2つの集団を区別する特徴を見つける関連シリーズ
タイタニック号データ 1:データから集団を区別する特徴を探す
タイタニック号データ 2:生存者/犠牲者のルールを発見する
データからSignal(有意な差)とNoise(偶然による差)を区別する方法
Intro
データのSignalとNoiseとは?
ビジネスの観点からデータ分析とは、目標変数(Y)の値の差を説明することであり、差は本質的な差と偶発的な差の合計で構成されます。
全国の個々の営業店が示す純利益率の差は、営業店の本質的な性能(技量)の差の反映である場合もあれば、単に運が良くて商売がうまくいった(いかなかった)ことの反映である場合でもあります。
本質的な、だから一般化できる違いをSignalとし、偶然(Chance)によって誘発された違いをNoiseとしたとき、SignalとNoiseをどのように区別することができるでしょうか(偶発的または架空の配列に基づく違いを本質的な違いと主張したのが差別の歴史でもあります)。
ちなみに、安定したシステムほど、システムを構成する個々の構成要素のスキルの差が少なくなる。これは、構成要素(例えば、営業店)がbest practiceを互いに学習した結果、販売のスキルが互いに似てくるようになり、結局利益の差(変量)も小さくなるからです。
このようにスキルの差が少ない構成要素で構成されたシステムでは、個々の構成要素の成果差に及ぼす運の影響力が比較的大きくなりますが、このような現象をスキルのパラドックス(Paradox of Skill)といいます。
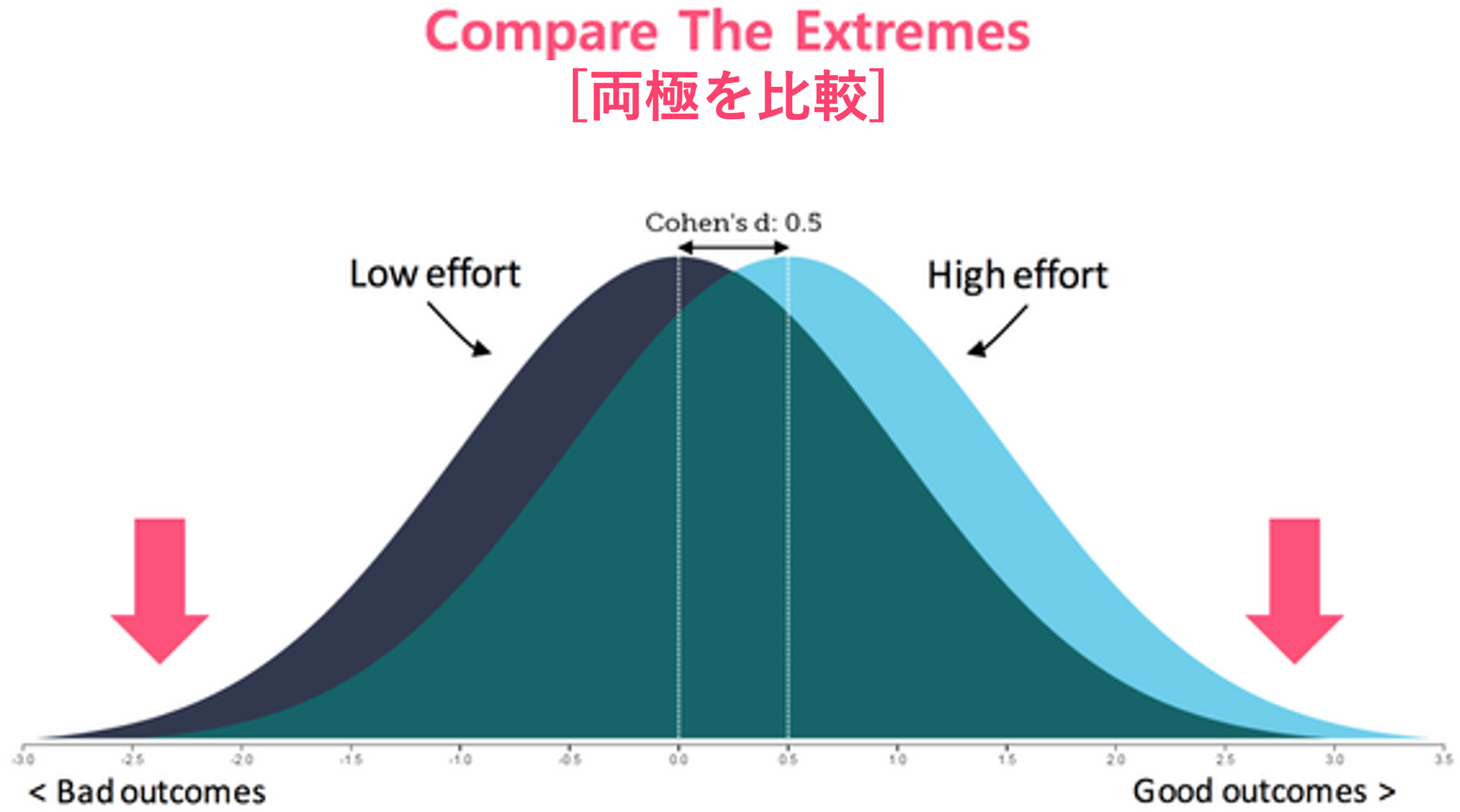
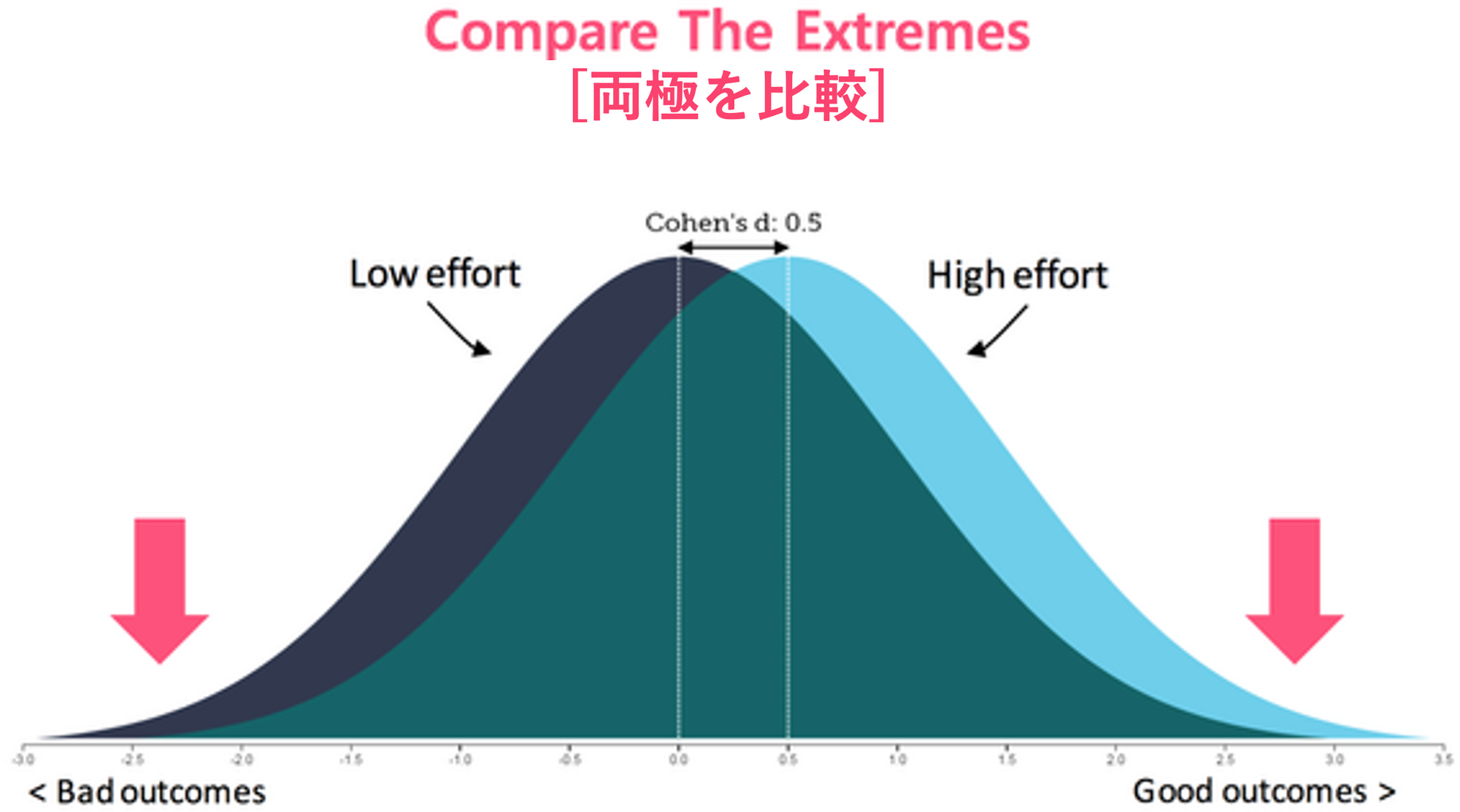
両極端の2つの集団を比較する
今月、営業店Aの周辺で大きな国際イベントが開催され、営業店Aの利益が例外的に高かったとします。営業店Aの利益は、来月はおそらく再び平均(普通)に回帰するでしょう。 (Regression to Mean/Mediocrity)
しかし、過去2年間、着実に高い利益率を出した営業店は、運(偶発的な出来事;Noise)のせいではなく、店舗に内在する本質的な実力が利益の違いで現れたと考えることができます。 (逆に、着実な商売ができない営業店の場合も同様です)
ある特性(利益)の両端に位置する対象(例えば、利益率上位/下位20%代理店、業績スコア3年平均上位/下位20%である社員)を比較すると、スペクトルの真ん中に位置する判断が難しい社員(運と技量が均等に混ざっている子)が分析対象から除去され、与えられた特性(利益)差をもたらすより本質的な要因(パターン、Signal)を見つけることができます。
Decision Tree Algorithm(決定木アルゴリズム)とは?
異なる二つの集団の顕著な違いを通じて二つの集団を、完璧ではないかもしれませんが、最大限、互いに集まるように分類(Classification)するルールを探す代表的な分析アルゴリズムが決定木(Decision Tree)です。
例えば、長期勤続者(A)と早期退職者(B)は、異なる二つの集団を区別する論理的なルールを意思決定ツリーアルゴリズムを通じて以下のように見つけることができます。
- 長期勤続者分類ルール: [年齢 >= 27] & [採用経路=新聞広告]の場合90%の確率で長期勤続者
- 早期退職者の分類ルール: [年齢 < 27] & [学歴=修士or博士]の場合、93%の確率で早期退職
Analysis in HEARTCOUNT
Dataset: Superstore
ウォルマートの売上関連変数が集まっている'SuperStore'というデータでSignalとNoiseを分離する実習をしてみましょう。 主な変数を見ると、
- 利益
- 売上高
- 割引率
- 配送方法
📎 実習で使用した売上データをダウンロードする
Analysis
独自のDecision Treeアルゴリズムが実装されているHEARTCOUNTのセグメンテーションを実習に使ってみます。
<レシピ>
FurnitureのProfitが上位20%のグループと下位20%のグループを比較分析し、両極端の2つの集団(Top 20% vs. Bottom 20%)を分類するルールを見つけようと思います。
- スマートフィルター機能で[Category=Furniture]に設定すると、家具の売上データのみを分析することができます。
- 集団区分の基準になる変数として[Profit]を設定します。
- 数値型変数を目標変数に設定すると、自動的に上位20%(top 20%)グループと下位20%(bottom 20%)グループに分類されます。
<分析結果の解釈>
- 結果はtreeまたはsunburst形式で表現することができます。
- tree形式の視覚化では各node(円)をクリックすると該当ルールを確認することができ、sunburst形式では色で区切られた弧(arc)にマウスオーバーすると分類ルールを確認することができます。
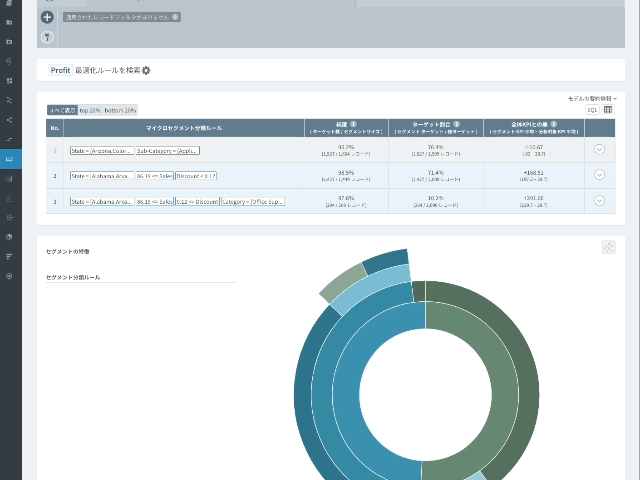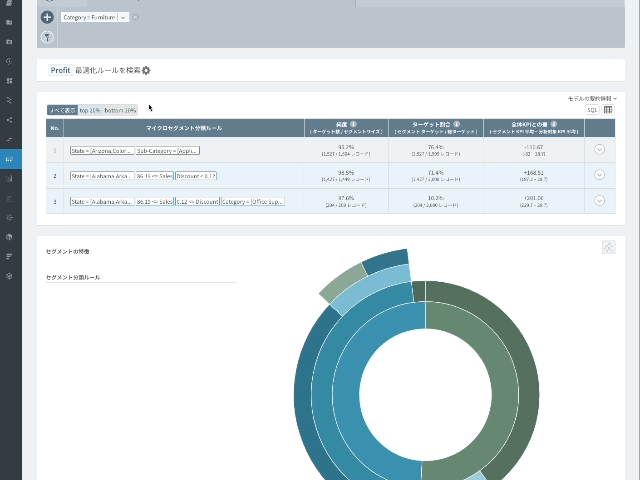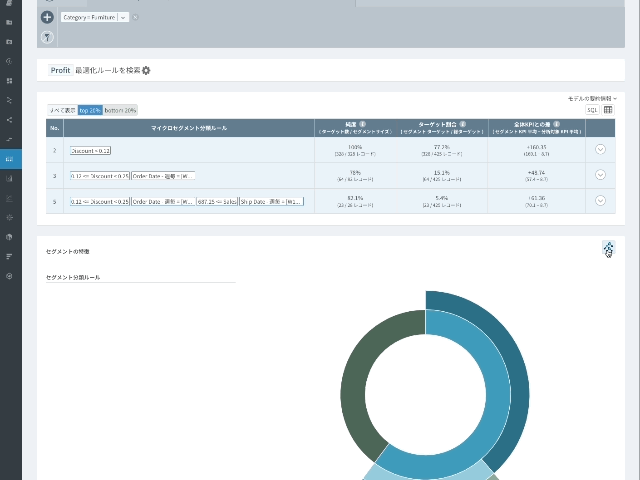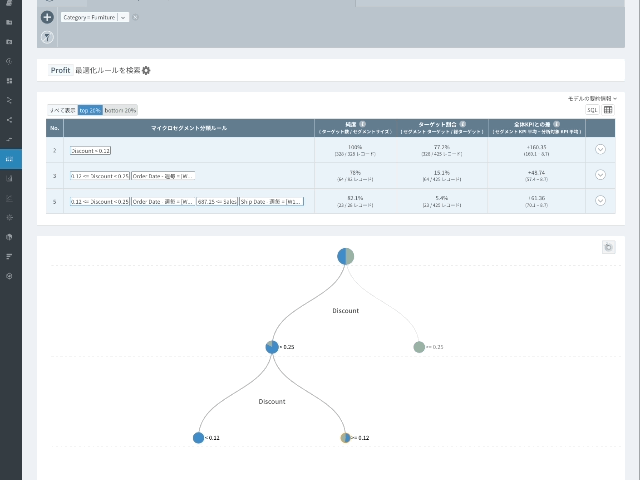
セグメンテーションの結果画面
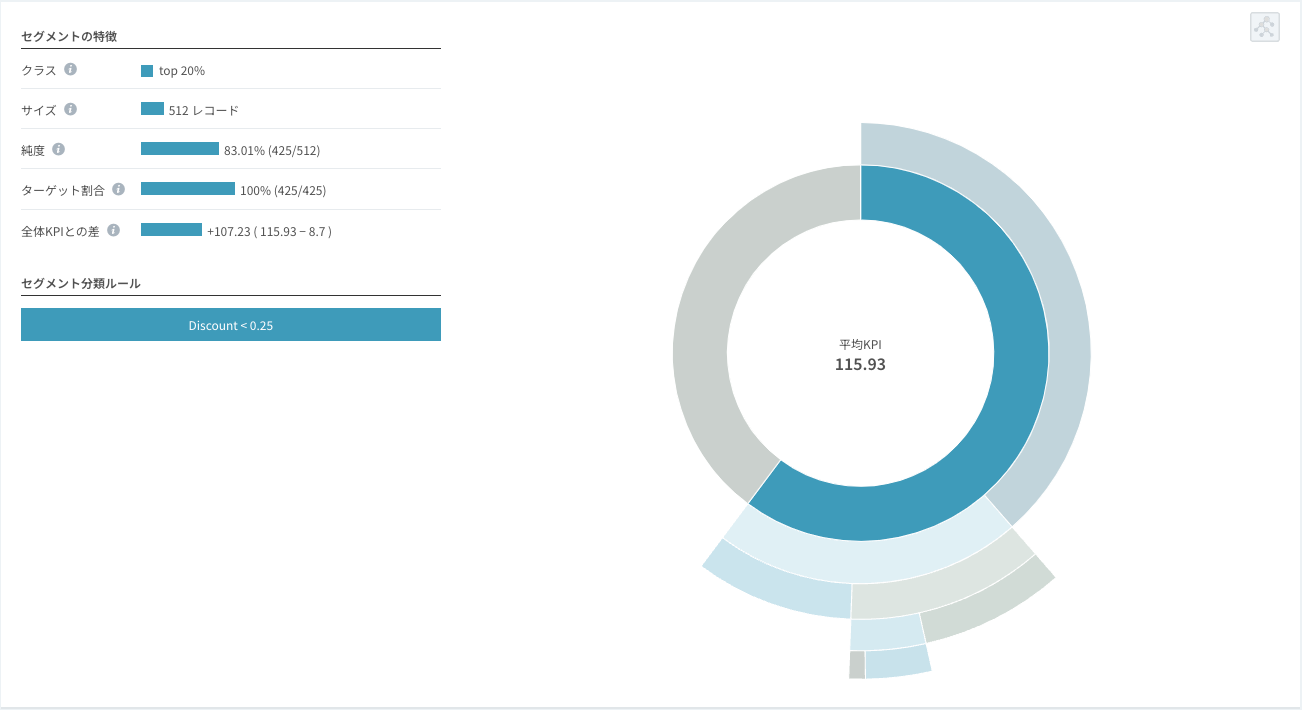
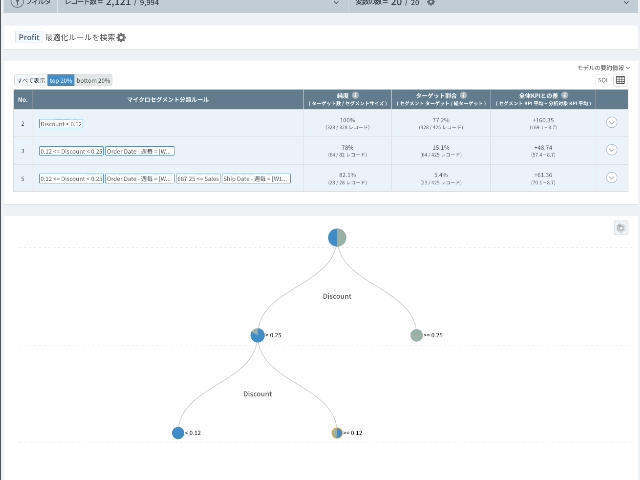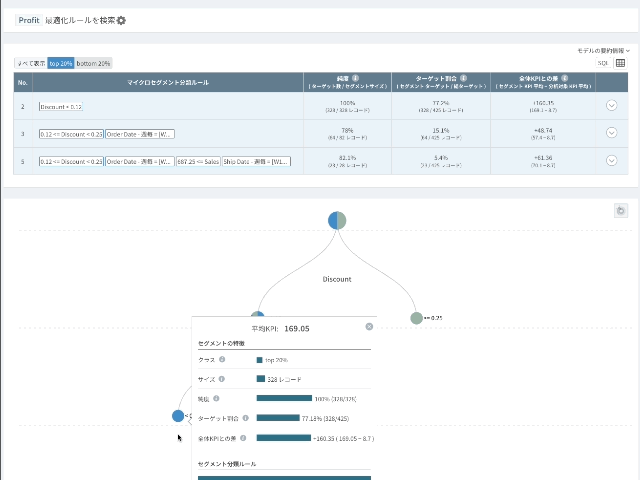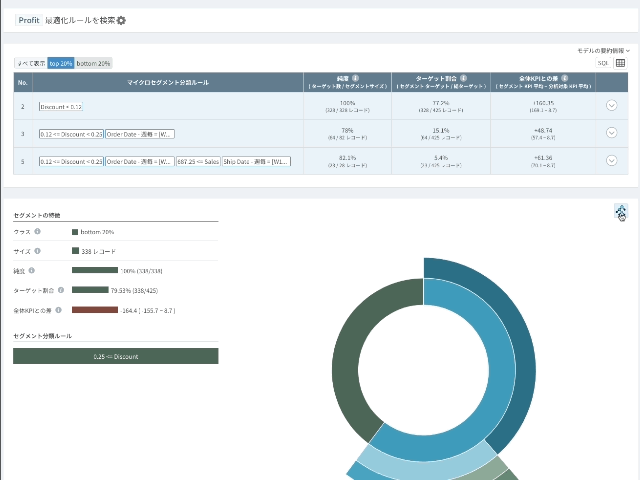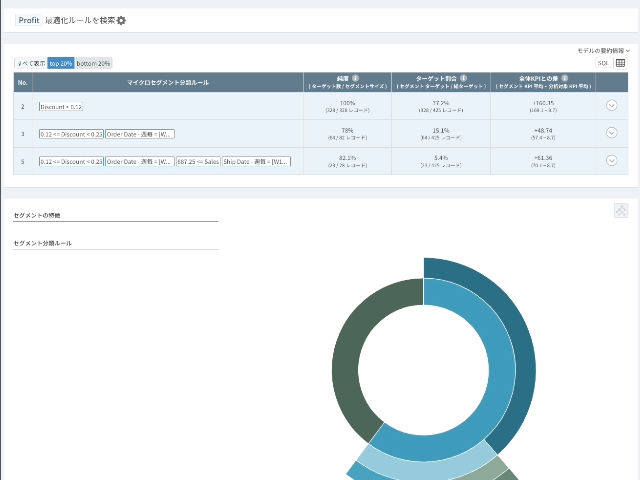
- 純度(分類ルールがどれだけ正確であるかを測定することができる。): 分類ルールに該当するすべてのレコード(割引率が0.12以上0.25未満、売上高が579.64未満の場合)の68.49%がFurnitureのProfitの下位20%である。
- ターゲット比率:FurnitureのProfitの下位20%である総販売件数のうち14.25%がこのルールで説明される。
分類ルール(モデル)をさらに絞り込むこともできます。
- セグメンテーションの分類ルールは、基本設定上、ターゲット変数を除いた残りの変数で発見されます。
- 範囲をさらに狭めるために、変数フィルターを通して決めたり、分析結果にある変数を変数フィルター領域にドラッグ&ドロップすると、その変数を除いた残りの変数で分類モデルが作成されます。



![[HEARTCOUNT実習例] HR dataset - I(人事分析)](/ja/content/images/size/w540/2024/10/------_--------_-----_--------_-1-.png)