
이전 글에서 데이터 기반 의사결정이 잘 안되는 이유 중 아래 두가지에 대해 이야기했다.
"A. 쓸만한 데이터가 없다. and B. 분석 결과가 의미없다."
그럼, 이번 편에서는 데이터 기반 의사결정이 잘 안 되는 이유 세 번째, ‘바쁘고 어렵다’에 대해서 이야기해보겠다.
C. 바쁘고 어렵다.
바쁘고 어려워서 못 하고 있다는 것은 그 일의 우선 순위가 낮다는 것.
바쁘고 어렵다는 이유로 특정 업무를 잘 못하고 있다면 그 일은 중요한 일이 아니기 쉽다. 데이터 분석을 잘 하는 것이 본연의 업무인 데이터 분석 전담조직 말고 현업 부서들의 경우 데이터 분석하는 일이 업무의 (최)우선 순위이기 힘들다. 데이터 분석을 “배우고 때때로 익히면" 어찌 기쁘지 않겠냐만은 더 중한 다른 일로 바빠서 새로운 일을 제대로 해낼 시간이 없는 것이 현실이다.
데이터 분석이 주업무가 아닌 조직의 경우 어떤 형태로 일해야 할까?
해결책은 일부 직원들에게 데이터 분석하는 일을 공식 업무/과업으로 할당하거나, 한 번 일을 제대로 크게 벌리고 싶다면, 분석 전담팀을 꾸리는 것이다.
기존 직원에게 분석 업무를 추가로 할당하면 절대 안 된다. 기존에 하던 일들 중 일부를 실질적으로 덜어내 주고 그 공백을 분석 관련 일로 메우도록 해야 한다. 북핵 폐기와 관련하여 CVID(Complete, Verifiable, Irreversible Dismantlement)를 강조하듯이 그렇게 확실히 기존 업무를 덜어줘야 한다.
데이터 분석을 위한 TF 조직도 예시
아래 그림은 HR 부서 내에서 인사데이터 분석을 수행하는 People Analytics Team을 새로 꾸린다고 가정했을 때, 해당 팀의 역할과 다른 팀과의 관계를 정리한 것이다. 처음에는 본인 리소스의 30~50% 정도를 사용하는 한 두명으로 구성해서 운영하다가 잘 되면 팀을 양적, 질적으로 성장시키면 좋겠다.
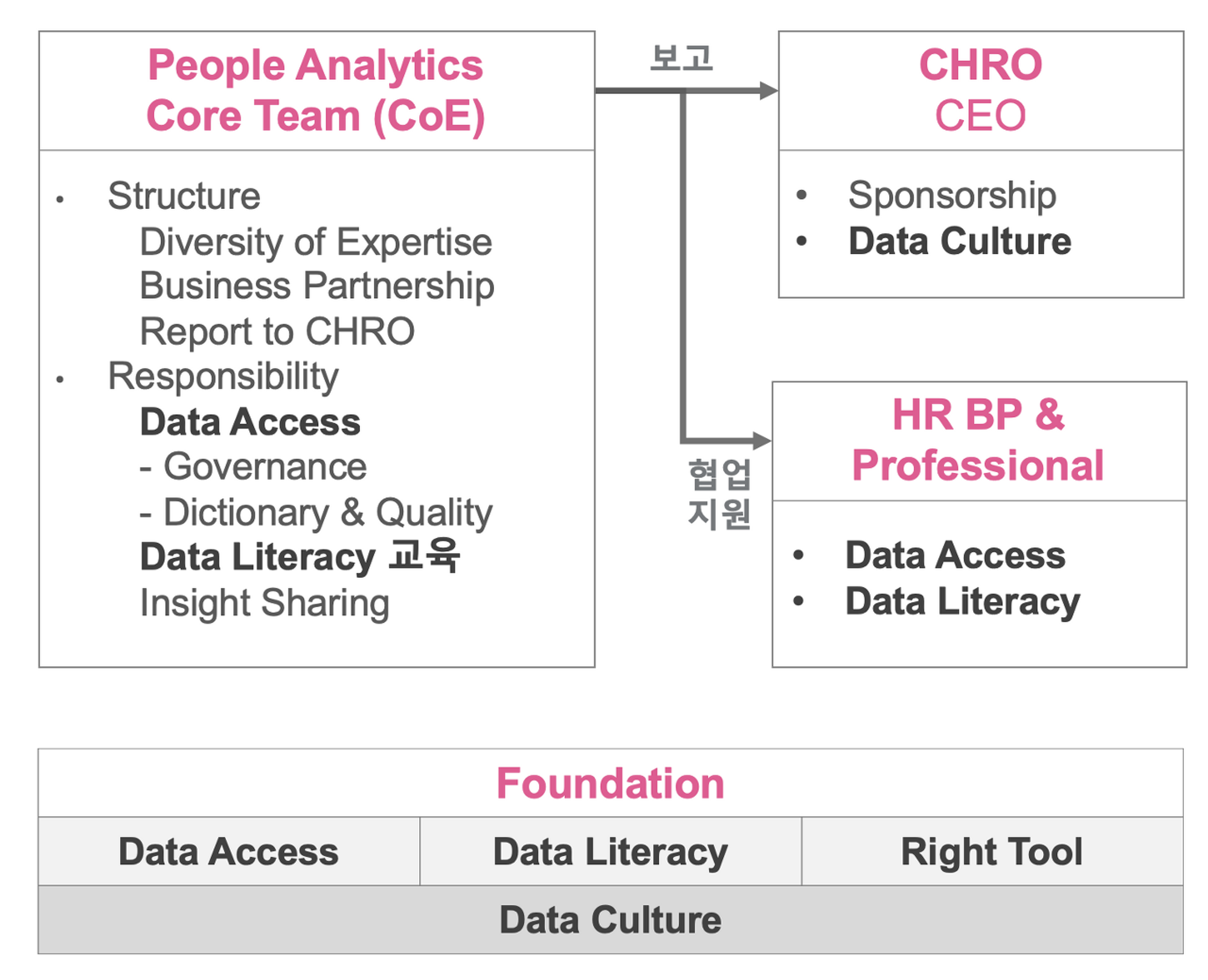
위 도식에 표현된 People Analytics Core Team(데이터 분석 TF팀)의 주요 역할과 구조를 살펴보면,
- Data Access: 부서 내 다른 구성원들이 필요로 하는 최신의 신뢰할 수 있는 데이터를 제공하는 역할이다.
Data Access 역할은 다음 세가지 세부 역할로 나눌 수 있다.
a) Data Dictionary(Catalogue): 부서 내에서 수집, 관리하고 있는 데이터(변수)의 종류, 데이터의 원천(Source: 근태시스템, 채용시스템, HRIS 등), Ownership 등을 관리하는 일
b) Data Quality: 데이터의 품질을 개선, 유지하는 일
c) Data Governance: 데이터(변수)의 민감도 및 중요도에 따라 접근 권한 및 활용에 대한 원칙을 수립하고 지켜내는 일
위에서 이야기하는 Data Governance는 기술적인 통제/보안이나 Regulatory Compliance 관련 정책을 수립하는 일이기 보다는 오히려 데이터 사용과 관련된 투명한 원칙을 수립하는 일에 가깝다. 아래 링크를 참고하면 좋겠다.

- Data Literacy: 의사결정을 위한 분석 활동은 사회적 상호작용이다. 좋은 책을 읽고자 하는 사람이 있어야 좋은 책을 쓰는 사람이 존재할 수 있듯이 분석하는 사람(Producer)과 분석 결과를 활용하는 사람(Consumer)이 유기적으로 함께 존재해야 한다. Core Team은 동료나 매니저들이 분석 결과를 실용적으로 활용할 수 있도록 데이터 활용에 대한 기본 교육에도 일정 부분 책임이 있다. Core Team이 직접 강의를 할 수도 있고 외부 콘텐츠를 Curation하여 커리큘럼을 짤 수도 있겠다. (참고: 에어비앤비 사례)
- Insight Sharing: 분석 결과를 일선의 담당자 및 의사결정권자들과 공유하여 실용적으로 활용되도록 하는 일이다. 개념적으로 쉽게 동의할 수 있는 말들이 대부분 그렇듯이 어려운 일이다. 아래 [분석 결과가 쓸모있으려면]에서 좀 더 구체적인 생각을 나누도록 하겠다.
- Reporting Structure: 분석의 독립성을 위하여 CHRO나 필요하다면 CEO에게 직접 보고하는 것이 바람직하다. 보고 라인이 길어지는 경우 최초의 데이터/사실 중심의 거칠지만 담백했던 보고 내용에 자의적 해석이 덧칠되어, 결국 “그분이" 보고 싶고 듣고 싶은 것을 익숙하고 세련된 방식으로 보고하게 되는, 그래서 현실에서 한 걸음도 나아가지 못하는, 경우가 많기 때문이다. (아쉽게도 국내에 CHRO 직속 조직으로 People Analytics 팀이 운영되고 있는 사례를 아직 알지 못한다.)
데이터 분석이란, 데이터의 쓸모(유용성)을 찾는 것.
데이터 분석이 무엇이냐고 묻는다면 “데이터의 쓸모를 찾는 일”이라고 답하겠다. 데이터를 통해 세상, 사물, 사람에 대한 인식이 더 정확하고 깊어질 수 있겠지만 기업 내 데이터 분석의 목표가 나의 인식을 풍부하고 정교하게 하는 일이 될 수 없다. 쓸모가 있다는 것은 비지니스 문제를 해결한다는 것이다. 쓸모 있는 분석을 한다면 조직에서 더 잘하라고 물심양면으로 아낌없는 조직적 지원을 해줄 것이다.
조직에게 쓸모 있는 데이터 분석을 해내려면,
특정 세그먼트(집단)을 타겟팅하고 최적화 방법을 찾을 줄 알아야 한다.
데이터 기반 의사결정 맥락에서 분석 결과의 쓸모는 크게 두가지로 나눌 수 있다.
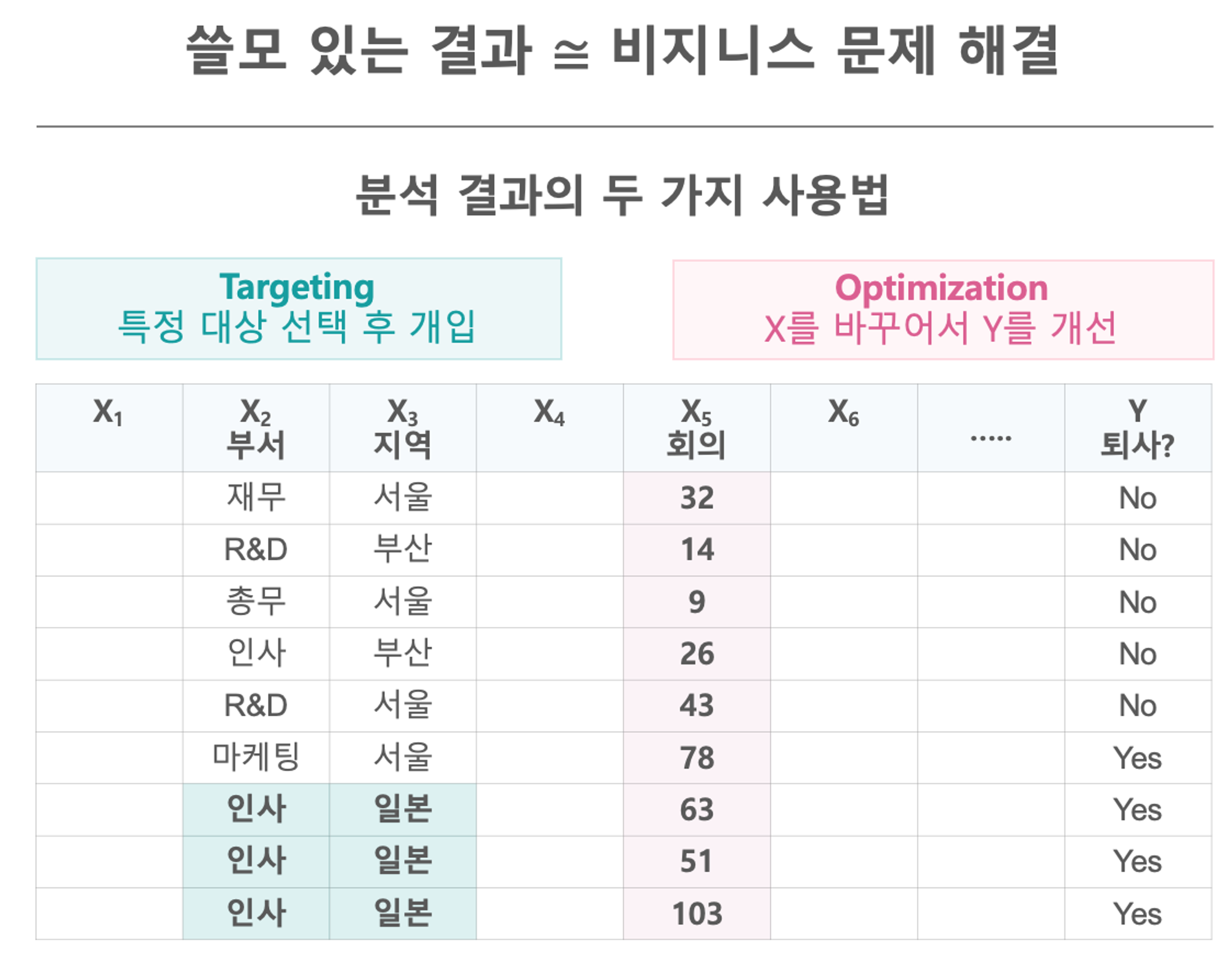
- Targeting
특정 행동이나 특성을 보이는 사람(레코드)이 밀집한 집단(Segment)을 찾는 일이다. 아래 표처럼 일본에서 근무하고 있는 인사부서 사람들의 퇴사율이 타 집단 대비 월등히 높다면 해당 세그먼트를 타겟으로 적절한 조치를 취할 수 있겠다. Targeting이 분석의 목표인 경우 Why(왜 퇴사했는지)는 중요하지 않다. 특정 행동이나 특성을 보인 사람(레코드)이 밀집한 집단을 찾는 것이 목표이다. - Optimization(Intervention)
최적화(개입)는 목표변수(Y)의 원인(X)을 찾아 X에 개입하여 Y를 개선하는 일이다. 이 경우 X와 Y 사이의 인과성(Causality)이 반드시 필요하다. 아래 표의 경우 X(회의 시간)와 Y(퇴사율) 간에 패턴이 발견된 경우 X에 개입하여 Y를 개선할 수 있겠다.
인과관계 vs 상관관계
최근까지도 통계나 데이터 분석을 하는 사람들 사이에서 금기시 되는 단어가 있는데 바로 인과성(Causality)이다. 이건 지금 학교에서 가르치는 통계학의 기반을 다지신 분들의 “인과성을 따지는 것은 과학적이지 못한 태도이며 상관관계(Correlation)만으로 이야기를 해야 한다”는 가르침이 지금까지 이어져온 탓이 크다. 다른 한편으로는 통계나 데이터 분석에서 인과관계를 표현할 보편적 언어(수학적 표기법)를 아직 개발하지 못한 탓도 있다.
바로 위에서 회의시간과 퇴사율 간의 인과성에 대해 단정적으로 결론을 내렸는데, 인과관계에 대한 이야기는 별도의 포스트를 통해 다루도록 하겠다.
Judea Pearl과 같은 분들이 데이터에서 인과성을 과학적으로 찾고 그 내용을 기술하는 방법을 수립하기 위해 많은 노력을 기울이고 있다.
아쉬운대로, 인과성에 대한 검증을 위한 대표적 방법인 CRT에 대해 알고 싶은 분은 아래 참고. Controlled Randomization Trial(Experiment)
 Amy Gallo
Amy Gallo
X와 Y 간에 인과성이 존재한다고 (사회 통념상 또는 별도의 실험을 통해 증명) 가정했을 때 X에 개입하여 Y를 개선하기 위해서는 추가적으로 두 개의 조건이 더 필요하다.
- X에 개입(Intervention) 가능: 예를 들어 인지점수(X1)가 높고 미사용 휴가일수(X2)가 적은 사람들이 영업성과(Y)가 좋다고 했을 때, X1에 대해서는 인위적으로 개입하기 힘들지만 X2는 의지만 있다면 개입할 수 있다.
- Y의 개선 측정(Monitoring) 가능: 영업직군을 대상으로 눈치보지 않고 자유롭게 휴가를 사용하도록 해서(X2에 개입), 영업성과(Y: 매출, 신규고객 유치 등)과 정말 좋아졌는지 여부를 모니터링할 수 있어야 한다. 만약, Y가 상대평가한 성과 등급/점수였다면 개입에 의한 Y의 개선 정도를 측정하기 어렵겠다.
Data-Driven Decision-Making vs. Data-Driven Problem-Solving
더 좋은 의사결정을 내리기 위해 데이터 분석을 하는 경우 분석의 궁극적 목표는 비지니스 문제 해결이라고 했다. 데이터 기반 의사결정은 데이터 기반 문제해결의 수단이자 방법이지 그 자체가 목표는 아니다. 해결되는 문제는 하나도 없이 꿋꿋하게 데이터에 기반하여 의사결정을 내릴 수 있겠지만 본인이 제일 힘들어질 것이다.
개선하고 최적화해야 하는 Metric/KPI가 없는 조직은 없을테니 분석할 데이터에서 Y를 찾기 힘든 경우는 드물다. 그리고, Why가 아닌 Who를 찾는 Targeting 분석의 경우, X(입력변수)를 조합하여 Targeting할 대상을 찾는 일도 아주 어렵지 않다.
하지만, 내가 이미 가지고 있는 데이터에서 Y에 대한 원인이면서 동시에 개입할 수도 있는 X를 찾는 것은 많이 어렵다. 특정 분석 프로젝트의 목표가 내가 개입할 수 있는 원인변수를 찾는 거라면 분석 하기 전에 확보한 데이터 안에 그런 변수가 있는지 먼저 살펴볼 일이다. 만약, 없다면 설문이나 실험을 통해 채워 넣으면 될 일이다.
“data! data! data!” he cried impatiently. “I can’t make bricks without clay.”
by Sherlock Holmes

![[하트카운트 실습 예제] 보험사 고객 dataset](/ko/content/images/size/w360/2023/10/------_--------_-----_--------_-2--1.png)