営利を目的として設立された企業内でデータで集団間の違いを議論する場合、その対象は働く人(従業員)か消費する人(顧客)のどちらかになりがちです。
従業員の場合は、望ましい行動を示した集団とそうでない集団の違いを見つけて以下のような活用ができます。
a.個人レベルで発見して選抜、配置などに活用できる。
b.その違いを環境的、構造的な特性で説明する。
この発見を組織文化を変えることに活用することができます。この場合、違いを説明できる特性と行動(結果)の間に因果性に対する信念が必要です。 なぜなら、その原因(特性の違い)に介入して結果(組織レベルでの望ましい行動の総量)を改善することが目的だからです。
顧客の場合、「原因→結果」のような因果的なパターンの発見よりも、望ましい行動を示す集団を知っている情報で記述することが重要です。
例として、当社のウェブサイト経由で会員登録を行った顧客とそうではない顧客を比較すると、入口が「自社メディアの技術ブログ」と「20代から30代の年齢層」である場合、コンバージョン率は15%に達し、これは平均の3%を大きく上回ることが定量的に分析できます。この傾向を理解することは、なぜこのような結果が生まれるのかの因果関係を深く掘り下げることなく、コストを抑えつつコンバージョン率を効率的に向上させる戦略につながります。
本ブログでは、データでA.集団間の特性の違いを説明し、B.特性の違いで特定の集団を区別する方法について説明します。
A. 集団間の特性の違い
グループが初めから明確に分けられている状況において、これらのグループ間で存在する特徴の差異を検討し、「グループ間には一般的な差異が存在する」と結論付けることは、特定の行動パターン(例:月間で平均7万円以上の購入をする顧客)を持つグループの特有の特徴(例:年齢、性別、結婚の有無)を特定する作業とは、目的と方法が異なる分析手法です。
「グループ間の特徴の差」を探求する際、一般的には事前に定められたカテゴリーに焦点を当てます。たとえば、「開発職と経営管理職の従業員満足度に差はあるか」や「異なる年齢層でコンバージョン率が異なるか」などの質問は、私たちが日常的に使っている分類(職種や年齢層など)を基にしています。これらのカテゴリー間で、行動(例えばコンバージョン率)や意識(例えば満足度)に目立った差が存在するかを分析することが、主な目的となります。
異なる集団の特性の差を明確にするためには、これらの差が偶然によるものではなく、統計的に有意なものであることを示す方法が求められます。
統計学で用いられるこの手法を「検定(test)」と呼びます。これは、限定されたデータセットを用いて、より大きな母集団に関する仮説を評価する過程です。このブログでは、多様な検定手法の全体を紹介するのではなく、特にStudent t-testがどのように発展してきたかについて簡潔に触れてみたいと思います。
Introducing Statistics: A Graphic Guide
ギネス醸造所と最初の統計検定
・20世紀の初めに、ギネス醸造所に所属していた統計学者兼化学者のウィリアム・シーリー・ゴセットは、統計的品質管理の検定手法の先駆者でした(ゴセットは会社の方針で自身の名前を使用しての出版が禁止されていたため、論文を発表する際には「Student」という筆名を使用していました)。
・ギネス社に勤める中で、ウィリアム・シーリー・ゴセットは、ビール製造の原料と最終製品の品質に関連する多くの化学的実験データを調査しました。彼は特に、大麦やホップなどの原材料が完成したビールの品質にどのように影響を与えるかについて、深い関心を持っていました。
・ゴセットがデータの分析を行う上で遭遇した主な障害は、測定値の大きなばらつきと、利用可能なデータ(観測値)の少なさでした。
・ギネス社では、優れたビールの品質を維持するため、注目すべき原材料の差異と無視可能な差異を区別することが重要な課題でした。この問題を解決するため、ゴセットは1905年7月12日に、当時の統計学の権威であるカール・ピアソンとの会合を設定しました。

Small Samples vs. Large Samples
・ウィリアム・シーリー・ゴセットは、カール・ピアソンに対して、サンプルサイズの小ささが統計分析上の大きな問題であると伝えました。なぜなら、ピアソンの統計検定方法は小規模なサンプルに適用すると、歪んだ結果を生み出す恐れがあったからです。この問題を克服するため、ゴセットは天文学で使用される手法とピアソンの統計手法を統合し、新たな統計ツールの開発に取り組みました。
・また、ゴセットは異なる大麦品種が生産するビールの品質を比較する研究を行いました。これらの品種は隣接する2つの畑で栽培されていました。彼は小規模なサンプルデータを利用して、サンプル平均と母集団平均との間の有意な差異を調査するために、z-ratio(またはz-test)という概念を導入しました。

Student's t-test
・ウィリアム・シーリー・ゴセットが開発したz-ratioを用いて行った大麦の品種とビール品質の分析から、ギネスビールに最適な大麦の品種が「アーチャー」と判明しました。これを受けて、ギネス社はデンマークからアーチャー大麦の種を入手し、提携農家に配布。結果として、より良い味わいのビール生産が可能になりました。
・ゴセットの開発した新たな統計的検定法のおかげで、ビール醸造の複雑なプロセスにおいて、品質に影響を与える要因の相対的な重要性を正確に判別することができるようになりました。このz-ratioは、工業品質管理のための初期の統計的テストとして認識されることになります。
・R.A.フィッシャーはゴセットの統計テストに感銘を受け、1924年にゴセットのz-ratioをもとにして「Student's t-test」としてさらに発展させました。彼はz-テーブルの値を再計算し、t-テーブルに置き換えて「Student's t-distribution分布」と名付けました。
・フィッシャーはその後、三つ以上のグループ間の特性差を検定する方法であるANOVA(分散分析)を発明し、この分野をさらに深めることになりました。

統計的有意性と実用的有意性のジレンマ
(Statistical Significance vs. Practical Significance)
しかし、現代の企業環境においてt検定を用いてデータを解析する際、世界が大きく変化し、標本と母集団の境界線が曖昧になってきています。実際、多くの企業が収集するデータの標本が母集団と直接一致するケースが増えています。
考えてみれば、従業員に関する分析を行う際、多くの場合は全従業員のデータに基づいて行われます。この標本=母集団という状況下では、標本における観測された違いを母集団に一般化して適用することの科学的妥当性については、仮説を立てて検証することは科学的であると言えますが、実際には必ずしも実用的ではないと考えられます(これは私個人の意見です)。
それでも、データに基づく意思決定が求められる場合、統計的な有意性の判断は重要です。これは、組織内での意思決定に科学的な裏付けと心理的な安心感を提供するためです。つまり、効果的な意思決定を行うには、実用的有意性(Practical Significance: その決定がビジネスに与える影響の大きさ)と統計的有意性(Statistical Significance: 観察された関連性や差異が偶然によるものではないという数学的根拠)の両方が必要とされます。
B. 特定の行動を示した集団特性
特定の行動を示す集団の特性"については、既知の、あるいは入手可能な属性情報(例えば、50歳以上の既婚者でレジャー活動を好む人など)を活用して、私たちの関心対象である特定の行動(例:月に平均百万ウォン以上を購入するVIP顧客)を行う集団をできるだけ正確に定量的に描写することが求められます。これらの属性を持つ人々が常にその行動(多額の購入)をするわけではありませんが(属性と行動の間に直接的な因果関係はないため)、その行動を示す確率が平均よりも高い場合、その条件をターゲットマーケティングに利用することができます。
このウェビナー動画では、ある集団が示す特定の行動の特性を個々の変数ごとに、または複数の変数の組み合わせによって理解する二つのアプローチについて解説しています。しかし、本ブログでは、デシジョンツリー(Decision Tree)アルゴリズムを用いて、特定の行動を示す集団の特性を変数の組み合わせを通じて理解する方法に焦点を当てて説明します。
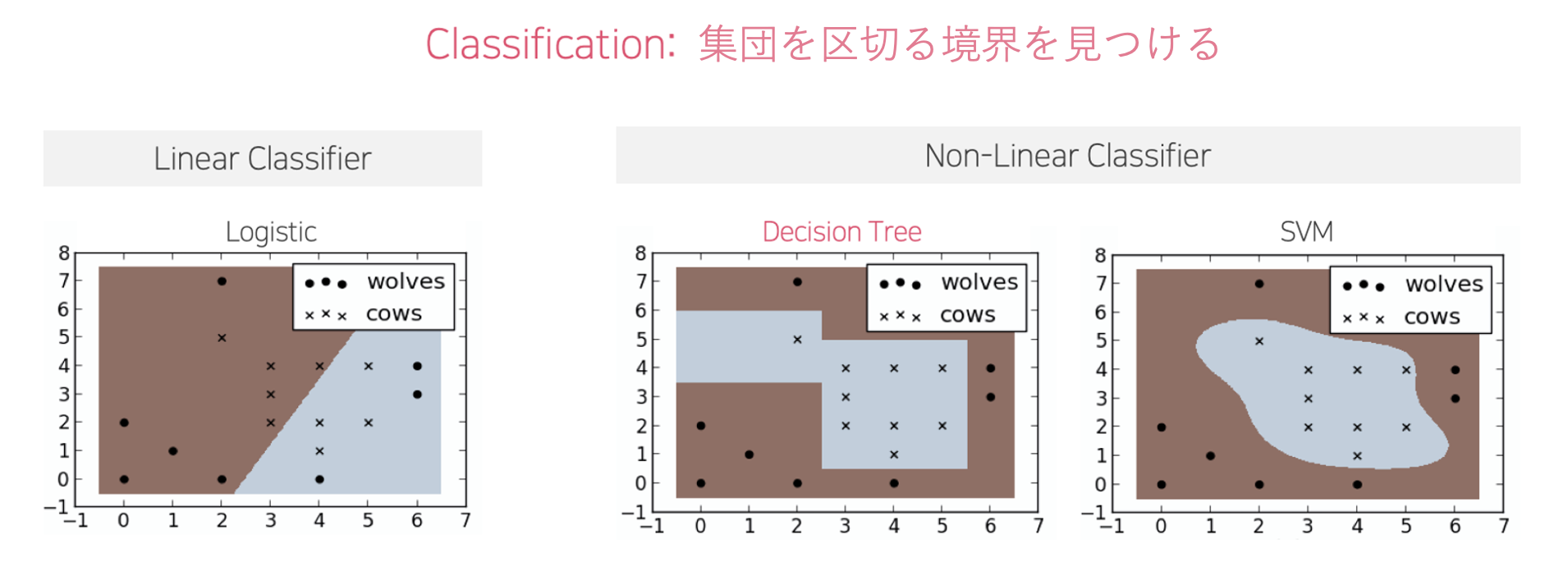
Decision Tree: 解釈が可能な分類(Classification)アルゴリズム
代表的な分類モデルであるDecision Treeは、そのルール(直線的に集団を区分する)のシンプルさから、その結果を人が理解し、マーケティングなどに適用するのに適しています。
提供された保険金請求データセットを活用して、保険会社として望ましい行動を取る集団(最近6か月間入院歴のない人々)とそうでない集団を区分するための基準を、デシジョンツリー(Decision Tree)アルゴリズムを使用して見つけてみましょう。
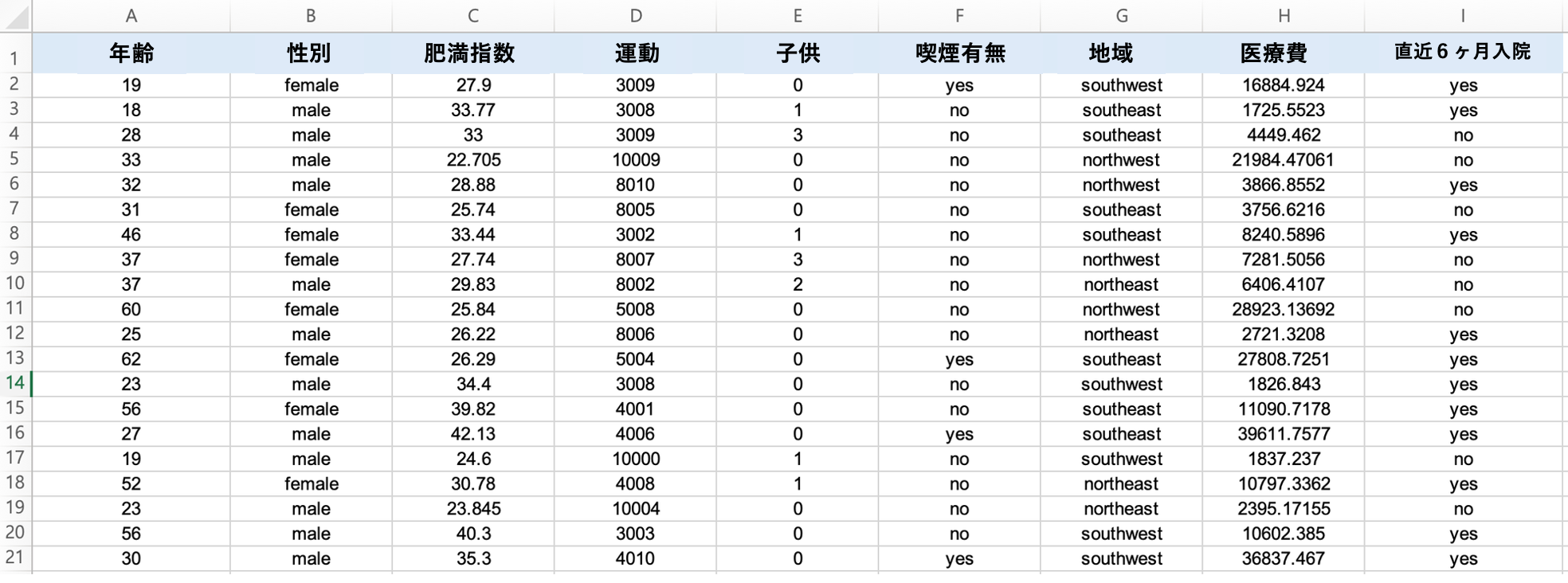
下のHEARTCOUNTでDecision Treeを回した結果を記録した映像のように、「入院有無=No」である集団(青色表示)の代表的な属性は
- 肥満指数が25以下であり、かつ非喫煙者である人々(肥満指数 < 25.98 & 喫煙有無 = no)のグループに注目しました。
- この基準に該当する被保険者は合計250人おり、その中の92.8%が最近6ヶ月以内に入院歴がありません。この割合は、全被保険者の中で「過去6ヶ月以内に入院していない」割合である41%と比較してもかなり高い数値です。
- このような規則は、病院への頻繁な入院の可能性が低い人々を対象としたマーケティングキャンペーンにおいて、貴重なターゲット条件となる可能性があります。



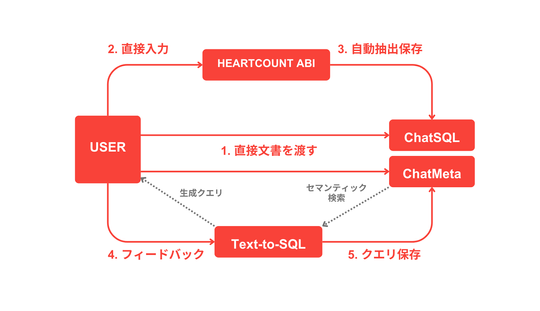
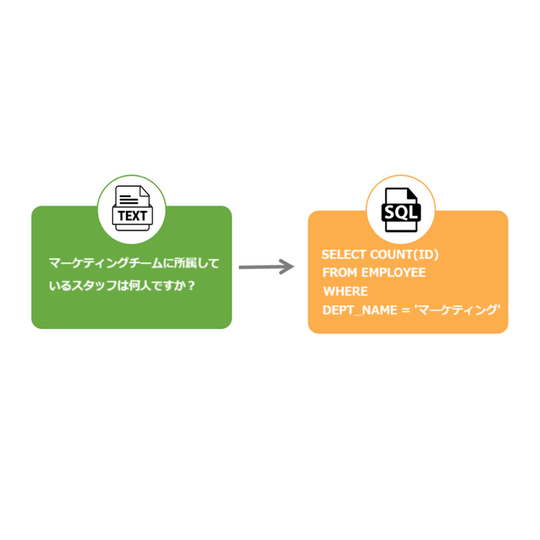
![[HEARTCOUNT実習例] HR dataset - I(人事分析)](/ja/content/images/size/w540/2024/10/------_--------_-----_--------_-1-.png)