連するデータセットを持って質問に対する定量的事実と関連のグラフ、そして私の見解から構成されたレポートを作成しなければなりません。
この作業で言語的な能力が必要な分野は以下の3つです。
- 分析的推論の過程で、現在与えられている分析の文脈の後に尋ねる質問を生成する。
- 与えられたグラフから重要で注目すべき定量的事実を作成する。
- 定量的事実を総合(synthesis)して結論(見解)を追加する。
この3つの作業のうち、2024年2月現在でLLMの有用性を判断すると、
- 教科書的な質問の提示はできるものの、与えられたデータで答えられる質問とそうでない質問とを区別することがうまくできません。
- 画像としてのグラフの解釈は苦手ですが、グラフを構成する データテーブルに存在する内容をある程度正確に読み取ることはできます。
- 三人称でもっともらしい言葉ではなく、ビジネスの現実を示し、組織の新しい知識生産に貢献できる言葉は、あなただけが発言でき、あなたが発言を行わなければなりません。
分析的推論作業を必要とする質問は、ほとんどの場合、自社の主要な指標の変化に関連する Why? How? という質問であり、関連するデータセットが与えられた場合にアナリストが行う分析的推論作業は、ある程度標準化できる mechanicalな作業に近いと思います。 LLM技術がなくても、分析的推論作業は自動化することができ、当社は HEARTCOUNT Dialogue という機能を通じて関連する努力を行っています。
生成AIが Analytics and BIツールに与える影響
BIとAnalyticsツールにあった過去の大きな変化をまず見てみましょう。
- 20世紀末と21世紀に入ってからの最初の変化の波は、レポート開発者がSQLを使わずにレポートを作成できるようにすることでした。SAP Business Objects、IBM Cognosがこの市場をリードしました。
- 10年以上前に起こった2番目の変化は、データアナリストがスプレッドシート、データキューブ、データウェアハウスの中に閉じ込められていたデータをより自由に視覚化できるようにするツールの発明でした。Tableau、Qlik、Power BIがその市場をリードしました。
- 約7~8年前に始まった3番目の変化は、拡張分析(Augmented Analytics)であり、自然言語インターフェースを介したデータ分析、パターン発見の自動化により、困難なデータ分析タスクを自動化しようとする最初の試みでした。自然言語ベースのクエリ(NLQ)を前面に押し出した ThoughtSpot、弊社が開発した HEARTCOUNTのような新製品が市場に登場し、Tableauのような既存プレイヤーも買収により Ask Dataのような機能をリリースし、変化に対応しようとしました。
- これらと同じ時期に「Modern Data Stack」というSQLベースのクラウドデータプラットフォームに関連する一種の コンセプト/ミームが生まれ、現在まで流行しており、MDSの哲学を本質的に具現化した代表的なデータツールとして Lookerが一時流行しましたが、大勢を変えることはできませんでした。
そして、今私たちが目撃している変化の波は、LLMの言語能力を活用した分析の民主化と自動化です。インタラクティブな分析による分析の民主化、データの質問への回答の自動化による生産性の向上が標榜されている主な価値であり、Microsoft Copilot for Power BI、Google Duet AI for Looker、Tableau Pulse、HEARTCOUNT Dialogueなどが世間の注目を集めています。(はい、弊社製品も少し入れました)。
データ活用ツール(BI and Analytics)に生成AIを組み込むことに関連する話は、HEARTCOUNTチームのGudabinが作成した記事に詳しく説明されていますので、参考にしてください。
生成AIがデータ職種に及ぼした(及ぼす)影響
2010年初頭まで、データチームの構造は単純明快でした。データアナリストはダッシュボードと分析レポートを作成し、データサイエンティスト(通常は修士・博士号)は複雑な予測/レコメンドモデルを作成しました。データエンジニアはデータアナリストとサイエンティストが必要とするデータを供給する役割を担っていました。
しかし、2012年にデータサイエンティストが「21世紀で最もセクシーな職業」と(誤って)宣言されたことで、状況が急変しました。 一部の企業は慌ててデータアナリストをデータサイエンティストにリブランディングし始めました(一部の企業は既存の データサイエンティストと区別するために データサイエンティストを リサーチサイエンティストと呼んだこともありました)。
2019年頃には、analytics engineerというデータアナリストとデータエンジニアの間に位置する職種が、 データサイエンティストに代わる最も有望なデータ職種として位置づけられました。
AIの人気が再び高まり、2024年にはデータに関連する役割にAIの単語が含まれる可能性があります。AI リサーチャー、AI エンジニアなど。Chief Data Officers (CDOs)や Chief Data and Analytics Officers (CDAOs)と呼ばれていた人たちが、Chief AI Officers (CAIOs)として位置づけているのも、このような流れを反映しているようです。
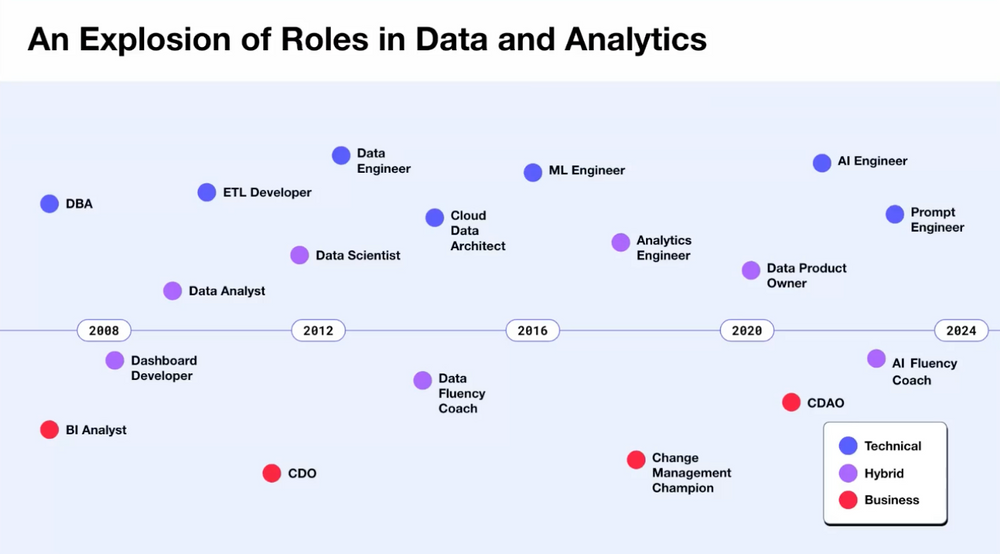
2024年のデータチーム、データエンジニア、アナリストの役割
データチーム: ある程度の規模の会社であれば、すでに 生成AIのプロジェクトを開始しています。伝統的にデータチームがAI研究を主導してきましたが、生成AIプロジェクトの場合、データチームが無条件にOwnershipを持つことは望ましくありません。 いくつかの場合では、生成AIプロジェクトは Foundational Modelが提供する APIや OSS Modelと連動した開発 フレームワーク (LangChainなど)を活用する開発プロジェクトと似ています。このような場合、データチームは補助的な役割に満足しなければならないかもしれません。
データエンジニア: RAG、VectorDBなどを学習し、新しくやるべきことが追加されましたね。内部データとLLMとを連携させる必要がある 生成AIプロジェクトではデータエンジニアは重要で代替不可能な役割を果たすことになるでしょう。
データアナリスト: 将来の職業について専門家が何と言おうと、企業は、過去にもそうであったように、今後も意思決定者が与えられた現象と問題を診断し、企業を取り巻く現実をより精巧に理解して改善策を提示する人を必要としています。データアナリストは今日も明日も重要な人材です。
参考資料
Gartnerの Data and Analytics業界や技術に対する予測内容について興味のある方は、以下の添付のpdf文書を参照してください。
LLMの因果的推論能力について知りたい方は以下を参照してください。