2つの集団を区別する特徴を見つける関連シリーズ
タイタニック号データ 1:データから集団を区別する特徴を探す
タイタニック号データ 2:生存者/犠牲者のルールを発見する
データからSignal(有意な差)とNoise(偶然による差)を区別する方法
Intro: 決定木アルゴリズム
村上春樹のノルウェーの森には、「世の中にあなたを理解しようと努力することを楽しむ人が一人くらいいても悪くないですよね」という一文があります。
“だから、あなたを理解しようとして楽しんでいる男がたまたま世界に一人いたとして、何が悪い?”
決定木(decision tree)もデータに含まれるルールと秩序をあなたに理解させようとする数少ないアルゴリズム(white box model)の一つです。
今回は、データを勉強した人なら一度は聞いたことがある"titanic dataset"で決定木が動作する仕組みとモデル(分析結果)の解釈方法を見ていきます。
決定木: 異なる(二つの)集団を分類するルールを作る方法
ジャンル的には、決定木は異なる集団を分類するモデルを作るClassificationアルゴリズムです。
下の図のように二次元の平面上に分布したオオカミと牛を分類する方法は以下の通りです。
- 一つの直線(左端の図): 単純だが、牛とオオカミがよく区別がつかない。
- 曲がりくねった曲線(一番右側): 非常によく分類されるが、分類された規則が複雑で、人に日常の言語で説明するのが難しい。
- 直線で空間を区画(中央): 分類も結構よく、分類されたモデル(ルール)を理解しやすい(white box model)意思決定木は下の真ん中の図のようにオオカミはオオカミ同士、子牛は子牛同士が集まるように空間を直線を使って区画する方式で動作します。
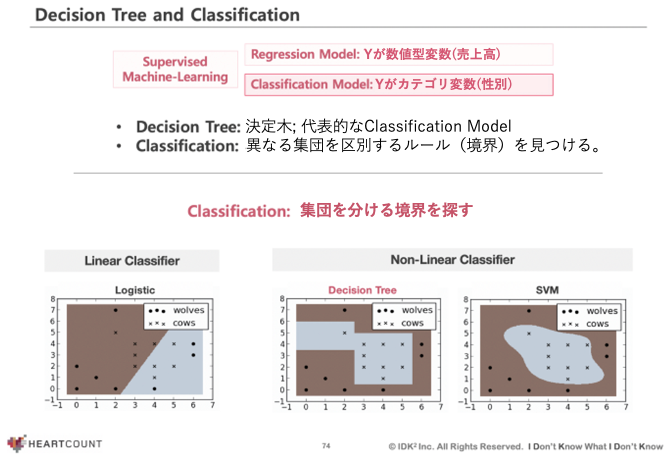
決定木: 仲間が集まるように空間を区画する方法
以下は、新入社員を成果点数を基準に上下20%に分けて、二つの集団を区別するルールを作る例です。例えば、人間性検査で測定した忍耐力スコア(Y軸)と大学時代にサークル活動をした期間(X軸)の2つの変数を使用して2つの集団を区分するとします。
星は星同士、三角形は三角形同士、均質なオブジェクト(class)が純度高く分布する空間を下の図のように区分すると、活用可能な分類規則を作ることができます。
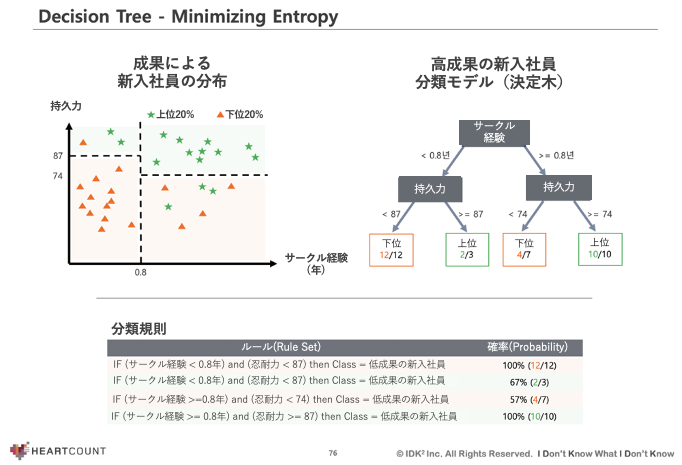
ただし、実際のデータは分類規則を作るために使用しなければならない変数が多いですが、このうち可能な限り少ない変数を使用して最適な分類規則を作る作業を決定木アルゴリズムが代わりに行ってくれます。
また、決定木モデルを通じて説明変数間の相互作用を理解することができるという利点があります。 (例えば、サークル経験が0.8年以上で、同時に忍耐力が74点以上であれば、ほとんどの場合、すぐに仕事ができる...)
Analysis in Heartcount
Dataset
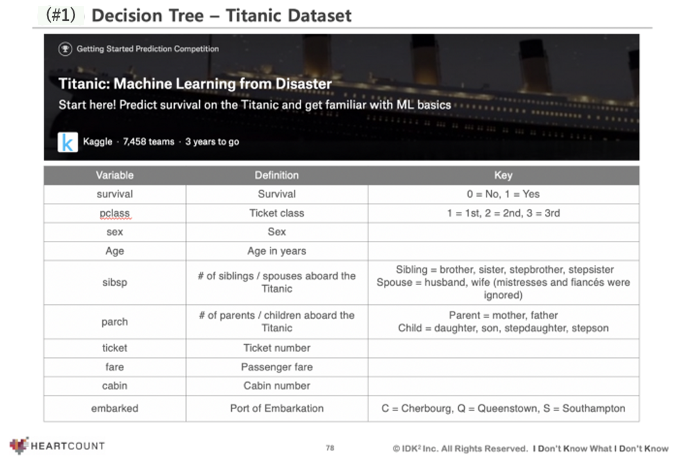
タイタニックデータセットは以下のように構成されています。
主な変数は以下のようなものとなっています。
- survival: 生存/死亡の有無を表示する変数
- pclass: 何等席に乗ったかを表示する変数
- sex, age: 性別, 年齢
Analytics
決定木アルゴリズムが適用されているHEARTCOUNTのセグメント機能を使って、生存者と死亡者を分類してみましょう。
<レシピ>
目標変数を「Survived」に選択した後、[分析]ボタンを押すと、生存者(1)と犠牲者(0)を区別するモデルを生成してくれます。
<分析結果の解釈>
分析結果をツリー形式で見てみましょう。 (緑:生存者、青:犠牲者)
- 女性(female)の場合、生存率(survived=1である割合)が74.2%であり
- 女性であり、同時に1,2等席に搭乗した場合(pclass < 2.5)の生存率が94.7% (キャンペーン作成時にpclassを数字で指定した結果であり、キャンペーン作成時にpclassをカテゴリとして選択すると、他の結果が出ることがあります)
- 一方、男性(male)の場合は6歳以下の場合、生存率が66.6%と高いことが分かりますね。
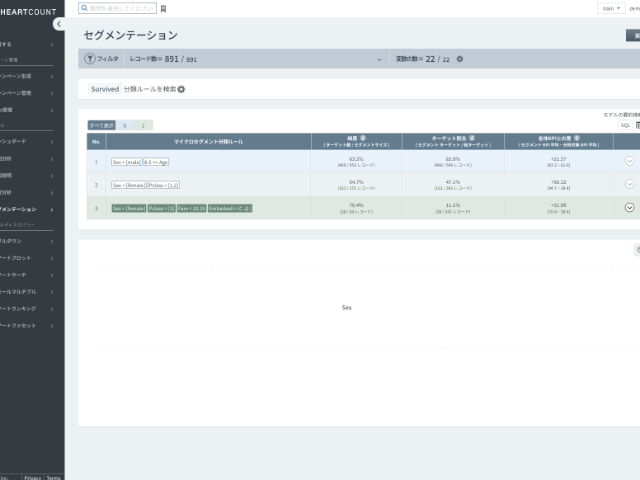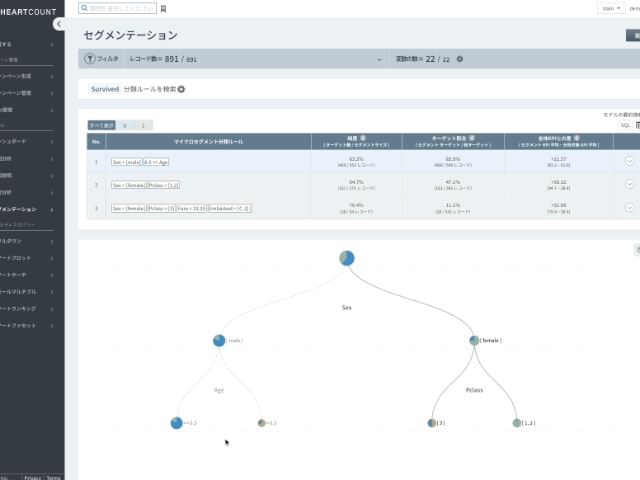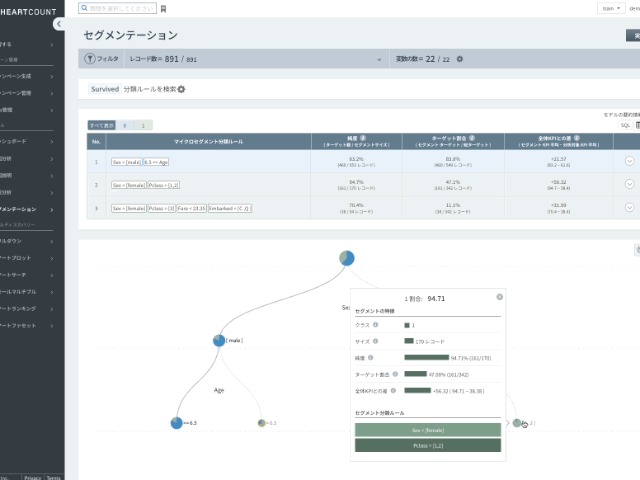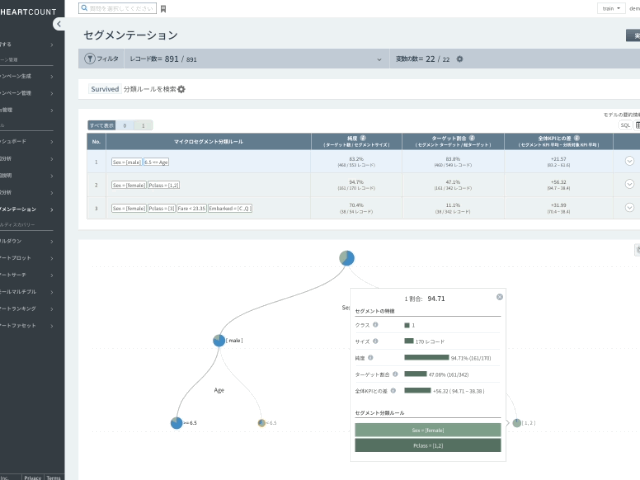
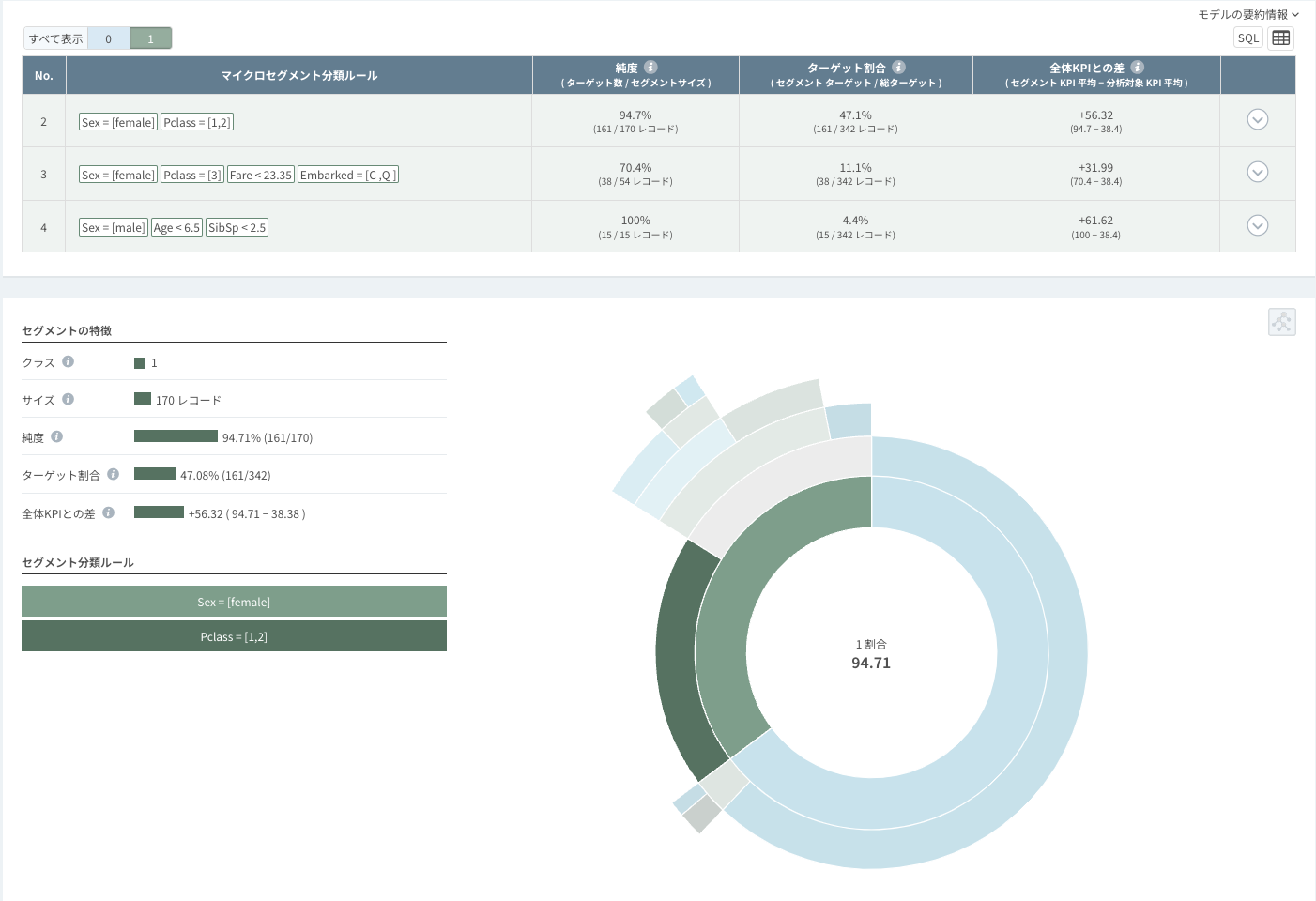
以下は、生存者(1)の分類ルールテーブルと特定のルール(女性で1/2等席搭乗)を別の方法(sunburst)で視覚化した画面です。
- 性別が女性(female)で同時に1,2等席(Pclass < 2.5)に搭乗した場合
- 純度94.71%: 該当条件を満たす170人中94.71%が生存者(1)に分類された(分類精度)
- 目標比率47.08%: 全生存者(1) 342人のうち、そのルールで47.08%を分類できることを意味する(再現率)
このようにしてHEARTCOUNTを活用することで、手元にあるデータから有効なルールやパターンを発見することができるでしょう。