1. Those eager to grasp the latest trends and developments in the 2024 Data & Analytics market.
2. Individuals curious about how Generative AI will reshape the data analysis landscape.
I remember reading in a book that humans have three distinct abilities: thinking, wanting, and feeling. Now, it seems that thinking is no longer exclusively a human ability. If we consider language-expressed thoughts as a means to rationalize our primal and vague feelings, then there might be advantages to a mechanistic mode of reasoning devoid of emotion.
I've attempted to share my thoughts and feelings about the changes that Generative AI technology will bring to products and people dealing with "Data and Analytics," albeit in inadequate sentences. Under the somewhat naive assumption that Generative AI technology will evolve linearly, I've glimpsed into the year 2024.
Judging solely by the year 2023, it seems that generative AI hasn't significantly altered "task-oriented" data analysis. I use the term "task-oriented" data analysis because analyzing data within a company is a very purpose-driven activity. And that purpose is none other than "knowledge production" (it should be).
Baseline Model and Baseline Shift
When we utilize data for crucial decision-making within a company, there are two things we should (must) do:
- Firstly, we need to compare and refine our understanding (mental model) of our business's structure (the variables constituting metrics - such as customer characteristics, product features, sales regions/time slots - and the controllable factors influencing these metrics) with the structure of our business as depicted in the data. This involves accurately and intricately crafting knowledge (baseline model) about the reality/solidity surrounding our business.
- Secondly, we observe the trends of key metrics in the business and monitor changes. When there are changes in metrics, we must determine whether these changes are due to random fluctuations (noise) or if there are fundamental changes in the internal/external environment surrounding the business, leading to the establishment of a new reality (baseline shift). In the event of a paradigm shift, it becomes paramount to comprehensively grasp the modified structure, dynamics, and causal relationships. This entails updating our foundational understanding (baseline mental model) and recalibrating strategic, tactical, and operational decisions to align with the new reality.
Certainly, there are limitations to how far a refined baseline model derived from data can guide us. While it can inform us that changing the button color from mustard yellow to primrose yellow increased the conversion rate by 0.1%, it won't reveal other potential game-changing possibilities (like a golden button). This realm still belongs to intuition, and whether machines can acquire this ability, or if it remains exclusive to humans, only time will tell.
Ultimately, from a practitioner's perspective, when we talk about utilizing data as a task, the only significant issue is to inspire decision-makers with insights into the structure, order, and causal links of our business, contributing to knowledge production. It's about creating moments like "Now, I See It!" or "Ah, so that's how it's done!"
The Reason Data Doesn't Inspire and Generate Knowledge
However, the reason we still struggle to produce knowledge through data, despite having the ability to understand language in existing data tools or lacking in the coding skills of data analysts/practitioners, is not likely due to those factors.
Here are three reasons why data doesn't serve as a source of inspiration and knowledge, along with clues to solutions:
- Difficulty distinguishing between questions that should be asked and those that shouldn't: When there's fluctuation in metrics due to random noise, there's nothing new to be learned by searching for the cause of the fluctuation in the data. Tools and algorithms should distinguish between noteworthy changes and those that aren't, akin to not being distracted by a chart that wiggles like a scribble drawn by a three-year-old. (I'll address my thoughts on algorithms for distinguishing signal and noise in a separate blog.)
- The laborious task of accessing datasets relevant to questions: While technological and procedural obstacles to accessing data can serve as convenient excuses for not answering questions with data, the frustrating reality remains unchanged. Text-to-SQL could be a solution to democratize data access. (Refer to the Text-to-SQL section.)
- Given datasets, reaching the knack of knowledge production: The fact that the situation of "not knowing what to do" isn't solved by educating people on data literacy is a testament to the past decade. This needs to be addressed through the invention of new tools that provide experiences of solving problems with data. Intelligent data tools should suggest the analytical inference process in the context of given questions and unfold the entirety of patterns/orders that datasets can reveal. With this, practitioners can select and integrate patterns appropriately to create "knowledge-laden" data reports. (Like an explorer guided by starlight...)
So, in 2024, the impact of Generative AI (LLM) on tools and professions related to Data and Analytics seems more likely to focus on improving usability and productivity for handling data, rather than providing fundamental solutions to the three aforementioned real problems. However, whether the same argument can be made this time next year remains uncertain.
Impact of GenAI on "Task-Oriented" Data Analysis
The subtasks involved in data analysis (dataset access, analytical inference, report writing, etc.) are inconvenient and challenging. If anyone can handle the same task in a similar procedure in similar contexts, automation of that task is imperative.
Let's examine the changes Generative AI technologies like LLM will bring to the automation of "task-oriented" data analysis from the perspectives of data analysis tasks, data utilization tools, and data professions.
Below is a schematic representation of the data infrastructure and tools commonly possessed by companies seriously utilizing data, segmented into several stages, referred to as the Modern Data Stack (MDS).
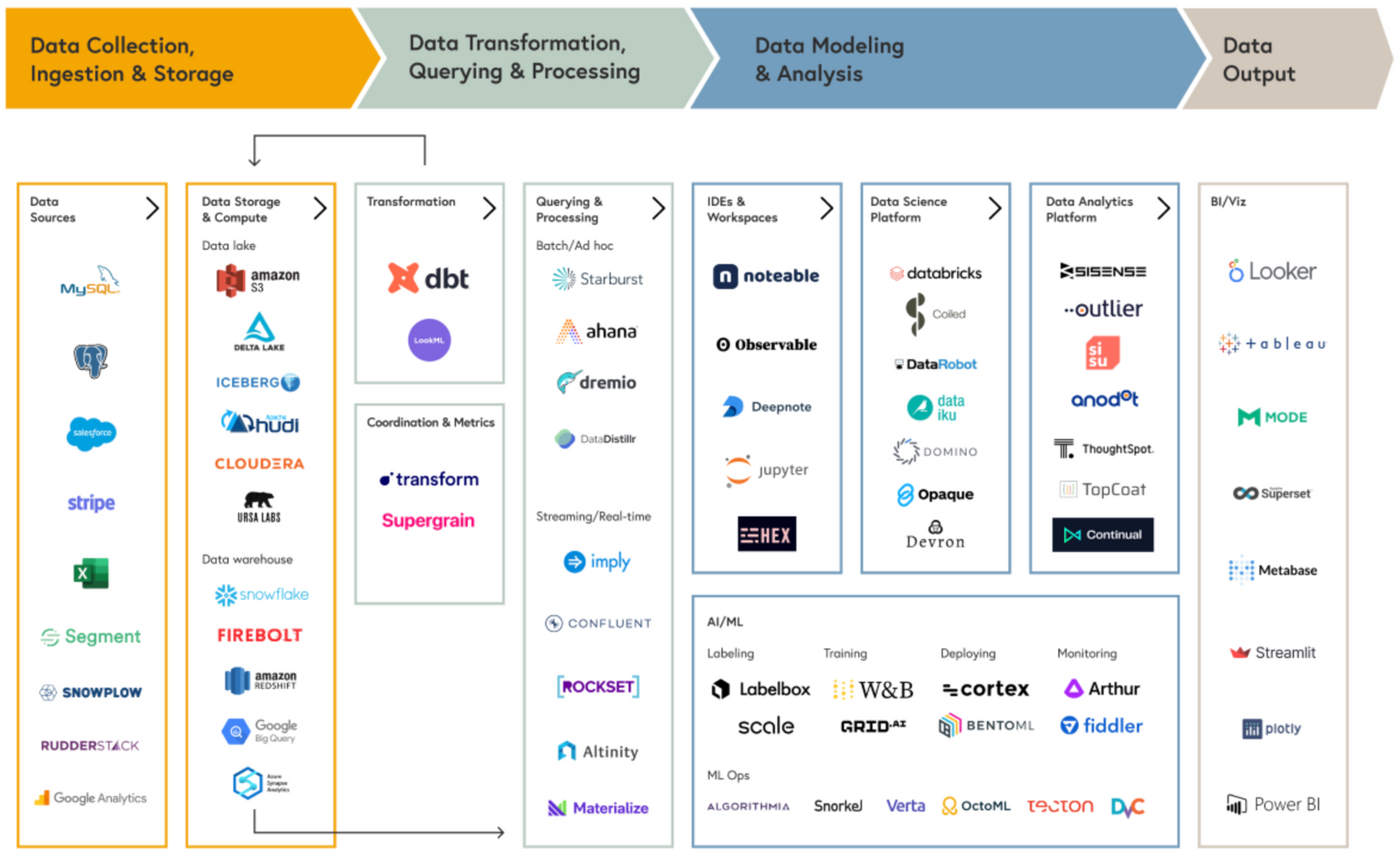
Starting from data collection/storage, which Data Engineers primarily perform, to processing/transformation, modeling performed by Data Scientists, and the key role of data analysis/reporting by Data Analysts, it is structured. In practice, practitioners consume data through BI or datasets implemented by Data (BI) Analysts.
Most Data Analysts, Data Scientists, Data Engineers, and Analytics Engineers have not experienced significant changes in their work using generative AI technologies and tools like ChatGPT. It is unfortunately apparent that only streamers, instructors, and content creators seem to have experienced the new world of data analysis through LLM.
While developers are experiencing improved coding productivity using GitHub Copilot, data professionals handling code (SQL, R, Python) or using data tools do not seem to enjoy the benefits of new technologies. What is the reason for this?
Data Analytics, Context, and Code Are Tightly Coupled
The reason is that most application code is composed only of logic and is closely connected to data (code and data decoupling), making it relatively easy to generate related code when given coding purposes/intentions.
On the other hand, coding related to data cannot be properly generated without considering the structure and context of the dataset on which the code is executed. Since data analysis is closely intertwined with context (DB schema, data catalog, dataset semantics), generating data analysis-related code automatically when given analysis purposes/intentions without understanding the structure and semantics of the dataset will have significant constraints.
Nevertheless, if there are analysis tasks that are expected to benefit from the prowess of the language genius LLM within the next 1-2 years, I would think of Text Analytics and Text-to-SQL. Contrary to expectations, areas where LLM struggles to provide practical value are Data Engineering and Data Reporting tasks. Let's examine each below.
Useful Analysis Tasks Using LLM: Text Analytics, Text-to-SQL
Text Analytics: The reason text analysis was difficult is that while avg(sales) can be performed deterministically in a universally agreed manner, avg(customer opinions) could not. LLM seems to be a viable solution in situations where practitioners lacked appropriate technologies and tools to understand the main topics and sentiments (positive/negative) contained in text data and to summarize documents.
Below is the analysis of movie reviews for the movie "The Last Princess" based on review texts using ChatGPT. It's quite impressive. (The original data included movie ratings, but using data with ratings posed a problem where the focus shifted more towards ratings rather than the content when trying to find negative evaluations. Therefore, in the example below, data without ratings was used.)


Certainly, traditional text analysis based on metrics like tf-idf focusing on the frequency of morphemes still requires traditional statistical analysis methods. However, in tasks such as classifying sentences based on sentiment or concepts, or extracting keywords/topics considering semantics, chatGPT can provide value (fast speed and high-quality results) that conventional tools cannot.
Text-to-SQL: In the case of Text-to-SQL, which uses LLM to convert natural language questions into SQL, HEARTCOUNT also launched a related feature last year. However, the feature has clear constraints.
To adopt TTS within the enterprise, considerations such as security (permission management, Self-Hosted LLM), integration with internal semantics layer (RAG), and cost/performance management including LLMOps require considerable effort. (Perhaps that's why successful enterprise adoption cases have not been heard of yet.)
Due to the (mentioned above) characteristic of code and context being closely coupled, similar to how developers use GitHub's copilot to increase coding productivity, it seems unlikely that data engineers' SQL productivity will be significantly increased using new technologies.
Despite these limitations, I cautiously speculate about the usefulness of TTS using LLM because it can solve a significant portion of the data access problems encountered by practitioners.
Practitioners can prepare datasets frequently requested by practitioners in advance (dataset curation). However, preparing datasets for all ad-hoc questions that arise in real-world situations is physically impossible.
For democratizing data access, within controlled schemas (e.g., composed of sales-related transaction tables and related dimension tables), it is possible with current technology to extract datasets that practitioners want using simple meta data (table, column descriptions) and prompt engineering. (Some of our corporate customers are using this feature effectively.)
However, to use TTS effectively, practitioners will still need skills to validate the structure and syntax of the generated SQL.

Useless Analysis Tasks Using LLM: Data Engineering, Data Reporting
Data Engineering: It is difficult to empathize with the expectation and prediction that routine tasks related to data cleansing and preprocessing being automated will allow those who handle data to focus more strategically on high-value tasks. The difficulty in handling data for analysis is not so much a problem caused by the absence of related technologies and tools but rather because of the raw data of upstream applications not standardized and processed into a shape and structure suitable for analysis by combining them in a standardized manner.
Of course, managing data context in the form of metadata, catalog, semantic layer, knowledge graph, etc., is entirely feasible with current technology. However, it should be considered whether the ROI of comprehensive efforts (considering data contract) to make data context usable at the level that genAI can utilize is justified.
Data Reporting: LLM does not seem to have significant utility for writing data reports at the moment. As mentioned in a separate blog titled "[To write good data reports]," if I am given questions that require analysis, I need to write reports consisting of quantitative facts related to the questions, relevant charts, and my opinions.
The linguistic skills needed in this task are roughly the following three:
- Generating questions to ask next after the analytical inference process
- Generating key and noteworthy quantitative facts from given charts
- Synthesizing quantitative facts to add conclusions (opinions)
As of February 2024, when assessing the usefulness of LLM for these three tasks,
- It can suggest textbook-like questions, but it cannot distinguish well between questions that can be answered with the given data and those that cannot.
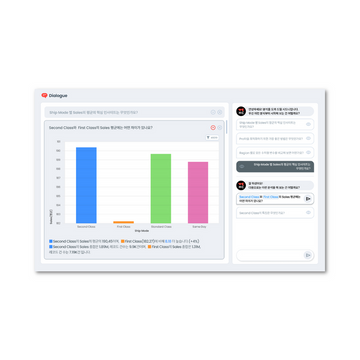
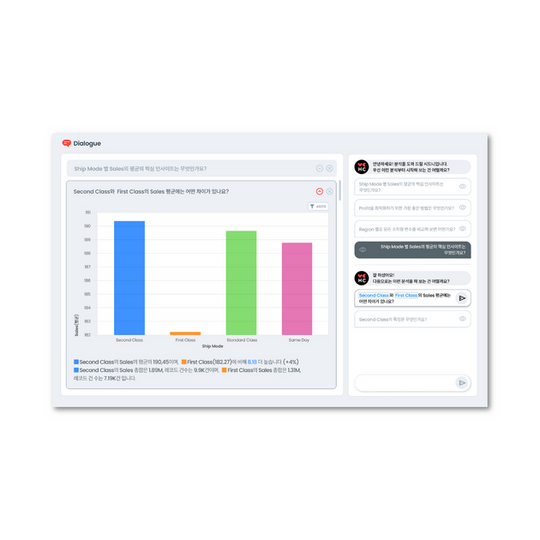
- It cannot interpret charts as images well, but it can read the content in the data table that constitutes the chart somewhat accurately.
- Rather than sounding plausible in the third person, it is only you who can show the reality of your business and contribute to the production of new knowledge in your organization, and it is you who must do it.
Most of the questions requiring analytical inference are relatively easy, such as why? and how? questions related to changes in our company's key metrics. I think the analytical inference tasks that analysts do when given the relevant dataset can be somewhat standardized and mechanical tasks that can be automated even without LLM technology, and our company is focusing on related efforts through the HEARTCOUNT Dialogue feature.
Impact of GenAI on Analytics and BI Tools
First, let's examine the significant changes in BI and Analytics tools in the past.
- The first wave of change, spanning the late 20th and early 21st centuries, allowed report developers to create reports without using SQL. SAP Business Objects and IBM Cognos led this market.
- About a decade ago, the second wave of change allowed data analysts to visualize data more freely from spreadsheets, data cubes, and data warehouses. Tableau, Qlik, and Power BI led this market.
- The third wave of change, which started roughly 7-8 years ago, was augmented analytics, the first attempt to automate difficult data analysis tasks through natural language interfaces and pattern discovery. New products such as ThoughtSpot, which emphasized natural language-based queries (NLQ), were released, and existing players like Tableau also released features like Ask Data through acquisitions to adapt to the change.
- At around the same time, the concept/meme of "Modern Data Stack," a SQL-based cloud data platform, emerged and has been trending ever since. Although Looker, a tool that embodies the philosophy of MDS, briefly gained popularity, it did not change the trend.
The current wave of change we are witnessing is the democratization and automation of analysis using LLM's language capabilities. Conversational analysis and automation of data question-answer pairs are touted as the main values, and products like Microsoft Copilot for Power BI, Google Duet AI for Looker, Tableau Pulse, and HEARTCOUNT Dialogue are garnering attention. (Yes, we also inserted our product subtly.)
Regarding the story of integrating GenAI with Data Utilization Tools (BI and Analytics), please refer to the article written by David of the HeartCount team for more detailed explanations.
GenAI's Impact on Data Roles
As recently as the early 2010s, the structure of data teams was straightforward. Data analysts created dashboards and analysis reports, and data scientists (usually with master's or doctoral degrees) created complex predictive/recommendation models. Data engineers supplied the data needed by data analysts and scientists.
However, around 2012, when data scientists were declared (wrongly) as the "sexiest job of the 21st century," the situation changed rapidly. Some companies began rebranding data analysts as data scientists in a hurry. (Some companies even called data scientists research scientists to distinguish them from existing data scientists.)
Around 2019, analytics engineers, a role positioned between data analysts and data engineers, emerged as the most promising data role to replace data scientists.
With the resurgence of AI's popularity, by 2024, AI-related terms are likely to be included in roles related to data. AI researchers, AI engineers, etc. The fact that people who were called Chief Data Officers (CDOs) or Chief Data and Analytics Officers (CDAOs) are positioning themselves as Chief AI Officers (CAIOs) also reflects this trend.
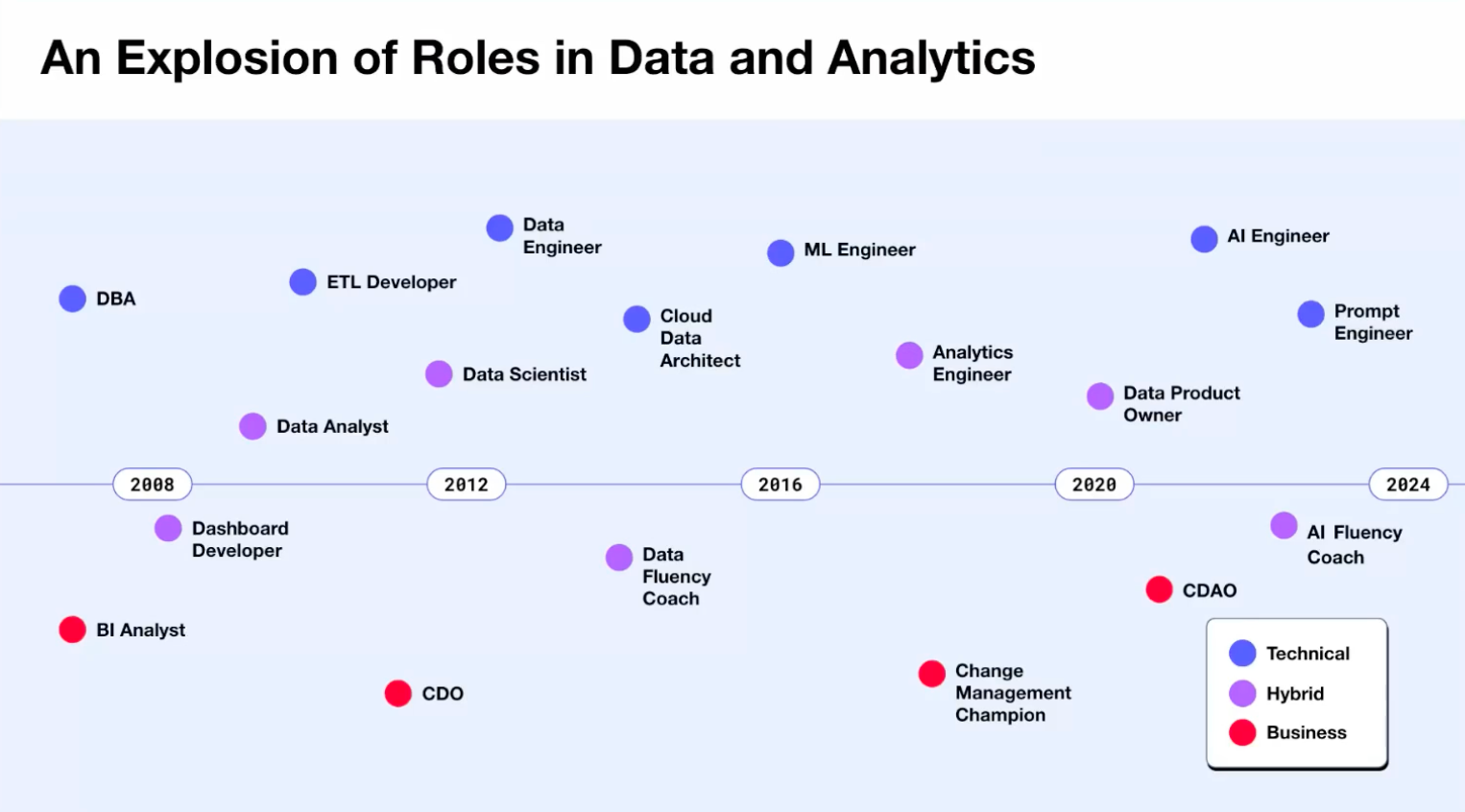
Data Team, Data Engineer, and Analyst Roles in 2024
Data Team: If a company of reasonable size has already started a GenAI (generative AI) project. Traditionally, data teams have led AI research, but in the case of GenAI projects, it may not be desirable for data teams to have ownership unconditionally. In many cases, GenAI projects resemble development projects that utilize API provided by the Foundational Model or open-source model and development frameworks (e.g., langchain). In such cases, the data team may have to be satisfied with a supportive role.
Data Engineer: RAG, VectorDB, and additional things to learn and do have been added. In GenAI projects that require integrating internal data with LLM, data engineers will play important, irreplaceable roles.
Data Analyst: Regardless of what the soothsayers say about future jobs, companies will still need people who can diagnose given phenomena and problems, understand the intricacies of the reality surrounding the company, and suggest improvements. Data analysts are still important today and tomorrow.
References
If you are curious about Gartner's predictions for the data and analytics industry and technology, please refer to the attached PDF document.
- Gartner's Predictions for 2024: Data & Analytics
- Gartner's over 100 data and analytics predictions
If you are interested in LLM's causal inference capabilities, please refer to the following:


If you have any questions related to the content of this article, please contact sidney.yang@idk2.co.kr.
Log in now with your Google account to try it out.