2つの集団を区別する特徴を見つける関連シリーズ
タイタニック号データ実習 1:データから集団を区別する特徴を探す
タイタニック号データ実習2:生存者/死亡者の分類ルールを発見する
データからSignal(有意な差)とNoise(偶然による差)を区別する方法
Intro
実務の現場では、2つの集団を区別する主要な特性をデータから見つけなければならないことがよくあります。 人事部門がハイパフォーマーとローパフォーマーを区別する主要な特性を把握したい場合、運営部門が売上が良い店舗とそうでない店舗の違いがどこに由来するのかを理解したい場合、マーケティング部門が最近のキャンペーンに反応した人々のセグメント特性を(反応しなかった人々と比較して)把握する必要がある場合などです。
今回は、タイタニック号に搭乗した人のうち、生き残った人と犠牲者を区別したいとき、搭乗者のどの属性(変数)が二つの集団を区別するのに役立つ変数であるかを確認する方法について説明します。
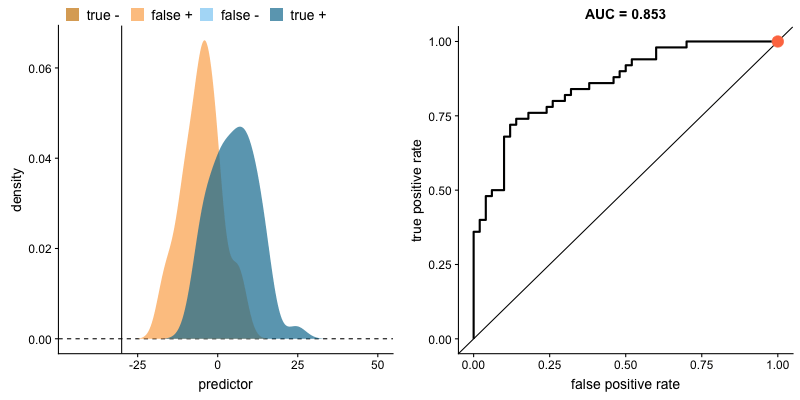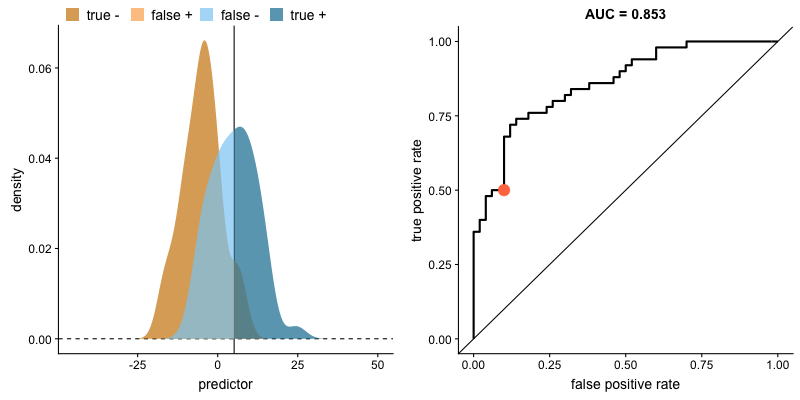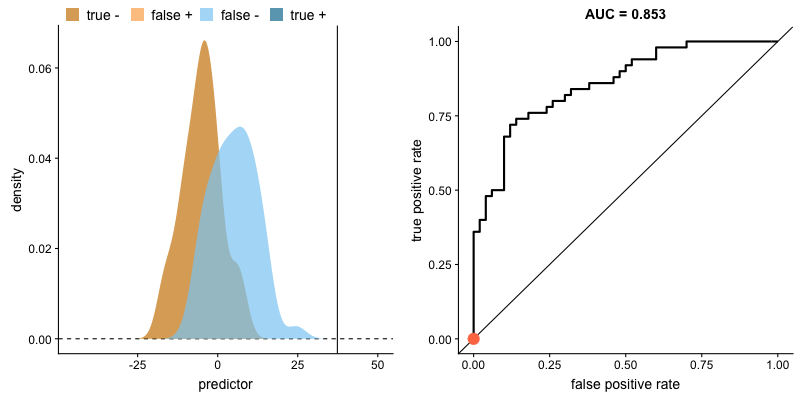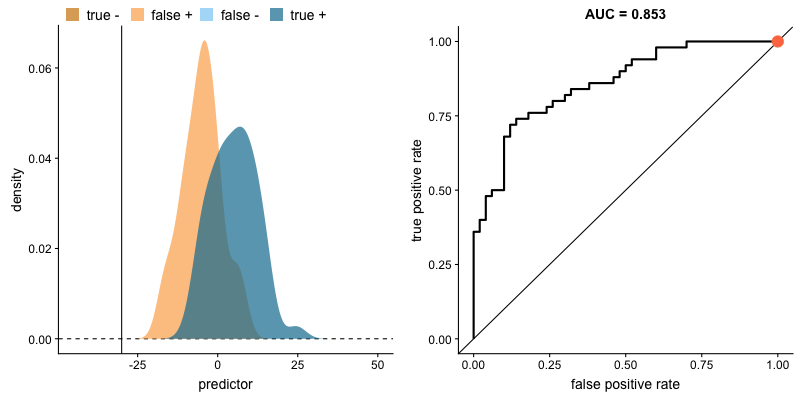
下の図で生存者を青色、犠牲者を黄色で区分した後、年齢による各集団の分布を視覚化したとします。 生存者集団の年齢が全体的に多いこと(青色集団の年齢分布が右側に偏っている)を簡単に確認することができ、年齢変数が2つの集団を区分するのに有用であることが推測できます。
ただし、年齢以外にも性別、搭乗券の種類など、二つの集団を区別する際に使用できる属性(変数)が多いとすると、これらの属性の相対的な重要度を肉眼だけで把握するには限界があります。
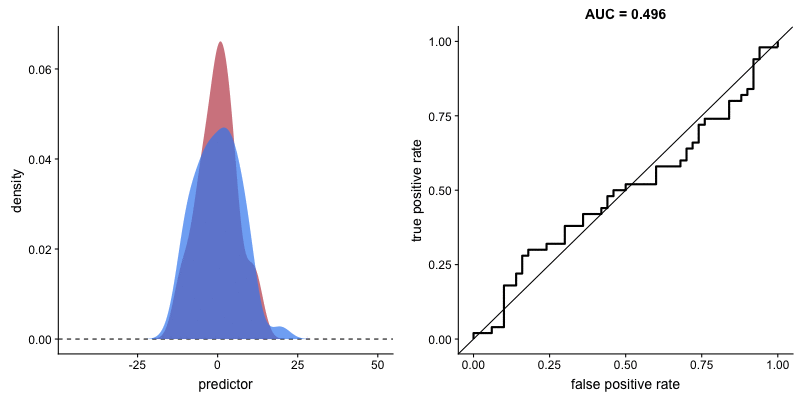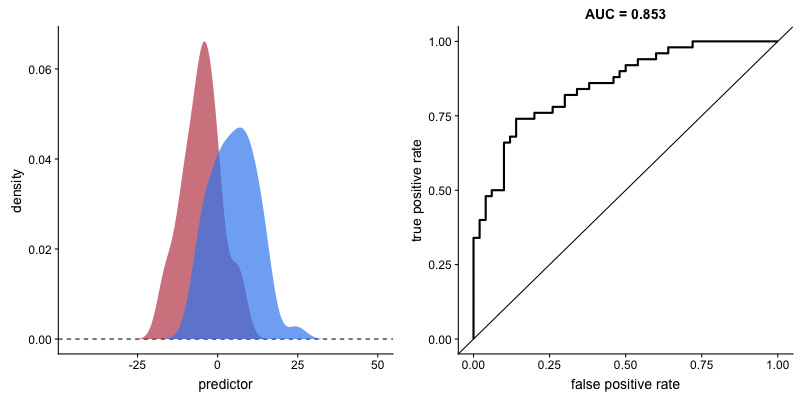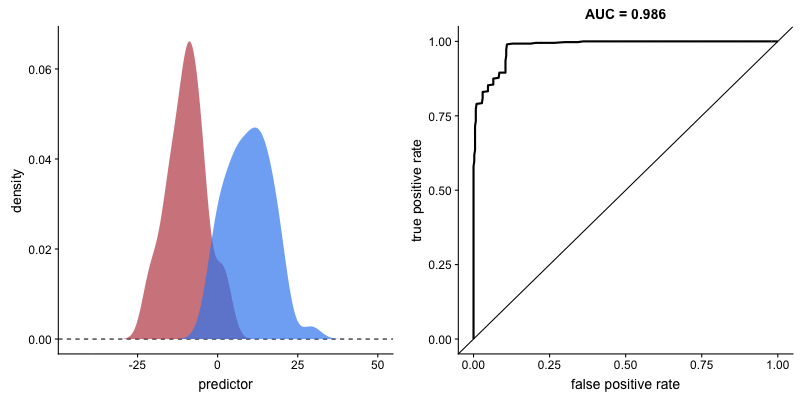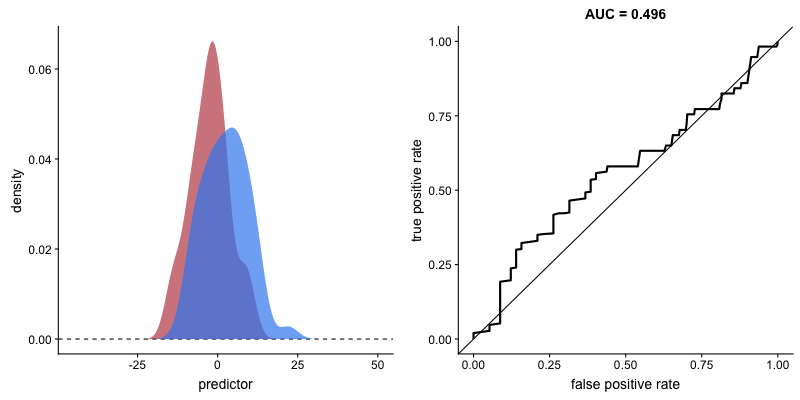
二つの集団の分布が与えられたとき、*AUC(上のボックス記事参照)が大きいほど、その変数が二つの集団をよく区別することができると言えます。下の図のように、二つの集団の分布が重なる領域(交点)がない状態になると、AUCは1になります。 (AUCが1の場合、その変数で二つの集団を完全に区別可能であることを意味します)。
Analysis in HEARTCOUNT
Dataset: タイタニックデータ
まず、タイタニックデータセットは下記のように構成されています。
主な変数を見ると、
- survival: 生存/死亡の有無を表示する変数
- pclass: 何等席に乗ったかを表示する変数
- sex, age: 性別, 年齢
HEARTCOUNTでタイタニック号の生存者、犠牲者の特徴を探します。
性能の良い予測モデルを作成し、当社のサービスに反映させるのでなければ、実務的な観点から、2つの集団の違いを理解することは以下の2つの目的で行われます。
- 個々の変数の相対的な重要性を把握する(例えば、純利益が高い店舗の最も顕著な特徴は、店舗従業員の離職率が低いことである)
- 特定の集団が高い純度で集まっている変数の組み合わせを探す(例えば、離職率が15%以下で配達比重が30%以下の店舗の場合、90%の確率で純利益基準上位20%の店舗集団に属していた)
以下では、HEARTCOUNTの比較分析機能を通じて、二つの集団を分類するのに重要な変数の相対的な重要度を確認する方法を簡単に説明します。
<レシピ>
- グループAとグループBに特性の違いを理解したい二つの集団の条件を設定します。例では、グループAには死亡者(Survived=0)、グループBには生存者(Survived=1)を設定しました。
- ループ設定が完了したら、[比較]ボタンをクリックします。
<分析結果の解釈>
- Survived 100%: 一番上の結果は、生存/死亡の有無を表示する(目標)変数である"survived"が出てきて、(当然)その変数で2つの集団が100%区別されることが確認できます。

- sex, female: 性別が二つの集団を区別する最も主要な変数であり、生存者(赤で表現されたグループB)の68.13%が女性だったのに対し、死亡者(青、グループA)の場合、14.75%だけが女性であり、女性(female)は生存者の主要な特性と言えますね。
- sex, 42.8%: 数字42.8は生存者/死亡者を性別(female, male)で区分するので、分布が重ならない面積の割合が42.8%程度という意味です(紫色は重なる領域を表します)。
- 二つの分布の違いを定量的に計算するために内部的に「Kullback-Leibler divergence」というアルゴリズムを少し変形して使用しており、42.8%はその変数が二つの集団を区別するのに相対的な重要度を測定するための指標程度と理解していただければと思います。