
1. 2024년, Data & Analytics 시장의 전체적인 흐름과 최신 트렌드를 파악하고자 하는 분들
2. 생성형 AI가 데이터 분석 업무를 어떻게 바꿀지 궁금한 분들
인간만의 세가지 능력이 사유(thinking), 의지(wanting), 느낌(feeling)이라고 어떤 책에서 읽은 기억이 납니다. 이제 사유가 더 이상 인간만의 능력이 아닌 것도 같습니다. 언어로 표현된 생각이 우리의 원초적이고 희미한 느낌을 합리화하기 위한 수단이라고 생각하면, 감정이 배제된 기계적 사유 방식만의 장점이 있을 것도 같습니다.
GenAI 기술이 "Data and Analytics"을 다루는 제품과 사람들에게 가져올 변화에 대해 느끼고 생각했던 것들을 공유하고자 부족한 문장으로 정리해 보았습니다. 가급적 덜 틀린 예상을 하기 위해 GenAI 기술이 선형적으로 발전할 거라는 다소 순진한 가정 하에 2024 올 한해를 조망하였습니다.
2023년 한 해만 놓고 판단하면 생성형 AI가 "일로서의" 데이터 분석을 크게 바꾼 게 없어 보입니다. 제가 "일로서의" 데이터 분석이라고 한정 지은 이유는 기업 내에서 업무로서 데이터를 분석하는 것은 매우 목적 지향적인 행위이기 때문입니다. 그리고, 그 목적은 다름 아닌 "지식 생산"입니다(이어야 합니다).
Baseline Model과 Baseline Shift
우리가 기업 내 주요 의사결정에 데이터를 활용할 때 (해야) 하는 일은 아래 두가지입니다.
- 우선, 데이터로 내가 이해하고 있는(mental model) 내 사업의 구조(지표를 구성하고 있는 변수들 - 고객특성, 상품특성, 판매 지역/시간대 등 - 의 기여도와 지표에 영향을 주는 통제할 수 있는 요인들에 대한 인과적 고리)와 데이터에 담긴 내 사업의 구조와 인과적 고리를 비교하며 내 사업을 둘러싼 현실/실재에 대한 지식(baseline model)을 정확하고 정교하게 하는 일이 선행되어야 합니다.
- 그 다음, 사업의 주요 지표들의 추이를 관찰하며 변화(variation)를 모니터링합니다. 지표 변화가 있을 때, 이 변화가 운(noise, randomness)에 의한 우발적인 변화인지 아니면 사업을 둘러싼 내외부 환경에 근본적인 변화가 있어 새로운 실재(reality)가 구축되었는지를 판단해야 합니다. 새로운 실재가 구축되었다면(baseline shift), 변경된 구조와 질서, 인과적 고리를 정량적으로 이해하여 내 지식(baseline mental model)을 업데이트하고 이에 따라 새로운 전략적, 전술적, 운영적 의사결정을 내려야 합니다.
물론, 데이터로 정교해진 baseline model이 우리가 가보지 않은 길, 장소까지 알려주지는 못 한다는 한계가 있습니다. 버튼 색깔을 찐노랑에서 개나리색으로 바꿨더니 전환율이 0.1% 늘었다는 건 알려줄 수 있지만, 더 큰 impact를 가져올 수 있는 다른 가능성들(황금색깔 버튼)에 대해서는 말해주지 않습니다. 이건 여전히 intuition의 영역이고, intuition이 사람만의 천부적 능력인지 기계도 습득할 수 있는 능력일지는 시간이 말해주겠지요.

결국, 실무자 관점에서 일로서 데이터를 활용한다고 했을 때 중요한 단 하나의 문제는 의사결정권자가 좋은 의사결정을 내릴 수 있도록 우리 사업의 구조와 질서, 인과적 고리에 대한 영감(inspiration)과 지식 생산에 이바지하는 것입니다. "이제야 제대로 보이네. Now, I See It!", "이렇게 한 번 해보면 되겠네!"와 같은 순간들을 만들어 내는 것입니다.
데이터가 돈이 되는 영감과 지식의 원천이 되지 못하는 이유
하지만, 우리가 데이터를 매개로 하여 지식생산하는 일을 여전히 잘 못 하고 있는 이유가 기존 데이터 언어/도구의 "언어 이해" 능력이나 데이터 분석가/실무자들의 "코드 생성" 능력의 부족 탓은 아닐 것입니다.
데이터가 돈이 되는 영감과 지식의 원천이 되지 못하는 이유 세가지와 해결방안에 대한 실마리는 이러합니다.
- 데이터에 물어야 마땅한 질문과 그렇지 않은 질문을 구분하는 일의 어려움: baseline의 변화는 없지만 운의 영향으로 지표가 꼼지락거린 경우, 데이터에서 꼼지락한 원인을 찾아 봐야 새롭게 알 수 있는 게 없습니다. 세살짜리 아이가 크레용으로 그린 낙서처럼 꿈틀대는 차트를 보며 일희일비하지 않도록 주목할 변화와 그렇지 않은 변화를 기술과 도구가 구분해 주어야 합니다. (signal과 noise를 구분하는 알고리즘에 대한 제 생각은 별도의 블로그에서 다루도록 하겠습니다.)
- 질문과 관련한 데이터셋에 적시에 접근하는 일의 수고스러움: 데이터 접근과 관련한 기술적, 절차적 난관들이 질문에 데이터로 답하지 않아도 되는 좋은 핑계거리가 될 수는 있지만 답답한 현실이 바뀌지는 않습니다. 데이터 접근의 민주화를 위해, TTS(Text-to-SQL)이 해결책이 될 수 있습니다. (Text-to-SQL 섹션 참고)
- 주어진 데이터셋으로 지식 생산에 이르는 일의 요령부득: 요령부득의 상황이 데이터 문해력 교육으로 해결되지 않는다는 것은 지난 10년의 세월이 잘 웅변해 주고 있습니다. 이건 데이터로 문제가 해결되는 경험을 선사하는 새로운 도구의 발명으로 풀어야 합니다. 똘똘한 데이터 도구가 주어진 질문 맥락에서 분석적 추론의 절차를 제시해 주고, 데이터셋이 알려줄 수 있는 패턴/질서의 총체를 펼쳐 보여줄 수 있다면, 실무자는 패턴을 적절히 선택, 종합하여 "지식이 담긴" 데이터 보고서를 작성하는 것이 가능할 거에요. (별빛에 인도된 탐험가처럼...)
그래서 2024년에 GenAI(LLM)가 Data and Analytics 관련 도구와 직업에 미칠 영향은, 위에 언급한 세가지 진짜 문제에 대한 근본적인 해결책을 제시하기 보다는, 데이터 도구의 사용성이나 데이터를 다루는 사람의 생산성 개선에 그칠 가능성이 커 보입니다. 다만, 내년 이맘 때에도 똑같은 주장을 할 수 있을지는 모르겠습니다.
GenAI가 "일로서의" 데이터 분석 작업에 미칠 영향
데이터 분석에 수반되는 하위 작업들(데이터셋 접근, 분석적 추론, 보고서 작성 등)은 불편하고 어렵습니다. 유사한 맥락에서 누가 하더라도 비슷한 절차로 작업을 처리할 수 있다면 해당 작업은 자동화되는 것이 마땅합니다.
LLM과 같은 생성형 AI 기술이 "일로서의" 데이터 분석 자동화에 미칠 변화를 데이터 분석 작업, 데이터 활용 도구, 데이터 직군 관점에서 살펴 보겠습니다.
아래는 MDS(Modern Data Stack)라고 불리는, 자못 진지하게 데이터를 활용하는 기업들이 통상적으로 구비하고 있는 데이터 infra와 tool들을 몇가지 단계로 구획하여 도식화한 것입니다.
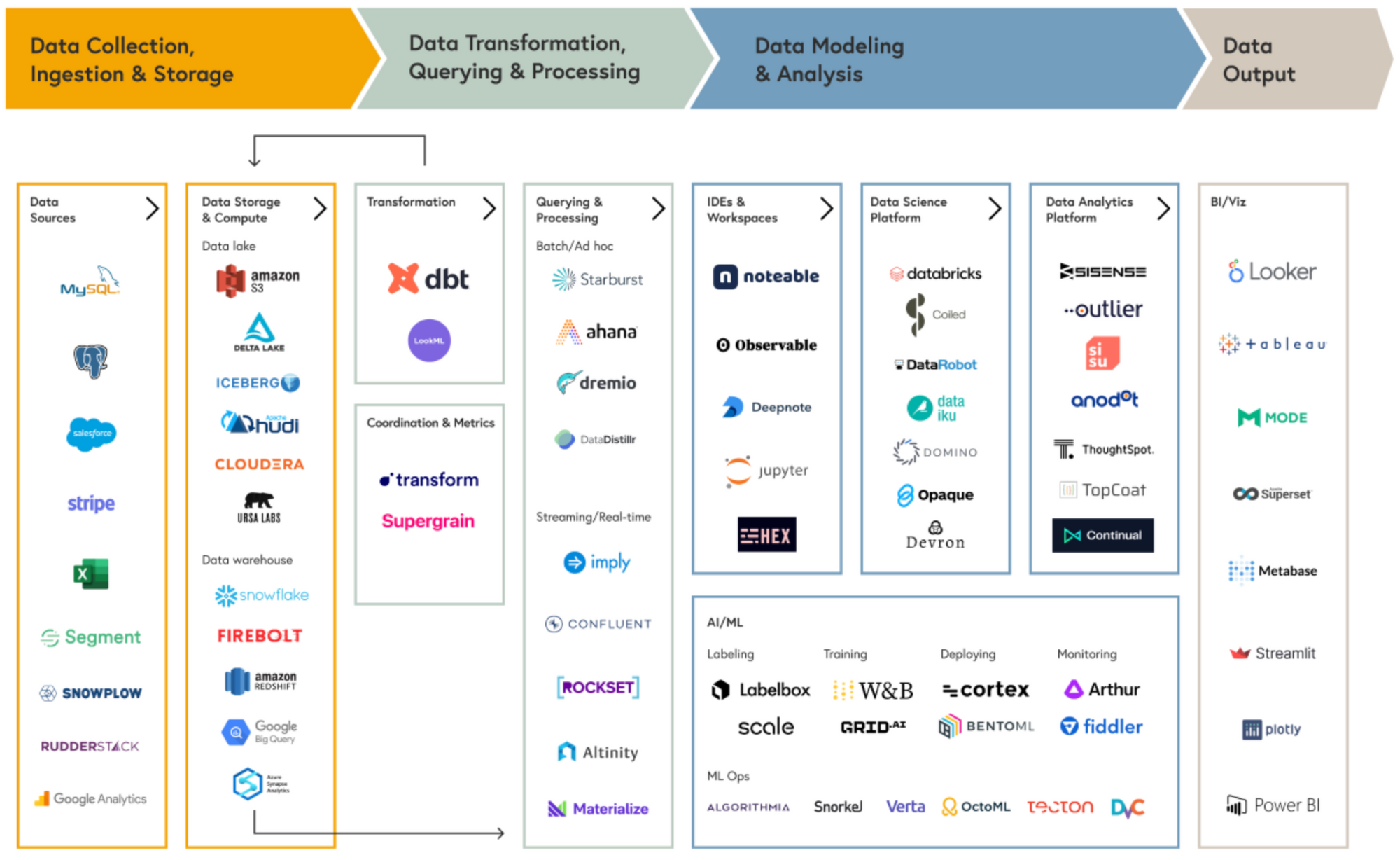
그림의 맨 왼쪽에 위치한 Data Engineer들이 주로 수행하는 데이터 수집/저장부터 가공/변환 단계에서 시작해서 Data Scientist들이 수행하는 모델링 단계, Data Analyst들의 주요 역할인 데이터 분석/보고 단계로 구성됩니다. 그리고, 실무자들은 Data(BI) Analyst가 구현한 BI나 데이터셋을 통해 데이터를 소비하게 되지요.
대부분의 Data Analyst, Data Scientist, Data Engineer, Analytics Engineer들은 ChatGPT와 같은 생성형 AI 기술과 도구를 통해 자신의 업무에 실질적인 변화를 경험하지 못했습니다. LLM을 통해 데이터 분석의 신세계를 경험한 것은 아쉽게도 스트리머나 강사 등 콘텐츠 사업을 하는 사람들뿐인 것 같습니다.
개발자(software engineer)들이 Github Copilot을 사용해서 실질적인 coding 생산성의 향상을 경험하고 있는 것에 반해, 비슷하게 code(SQL, R, Python)를 다루는 데이터 직군 종사자들이나 데이터 도구를 사용하는 실무자들이 새로운 기술의 혜택을 누리지 못하는 이유는 무엇일까요?
Data Analytics, Context and Code Are Tightly Coupled
그 이유는 대부분의 응용 프로그램 코드는 로직으로만 구성되고 데이터와는 밀접하게 연결되어 있지 않기(code and data decoupling) 때문에 coding 목적/의도가 주어졌을 때 관련 code를 생성하는 일이 상대적으로 용이하기 때문입니다.
반면, 데이터와 관련된 coding은 code가 실행되는 데이터셋의 구조와 맥락을 고려하지 않고서는 제대로된 code 생성이 불가능합니다. 데이터 분석은 context(DB schema, data catalogue, dataset semantics)와 code가 밀접하게 맞물려 있기 때문에 데이터셋의 structure와 semantics에 대한 이해 없이는 분석 목적/의도가 주어졌을 때 데이터 분석 관련 code를 자동으로 생성하는 일에 큰 제약이 따르게 됩니다.
그래도 1~2년 이내에 언어 천재 LLM의 활약을 기대해 봄직한 분석 작업들이 있다면 Text Analytics, Text-to-SQL정도라고 생각합니다. 기대와 달리 LLM이 실질적 가치를 제공하기 힘든 영역들은 Data Engineering과 Data Reporting 작업입니다. 아래에서 각각에 대해 살펴보겠습니다.
LLM이 당장 쓸모 있는 분석 작업들 : Text Analytics, TTS
Text Analytics: 텍스트 분석이 어려웠던 이유는 avg(매출)은 누구나 합의된 방식으로 확정적으로 수행할 수 있지만 avg(고객 의견)은 그럴 수 없었기 때문입니다. 실무자들이 텍스트 데이터에 담긴 주요 토픽과 긍/부정 정서 등을 이해하고 문서를 요약하는데 사용할 적절한 기술과 도구가 없었던 상황에서 LLM이 쓸만한 해결책이 되어주고 있는 것 같습니다.
아래는 조선의 마지막 황녀에 대한 영화 "덕혜옹주" 리뷰 텍스트와 해당 텍스트를 가지고 chatGPT를 이용해 분석해 본 내용입니다. 썩 잘하네요. (원본 데이터는 영화평점이 함께 포함되어 있었는데, 평점이 포함된 데이터를 사용한 경우, 부정적 평가를 찾을 때 내용보다 평점에 중심을 두고 문장을 찾게 되는 문제가 있어, 아래 예에서는 영화평점은 제거한 데이터를 사용했습니다.)

물론 tf-idf와 같은 형태소의 빈도(frequency)를 중심으로 수행하는 텍스트 분석은 여전히 전통적인 통계 분석 방식을 사용해야 하겠지만, 실무자들이 sentiment나 concept을 기준으로 문장들을 분류하거나 semantics을 고려한 keyword/topic 추출 등의 업무를 하는데 chatGPT가 기존 툴이 제공할 수 없었던 가치(빠른 속도와 높은 품질의 결과물)를 제공해줄 수 있다고 생각합니다.
Text-to-SQL: LLM을 활용하여 자연어 질문을 SQL로 바꾸어 주는 TTS(Text-to-SQL)의 경우 HEARTCOUNT도 작년에 관련한 기능을 상용 출시한 바 있습니다. 다만, 기능에는 명백한 제약이 따릅니다.
기업 내 TTS 도입을 위해서는 보안(권한 관리, Self-Hosted LLM), 내부 semantics layer와의 연동(RAG), 비용/성능 관리를 포함한 LLMOps 등 적지 않은 노력이 드는 것도 사실입니다. (그래서인지 아직까지 성공적인 기업 도입 사례를 들어보지는 못했습니다.)
TTS는 code와 context가 밀접하게 결합되어 있는 (위에 언급한) 특성으로 인해 개발자들이 github의 copilot을 사용하여 coding 생산성을 높이는 방식과 유사하게 data engineer들의 SQL 생산성을 높여줄 가능성도 크지 않아 보입니다.
이런 한계에도 불구하고, 제가 LLM을 활용한 TTS의 쓸모를 조심스럽게 점치는 이유는 실무자들의 데이터 접근과 관련된 문제를 상당 부분 해결해 줄 수 있다고 믿기 때문입니다.
실무자들이 자주 요청하는 데이터셋을 미리 편성하여 준비해 놓을 수(dataset curation) 있습니다. 하지만, 실무 현장에서 발생하는 그때 그때의 모든 질문들(ad-hoc questions)에 대한 데이터셋을 미리 준비해 놓는 것은 물리적으로 불가능합니다.
데이터 접근의 민주화를 위해, 통제된 스키마(예, 매출 관련 transaction table과 관련 dimension table들로 구성) 내에서는 간단한 meta data(tabe, column descriptions)와 prompt engineering을 통해 실무자가 원하는 데이터셋을 추출하는 것이 현 기술로도 가능합니다. (저희 기업 고객들 중에 유용하게 해당 기능을 사용하고 있는 실무자분들이 있습니다.)
다만, TTS를 잘 사용하려면 실무자가 생성된 SQL의 구조와 문법을 검증할 수 있는 스킬은 여전히 필요하겠습니다.

LLM이 당장 별 쓸모 없는 분석 작업들: 데이터 엔지니어링, 데이터 리포팅
Data Engineering: data cleansing, preprocessing과 관련된 routine한 작업들이 자동화되어 데이터를 다루는 일을 하는 사람들이 보다 전략적이고 가치 높은 일에 집중할 수 있게 될 거란 기대와 예측은 공감하기 어렵습니다. 데이터를 활용하기 좋게 처리하는 일이 어려운 것은 관련 기술과 도구의 부재로 인해 야기된 문제라기 보다는 기업 내에서 표준화된 방식으로 생성, 저장되지 않은 upstream 응용프로그램의 날것의 데이터(raw data)들을 표준화하고 확정적 방식으로 결합하여 분석하기 좋은 모양과 구조로 가공해 줄 자동화 기술이 존재하기 어렵기 때문입니다.
물론, 데이터가 수집, 저장, 가공된 context를 meta data, catalogue, semantic layer, knowledge graph 등의 형태로 관리하는 것은 현재의 기술로도 충분히 가능한 일입니다. 다만, data context를 genAI가 활용할 수 있는 수준으로 만들고 유지하는데 드는 전사적 노력(data contract 참고) 등을 고려한 ROI를 따져 보아야 할 것입니다.
Data Reporting: 데이터 보고서 작성에도 LLM이 당장은 큰 쓸모가 없어 보입니다. [데이터 보고서를 잘 쓰기 위해]란 제목의 별도의 블로그에서도 이야기한 것처럼, 분석이 필요한 질문이 나에게 주어졌다면 관련 데이터셋을 가지고 질문에 대한 정량적 사실과 관련 차트, 그리고 나의 견해로 구성된 보고서를 작성해야 합니다.
이 작업에서 언어적 능력이 필요한 영역은 아래 세가지 정도입니다.
- 분석적 추론 과정에서 현재 주어진 분석 맥락 다음에 물어볼 질문 생성
- 주어진 차트에서 핵심적이고 주목할 만한 정량적 사실 생성
- 정량적 사실들을 종합(synthesis)하여 결론(견해) 추가
이 세가지 작업 중 2024년 2월 현재 LLM의 쓸모를 판단하자면,
- 교과서적인 질문 제시는 할 수 있지만, 주어진 데이터로 답할 수 있는 질문과 그렇지 못 한 질문을 잘 구분하지 못합니다.
- 이미지로서의 차트 해석은 잘 못 하지만 차트를 구성하는 data table에 있는 내용을 어느 정도 정확하게 읽어 줄 수 있습니다.
- 삼인칭으로 그럴듯한 말이 아니라 내 사업의 실재를 보여주고 우리 조직의 새로운 지식 생산에 기여할 수 있는 말은 당신만 할 수 있고 당신이 해야 합니다.
분석적 추론 작업이 필요한 질문은 대부분 우리 회사의 주요 지표 변화와 관련된 왜? 어떻게? 질문이기 쉽고, 관련 데이터셋이 주어졌을 때 분석가가 하는 분석적 추론 작업은 어느 정도 표준화될 수 있는 mechanical 작업에 가깝다고 생각합니다. LLM 기술 없이도 분석적 추론 작업이 자동화될 수 있고 저희 회사는 HEARTCOUNT Dialogue라는 기능을 통해 관련 노력을 기울이고 있습니다.
GenAI가 Analytics and BI 도구에 미칠 영향
BI와 Analytics 도구에 있었던 과거의 큰 변화를 우선 살펴보겠습니다.
- 20세기 말과 21세기 들목에 걸쳐 있던 첫번째 변화의 물결은 보고서 개발자가 SQL을 사용하지 않고 보고서를 만들 수 있게 하는 것이었습니다. SAP Business Objects와 IBM Cognos가 이 시장을 주도했었습니다.
- 10여년 전에 있던 두 번째 변화는 데이터 분석가들이 spreadsheet, data cube, data warehouse 속에 갇혀 있던 데이터를 보다 자유롭게 시각화할 수 있도록 해주는 도구의 발명이었습니다. Tableau, Qlik, Power BI가 해당 시장을 주도했습니다.
- 대략 7~8년 전에 시작된 세 번째 변화는 증강 분석(Augmented Analytics)으로, 자연어 인터페이스를 통한 데이터 분석, 패턴 발견의 자동화를 통해 어려운 데이터 분석 작업을 자동화하려는 최초의 시도였습니다. 자연어 기반 질의(NLQ)를 전면에 내세운 ThoughtSpot, 저희 회사가 만든 HEARTCOUNT 같은 새로운 제품이 시장에 출시되었고 Tableau와 같은 기존 player도 인수를 통해 Ask Data와 같은 기능을 출시하며, 변화에 발맞추고자 하였습니다.
- 이와 비슷한 시기에 "Modern Data Stack"이라는 SQL 기반의 클라우드 데이터 플랫폼과 관련된 일종의 concept/meme이 생겨나 현재까지 유행하고 있고, MDS의 철학을 태생적으로 담은 대표적 데이터 도구로서 Looker가 잠시 유행했지만 대세를 바꾸지는 못 했습니다.
그리고, 지금 우리가 목격하고 있는 변화의 물결은 LLM의 언어 능력을 활용한 분석의 민주화와 자동화입니다. 대화형 분석을 통한 분석의 민주화, 데이터 질문 답변 자동화를 통한 생산성 증가가 표방되고 있는 주된 가치이며, Microsoft Copilot for Power BI, Google Duet AI for Looker, Tableau Pulse, HEARTCOUNT Dialogue 등이 세간의 관심을 받고 있습니다. (네, 저희 제품도 살짝 끼워 넣었네요.)
데이터 활용 도구(BI and Analytics)에 GenAI를 접목하는 것과 관련된 이야기는 하트카운트팀의 구다빈님이 작성하신 글에 더 자세히 설명되어 있으니 참고해 주세요.
GenAI가 데이터 직군에 미친(칠) 영향
2010년 초반만 해도 데이터 팀의 구조는 간단 명료했습니다. 데이터 분석가는 대시보드와 분석 보고서를 작성했고, 데이터 과학자(대개 석박사급)는 복잡한 예측/추천 모델을 만들었습니다. 데이터 엔지니어는 데이터 분석가와 과학자가 필요로 하는 데이터를 공급하는 역할을 했구요.
그러나 2012년에 데이터 과학자가 '21세기에서 가장 섹시한 직업'으로 (잘못) 선언되면서 상황이 급변했습니다. 일부 기업들은 부랴부랴 데이터 분석가를 데이터 과학자로 rebranding하기 시작했습니다. (일부 회사는 기존 data scientist와의 구분을 위해 data scientist를 research scientist로 호명하기도 했었죠.)
2019년 즈음에는 analytics engineer란 데이터 분석가와 데이터 엔지니어 스펙트럼 사이에 위치하는 직군이 data scientist를 대체하는 가장 유망한 데이터 직군으로 자리 잡기도 했습니다.
AI의 인기가 다시 증가하면서, 2024년에는 데이터와 관련된 역할에 AI 단어가 포함될 것도 같습니다. AI researcher, AI engineer 등등. Chief Data Officers(CDOs)나 Chief Data and Analytics Officers(CDAOs)로 불리던 사람들이 스스로를 Chief AI Officers(CAIOs)로 positioning하고 있는 것도 이런 흐름의 반영으로 보입니다.
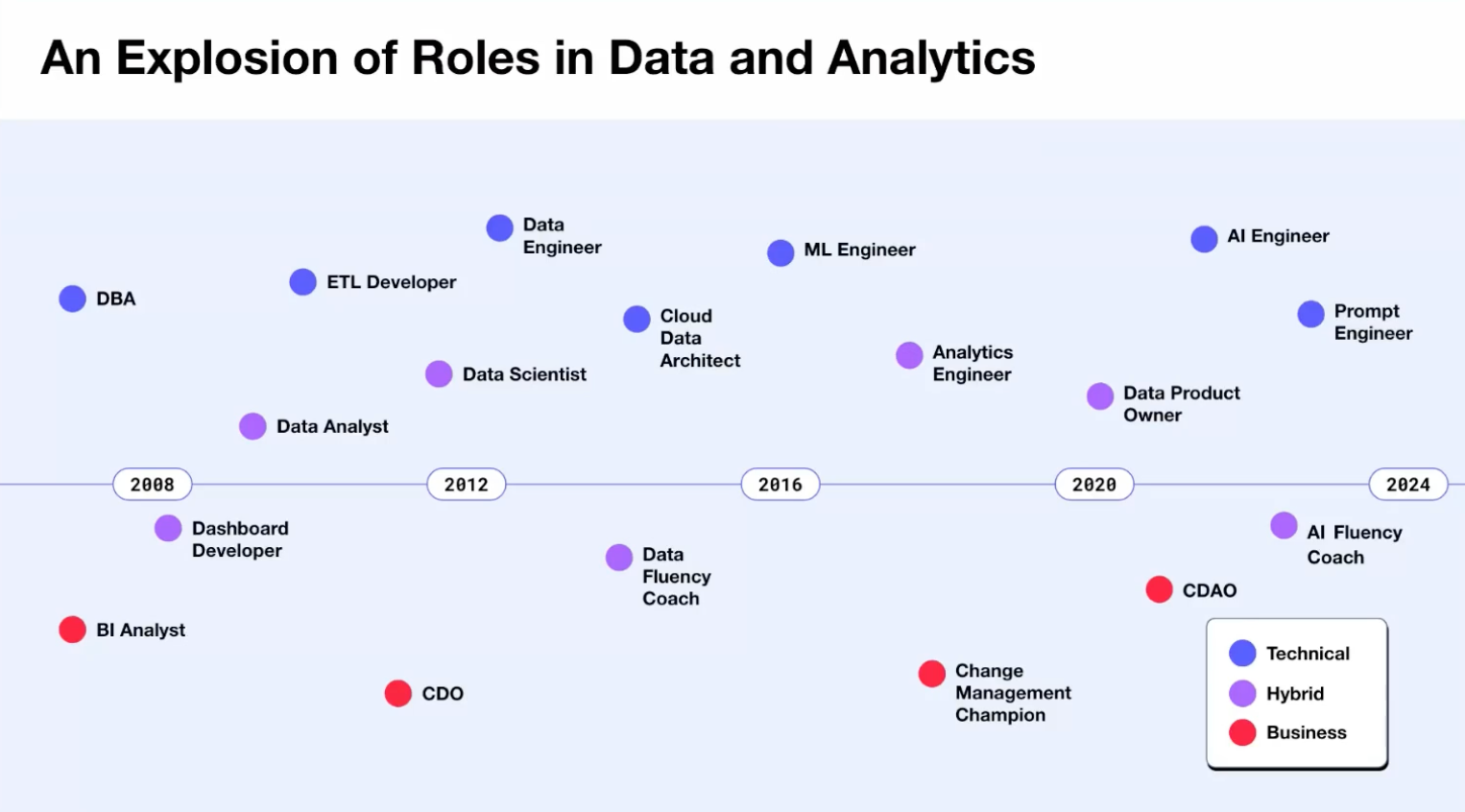
데이터 팀, 데이터 엔지니어, 분석가의 역할 in 2024
데이터 팀: 어지간한 규모의 회사면 이미 GenAI(생성형 AI) 프로젝트를 시작했습니다. 전통적으로 데이터 팀이 AI 연구를 주도해 왔지만, GenAI 프로젝트의 경우 데이터 팀이 무조건 Ownership을 갖는 것이 바람직해 보이지 않습니다. 적지 않은 경우, GenAI 프로젝트는 Foundational Model에서 제공하는 API나 OSS Model과 연동된 개발 framework(langchain 등)를 활용하는 개발 프로젝트와 유사합니다. 이런 경우, 데이터팀은 보조적인 역할에 만족해야 할 수도 있겠네요.
데이터 엔지니어: RAG, VectorDB 등 배우고 새로 해야 할 일이 추가 되었네요. 내부 데이터와 LLM을 연동해야 하는 GenAI 프로젝트에서 데이터 엔지니어들은 중요한, 대체 불가능한 역할을 하게 될 것입니다.
데이터 분석가: 미래의 직업에 대해 호사가들이 뭐라 하든 기업은, 과거에도 그랬듯이 앞으로도, 의사결정권자들이 주어진 현상과 문제를 진단하고 기업을 둘러싼 실재를 더 정교하고 이해하여 개선책을 제시할 사람을 필요로 합니다. 데이터 분석가는 오늘도 그리고 내일도 여전히 중요한 사람입니다.
참고 자료
Gartner의 Data and Analytics 산업과 기술에 대한 예측 내용이 궁금하시다면 아래 첨부 pdf 문서를 참고해 주세요.
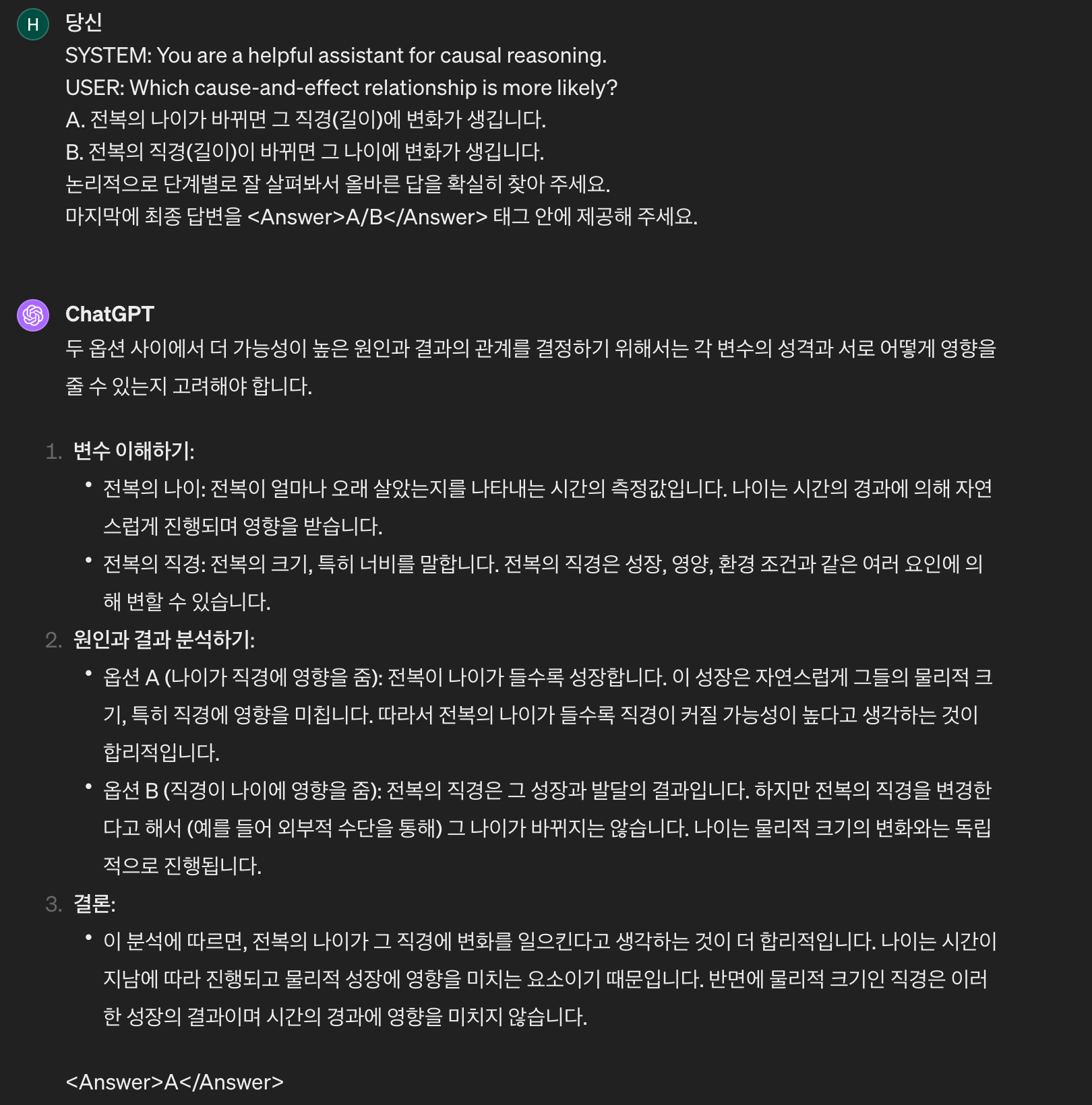
LLM의 인과적 추론 능력에 대해 알고 싶으시다면 아래를 참고해 주세요.
본 글의 내용과 관련해서 문의주실 게 있으면 sidney.yang@idk2.co.kr로 연락주세요.
지금 구글 계정으로 로그인하여 사용해 보세요.

