
변하지 않는 것, 계속 변하는 것
본 블로그와 웨비나(아래 VOD 영상 참고)에서는 ChatGPT 같은 GenAI(LLM)를 활용한 데이터 분석 도구들을 살펴보며, '실무자들이 주어진 질문에 데이터로 답하는 일에 이런 도구들이 당장 얼마나 도움이될 수 있을까' 라는 질문에 답해 보도록 하겠습니다.
변화를 좇기보다 "앞으로 10년 동안 변하지 않을 것"에 집중해서 사업 전략을 세우라는 제프 베조스의 이야기는 잘 알려져 있습니다. 기업의 실무자들도 바뀌지 않을 비지니스 문제에 새로운 기술을 어떻게 생산적으로 활용할 수 있을까 라는 문제의식을 가지고 LLM과 같은 신기술을 바라보면 좋겠습니다.

데이터로 풀어야 하는 비지니스 문제
앞으로 10년 동안 변하지 않을 데이터로 풀어야 하는 비지니스 문제 중 하나는 실무자들이 주체적으로 데이터에 접근하고 지표 개선을 위한 지식을 생산하는 일입니다. 아래 그림처럼 질문과 관련된 데이터에 주체적으로 접근하고, 데이터가 답할 수 있는 최선의 답을 찾아 보고서에 담는 일, 이 두가지가 해결되어야 합니다.
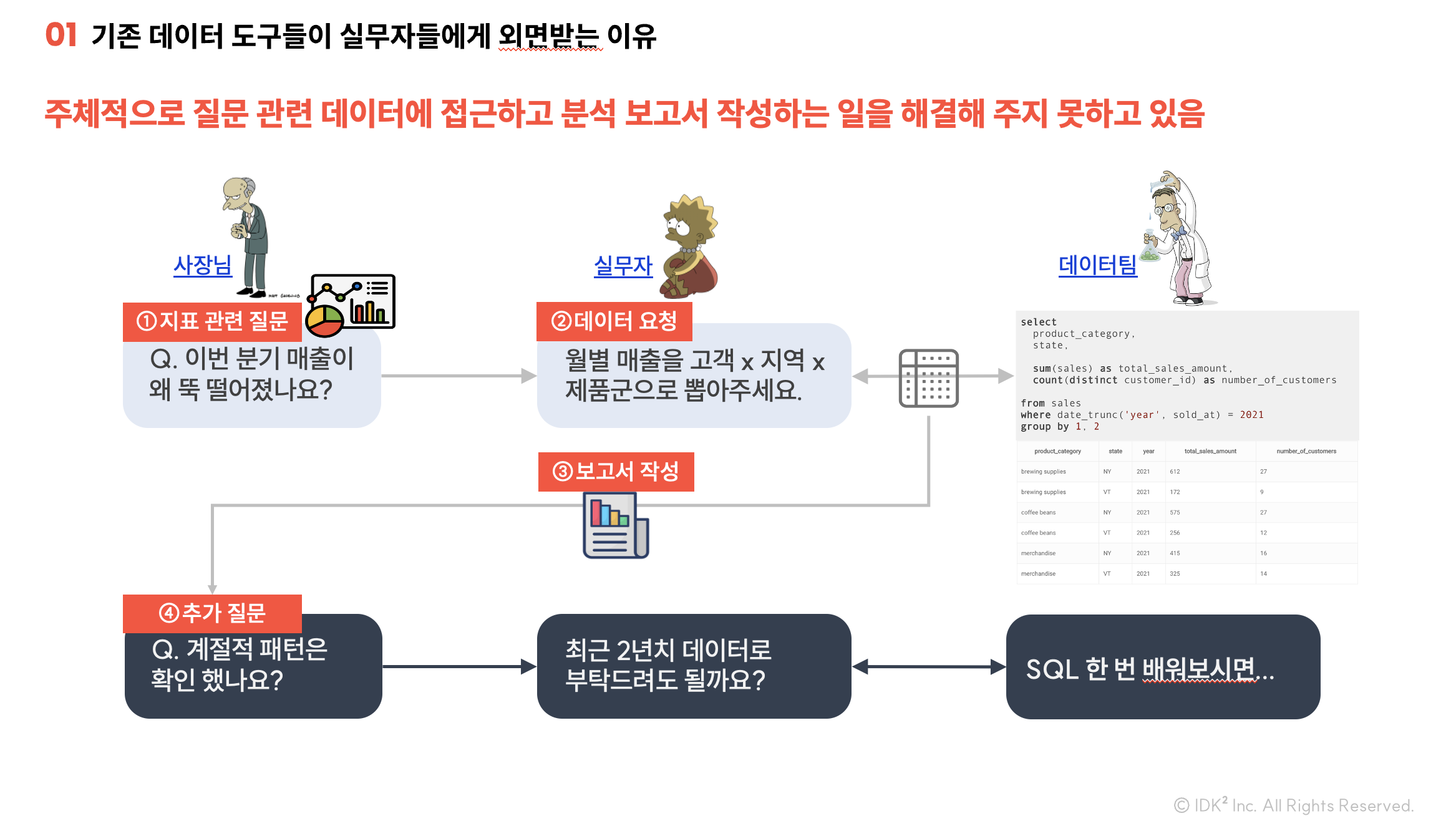
데이터로 지식 생산하는 일의 비생산성
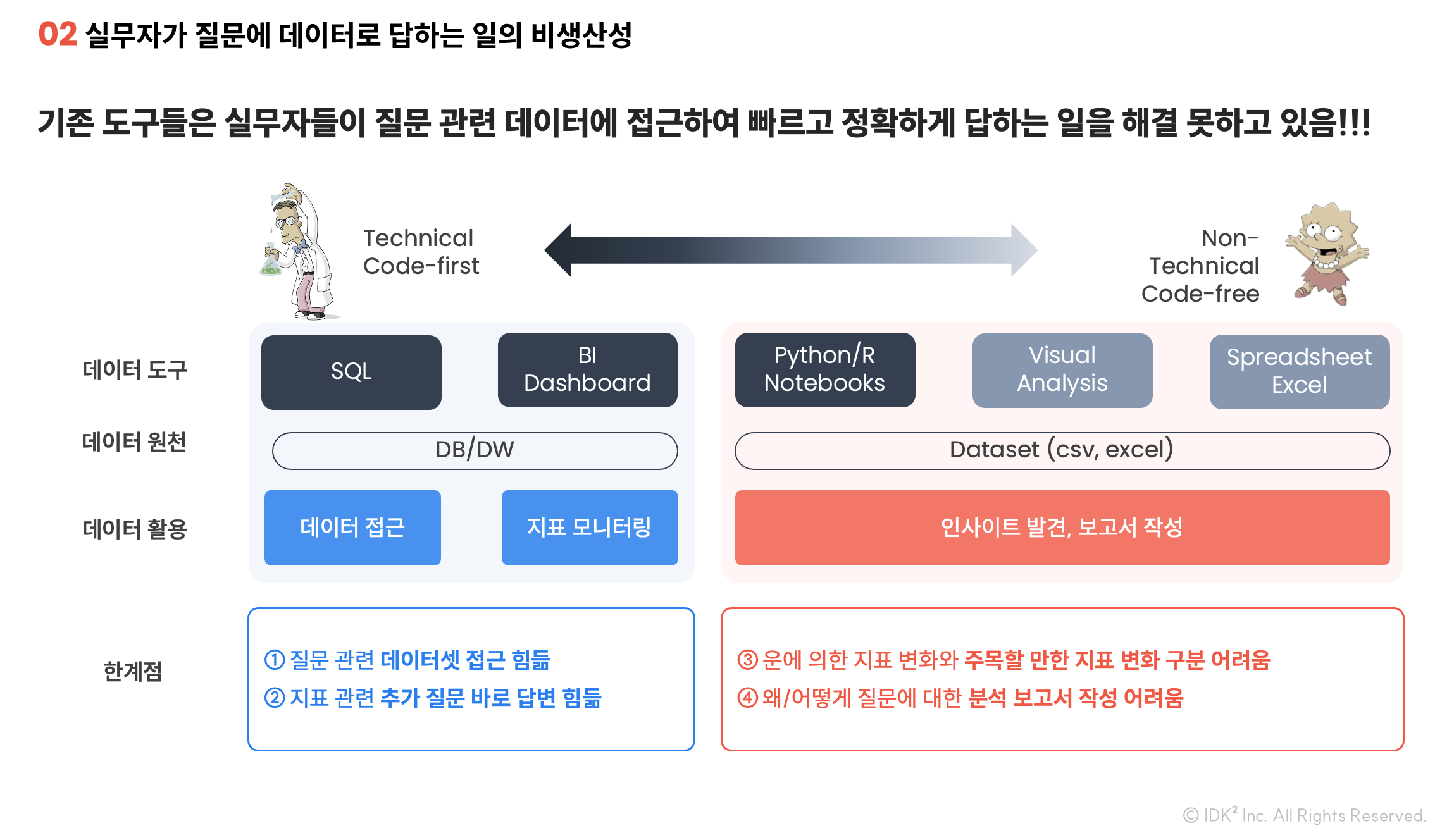
데이터 도구는 날것의 데이터를 비지니스 문제 해결에 활용하는 일의 생산성을 높이기 위해 존재합니다. 아래 그림은 데이터 활용과 소비(질문에 데이터로 답변, 지식/보고서 생산) 측면에서 주요 데이터 도구들과 각 도구의 역할과 한계에 대해 도식화한 내용입니다.
BI/대시보드 도구를 "code-first"쪽에 위치시킨 이유는 대시보드를 수동적으로 소비하는 것이 아니라 직접 생산하기 위해서는 여전히 DB 구조와 SQL과 같은 언어에 대한 이해가 필요하기 때문입니다.
Machine Learning, AI, Data Landscape
데이터와 관련된 기술, 도구 생태계에 대해 가장 폭넓은 연간 보고서를 꾸준히 작성하고 있는 Matt Turck의 2024년 보고서에서 실무자를 데이터 활용도구와 관련된 내용만 간단히 옮기면 이렇습니다. (전문은 아래 링크 참고)
- 통상 BI(Business Intelligence) and Analytics로 일컬어지는 데이터 활용/소비 도구는 혁신이 정체되어 왔다. 그 주된 이유는 마이크로소프트, 세일즈포스 등 BI 시장을 과점하고 있는 Big Tech 기업들이 본인들의 주력 사업(클라우드)이나 제품(CRM) 판매에 BI를 끼워파는 행태를 보이고 있기 때문이다.
- 생성형 AI를 통해 BI and Analytics 도구 시장에 혁신이 올 수도 있겠다. 자연어 인터페이스가 잘 구현된다면 "데이터 민주화"가 가능하기 때문이다. 다만, 비지니스 언어와 데이터 언어(SQL) 간의 불통을 해결하는 일의 어려움 때문에 회의론이 존재한다.
 Jeff Evernham
Jeff Evernham
LLM과 데이터 분석의 자동화
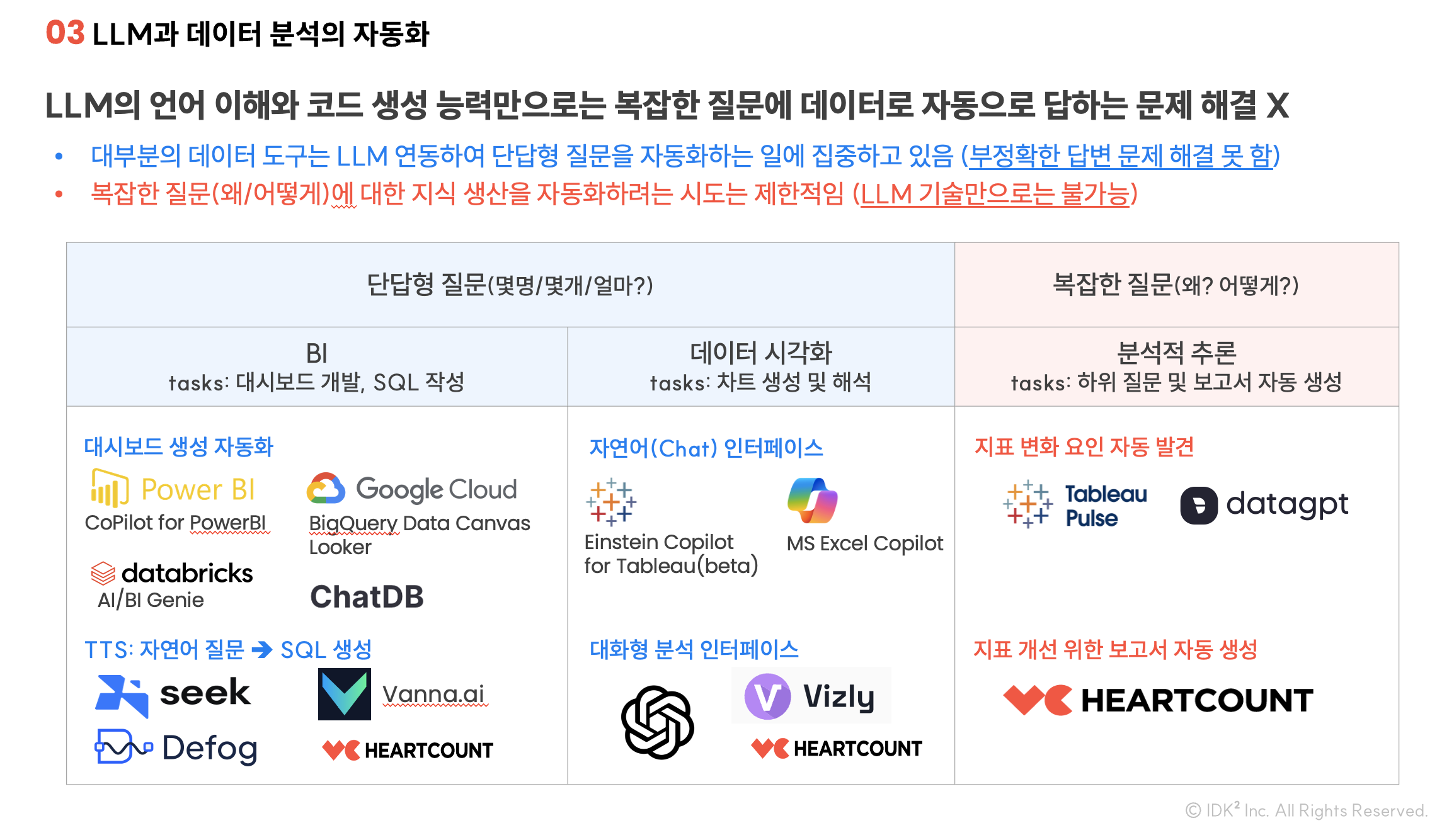
실무자에게 데이터 분석이란 지표와 관련한 그때 그때의 질문(ad-hoc questions)에 답변하는 일입니다. 그리고 질문에는 두가지 유형이 있습니다.
- 정답이 딱 정해져 있는 질문(몇개, 몇명?): 답변의 속도와 정확성(Accuracy)이 중요
- 하나의 올바른 정답이 없는 질문(왜, 어떻게?): 답변의 쓸모(Insight), 지식 생산이 중요
아래 표를 보면 데이터 도구들의 LLM 연동 노력이 정답이 정해져 있는 질문에 답하는 영역에 집중되어 있는 것을 확인할 수 있습니다. 분석적 추론이 필요한 복잡한 질문에 대한 답변 자동화 영역은 아직 그 시도나 성과가 제한적입니다.
아래 표의 각 영역별 주요 툴들에 대한 보다 자세한 소개는 관련 웨비나 영상과 아래 "LLM을 활용한 데이터 도구 비교 시연" 섹션을 참고해 주세요.
당신을 위한 데이터 도구의 재발명
당신을 위한 도구라지만, 당신을 위한 적이 없는 실무자를 위한 데이터 도구 시장에 당신의 일손을 덜어줄 똑똑한 데이터 도구가 하루 빨리 나오길 기대합니다.
자동차가, 엘리베이터가 발명되었지만 걷는 일이 사라지지 않았습니다. 지식 노동자들이 데이터에 기반하여 지식 생산하는 일을 자동화하는 작업은 이제 막 그 첫걸음을 떼었습니다. 데이터 분석과 활용과 관련된 하위 작업들 중 어디까지가 자동화의 영역이고 어디까지가 인간 고유의 영역일지는 시간이 말해 주겠지요.
당장은 지표 관련 질문에 데이터에 담긴 최선의 답변을 자동으로 발견해 기업 실무자들이 주체적으로 데이터를 활용할 수 있도록 돕는 도구의 탄생을 기대해봄직 합니다. 실무자들이 애쓰지않고 데이터에서 쓸모있는 패턴을 발견하도록 도와주는 데이터 도고, 하트카운트도 계속 관심을 가지고 지켜봐 주세요.
LLM 활용 데이터 도구 비교 시연
아래는 관련 웨비나(동영상 참고)에서 시연한 내용입니다. 세가지 Task(데이터 접근, EDA탐험 분석, 보고서 작성 업무)별로 시연을 했으며 시연에 사용한 데이터셋과 도구, 그리고 질문들이 아래에 정리되어 있습니다. 시연 내용은 아래 VOD 영상에서 확인해 보실 수 있습니다.
1. 데이터 접근/확보
- 데이터셋: 매출 DB
- 질문: 언제부터 언제까지 주/월별로 (지표)를 차원1, 차원2로 뽑아줘
- 데이터 도구: Defog vs. HEARTCOUNT
defog - sales DB
Who are the top 5 ticker seller? show the result table with seller name and ticket count and total amount?
Sport fan buys more ticket than others?
Do sport fans purchase more tickets than other buyers?
HEARTCOUNT - adventureworks DB
판매수익은 주문수량*제품가격이야. 판매수익이 높은 국가 6개 알려줘
판매건수 대비 취소건수가 높은 제품명과 취소 비율 알려줘
==> ::numeric / ::float
판매건수 대비 취소건수가 높은 제품명과 취소 비율 알려줘. 취소비율은 소수점 2째자리까지 보여줘
2. EDA
- 데이터셋: Superstore 데이터셋
- 질문: 단답형 질문, EDA(descriptive analysis), 요인(회귀분석)
- 데이터 도구: ChatGPT vs. HEARTCOUNT
- Ref. https://www.kaggle.com/datasets/vivek468/superstore-dataset-final/code?datasetId=1940216&sortBy=voteCount
EDA 질문 리스트
- Y:숫자, X:범주-요약: 지역별 매출 총합을 차트와 요약 테이블로 보여줘
- Y:숫자, X:범주-분포: 지역별 매출 분포를 차트로 시각화 해줘. 아웃라이어에 대한 정보도 알려줘
>> 한글패치: koreanize_matplotlib-0.1.1-py3-none-any.whl - Y:숫자, X:시간-추이
- 주문일에 따른 매출 추이를 보여줘
- 시간 interval을 월로 해서 다시 표현해줘
- 제품대분류로 구분해서 다시 그려줄래?
(하나의 올바른 정답이 없는 질문)
- 2014년 10월 매출이 9월 대비 급감했는데 그 주된 요인이 뭐니?
- 다른 모든 범주형 변수(소분류, 지역, 고객분류 등)와 변수 두개의 조합을 사용해서 매출이 급감한 이유 찾아 줄래? - Y:숫자, X:숫자: 상관관계
- 이익과 매출 간의 상관관계를 scatterplot으로 그린 후 상관계수를 알려줘 - 요인 분석(회귀분석)
- 이익 변수와 다른 모든 변수에 대해 선형회귀분석을 수행한 다음 결정계수가 가장 높은 순으로 테이블로 정리해서 알려주세요.
번외) 간단한 데이터 모델링
- 데이터셋: 타이타닉
- 질문: 생존/사망 분류 규칙(모형) 생성
- 데이터 도구: ChatGPT vs HEARTCOUNT
분류 모형 질문
- survived 변수로 트리모형(decision tree)을 사용해서 생존자와 사망자를 분류하는 classification 모형 만들어 주세요.
- 트리모형에 있는 생존자 규칙들을 가장 정확도가 높은 것들 중심으로 재현률과 함께 알려주세요.
- 트리 모형 전체를 분류 규칙과 함께 시각화 해주세요.
- 각 분류 규칙을 규칙과 precision과 recall이 포함된 테이블 형식으로 보여주세요.
3. 보고서/지식 생성
- 데이터셋: 슈퍼스토어 매출 데이터셋
- 질문: 왜? 어떻게? 지표(메트릭)가 왜 올랐나요/떨어졌나요?
- 시연 (2014년 10월 매출이 (9월 대비) 급감한 이유)
- 데이터 도구: HEARTCOUNT vs. Vizly
지표 변동 요인 질문
- 월별 매출 총합 추이 알려주세요
2014년 10월에 2014년 9월 대비 매출이 급감했는데, 급감한 원인을 알려주세요. - 제품별 매출 분석을 진행해 주세요.
- "지역" 변수를 써서 매출 차이가 가장 컸던 조건을 알려주소서
- 매출 총합 추이가 증가세에서 하락세로 전환된 조건 알려주세요.
지금까지 함께 ChatGPT 같은 GenAI(LLM)를 활용한 데이터 분석 도구들을 함께 살펴보며 당장의 활용 가능성과 한계를 짚어 보았습니다. 당신을 위한 도구라지만, 당신을 위한 적이 없는 실무자를 위한 데이터 도구 시장에 당신의 일손을 덜어줄 똑똑한 데이터 도구가 하루 빨리 나오길 기대합니다.

![[Monthly Webinar VOD] AI 데이터 분석, 어디까지 왔니? 다섯가지 툴 비교해보기](/ko/content/images/size/w360/2024/08/7---_---------------------1080_1080.png)



![[Monthly Webinar VOD] AI 데이터 분석, 어디까지 왔니? 다섯가지 툴 비교해보기](/ko/content/images/size/w540/2024/08/7---_---------------------1080_1080.png)
![[Monthly Webinar VOD] 2024 Data & AI 트렌드 분석](/ko/content/images/size/w540/2024/02/---------------------1080_1080.png)
{kind=link}