데이터를 읽고, 쓰고, 행동하고
데이터를 잘 읽는 사람은 인간과 세상을 더 정확하고 넓고 깊게 이해하게 됩니다. 이전과는 다른 방식으로 세상을 보게 되고, 진부하지 않은 내용을 말하고 쓸 수 있게 되지요. 그래서, 더 좋은 생각을 하게 되고, 좋은 생각은 우리를 행동하게 만듭니다.
표지 그림(에셔, drawing hands)처럼 데이터를 읽고 해석하는 일과 보고서를 쓰는 일은 그 시작과 끝을 구분할 수 없는 순환적인 작업입니다. 잘 읽어야 잘 쓸 수 있고, 잘 쓸 수 있는 사람은 또 잘 읽을 수 있습니다.
또한, 데이터 보고를 포함한 데이터 분석 행위는 사회적 상호작용입니다. 데이터를 잘 읽는 사람(소비자)이 있어야 쓰는 사람도 있게 되고, 역으로 잘 쓰는 사람(생산자)이 있어야 읽는 사람도 있게 됩니다. 적과 동지를 구별해서 공포와 희망의 감정을 조장하면서 원하는 결과를 만들어 내야 하는 고도의 정치적 행위이기도 하고요.
보고서 작성이 단순히 기술적인 내용만은 아니라는 사실을 염두에 둔 채 오늘은 데이터에서 발견한 패턴을 다른 사람이 활용할 수 있도록 잘 쓰는 일에 대해 말해 보려고 합니다.
데이터 시각화의 선구자들 (Brinton to Bertin to Tukey to Tufte)
데이터 보고서는 시각화 차트와 텍스트(차트에 대한 정량적 해석과 견해)로 구성되어 있고, 텍스트 중심의 여타 보고서와의 가장 큰 차이는 시각화 차트(데이터 테이블 포함)의 존재입니다. 데이터 시각화 역사를 논할 때 주로 언급되는 선구자들에 대한 이야기로 시작합니다.
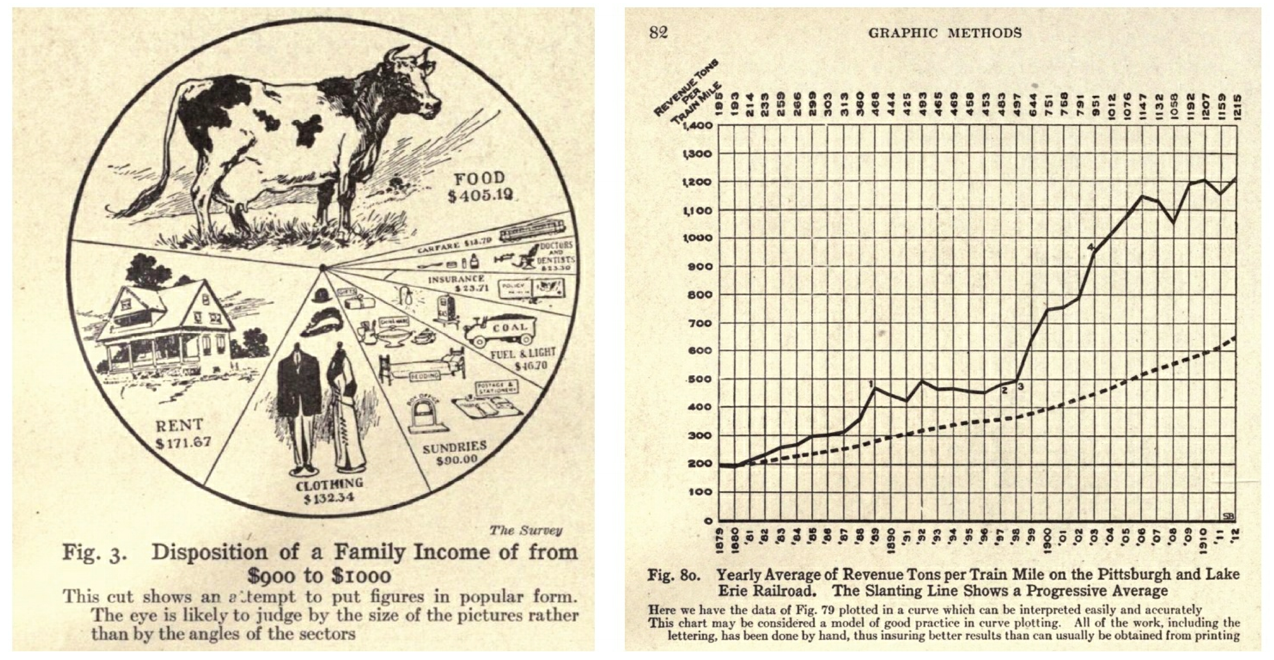
시각화는 복잡한 것을 시각적 요소로 추상화(abstraction)하는 기법입니다. 인간의 삶이 복잡해진 산업화 시대에 데이터 시각화가 최초로 주목을 받기 시작한 것은 우연이 아닙니다. 1914년에 출간된 "Willard C. Brinton"의 "Graphic Methods for Presenting Facts"라는 책은 데이터 시각화에 대한 최초의 경영서적으로 알려져 있습니다. 아래 우측 그림은 열차의 마일당 수익을 시계열 위에 시각화한 차트를 소개하는 내용인데 당시에는 '라인 차트'라는 용어가 생기기 전이라 "curve plotting"이라고 소개하고 있네요.
Brinton의 뒤를 이어 지도 제작자였던 "Jacques Bertin"은 1967년에 데이터를 시각화하기 위한 변수 7가지(7 visual variables: 위치, 크기, 모양, 색상, 밝기, 방향, 텍스처)를 최초로 정립하였습니다.
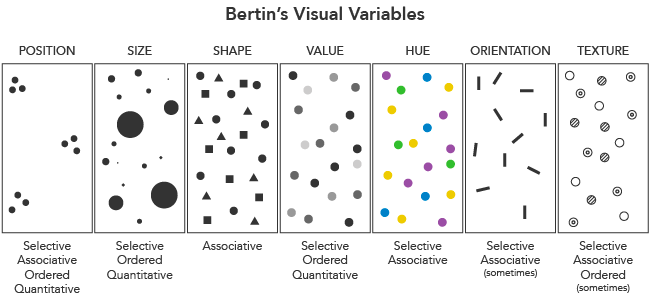
Bertin가 당시 주창한 데이터 시각화와 관련한 두 가지 원칙은 2023년에도 여전히 유효합니다.
- "Principle of Expressiveness": Say everything you want to say - no more, no less - and don't mislead (데이터로 주장하고 싶은 본질만 차트에 담아라)
- "Principle of Effectiveness": Use the best method for showing your data. (데이터로 주장하고 싶은 걸 적확하게 표현할 수 있는 형식을 선택하라)
Bertin의 뒤를 이은 "John Tukey"는 "Exploratory Data Analysis(1977)"의 개념과 방법들을 체계적으로 정립한 분으로 워낙 유명한 분인지라 자세한 설명은 생략하겠습니다. 다만, EDA를 학문적으로 접근해 볼 욕심이 있는 분들은 요 링크에 있는 내용을 참고하면 좋겠습니다. Tukey의 조금은 난해한 문장들을 쉽게 풀어서 강의 형식으로 정리한 내용입니다.

마지막으로 소개할 분은 "Edward Tufte"입니다. Tufte는 1983년에 출간된, 데이터 시각화의 복음서로 불러도 부족함이 없는, 'The Visual Display of Quantitative Information'의 저자입니다. 이 책 본문에 있는 유명한 문장들을 몇 개 옮겨보면 이렇습니다.
- “Above all else show the data” (p. 92). Erase everything you don’t need.
- Data-Ink Ratio(p.93) = 1 - "정보 손실 없이 없앨 수 있는 그래픽 요소의 비율".
- “Graphical excellence consists of complex ideas communicated with clarity, precision, and efficiency.” (p. 51)
- You don’t have to use a graphic when there isn’t much data — a table is often better.
- Pie charts are useless. The dude hates pie charts.

고전을 읽다 보면 그때는 맞지만 지금은 틀린 얘기들도 적지 않습니다. 내가 지금 하고 있는 일의 역사를 아는 것은 내가 하는 일의 미래를 상상하는 데 도움이 되니 언급된 문헌들을 참고하시면 좋겠습니다.
데이터 보고서, 대략의 구성
데이터 보고서는 데이터셋에 대한 설명, 보고서의 주제(핵심 질문), 데이터에 발견된 주요 사실들, 결론으로 구성됩니다.
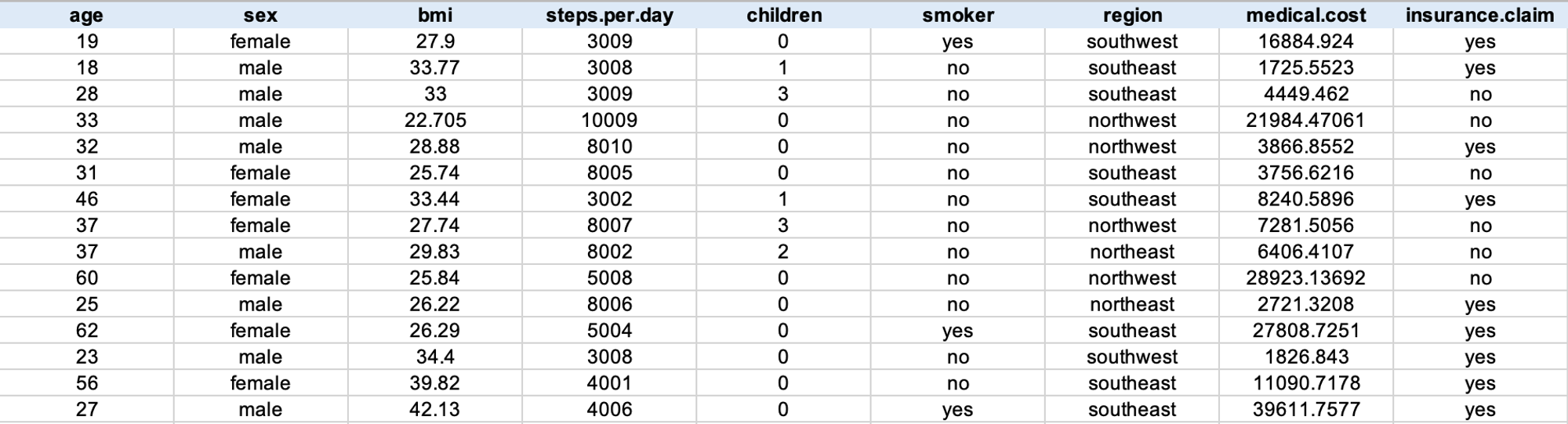
Dataset - 선택한 데이터셋에 대해 기술
보고서를 읽는 사람이 Analytics Report에 어떤 데이터셋을 사용했는지, 데이터셋을 구성하는 변수들은 무엇인지 알 수 있도록 해주세요. 예를 들면, 본 보고서에 사용된 데이터셋은 보험회사의 2022년 1월1일부터 12월31일까지 청구된 의료비 지급(insurance claim) 내역입니다. 보험 청구인의 나이, 성별, 비만지수, 지급된 의료 비용 등으로 구성되어 있습니다.
Business Objective - 데이터 분석의 목적; 핵심 질문
데이터를 통해 알고자 하는 것이 무엇인지? 분석을 하는 이유와 목표를 기술해 주세요. 예를 들면, 높은 의료 비용과 관련된 피보험인의 특성을 이해, 보험 청구비용 최적화를 위한 타겟 세그먼트 발굴.
Key Findings - 데이터에서 발견한 주요 사실들
핵심 질문과 관련하여 데이터에서 발견한 정량적 사실들을 “시각화 결과(차트)”와 “차트에 대한 해석”으로 구성합니다.
Insight - 결론
분석 목적 달성을 위해 어떤 결정과 행동을 하면 좋을지에 대한 최종 결론을 간략하게 기술해 주세요.
데이터 보고에서 차트로 거짓말하지 않기
Tukey는 "Exploratory Data Analysis(1977)" 책에서 “the greatest value of a picture is when it forces us to notice what we never expected to see.”라고 말했습니다.
하지만, 새로운 영감과 세상을 보는 관점을 넓혀줄 수 있는 시각화 차트는 역설적으로 존재하지 않는 패턴을 존재하게 만들 수도, 무의미한 현상에 의미를 부여하는 일도 할 수 있습니다.
요즘에는 다행스럽게도 차트의 기본 문법을 충실히 따르고 있는 시각화 도구나 라이브러리를 사용하기 때문에 변수나 질문 유형에 따른 차트 선택 등 형식적인 면에 있어서 실수할 가능성은 크지 않습니다.
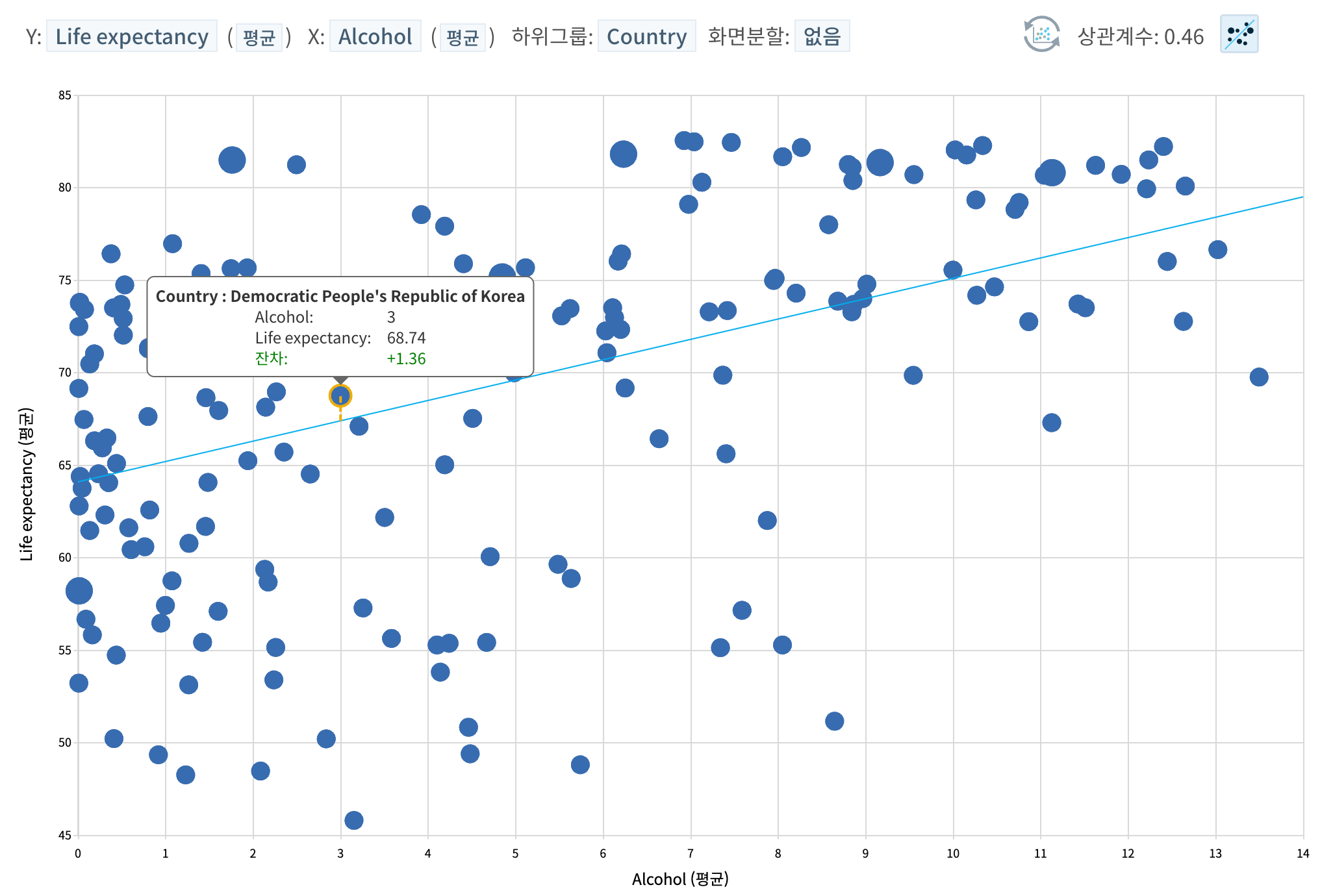
아래에서는 차트의 형식에서 비롯되는 해석의 문제가 아닌 데이터가 보여주는 현실을 곧이곧대로 제시하는 데서 발생하는 문제에 대해 "국가별 알코올 소비량과 평균 수명 간의 관계"라는 분석 주제를 가지고 살펴보겠습니다.
- 국가별 평균 기대수명(Y)과 Alcohol 평균 소비량(X) 간의 상관관계를 보면 0.46으로 매우 높습니다. 해당 관계의 정량적 크기(0.46)를 시각화한 아래 차트는 명백한 사실입니다. 따라서, 국가별 평균 알코올 소비량과 평균 기대수명 간에는 매우 높은 양의 상관관계가 있다고 이야기해도 틀리지는 않습니다. 다만, 상관관계가 있다는 것은 두 변수만을 놓고 보았을 때 선형적 관계가 존재한다는 것이지, 둘 간에 인과성이 존재한다는 이야기는 아닙니다.
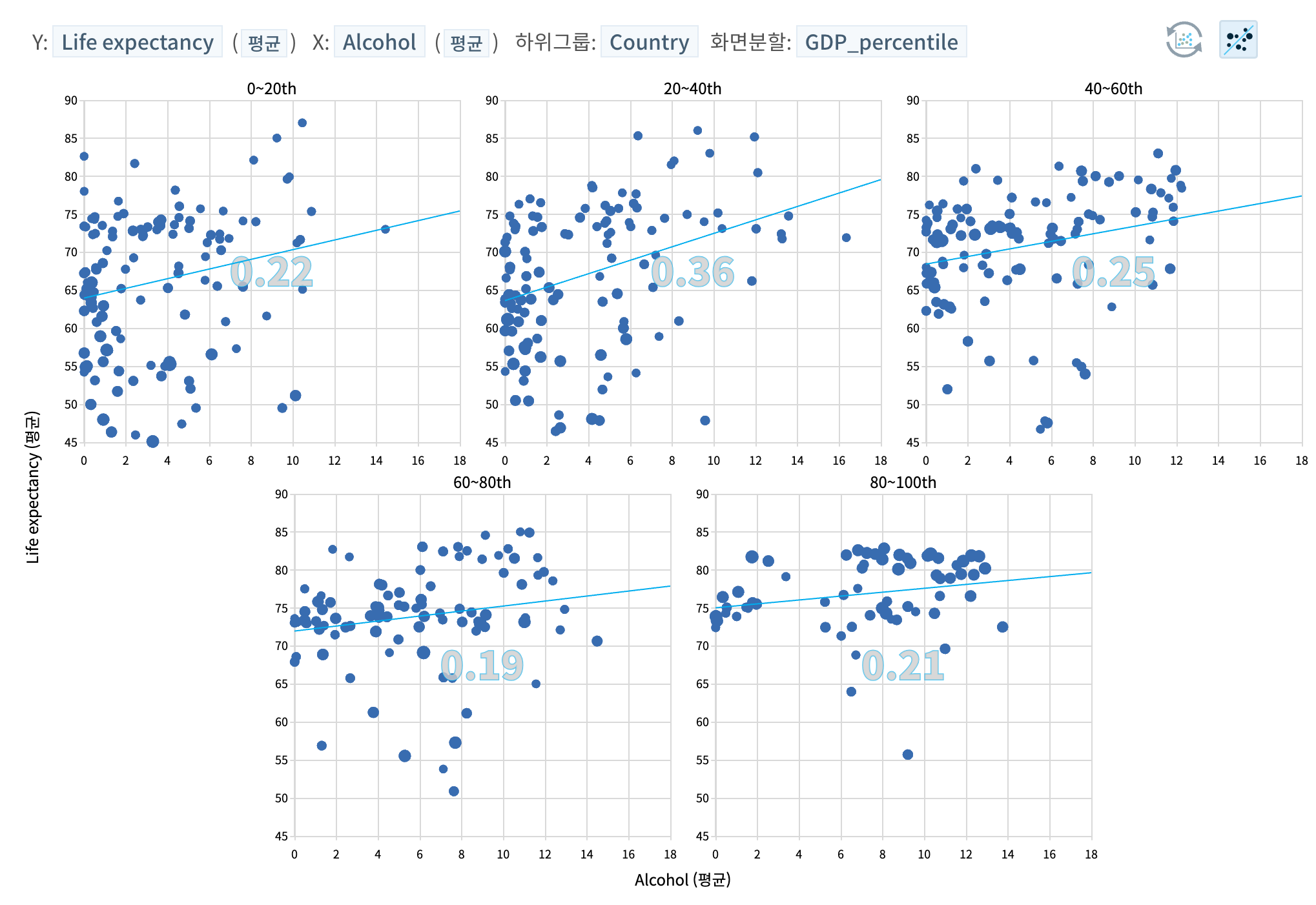
- 제3의 변수(예, 소득 수준)가 기대수명과 알코올 소비량 두 변수에 동시에 영향을 미쳤을 수 있고, 이런 제삼의 교란변수(confounding)의 효과를 없애거나 줄이기 위해 소득수준(GDP)으로 데이터셋을 그룹핑한 후 개별 그룹별로 차트를 생성합니다. 개별 그룹에서 상관관계가 줄어들었고, 특히 고소득 국가 집단(상위 20%와 차상위 20% 집단)에서 눈에 띄게 상관관계가 감소했습니다.
기대 수명과 알코올 소비량 두 가지에 모두 영향을 주었을 변수들(예, 종교)을 좀 더 통제해 나간다면, 두 변수 사이의 상관관계는 아마 더 크게 줄어들게 될 것입니다.
상관관계와 인과적 추론에 대해 좀 더 공부하고 싶다면 아래 웨비나를 참고하세요.
 heartcount
heartcount
현대의 시각화 문법을 따르고 있다면, 그리고 데이터 품질에 문제가 없다면, 주어진 데이터를 시각화하고 그것을 정량적으로 서술하는 일 자체는 옳고 그름을 따질 수 없는 일입니다. 다만, 현상을 기계적으로 기술하는 데이터 분석이 아니라, 현실을 더 정교하게 이해하고 행동으로 옮길 수 있는 분석(보고서 작성)이 되기 위해서는 사실관계의 시각적 표현이 아니라 지식 생산에 도움이 되는 사실의 시각적 표현을 목표로 하면 좋겠습니다.
감각의 작용들이 일어나기 시작하면 진면모를 가려버리기 쉽습니다. 공룡이 보여도 침착하게... 눈에 보이는 것 이면의 복잡다단한 현실을, 데이터가 수집된 맥락을, 전체 데이터셋이 표현하고 있는 집단의 동질성 등을 고려합시다!
Escaping Flat Land
"Escaping Flat Land"는 Edward Tufte의 "Envisioning Information"이라는 책의 첫 번째 챕터의 제목입니다. 삼차원의 시공간에 살고 있는 우리는 이차원의 평면을 통해 정보를 습득하도록 진화하였고, 2차원의 평면 위에 여러 차원을 효과적으로 표현하는 것은 데이터 시각화에서 매우 중요한 문제입니다.
두꺼비의 껍질을 바닥에 펼쳐 놓은 아래 그림과 우리가 현실의 추상화로서 데이터를 시각화하는 방식은 크게 다르지 않습니다.
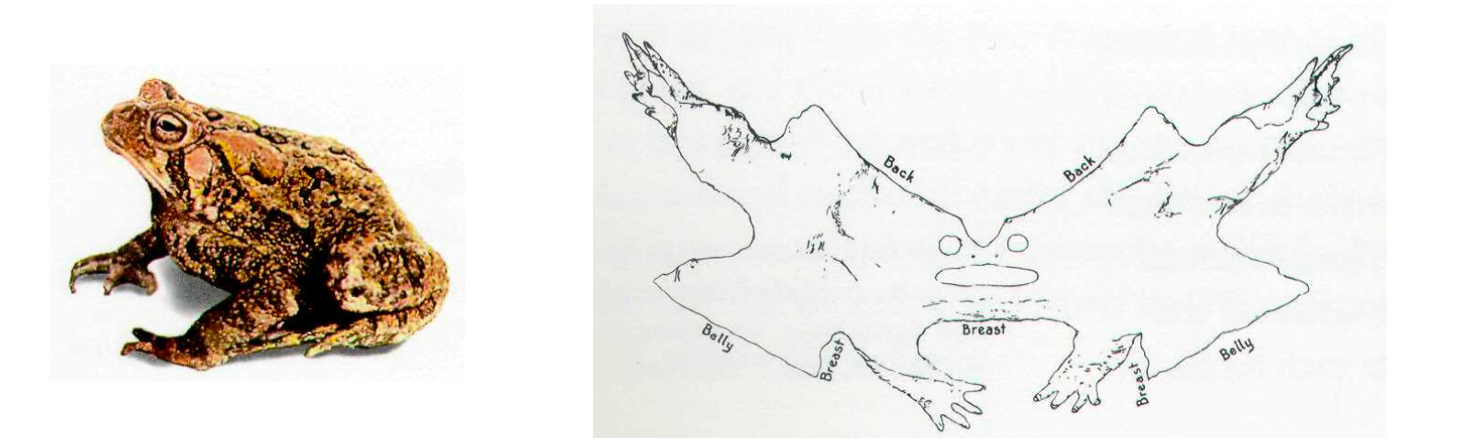
여러 차원의 변수들을 평면에 시각화하는 효과적인 방법들은 아래 블로그 포스트를 참고해 주세요.
heartcount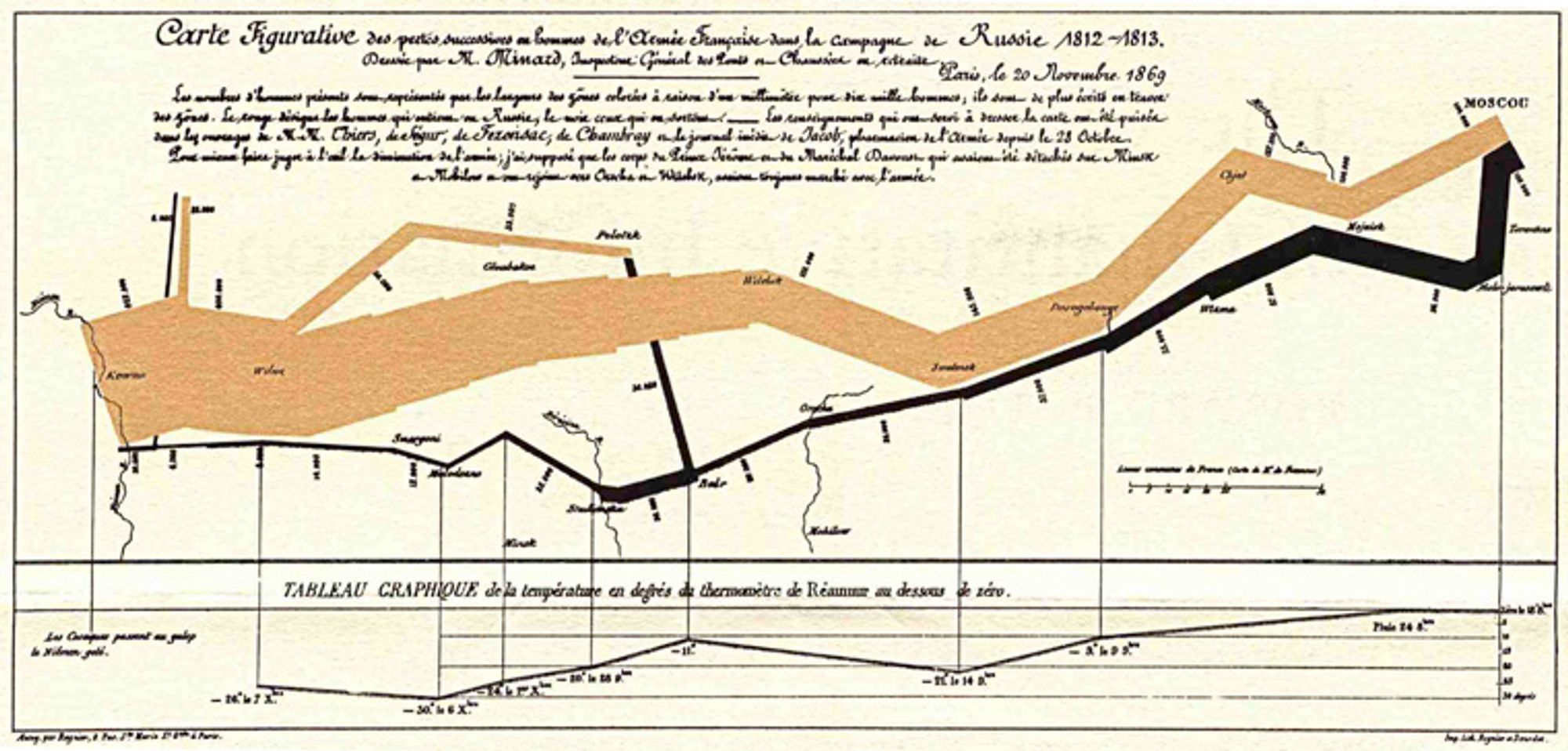
시각적 인지 노력을 최소화하기 위한 시각화 기법들
이번에는 전주의 처리(Pre-attentive Processing)라는 개념에 대해 알아보겠습니다. 데이터 시각화에서 전주의 처리란 시각적 인지의 초기 단계에 사람이 애써 인지적 노력을 기울이지 않더라도 자동적이고 무의식적으로 정보를 처리하는 과정을 의미합니다. 두드러진 크기나 색상 등을 먼저 인지하게 되는 특성을 잘 활용하면 핵심적인 정보를 잘 강조할 수 있게 됩니다.
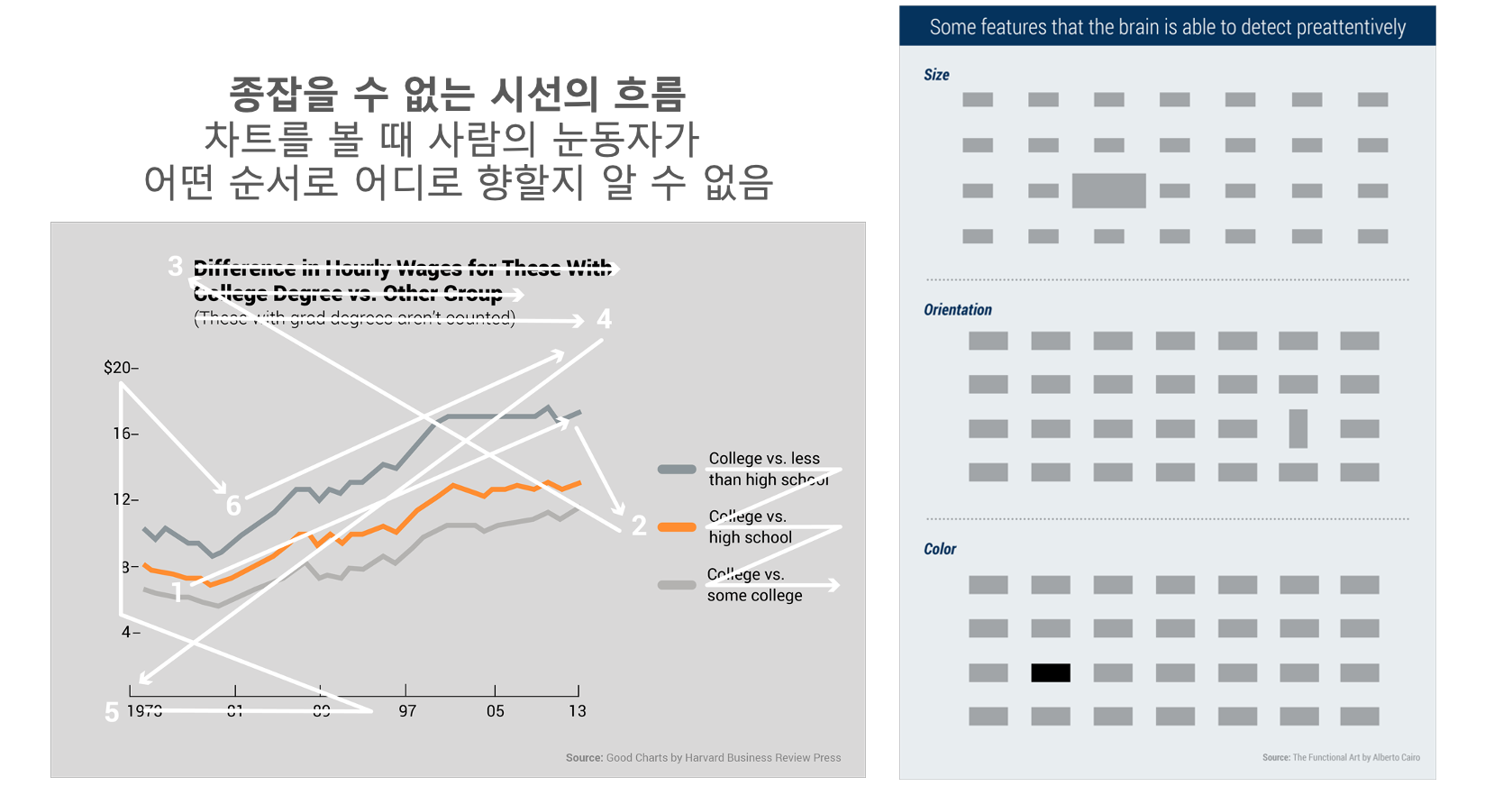
아래 그림을 한 번 들여다 봅시다. 뭐가 먼저 눈에 들어오나요?

어깨에 놓인 여섯 번째 손가락이 아니라 삐뚠 검정 이빨이 유독 눈에 뜨인 건 우리가 시각적 정보를 처리할 때 굳이 손가락 개수를 애써 헤아리도록 진화하지 않았기 때문입니다. 최소한의 인지적 노력으로 핵심 정보를 시각적으로 포착하고자 하는 우리의 성정을 고려했을 때 차트에는 강조하고 싶은 하나의 메세지와 관련된 시각적 요소만 강조하는 것이 좋습니다.
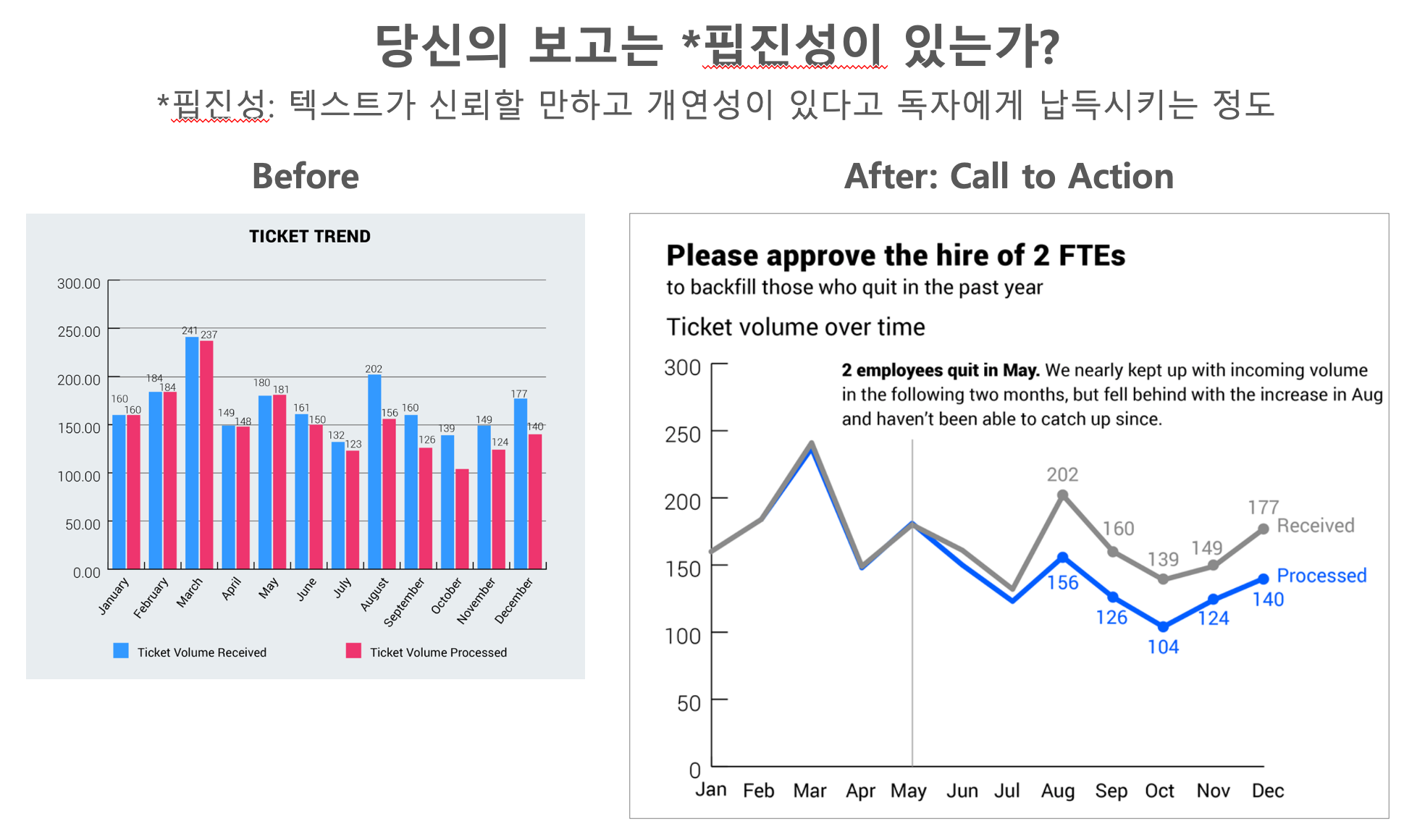
동일한 메세지(일손이 부족해서 사람이 더 필요하다)에 대한 증거로서의 차트 두 개를 놓고 어느 쪽이 더 잘 표현되었는가 따져 봅시다. 왼편, 오른편 모두 동일한 데이터를 표현한 차트이지만 오른쪽의 경우, 오월을 기점으로 처리해야 하는데 처리하지 못 하고 있는 티켓 수가 증가하고 있고, 이건 5월에 두 명이 퇴사했기 때문이라는 핵심 메시지가 잘 담겨 있습니다. 오른쪽 차트 승리!
Some Science of How We See
좋은 음악을 작곡하고 싶으면 음악 이론을 배우는 편이 좋습니다. 시각적으로 효과적인 차트를 만들기 위한 몇 가지 과학적 원칙을 소개합니다. Good Chart라는 책의 두 번째 장에 있는 내용을 정리한 것임을 밝힙니다.
- We don't go in order. 우리는 책을 읽듯이 정해진 순서대로 차트를 보지 않습니다. 사용자는 시각적 요소를 먼저 인지한 다음, 그 시각적 요소가 무엇을 의미하는지 단서를 찾기 시작합니다. 차트의 시각적 요소가 의미하는 바를 이해하는 데 도움이 되는 단서를 적절히 배치하세요.
- We see first what stands out. 사용자는 색상이나 크기 등에서 튀는 시각적 요소를 먼저 인지하게 됩니다(전주의 처리). 튀는 시각적 요소를 핵심 메세지 전달에 도움이 되는 방식으로 사용하세요.
- We see only a few things at once. 우리는 동시에 단지 몇 가지만 볼 수 있습니다. 전체적인 패턴이 아니라 개별 요소(예, 개별 범주)에 관해 이야기할 때는 개별 요소의 개수를 제한해 주세요.
- We seek meaning and make connections. 우리는 본능적으로 패턴을 감지하려고 하며, 의미를 찾고 연결고리를 만들려고 합니다. 우리의 두뇌는 패턴이 존재하지 않은 경우에도 "점들을 연결"하고 의미를 부여하려고 합니다.
- We rely on conventions and metaphors. 우리는 더 빨리 결론에 도달하기 위해 인지적 지름길을 사용합니다. 이때 관습적인 해석이 작용하기도 합니다. 빨간색에 부정적 의미를 녹색에 긍정적 의미를 부여하는 식으로 말이죠.
데이터 스토리텔링과 데이터 보고의 차이점
데이터 스토리텔링이나 데이터 보고 모두 주어진 질문/주제와 관련된 유용한 정보와 지식(Insight)을 데이터에서 발견하여 차트와 텍스트 형식으로 보고서에 담는 일입니다. 그 과정에는 다양한 가설에 대한 정량적 사실 확인, 발견된 사실에 대한 해석과 맥락 부여를 통한 지식 생산의 과정이 포함되어 있습니다.
다만, 데이터 스토리텔링이 불특정 다수를 대상으로 내 주장과 견해를 설득하는 것(참고 데이터 저널리즘)이 목적이라면 데이터 보고는 보고를 받는 사람이 좋은 견해와 의견을 형성할 수 있도록 다양한 사실들을 제공하는 일이라고 생각합니다. 내 의견과 견해를 내세우기보다는 보고받는 사람이 미처 생각하지 못했던 다양한 관점을 제공해서 보고 받는 사람이 더 좋은 견해를 생성하도록 돕는 것이 목적이 되어야 합니다.
데이터 보고서의 텍스트를 구성하는 두 가지 요소인 정량적 사실과 해석(내지는 견해) 중 그 방점은 사실에 놓여야 합니다. 사실이 정확하고 정교하다면 사람의 해석과 견해가 개입될 여지 역시 크지 않을 것입니다. 우리는 보고서에 견해를 담는 일에 집중하기보다 정확하고 세밀한 사실을 담는 일에 집중해야 한다고 생각합니다.
견해는 언젠가 진부해지지만 사실은 영원히 진부해지지 않는다.
by 미국 작가 아이작 싱어의 형
데이터 보고: People Problem vs. Technical Problem
데이터를 활용한 보고는 근본적으로 technical problem이 아닌 people problem이라고들 얘기합니다. 이 주장은 digital transformation의 성공을 위해서는 digital technology와 병행해서 그 기술을 사용하는 사람의 역량과 자세, 그리고 조직문화의 변화를 강조하는 이야기들과 그 궤를 같이합니다.
단언할 수는 없지만, 데이터 보고는 가까운 미래에 100% 자동화될 수 없다고 제법 단호하게 말할 수 있습니다. 기계에 의해 온전히 자동화될 수 없는 문제를 기술 또는 사람 문제라는 이분법으로 바라보지 말고 스펙트럼으로 바라보는 관점이 필요합니다. 데이터 기술이 닿을 수 있는 분석(패턴 발견)의 자동화 경지의 끝에 다가가기 위한 노력, 끝끝내 사람의 몫으로 남을 수밖에 없는 사실 해석과 보고서 작성과 관련된 최적의 경험 제공만이 유일한 해결책일 것입니다.
현업이 데이터를 활용하여 보고서를 만드는 일에는 크게 두 가지 장애/장벽이 있고 각각에서 기술이 풀 문제와 사람이 풀 문제는 아래처럼 정리할 수 있습니다. 기술과 제품이 해내는 몫이 커질수록 사람이 감당해야 할 몫은 줄어들게 될 것입니다.
| Barrier(장애/장벽) | 기술의 몫 | 사람의 몫 |
|---|---|---|
| Data Access | 질문과 관련된 데이터 접근 ⇒ Curated Dataset; Text-to-SQL | 데이터가 수집된 맥락 이해 |
| Data Skill | 정량적 사실 발견 및 시각화 ⇒ 패턴 발견 및 시각화 및 차트 해석 자동화 | 분석된 결과/사실 해석 |
데이터 보고 자동화 (feat. HEARTCOUNT Dialogue)
아래 영상은 데이터 보고, 특히 분석적 추론이 필요한 질문에 대한 답을 찾는 일을 돕기 위한 HEARTCOUNT의 Dialogue 동영상입니다.
보고자-피보고자의 관계에서 보고자가 아니라 보고 받는 사람이 좋은 의견을 형성하는 게 더 중요하다고 말했습니다. 데이터 도구와 실무자(보고자)의 관계에서도 데이터 도구가 확정적으로 의견을 말하기보다는, 실무자가 사실에 기반한 좋은 의견을 형성할 수 있도록 정확한 사실, 새로운 관점을 제공하는 것이 중요하다고 생각합니다.
HEARTCOUNT Dialogue는 소크라테스의 대화법처럼, 실무자가 바빠서 또는 분석적 추론 과정에 익숙하지 않아 데이터에 질문하지 못하는 좋은 질문을 제안하는 방식으로 사용자의 보고서 작성, 지식 생산에 도움을 드릴 수 있습니다.
지금 구글 계정으로 로그인하여 사용해보세요.

![[하트카운트 프리미엄 강의] HELLO! DATA!](/ko/content/images/size/w360/2023/11/231101_--------_963_963-1.png)



![[Monthly Webinar VOD] 당신의 첫 데이터 분석 파트너, 하트카운트 AI Analytics 소개 웨비나](/ko/content/images/size/w540/2024/06/5---_---------------------1080_1080.png)
![[Monthly Webinar VOD] 노션과 하트카운트로 100점짜리 보고서 쓰기](/ko/content/images/size/w540/2024/04/4---_---------------------1080_1080.png)