바야흐로 대(大) AI의 시대입니다. ChatGPT를 필두로 한 초거대언어모델(Large Language Model, 이하 LLM)의 등장은 거의 모든 산업군의 소프트웨어에 LLM이 적용되는 흐름을 만들어냈으며, 이제는 LLM이 도입되지 않은 제품을 찾기조차 어려울 정도입니다.
특히 데이터 분석 분야에서는 LLM이 불러온 파급력과 함께 시장의 판도가 크게 변화하고 있습니다(이에 대해서는 이전에 한 차례 소개드린 바 있습니다). 평균을 내고, 총합을 계산하고, T검정을 수행하고, 간단한 시각화를 하는 등 전통적인 데이터 분석 작업은 이제 ChatGPT에 데이터만 올리면 자동으로 코드 작성부터 계산까지 손쉽게 처리됩니다.
이처럼 누구나 몇 문장의 명령어만으로 분석을 실행할 수 있는 시대가 되면서, ‘데이터 분석을 위해 굳이 통계학처럼 어려운 학문을 배워야 할까?’라는 회의가 점점 확산되고 있습니다. 기업 입장에서도 이제는 고가의 분석 도구나 전문 인력을 채용할 필요가 없다고 판단하는 경우가 많아지고 있습니다.
하지만 여기에는 중요한 오해가 하나 있습니다. 많은 사람들이 '통계'를 단순히 평균이나 검정을 계산하는 기법으로만 인식하지만, 통계학의 본질은 수치를 넘어 세상을 이해하는 사고의 틀, '통계적 사고(Statistical Thinking)'에 있습니다.
1부. 통계적 사고의 본질과 역할
통계적 사고(Statistical Thinking): 세상의 불확실성을 이해하는 틀
통계적 사고는 다음과 같이 간단히 요약할 수 있습니다.
- 세상의 대부분의 현상은 불확실성 아래에 있다는 사실을 전제하며 (error term)
- 그 불확실성 속에서도 체계적인 관찰과 추론을 통해 의미 있는 패턴과 원인을 식별할 수 있다고 믿으며 (pattern recognition)
- 어떤 수치가 나왔는지를 넘어서, 왜 그런 수치가 나왔는지를 끊임없이 질문하는 사고 방식입니다.
쉽게 말해, 통계적 사고는 데이터의 표면을 읽는 데 그치지 않고, 그 이면의 맥락과 구조를 추론하려는 태도입니다. 예를 들어, 한 마케팅 캠페인 이후 매출이 증가했다면, 단순히 "매출이 늘었다"는 결과에 만족하지 않고, “정말 이 캠페인이 원인이었을까?”, “다른 외부 요인은 없었을까?”, “같은 결과가 다른 시점에도 반복될까?” 같은 질문을 던지는 것이 통계적 사고입니다. 이는 단순히 데이터 분석가라는 전문 직종만의 일이 아니라, 엑셀 수준에서라도 숫자를 들여다보는 모든 산업군의 모든 사람의 고민일 것입니다.
오늘날처럼 LLM이 분석 코드도 짜주고, 복잡한 모델도 자동으로 만들어주는 시대일수록 오히려 그 결과가 의미하는 바를 해석하고 판단하는 통계적 사고의 중요성은 더 커진다고 할 수 있습니다. 아무리 뛰어난 AI라 해도, 그 결과를 해석하고 활용하는 주체는 결국 사람이며, 그 사람에게 필요한 것은 통계 기술이 아니라 바로 이 사고방식입니다.
조금 더 자세히 알아보겠습니다. 통계학자들은 이 복잡한 세상의 구조를 설명하기 위해, 놀랍도록 단순하면서도 강력한 하나의 수식을 제안했습니다. 중학교 수학 수준의 함수 개념만 알아도 이해할 수 있는 이 수식은, 통계적 사고의 핵심을 응축한 상징과도 같습니다.
Y = f(X) + e : 세상의 현상은 패턴과 불확실성으로 이루어진다
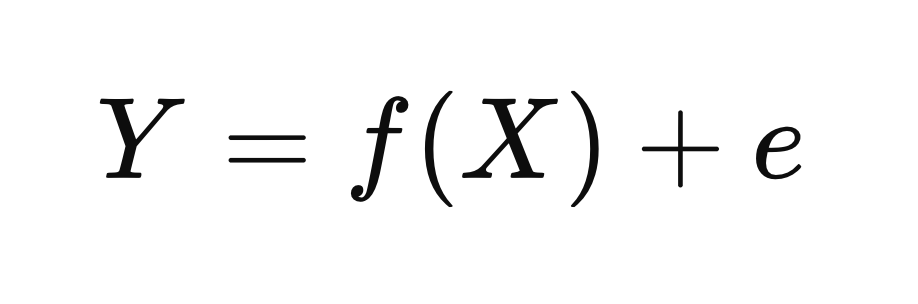
이 수식은 단순하지만, 우리가 현실을 바라보는 사고방식 자체를 바꾸어 놓습니다.
- Y는 우리가 궁극적으로 알고자 하는 ‘결과’ 혹은 '현상'입니다.
예를 들어 고객 이탈률, 매출, 제품 클릭률, 치료 효과 등이 될 수 있습니다. - X는 그러한 결과에 영향을 주는 원인이나 조건입니다.
고객의 연령, 가격, 접속 경로, 복용한 약물, 실험군 여부 등 다양한 설명 변수들이 여기에 들어갑니다. - f(X)는 X가 Y에 미치는 구조적이고 체계적인 영향입니다.
다시 말해, 세상의 작동 원리를 나타내는 함수입니다. - e는 우리가 설명하지 못하는 오차항입니다.
즉 불확실성과 예외의 영역을 의미합니다.
이 수식을 조금만 틀어서 생각하면 다음과 같은 사실을 알 수 있습니다. 우리가 Y라는 것을 우리가 원하는 방향대로 바꾸고 싶을 때, 매출을 높이거나 직원의 성과를 개선하고 싶을 때, f(X)를 개선하면 e를 줄일 수 있다는 것입니다. 매출(Y)이 100이고 f(X)로 설명할 수 있는 부분이 80%라면 오차는 20%일 것입니다. 이 때 f(X)로 설명할 수 있는 부분을 99%로 늘릴 수만 있다면, 오차는 1%로 줄어들 것입니다.
조금만 더 쉽게 한 가지 예를 들어 설명해볼까요? 고객 만족도(Y)를 높이고 싶다고 가정해봅시다. 고객 만족도 자체는 주관적이고 정량적으로 측정하기 어려운 Y입니다. 하지만 고객 응대 시간, 문의 처리 정확도, 배송 속도, 가격 적정성 등은 X로서 우리가 측정하고 조정할 수 있는 요인들입니다. 이 X들을 잘 정의하고, 어떻게 작용하는지를 잘 파악한 정교한 f(X)를 만든다면, 고객 만족도라는 결과를 더 안정적으로 설명하고 예측하고 개선할 수 있게 됩니다. 예를 들어 문의 처리 정확도가 고객 만족도에 미치는 영향을 이해하고, 현재 처리 정확도가 지지부진하다면, 이를 얼마 정도 개선하면 고객 만족도도 개선할 수 있는지를 파악하여 적절한 전략을 구상할 수 있겠죠?
인과 추론의 필요성과 상관 관계 오해
하지만 여기서 한 가지 중요한 질문이 생깁니다. “과연 X와 Y 사이에 진짜로 인과관계가 있는 걸까?”
데이터를 분석하다 보면, 서로 밀접하게 움직이는 변수(상관관계가 있는 변수)들을 자주 발견합니다. 예를 들어 광고비가 증가한 시기에 매출도 올랐다고 합시다. 이 두 변수 사이에 통계적으로 유의미한 상관관계가 있다고 하더라도, "광고비를 늘리면 매출이 늘어난다"는 주장을 바로 할 수 있을까요? 혹시 광고비와 매출 모두 계절적 요인이나 프로모션, 경쟁 상황 등의 제3의 요인에 의해 동시에 영향을 받은 것은 아닐까요?
이처럼 X와 Y가 함께 움직인다(correlation)는 사실만으로 X가 Y의 원인이다(causation)라고 단정할 수 없습니다. 그리고 이것이야말로 많은 데이터 기반 의사결정에서 반복적으로 발생하는 치명적인 오류입니다.
바로 이 지점에서 등장하는 것이 인과추론(causal inference)입니다. 인과추론은 단순히 관찰된 데이터 속의 패턴을 찾는 것이 아니라, "어떤 원인을 바꾸면 결과가 바뀌는가?"라는 질문에 과학적으로 접근하는 방법입니다. 즉, 우리가 모든 데이터 분석을 통해 알고 싶은 것은 “무슨 일이 일어났는가?”보다 “무엇을 바꾸면 더 나은 결과가 일어날 수 있는가?”입니다.
이를 위해 인과추론은 다음과 같은 중요한 사고를 포함합니다:
- 개입(intervention): 어떤 X를 바꾸면 Y는 어떻게 달라질까?
- 반사실적 사고(counterfactual): 만약 다른 선택을 했더라면, 결과는 어떻게 달라졌을까?
- 교란 변수(confounder): X와 Y 사이의 인과를 흐릴 수 있는 제3의 요인은 무엇일까?
- 대리 변수(proxy variable): 직접 관찰할 수 없는 요인을 어떤 관찰 가능한 변수로 대체할 수 있을까?
이러한 질문들은 단순한 통계 모델이나 LLM 기반 평균/총합 관점의 분석만으로는 해결하기 어렵습니다. 왜냐하면 대부분의 AI 모델은 기존 데이터에서 존재하는 패턴을 반복 학습하는 데 초점을 맞추기 때문입니다. 하지만 인과추론은 존재하지 않았던 상황, 즉 "일어나지 않은 사건"에 대한 상상력과 논리적 가정을 통한 검증을 필요로 합니다. 이러한 사고는 본질적으로 인간 중심의 사고이며, 데이터를 넘어선 판단력을 요구합니다.
예를 들어봅시다. 아까 Y = f(X) + e의 예시로 돌아와서, 한 회사가 고객 이탈률(Y)을 줄이기 위해 여러 조치를 취하고 있습니다. 고객센터 응답 속도, 할인 쿠폰 제공 여부, 멤버십 등급 정책 등을 X로 설정하고, 이들이 이탈률에 어떤 영향을 주는지를 분석하려 합니다. 그런데 이때 단순히 “멤버십 등급이 높은 고객은 이탈률이 낮다”는 상관관계를 발견했다고 해서 “멤버십 등급을 높이면 이탈률이 줄어든다”고 말할 수는 없습니다. 실제로는 만족도가 높은 고객이 멤버십도 높고 이탈도 덜 하는 것일 수도 있기 때문입니다. 이 경우 고객 만족도라는 숨겨진 교란 변수(confounder)를 통제하지 않으면, 우리는 잘못된 결론에 도달하게 됩니다.
교란 변수 통제 방법: RCT, PSM, DiD
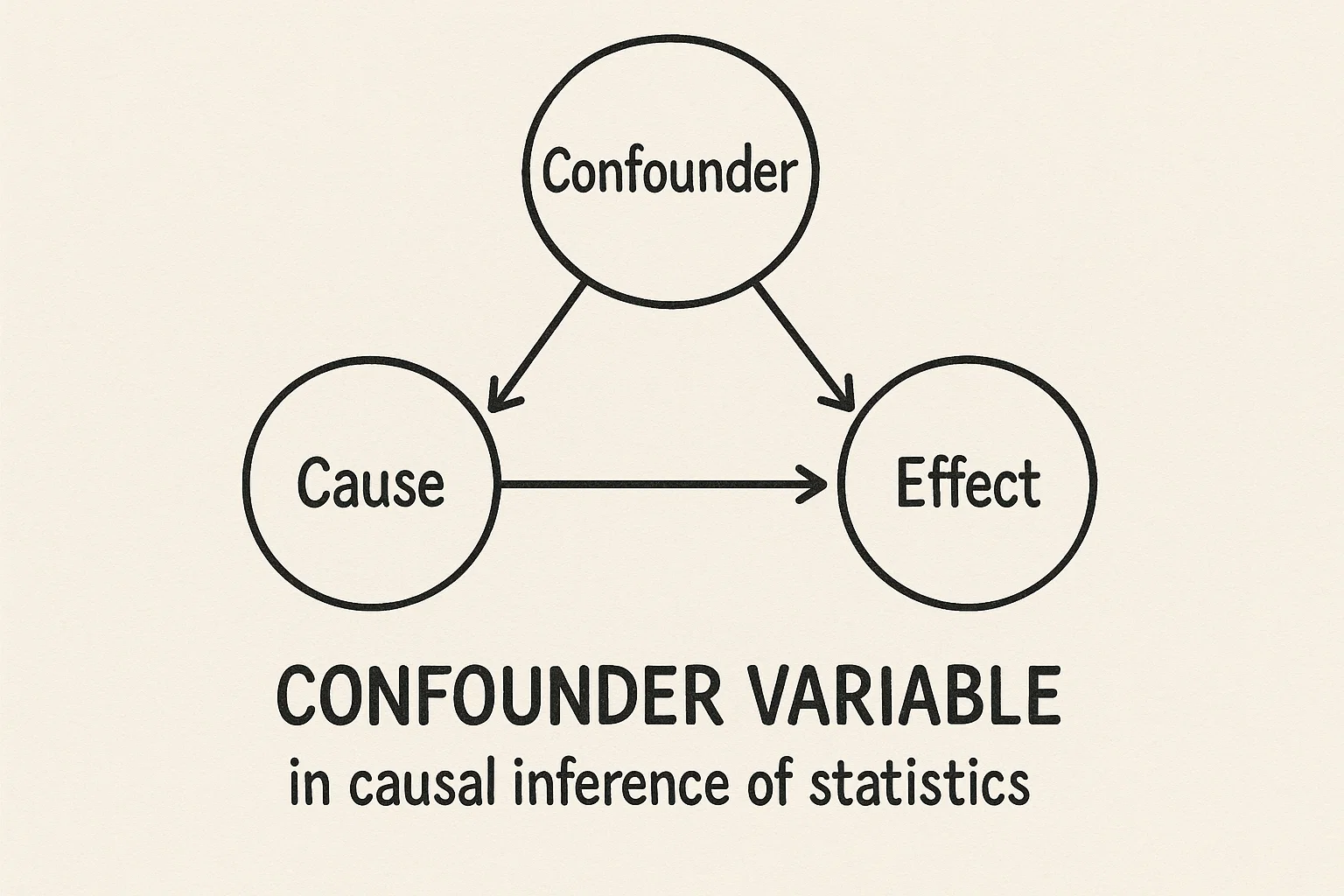
그럼 이럴 때는 어떻게 해야 할까요? 고객 만족도라는 교란 변수를 통제하기 위해 우리가 사용할 수 있는 방법은 여러 가지가 있습니다. 통계학자들은 이러한 상황을 해결하기 위한 여러가지 프레임워크를 오랜 시간 개발해 왔습니다.
- 무작위 실험(Randomized Controlled Trial, RCT)
가장 이상적인 방식은 무작위 실험을 설계하여 고객을 임의로 나누고 한 그룹에만 멤버십 등급을 높여주는 방식입니다. 이렇게 하면 만족도를 비롯한 모든 외부 요인이 양 그룹 간에 평균적으로 같아지므로, 멤버십 등급 변화가 이탈률에 미치는 인과 효과를 비교적 정확하게 파악할 수 있습니다.
- 성향 점수 매칭(Propensity Score Matching, PSM)
하지만 실제 비즈니스 환경에서는 이런 실험이 항상 가능하지 않기 때문에, 관측 데이터를 바탕으로 인과 추론을 시도해야 하는 경우가 많습니다. 이때 사용할 수 있는 대표적인 방법이 성향 점수 매칭입니다. PSM은 멤버십 등급이 높은 고객과 그렇지 않은 고객을 ‘만족도’나 ‘고객 충성도’ 등 주요 변수들을 기준으로 비슷한 조건끼리 짝지은 뒤, 그 둘의 이탈률을 비교하는 방식입니다. 이렇게 하면 멤버십 등급을 제외한 나머지 조건이 유사한 집단 간 비교가 가능해지므로, 멤버십 등급 그 자체의 효과를 보다 분리해볼 수 있습니다.
- 차분의 차분(Difference-in-Differences, DiD)
또 다른 방법으로는 차분의 차분 기법을 들 수 있습니다. 이 방법은 정책 변경 전후의 변화를 기준으로, 멤버십 혜택이 강화된 집단과 그렇지 않은 집단의 이탈률 변화 폭의 차이를 비교합니다. 단순한 시계열 비교보다 훨씬 더 타당한 근거를 제공하며, 정책 도입 전후의 외부 환경 변화도 일정 부분 통제할 수 있습니다.
이처럼 관측 데이터에서 인과관계를 파악하려면 어떻게 교란 요인을 통제할 수 있을지를 체계적으로 고민하는 과정이 필수적이며, 이는 단순한 상관 분석이나 LLM 기반 통계 생성만으로는 대체할 수 없는 통계적 사고의 핵심 영역이라 할 수 있습니다.
LLM 시대에도 여전히 중요한 통계적 사고의 본질
이제 우리는 통계적 사고 위에 한 층 더 올라섰습니다. 데이터를 보는 눈으로서 통계적 사고에 더해, 세상을 바꾸기 위한 개입의 논리(인과적 사고)를 갖게 된 것입니다.
이는 특히 AI와 자동화가 범람하는 시대에 더욱 중요합니다. 왜냐하면 AI가 아무리 정교해져도, “어떤 데이터를 어떻게 수집해야 하는가?”, “이 변수와 결과 사이에 인과적 연결이 있는가?”, “모델의 결과를 그대로 믿어도 되는가?”와 같은 핵심 질문에는 결국 위에서 소개한 통계적 사고가 필요하기 때문입니다.
사실 우리는 일상 속에서 이미 이런 질문들을 자연스럽게 던지고 있습니다.
“왜 저 사람은 퇴사했을까?”
“어떻게 하면 성과를 높일 수 있을까?”
“무엇이 고객을 만족시키는 걸까?”
"이런 액션을 취한다고 정말 지표를 개선할 수 있는 걸까?"
우리는 이런 문제들을 해결하기 위해 나름의 방식으로 추론하고 판단하며 행동합니다. 다만, 이를 보다 체계적으로 정의하고 검증하는 방법이 바로 ‘통계학’이라는 사실을 잘 모르기 때문에, 통계를 단지 평균이나 총합을 계산하는 기술 정도로만 오해하곤 하는 것입니다.
하지만 앞서 본 수식처럼, 통계는 단순한 수치 계산이 아니라 세상의 원인과 결과를 구조적으로 이해하고, 예측하고, 변화시키기 위한 사고의 틀입니다. 그리고 우리가 일상에서 겪는 수많은 ‘왜’와 ‘어떻게’에 답하기 위해, 이 사고는 지금 이 순간에도 여전히 가장 강력한 도구로 작동하고 있습니다. 이것이 바로 통계적 사고가 LLM의 시대에도 인간이 반드시 가져야 할 가장 중요한 ‘사고의 무기’인 이유입니다.
2부. LLM의 원리와 한계 : 인간의 사고를 대체할 수 있을까?
LLM의 작동 원리 : 확률론적 앵무새 논쟁과 무한 원숭이 정리
다시 LLM으로 돌아와 봅시다. LLM은 방대한 양의 과거 데이터를 기반으로, 다음 단어나 문장을 가장 적절하게 확률적으로 예측하는 방식으로 동작합니다(이를 어려운 말로 조건부 확률 추정conditional probability estimation이라고 합니다. 확률이라는 단어를 기억해주세요). 즉, 주어진 단어 시퀀스에서 다음에 올 단어의 확률을 계산하여 가장 가능성 높은 출력을 생성하는 방식입니다.
하지만 LLM의 이러한 특성 때문에 일각에서는 LLM을 "확률론적 앵무새(Stochastic Parrot)"라 부르며 비판하기도 합니다. 우리 시대의 대표적인 언어학자 노엄 촘스키(Noam Chomsky)를 비롯한 일부 학자들은 LLM이 방대한 텍스트를 단순히 통계적으로 모방하고 조합하는 기계일 뿐, 결코 인간과 같은 진정한 의미의 "이해(understanding)"를 할 수 없다고 지적합니다. 촘스키의 관점에서 언어는 단순한 데이터의 축적과 패턴 반복이 아니라, 본질적으로 인간의 내재된 인지적 구조가 작용하여 만들어내는 창조적이고 혁신적인 행위이기 때문입니다.

이 비판을 설명할 때 흔히 등장하는 비유가 바로 무한 원숭이 정리(Infinite monkey theorem)의 개념입니다. 수많은 원숭이가 무작위로 타이핑을 계속하면, 결국 셰익스피어의 희곡과 같은 걸작이 우연히 완성될 수 있을 가능성이 거의 100%에 수렴한다는 것을 수학적으로 증명했다는 것이죠. 하지만 그렇게 완성된 문장을 두고 과연 원숭이가 셰익스피어를 "이해"했다고 말할 수 있을까요? 원숭이는 단지 무작위적인 패턴을 계속해서 만들어낸 것뿐이니까요. 촘스키 계열의 비판자들은 LLM이 보여주는 언어 능력이 결국 이 무한 원숭이와 원칙적으로는 다르지 않다고 주장합니다(물론 무한 원숭이들은 완전 랜덤한 타이핑이고, LLM은 조건부 확률 분포 기반이라는 차이가 있지만요).
제프리 힌튼의 반론 : 인간과 LLM 사고의 유사성
그러나 최근 이 비판에 정면으로 반론을 제기하는 대표적 인물이 바로 딥러닝의 대가, 제프리 힌튼(Geoffrey Hinton)입니다. 힌튼은 LLM이 "확률론적 앵무새"에 그친다는 주장에 대해 강력히 반대합니다. 그는 인간 역시 본질적으로 LLM과 다를 바 없는 방식, 곧 뉴런의 신경망을 통해 데이터를 축적하고 학습함으로써 세상을 이해한다고 강조합니다.
즉, 인간의 언어나 사고 능력 역시 많은 양의 데이터를 기반으로 통계적으로 학습된 결과물이며, 이런 측면에서 볼 때 인간의 사고방식과 LLM의 작동 방식은 근본적으로 다르지 않다는 것입니다. 할루시네이션 같은 현상 또한 인간의 기억이 왜곡되는 것과 큰 차이가 없다고 생각하는 것이지요.
LLM이 통계적·인과추론적 사고를 할 수 있는 능력을 가지고 있는가?
이처럼 초거대언어모델(LLM)은 우리가 입력한 텍스트에 기반해 그럴듯한 문장을 생성할 수 있지만, 그 결과물이 과연 인간과 같은 "사고(thinking)"나 "이해(understanding)"를 동반한다고 볼 수 있는지는 여전히 논쟁의 여지가 많습니다.
촘스키가 맞을지 제프리 힌튼이 맞을지는 저 같은 범인이 논할 영역은 아니라 생각합니다. 그러나 1) LLM은 학습한 데이터의 어떠한 계(system)에 갇혀 있을 가능성이 있다는 것 2) 이를 기반으로 LLM에 기반한 데이터 기반 의사결정의 가능성과 한계에 대하여 생각해 보아야 한다는 것은 알 수 있습니다.
위에서 살펴 본 것처럼, 특히 인과추론적 사고(causal reasoning)나 반사실적 추론(counterfactual reasoning)과 같은 고차원적 인지 능력은 인간 사고의 핵심적인 특징이자 통계적 사고의 핵심인데, LLM이 과연 어느 영역까지 이 부분을 돕거나 혹은 대체할 수 있을지 다음의 두 논문을 보며 생각해봅시다.
『Reasoning or Reciting?』: 학습된 패턴의 재현, 그 이상은 아닌가?

이 논문은 작년 ACL Anthology에 등재되었습니다. LLM이 단순히 학습된 패턴을 재조합하는 수준을 넘어서, 진정한 의미의 일반화된 추론을 할 수 있는지 평가하기 위해 반사실적 과제(counterfactual task)를 설계해 실험을 진행했습니다.
- 진법을 바꾼 산술 연산: 십진법(base-10) 대신 구진법(base-9) 등과 같이 LLM이 익숙하지 않은 방식으로 수 연산을 수행하도록 요구
- 공간 추론 과제: 기존의 좌표계를 회전시키거나 반전시킨 후 방향을 추론
- 프로그래밍 과제: 익숙한 0부터 시작하는 인덱스 체계 대신 1부터 시작하는 인덱스를 사용하는 가상의 언어 환경을 제시
이처럼 기존 학습 데이터와는 다른 규칙과 구조를 적용한 다양한 counterfactual 조건을 도입한 결과, GPT-4를 포함한 최신 LLM들은 기존 조건에 비해 현저히 성능이 하락했습니다. 주목할 점은, 모델이 조건을 이해하지 못한 것이 아니라, 이해했음에도 해당 조건 하에서 과제를 수행하는 능력이 부족했다는 것으로 보인다는 점입니다.
『Theory Is All You Need』: "이론" 없는 AI의 근본적 한계

이 논문은 더 근본적인 차원에서 LLM의 한계를 고찰해봅니다. 먼저 인간이 어떻게 사고하는지를 생각해 보는데요. 1) 인간은 경험을 바탕으로 이론을 구성하고, 2) 이 이론을 바탕으로 전혀 새로운 조건에 대한 가정을 세우고, 3) 그 결과를 예측하는 능력을 갖습니다. 그래서 이 논문은 인간이 혁신을 이루는 핵심이 바로 "데이터-신념 비대칭성(data-belief asymmetry)"에 있다고 설명합니다. 즉, 인간은 기존 데이터와 일치하지 않더라도, 이론에 기반하여 새로운 가능성을 믿고 추구할 수 있습니다. 그 예로 저자들은 라이트 형제의 비행 사례를 듭니다.
LLM은 반면 이러한 이론적 모험이나 신념 기반의 창의성을 지니지 못하며, 오직 기존 데이터 내 패턴에만 의존합니다. 즉 LLM은 철저히 과거 지향적이라는 것이죠. 이는 곧 LLM이 창의적인 반사실적 사고(counterfactual reasoning)나, 이론을 기반으로 한 적극적인 인과 추론을 수행하기 어렵다는 근본적 한계를 내포합니다.
...Here we are specifically talking about beliefs that may outstrip, ignore, and go beyond existing evidence. Forward-looking, contrarian views are essential for the generation of novelty and new knowledge. Due to the statistical and past-oriented nature of AI-based computational and cognitive systems (focused on correlations, associations, and averages from past data), they are not able to project or reason forward in contrarian ways, given the implicit insistence on symmetry between data and beliefs.
...여기서 우리는 명확히 기존의 증거를 넘어서거나, 무시하거나, 초월할 수 있는 믿음에 관해 이야기하고 있습니다. 새로움과 새로운 지식의 창출을 위해서는 미래지향적이면서 동시에 기존의 관점에 반하는(contrarian) 시각이 반드시 필요합니다. 그러나 AI 기반의 계산 및 인지 시스템은 본질적으로 통계적이고 과거지향적이기 때문에(즉, 과거 데이터의 상관관계, 연관성, 평균 등에 초점을 맞추기 때문에), 데이터와 신념 사이에 암묵적으로 존재하는 대칭성(symmetry)을 전제로 하며, 이로 인해 기존 관점을 벗어난 반대적이고 미래지향적인 추론이나 사고를 수행하기 어렵습니다.
Felin, Teppo & Holweg, Matthias. (2024). Theory Is All You Need: AI, Human Cognition, and Causal Reasoning.
3부. LLM과 통계적 사고의 시너지 : 더 나은 의사결정을 위한 가능성
이제까지 우리는 LLM이 근본적으로 갖는 제한점에 대해 논의했습니다. 특히 인과추론과 같은 고차원적 통계적 사고 방식에서 LLM은 본질적이고 이론적인 한계를 가지고 있습니다. 그럼에도 불구하고, 실무에서는 최근 몇 년 사이 연구자들과 기업들이 LLM을 보조 도구로 활용해 통계적 사고의 정확성을 높이고 업무 효율성을 극대화하는 다양한 사례를 제시하고 있습니다.
인과구조 발견의 효율성 증대 (LLM-Augmented Causal Discovery)
2024년 발표된 연구에서 GPT-4를 활용한 새로운 인과구조 학습 방법이 제시되었습니다(Using GPT-4 to guide causal machine learning). 이 연구에서는 GPT-4에게 실제 데이터 없이 오직 변수 이름만 제공한 뒤, 이 변수들 간의 인과 관계를 추론하여 인과 그래프(causal graph)를 그리도록 지시했습니다.
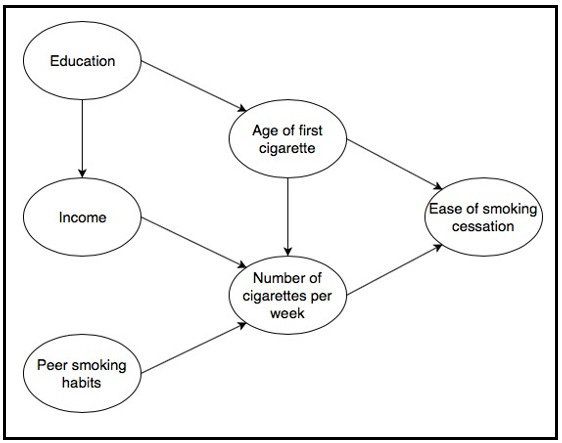
결과는 놀라웠습니다. 평가에 따르면 GPT-4가 생성한 인과 그래프는 순수한 데이터 기반 알고리즘보다 더 정확했으며, 심지어 도메인 전문가들이 만든 인과구조와 거의 동일한 수준의 정확도를 보였습니다. 더욱 중요한 점은, GPT-4의 제안을 기존의 통계적 인과 학습 알고리즘과 결합했을 때, 도메인 전문가 수준에 매우 근접한 하이브리드 모델을 얻었다는 것입니다.
실제 비즈니스 측면에서 이는 큰 의미가 있습니다. 기존에는 공급망 붕괴, 고객 이탈의 원인과 같은 인과적 분석을 위해 수많은 도메인 전문가들의 브레인스토밍이 필요했지만, LLM을 활용해 도메인 지식과 상식을 손쉽게 보완하고, 자동화된 방식으로 인과구조를 검증하여 실무자의 통계적 사고를 지원할 수 있게 된 것입니다.
마케팅에서의 반사실적 사고(Counterfactual Reasoning) 시뮬레이션
2023년 스탠퍼드 연구팀의 연구에서는 GPT 모델이 텍스트 기반의 다양한 마케팅 시나리오에서 인과 관계 추론(97%)과 인과 효과 추정(92%)에서 높은 정확도를 보였다고 보고했습니다(링크). 이를 통해 기업들은 다음과 같은 counterfactual 질문을 LLM에게 던지고 의사결정에 활용하고 있습니다.
- “만약 이 광고 캠페인을 겨울 대신 여름에 실시했다면, 성과는 어떻게 달라졌을까?”
- “이 캠페인을 이메일이 아닌 소셜 미디어를 통해 집행했다면?”
이에 따라 LLM은 기존 마케팅 데이터를 바탕으로 plausibility(개연성)가 높은 결과를 제시, 실제로 많은 비용이 드는 실험을 진행하기 이전에 전략적 선택의 우선순위를 의사결정자가 매길 수 있도록 돕고 있습니다.
의사결정 지원 및 설명 가능한(Explainable) 인과추론
최근에는 인과추론 결과를 기업 내부의 비전문가들이 이해하기 쉬운 형태로 번역하는 데에도 LLM이 활용되고 있습니다. 복잡한 통계적 사고 흐름의 결과를 자연어로 쉽게 설명하여, 데이터 분석가와 의사 결정권자 간의 소통을 원활하게 합니다(Large Language Models for Causal Discovery: Current Landscape and Future Directions).
금융 분야에서는 Fin-Force라는 프로젝트에서 경제 뉴스나 정책 발표 등 다양한 입력을 바탕으로 LLM이 plausibility 있는 반사실적 미래 시나리오를 생성하여, 의사 결정자들이 정책 변경에 따른 잠재적 영향을 손쉽게 평가할 수 있게 하고 있습니다. 결국 모든 데이터 분석의 목적은 더 나은 의사결정을 내리기 위함이라는 점에서 이 부분은 주목할 만한 점이라 생각합니다(Deriving Strategic Market Insights with Large Language Models: A Benchmark for Forward Counterfactual Generation).
...Counterfactual reasoning typically involves considering alternatives to actual events. While often applied to understand past events, a distinct form–forward counterfactual reasoning–focuses on anticipating plausible future developments. This type of reasoning is invaluable in dynamic financial markets, where anticipating market developments can powerfully unveil potential risks and opportunities for stakeholders, guiding their decision-making....
...반사실적 추론(counterfactual reasoning)은 일반적으로 실제로 일어난 사건에 대한 대안적 상황을 상상하는 것을 포함합니다. 이는 주로 과거 사건을 이해하는 데 활용되지만, 그와는 구별되는 형태로 ‘미래 지향적 반사실적 추론(forward counterfactual reasoning)’은 발생 가능한 미래의 전개를 예측하는 데 초점을 맞춥니다. 이러한 유형의 추론은 특히 역동적인 금융 시장에서 매우 중요합니다. 왜냐하면 시장의 전개를 미리 예측하는 것은 이해관계자들이 잠재적인 리스크와 기회를 파악하고, 보다 효과적인 의사결정을 내리는 데 강력한 통찰을 제공하기 때문입니다.
Ong, Keane, et al. "Deriving Strategic Market Insights with Large Language Models: A Benchmark for Forward Counterfactual Generation." arXiv preprint arXiv:2505.19430 (2025).
LLM 시대, 통계적 사고와 AI의 시너지가 이끄는 더 나은 의사결정
지금까지 초거대언어모델(LLM)의 시대에서 과연 전통적인 통계와 인과적 사고가 여전히 의미가 있는지, 그리고 그 가운데 LLM이 어떤 역할을 수행할 수 있을지를 다양한 관점에서 살펴보았습니다.
많은 사람들이 LLM의 등장과 함께 전통적 통계를 단순히 평균이나 총합을 계산하는 구식의 기법 정도로 여기고 있지만, 이것은 통계학의 진정한 본질에 대한 오해에서 비롯된 것입니다. 통계는 결코 구세대의 유물이 아닙니다. 통계는 단지 숫자를 다루는 기법이 아니라, 불확실성이 존재하는 세상을 이해하고 설명하고 예측하며, 이를 바탕으로 의사결정을 내리도록 돕는 하나의 강력한 사고의 틀입니다. 우리가 궁극적으로 관심을 두는 것은 단순히 “어떤 숫자가 나왔는가?”가 아니라, “왜 그런 숫자가 나왔으며, 어떻게 하면 원하는 방향으로 변화시킬 수 있는가?”입니다. 즉, 모든 데이터 분석의 핵심에는 의사결정이 자리하고 있고, 이 의사결정을 내리는 데 필수적인 능력이 바로 통계적 사고(statistical thinking)입니다.
이러한 맥락에서 앞으로 데이터 분석이 나아갈 방향은 명확합니다. 인간이 할 수 있는 통계적 사고 능력과 LLM의 언어 능력이 상호 보완적으로 결합되어야 합니다. LLM이 인간의 사고와 데이터 분석을 완전히 대체하는 것이 아니라, 통계적 사고의 흐름을 더욱 명확하게 하고, 우리가 선택할 수 있는 의사결정 옵션을 풍부하게 만들어주는 역할을 수행할 때 데이터 분석 영역에서 가장 큰 가치를 발휘할 것입니다. 인간이 데이터를 기반으로 세상을 더 깊이 이해하고, 더 좋은 결정을 내릴 수 있도록 돕는 것이 바로 데이터 분석의 궁극적인 목적이기 때문입니다. 이러한 결합이 성공적으로 이루어진다면, 기업과 조직이 보다 현명하고 전략적인 의사결정을 내릴 수 있는 새로운 지평이 열릴 것으로 기대됩니다.
HEARTCOUNT 역시 이와 같은 문제의식을 기반으로, 사용자의 질문에 담긴 의도를 통계적 사고 관점에서 해석하고, AI가 실제 비즈니스 현장에서 활용 가능한 인사이트를 자동으로 제안하는 방향으로 발전하고자 합니다. LLM이 분석을 완전히 대체하는 것이 아닌, 더 나은 사고를 가능하게 만들고, 더 나은 사고가 결국 더 나은 결정을 이끌어내는 미래를 HEARTCOUNT는 그리고 있고 또 오늘 이 시간에도 설계하고 있습니다.
이것이 바로 우리가 나아가야 할 LLM 시대 데이터 분석의 진정한 방향성이라 제언해보며 글을 마칩니다.
→ LLM + Statistical thinking = Better decision making
AI 데이터 분석 기능을 직접 사용해보세요. HEARTCOUNT는 개인, 기업 등 자신의 사용 용도에 맞게 사용할 수 있는 시각화/AI 자동 분석 도구 입니다.





![[Monthly Webinar VOD] AI 데이터 분석, 어디까지 왔니? 다섯가지 툴 비교해보기](/ko/content/images/size/w540/2024/08/7---_---------------------1080_1080.png)

![[Monthly Webinar VOD] 2024 Data & AI 트렌드 분석](/ko/content/images/size/w540/2024/02/---------------------1080_1080.png)