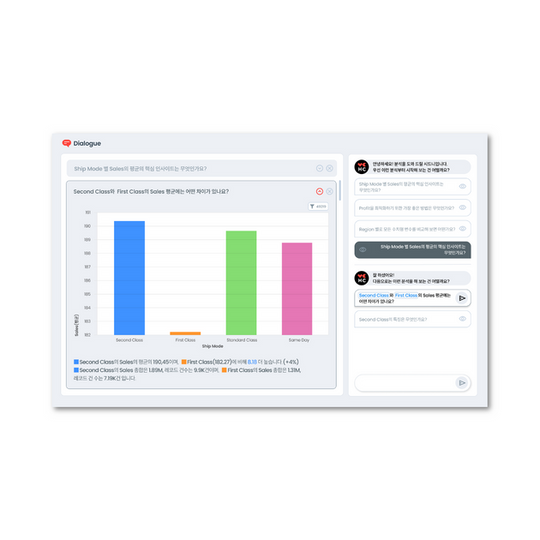
Text-to-SQL の性能を引き上げた技術「RAG」
JohnのText-to-SQLモデルは、LLM(大規模言語モデル)の限界を補うために、さまざまな試みを行ってきました。
特に、構造化データに対するクエリを自然言語で生成するためには、LLMに十分な文脈情報を与えることが非常に重要でした。
以前は、必要な文脈情報(メタデータ)をすべてプロンプトに直接書き込み、LLM(大規模言語モデル)に渡す方法が一般的でした。
しかしこのアプローチでは、トークン数の制限によって大事な情報が欠けたり、不要なデータが混ざることで、かえってSQLクエリの生成精度が下がってしまう課題がありました。
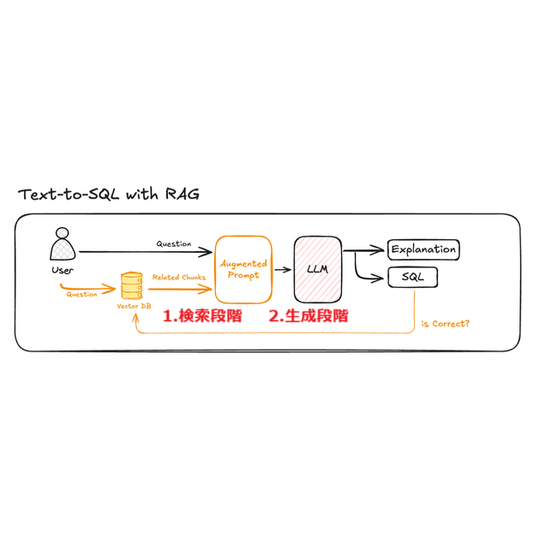
こうした課題を解決するために、最近注目されているのが RAG(Retrieval Augmented Generation) という技術です。
現在のText-to-SQLモデルでは、メタデータをベクターデータベース(Vector DB)に保存し、ユーザーの質問に合った必要な情報だけを検索してプロンプトに組み込む仕組みを採用しています。
これにより、不要なデータを省きつつ、クエリ生成に本当に必要な情報だけを大規模言語モデル(LLM)に効率的に伝えることが可能になりました。
さらに、事前に用意した「質問とSQLクエリのペア(サンプル)」を活用し、ユーザーの質問に近い例を一緒に提示することで、モデルがより正確で実用的なSQLを生成できるよう工夫しています。
 sidney yang
sidney yang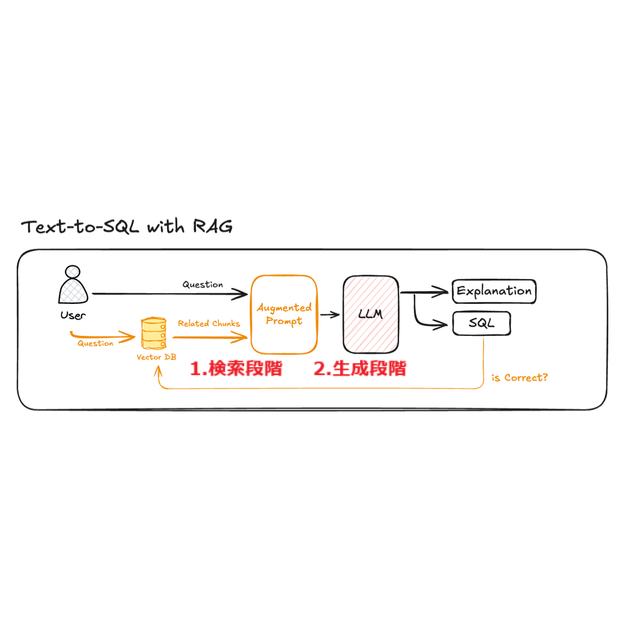 sidney yang
sidney yang
高精度・高性能を実現するためのアプローチ
以前は、LLMの性能と高度なプロンプト設計がText-to-SQLモデルの性能を左右していましたが、現在は状況が大きく変わっています。
Text-to-SQLモデルが実際の環境で安定して動作するためには、単にLLMをうまく活用するだけでは不十分です。
今では、「質問に対してどれだけ正確に情報を見つけ出し、その情報をどのように伝えるか」が、モデル全体の性能に大きく影響するようになりました。
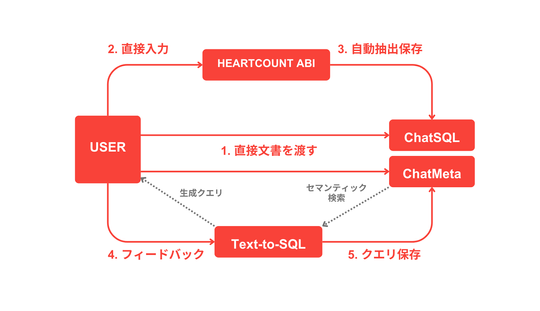
HEARTCOUNT ABIでもRAGを導入することで、自然とこの課題に向き合うことになりました。
”ユーザーの質問にもっと近い、
本当に必要な情報をどうすれば正確に見つけられるか?
この課題を解決するために、私たちが注力したポイントは次の2つです。
- 埋め込みモデル(Embedding Model)
- 検索アルゴリズム(Retrieval Algorithm)
この2つの要素はRAGの中核を成しており、情報検索の精度に直接影響を与えます。
HEARTCOUNT ABIが、この「埋め込みモデル」と「検索アルゴリズム」をどのような基準で選び、どのようなテストを行ってその効果を検証したのか
次に、その具体的なプロセスと結果について詳しくご紹介します。
埋め込みモデル(Embedding Model)の役割
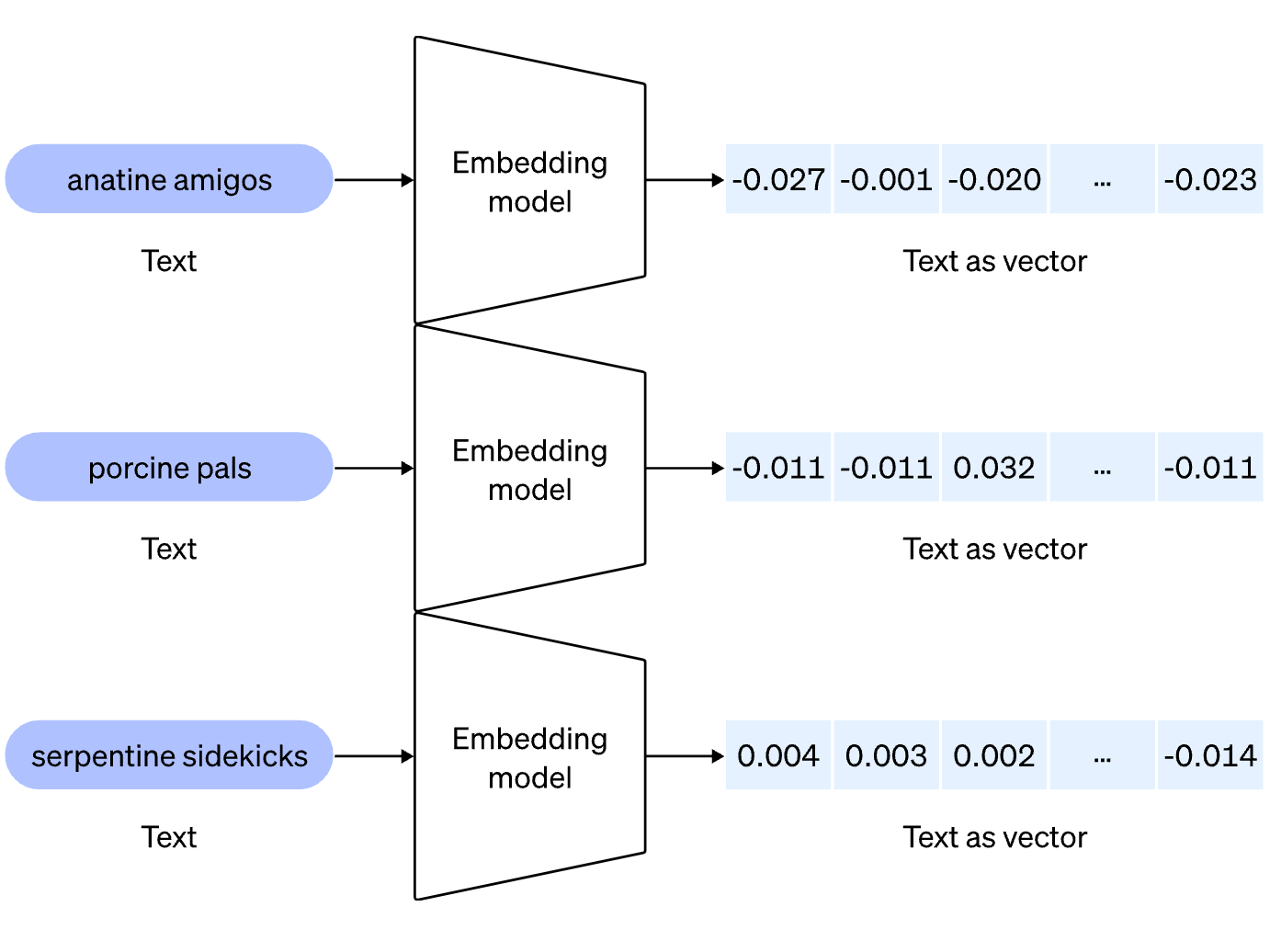
埋め込みモデル(Embedding Model)とは何でしょうか?
埋め込みモデル(Embedding Model)は、テキストデータを数値化されたベクトルに変換し、コンピューターが“意味”を理解できる形にするための基盤技術です。
この仕組みにより、単語や文章が持つ意味が数値で表され、意味が近いテキスト同士はベクトル空間上で自然と近い場所に配置されます。
この技術は、ベクター検索(Vector Search)において「似た質問」や「類似するクエリ」を見つけ出す際に欠かせません。
Text-to-SQLのシステムでは、ユーザーの質問に関連するメタデータや参考クエリを正確に探し出すための重要な役割を担っています。
OpenAIの最新埋め込みモデル「text-embedding-3-large」
HEARTCOUNT ABIのText-to-SQL 2.0では、OpenAIが2024年1月にリリースした最新の埋め込みモデル 「text-embedding-3-large」 を採用しています。
このモデルは、最大3,072次元の高精度なベクトル(埋め込み)を生成できるのが特徴です。
特に、これまで広く使われていた 「text-embedding-ada-002」 と比べて、意味の細かな違いを捉える表現力や、類似度の判断精度が大きく向上しており、より正確な情報検索やクエリ生成を実現しています。
OpenAIの発表によれば、text-embedding-3-large は次のような特徴を持っています。
- 多言語検索のベンチマークである MIRACL では、平均スコアを31.4%から54.9%へと向上。
- 英語ベースの埋め込み性能を測定する MTEB においても、61.0%から64.6%へと改善されています。
これは単なるスコア向上にとどまらず、実質的な意味ベースの類似度検索の品質向上を意味しています。
| 評価指標 | ada v2 | ➡ text-embedding-3-small | ➡ text-embedding-3-large |
|---|---|---|---|
| MIRACL 平均スコア (多言語検索) |
31.4 | 44.0 | 54.9 |
| MTEB 平均スコア (英語検索) |
61.0 | 62.3 | 64.6 |
さらに、このモデルは 256次元のような低次元設定でも、従来のada-002を上回る性能 を発揮することが大きな特徴です。OpenAIによれば、「text-embedding-3」シリーズは、モデル構造の効率性と汎化性能(ジェネラライズ性能)が優れており、
用途に応じて適切な埋め込み次元数(ベクトルサイズ)を柔軟に選択できる設計 になっています。
これにより、検索の精度とコストバランスを考慮した運用が可能になります。
| モデル名 | ada v2 | ➡ text-embedding-3-small | ➡ text-embedding-3-large |
|---|---|---|---|
| 埋め込みサイズ (次元数) |
1536 | 512 / 1536 | 256 / 1024 / 3072 |
| MTEB 平均スコア (英語検索性能) |
61.0 | 61.6 / 62.3 | 62.0 / 64.1 / 64.6 |
Text-to-SQL 2.0に導入した「text-embedding-3-large」
高精度な検索を支える埋め込みモデル
「text-embedding-3-large」は、最大3,072次元の埋め込み(ベクトル)生成に対応しています。しかし、HEARTCOUNT ABIのText-to-SQL 2.0では、性能とコスト効率の最適なバランス を考慮し、あえて 768次元 に設定しています。
この低次元設定にもかかわらず、従来の「text-embedding-ada-002」よりも高い表現力と類似度判断の精度 を維持しており、
安定した検索性能と実用性を両立しています。
実際に「text-embedding-3-large(768次元)」が類似度検索の精度向上に貢献しているかを検証するため、Spider Dataset の一部を使ったテストを行いました。事前に英語・韓国語・日本語で作成した質問とクエリのペアをベクターデータベースに登録し、各言語で 60件の質問 に対して検索を実施。その正確性(検索精度)を測定しました。
テスト結果は次の通りです。
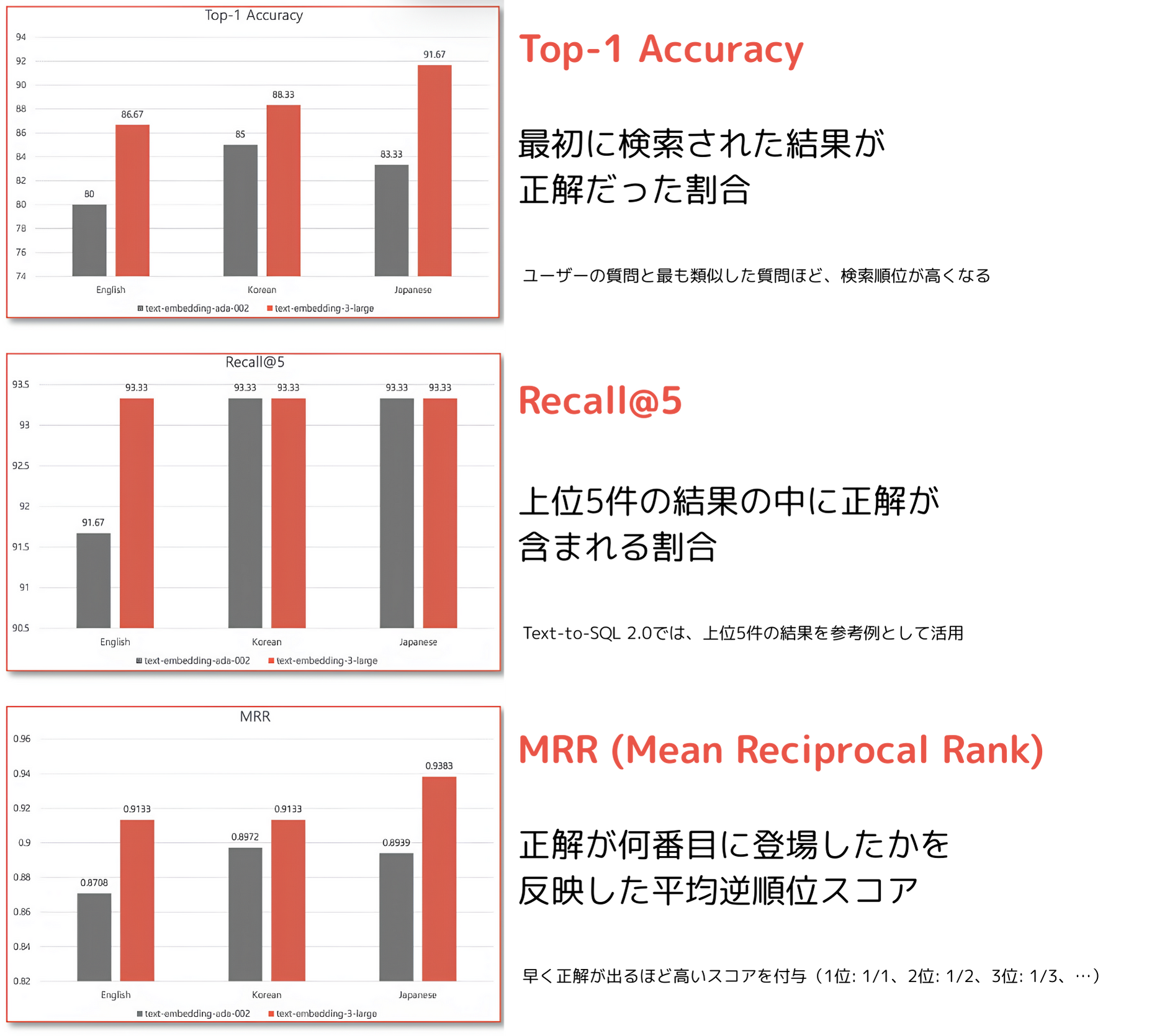
「3-large」モデルは次元数を768に抑えていますが、1,536次元の「ada-002」モデルよりも、すべての言語で高い性能を示しました。
このように、多言語環境においても高い検索精度と順位ベースの正答率(MRR)を達成できたことは、埋め込みモデルの品質がシステム全体の性能に直結することを示しています。類似した質問をどれだけ正確に見つけられるかによって、LLMに渡すサンプルの質が高まり、それがより精度の高いクエリ生成につながります。
韓国語-英語・韓国語-日本語の多言語質問における Text-to-SQL(TTS)性能評価
今回は、実際の運用環境を想定し、質問とデータベース内に保存されている言語が異なる場合でも検索性能が維持できるか を検証しました。
具体的には、
- 韓国語で質問
- 英語または日本語の質問のみが登録されている Milvus(ベクターデータベース)で検索
を行い、類似質問を正確に探し出せるかをテストしました。
| 入力言語 | 保存言語 | Top-1 正解率 | Recall@5 | MRR(平均逆順位) | Top-5 内で未検出の件数 |
|---|---|---|---|---|---|
| 韓国語 | 英語 | 83.33% | 91.67% | 0.8839 | 5 |
| 韓国語 | 日本語 | 90.00% | 93.33% | 0.9272 | 4 |
異なる言語で保存されていても、高い精度で類似するサンプルを見つけられることが確認できました。
ここで注目すべき点は、すべての言語に質問を翻訳して別々に保存しなくても、
1つの言語で作成された質問-クエリの例だけで、他言語からの質問にも正しく対応できる ということです。
これは、埋め込みモデルが持つ 多言語での汎化(一般化)能力 によるもので、
少ない労力で多言語環境をカバーでき、ユーザーはそれぞれ自然に自分の言語で質問しながら、正確で一貫性のあるSQL生成と回答を得ることができます。

検索アルゴリズム(Retrieval Algorithm)が果たす重要な役割
クエリ生成性能に大きな影響を与える検索アルゴリズム
ベクトルに変換されたテキスト同士をどう比較するかは、RAGベースのText-to-SQLシステムの性能に決定的な影響を与えます。
同じ埋め込みモデルを使用していても、どの類似度計算アルゴリズムを採用するかによって、検索品質は大きく変わります。
RAGベースのText-to-SQLシステムでは、ユーザーの質問に対して意味的に最も近い情報(例:サンプルクエリ、テーブル説明など)を
正確に見つけ出すことが成功のカギとなります。
そのためには、埋め込みベクトル同士の類似度をどの基準で比較するか が非常に重要です。
自然言語ベースのシステムでは、同じ意図の質問でも表現が多様 なため、
文の長さや構造に左右されず、「意味」そのものを正しく捉える比較方法が求められます。
こうした背景から、コサイン類似度(Cosine Similarity) は、
文同士の意味的な近さを反映する代表的な手法として、自然言語検索システムで広く利用されています。
コサイン類似度(Cosine Similarity)と他の検索アルゴリズムの比較
| アルゴリズム | 比較方法 | 長所 | 短所 |
|---|---|---|---|
| コサイン類似度 | ベクトルの方向(角度) | 意味に基づく類似度比較に優れている | 絶対的な距離(大きさ)は考慮しない |
| ユークリッド距離 | ベクトル間の直線距離 | 直感的にわかりやすい距離計算 | 文章の長さや表現方法に影響を受けやすい |
| 内積(ドットプロダクト) | 方向 + 大きさ | 計算が速く、一部の推薦システムで有効 | ベクトルの大きさに左右されやすく、正規化が必要 |
コサイン類似度は、2つのベクトル間の「方向性」に基づいて類似度を測定します。つまり、2つのベクトルがどれだけ似た方向を指しているか を比較する方法です。ここで重要なのは、ベクトルの「大きさ(長さ)」ではなく、
そのベクトルがどの方向を向いているか という点です。
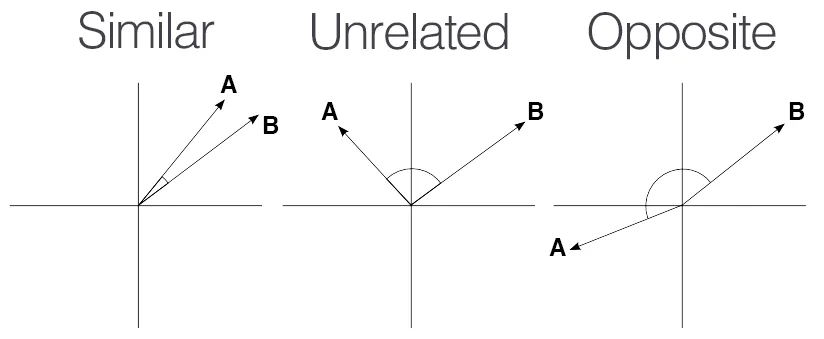
なぜ「ベクトルの方向」が重要なのか?
自然言語での質問は、表現の仕方によって文の構造が大きく異なる場合があります。
たとえば「ソウルの天気は?」と「今日のソウルの天気はどうですか?」は、
使われている単語数も文の構造も異なりますが、意味的にはほぼ同じ内容 です。
このような場合、ユークリッド距離のようにベクトルの絶対的位置や長さ(大きさ)を基準に距離を計算すると、
表現の違いによってベクトル間の距離が離れてしまい、意味的には近いにもかかわらず「似ていない」と誤って判断される ことがあります。
一方、コサイン類似度(Cosine Similarity) は、ベクトルを正規化して「長さ」ではなく「方向」だけを比較するため、
文の長さや単語数の違いに左右されず、意味に基づいて正確に類似度を判断できます。
つまり、ベクトルの長さではなく方向を比較するコサイン類似度は、
表現が異なっても意味が同じ自然言語の特徴をもっともよく反映できるアルゴリズム です。
Text-to-SQLシステムにおいても、コサイン類似度は
正確な情報検索と高品質なクエリ生成を支える重要な要素 であり、
モデル全体の性能を支える大きな軸となっています。
私たちのText-to-SQLは進化しました!
以前のText-to-SQLモデルも、シンプルな質問に対しては十分に良いパフォーマンスを発揮していました。
しかし、実際の業務環境で頻出する 複雑な条件指定や複数テーブルの結合が必要な質問 については、やはり課題が残っていたのが正直なところです。
その大きな理由は、LLM(大規模言語モデル)が参照できる情報が限定的だった ことにあります。
すべてのメタデータをプロンプトに詰め込む方式では、モデルが質問の意図を十分に把握し、精緻なクエリを生成するのは難しかったのです。
しかし、現在のモデルでは RAG(Retrieval Augmented Generation)を導入 することで、
質問に合った必要な情報だけを選択的にモデルに提供できる仕組み を実現。
これにより、複雑な質問でも大幅に高い精度でクエリを生成できるようになりました。
さらに、最適な 埋め込みモデル(Embedding Model)と検索アルゴリズム を採用するだけでなく、
より高い性能を目指して、モデルのチューニングや最適化も多方面から取り組んできました。
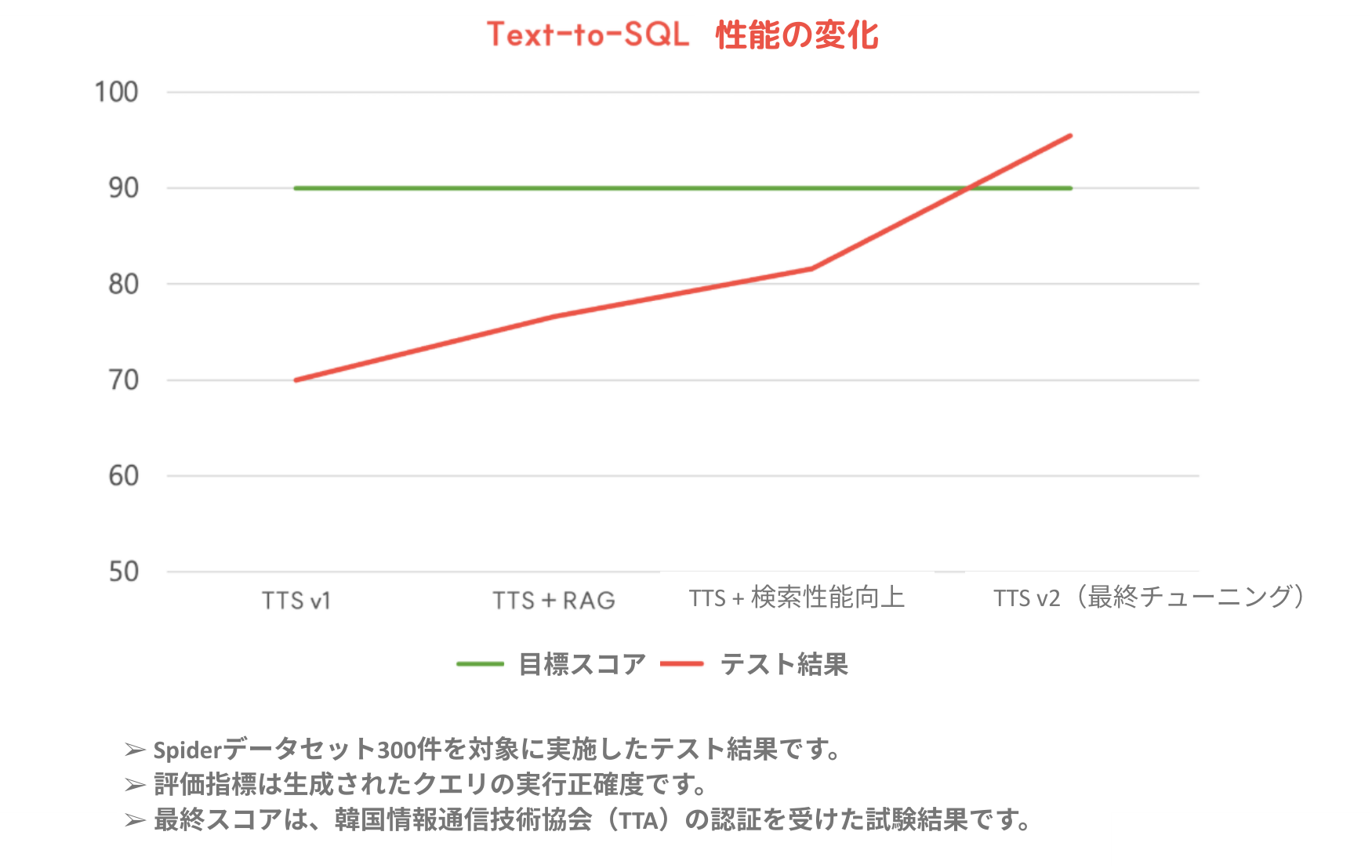
数値で性能向上が確認できただけでなく、より直感的に理解していただくために、同じデータと同じ質問に対する結果の違い を例としてご紹介します。
Text-to-SQL 性能比較
ハルシネーション(Hallucination)の問題
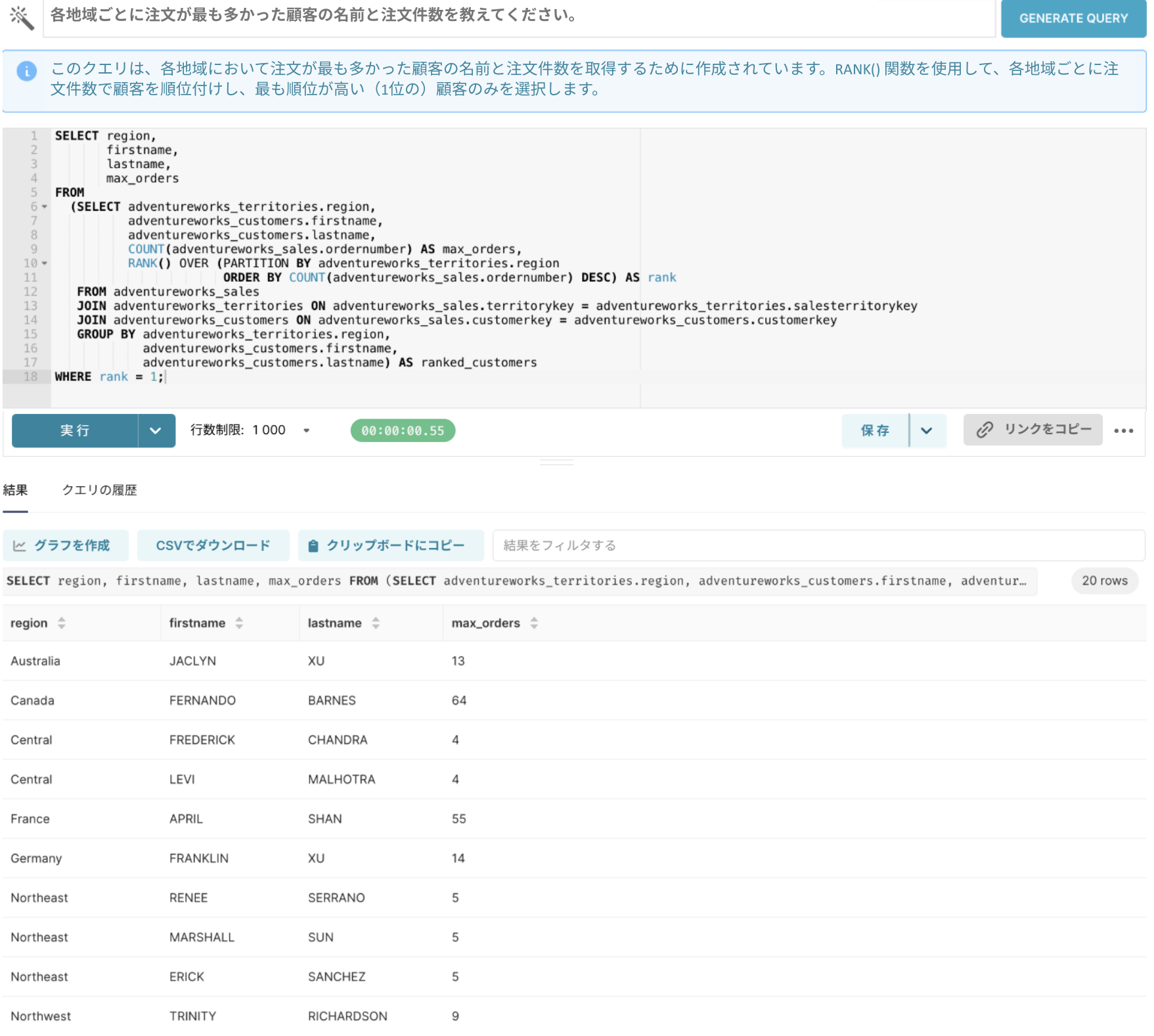
質問1:「各地域ごとに、注文が最も多かった顧客の名前と注文件数を教えてください。」
以前のモデル(LLM単体)では、実際のデータ構造を十分に理解できていなかったため、誤ったテーブル結合や不適切な条件が含まれるケースが多くありました。生成されたSQLの説明だけを見るともっともらしく見えるものの、実際にクエリを実行してみると、期待した結果が得られない ことがよくありました。
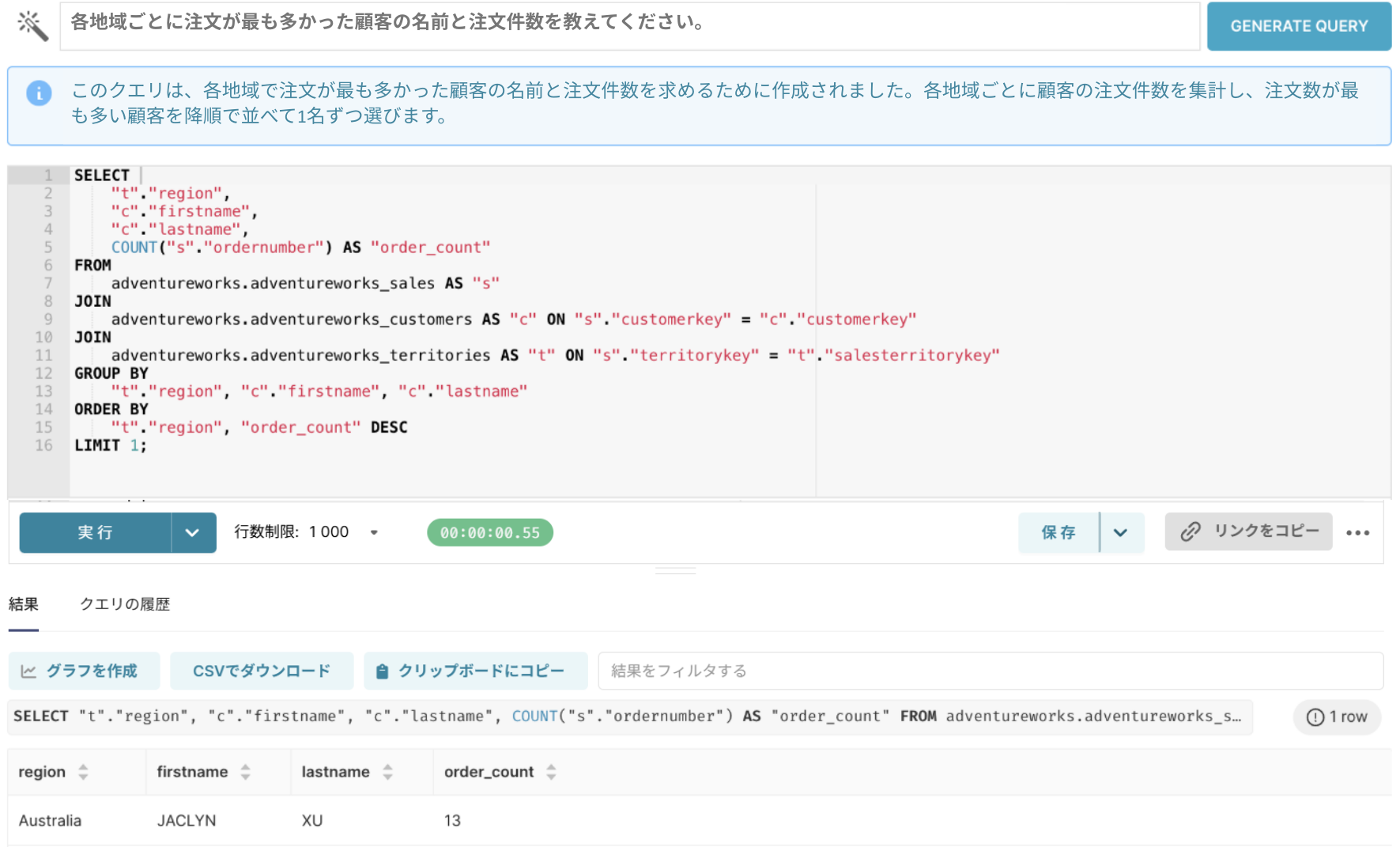
現在のモデル(RAG適用)では、3つのテーブル間の関係を正確に把握し、
必要な情報だけを適切に結合することで 正確なクエリを生成できています。
さらに、注文数が最も多い顧客が複数名いる場合でも、すべて確認できるようにクエリが作成されています。
データ表現の不一致問題
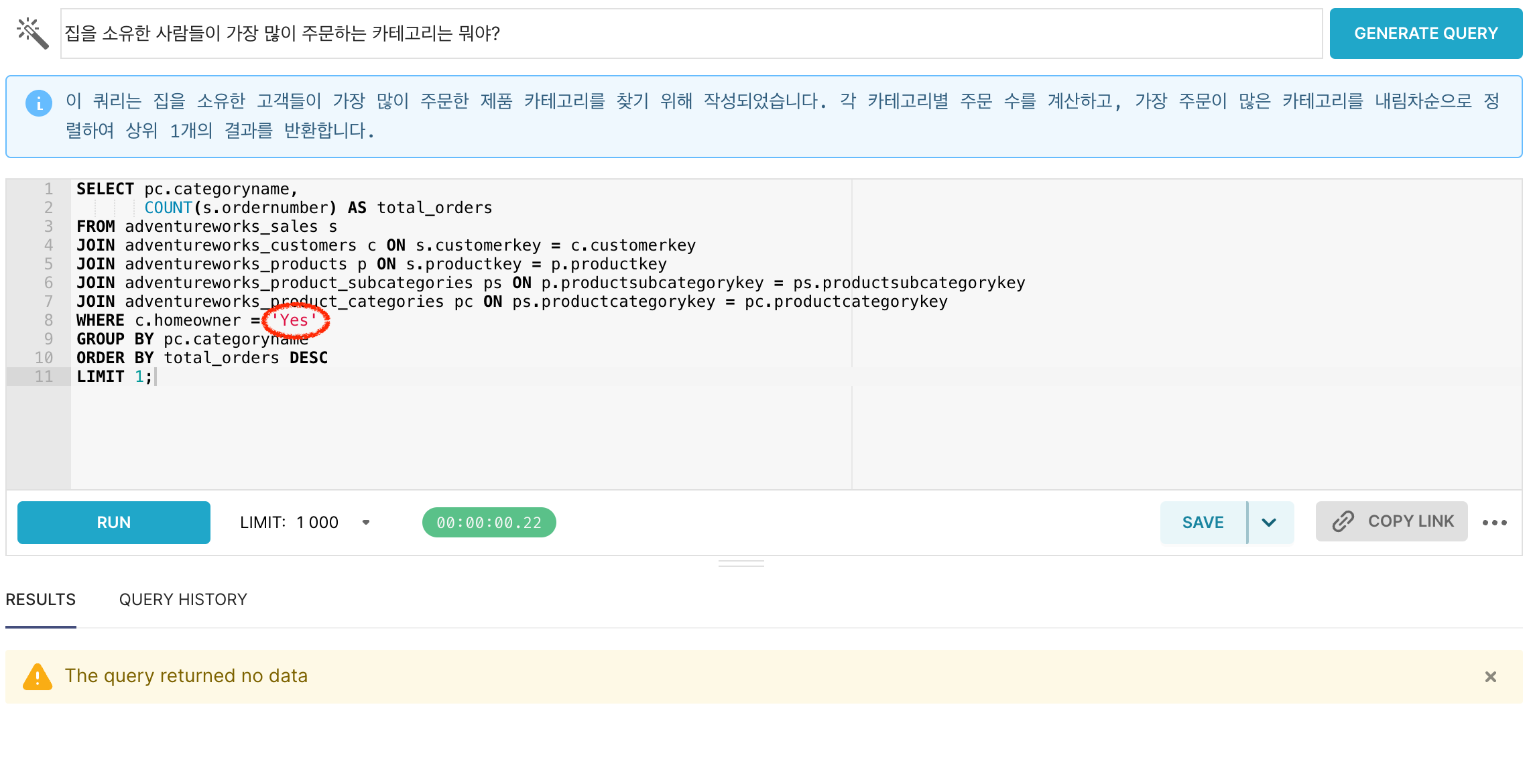
質問2:「家を所有している人たちが最も多く注文しているカテゴリは何ですか?」
生成されたクエリを実行してみたところ、結果データが返ってきませんでした。
クエリを確認したところ、「家を所有している顧客」を絞り込もうとはしていましたが、データにおける表現方法(値の記載方法)に関する情報が不足していたため、誤った条件でフィルタリングされていた ことがわかりました。
このようなケースでは、もし機密情報でなければ、こうした値の表現ルール(例:「Y」「Yes」「True」など)をあらかじめメタデータとして明示し、LLMが参照できるようにすることが効果的 です。
値が特定の範囲や条件で決まっている場合、その情報をメタデータに明示しておくことで、LLMがより正確なクエリを生成するのに役立ちます。
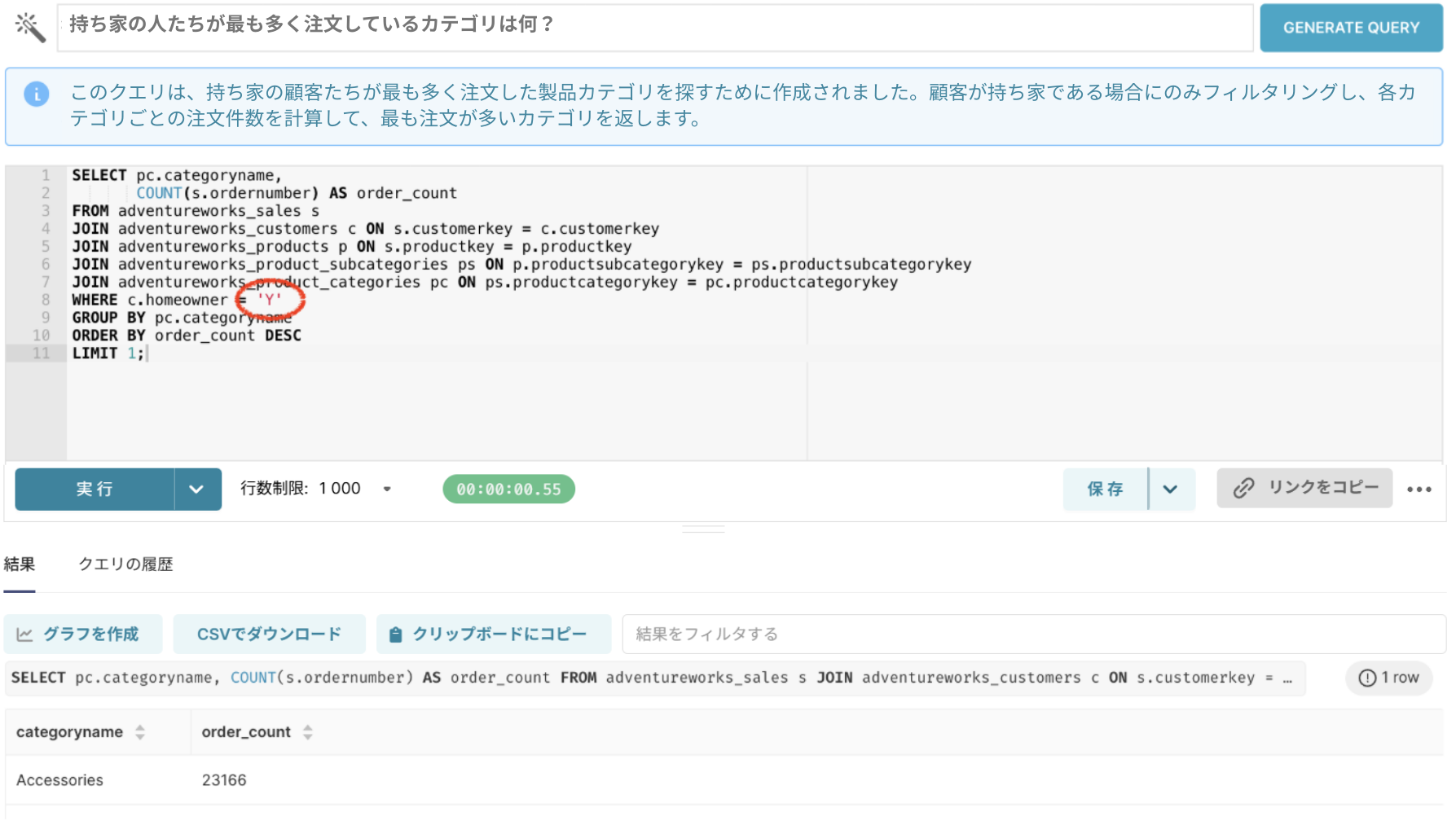
今回のケースでは、「持ち家かどうか」の判定基準が「Y」または「N」 であることをメタデータに含めることで、LLMがこの情報を参照しながら適切なフィルタ条件を設定できるようにしました。
変更されたクエリを一度確認してみましょうか?
持ち家かどうかを確認し、該当する顧客が注文した商品のカテゴリをグループ化して、正しく結果を表示しています。
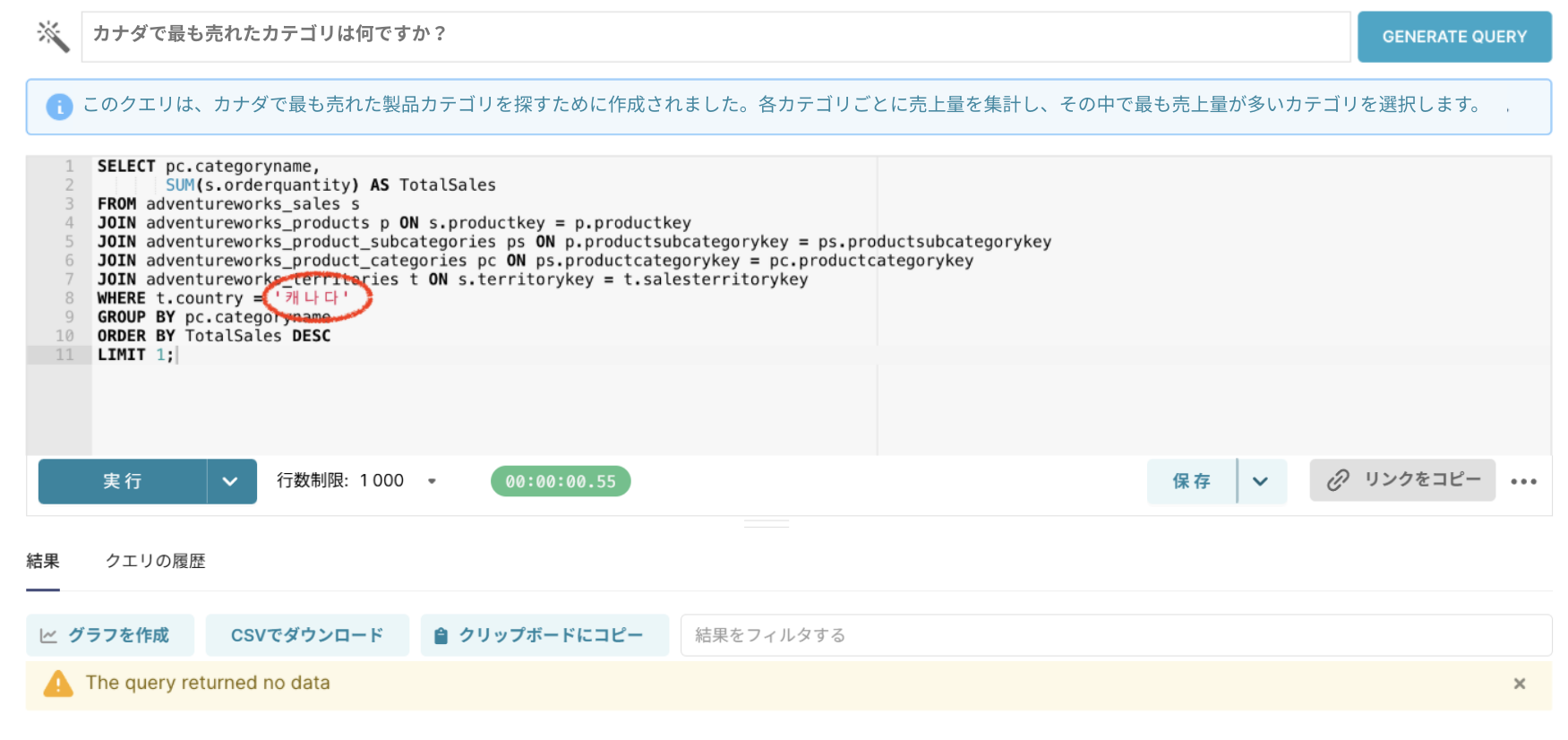
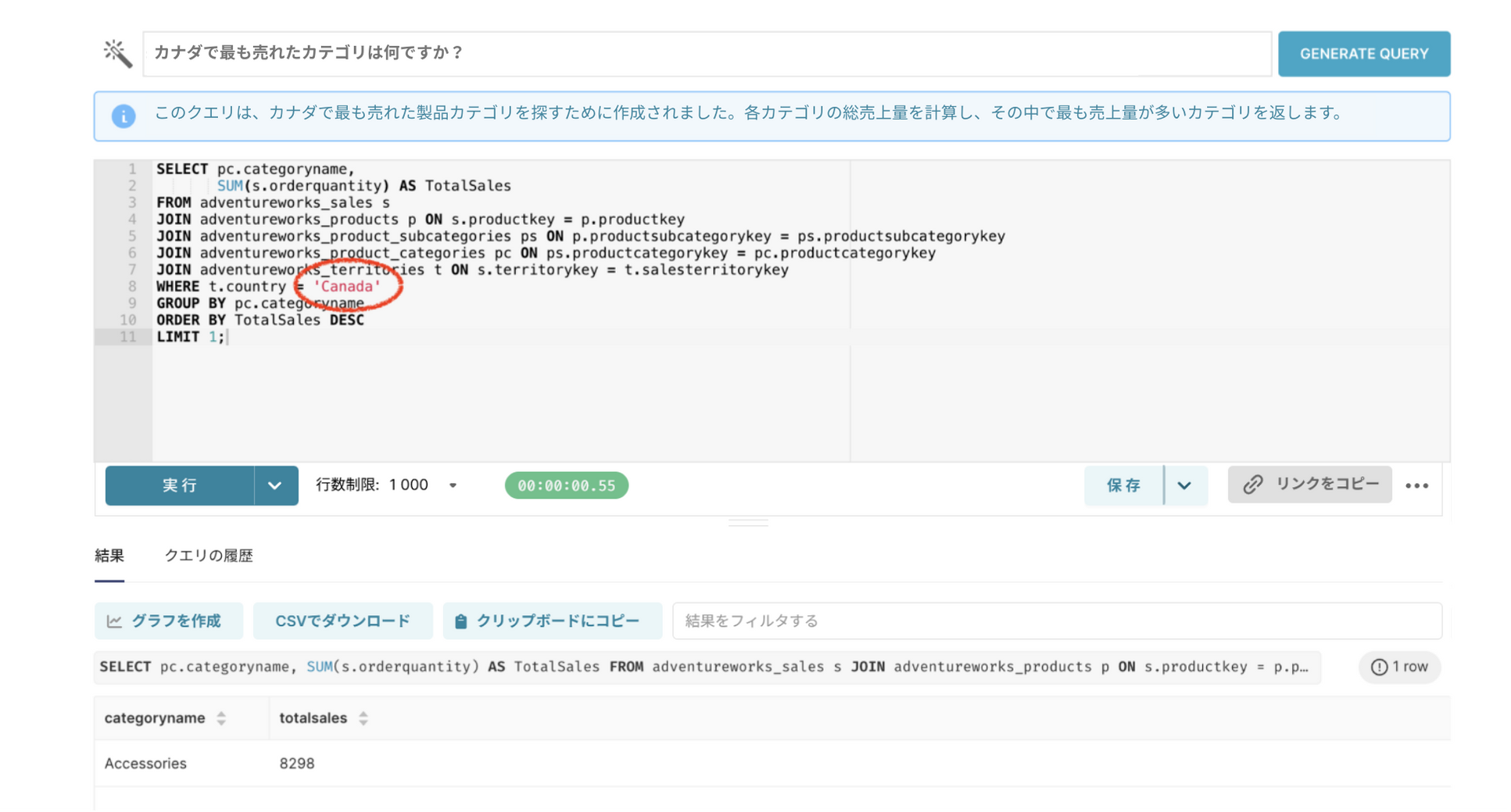
質問3:「カナダで最も売れたカテゴリは何ですか?」
今回も生成されたクエリを実行してみたところ、結果データがありませんでした。同じ方法でメタデータに説明を追加することで解決できそうですね!
メタデータにカラムの説明を追加した例です。データ内でどのように国名が表現されているかがわかるように、説明にその情報を加えました。
| public | adventureworks_territories | continent | 大陸 | 大陸名は英語で記載 |
|---|---|---|---|---|
| public | adventureworks_territories | country | 国家 | 国名は英語で記載 |
| public | adventureworks_territories | region | 地域 | 地域名は英語で記載 |
以前はユーザーの質問に使われた「キャナダ」という国名をそのまま使用していましたが、現在は英語で記載されている「Canada」という国名を正しく使用していることが確認できます。
質問の解釈ミス
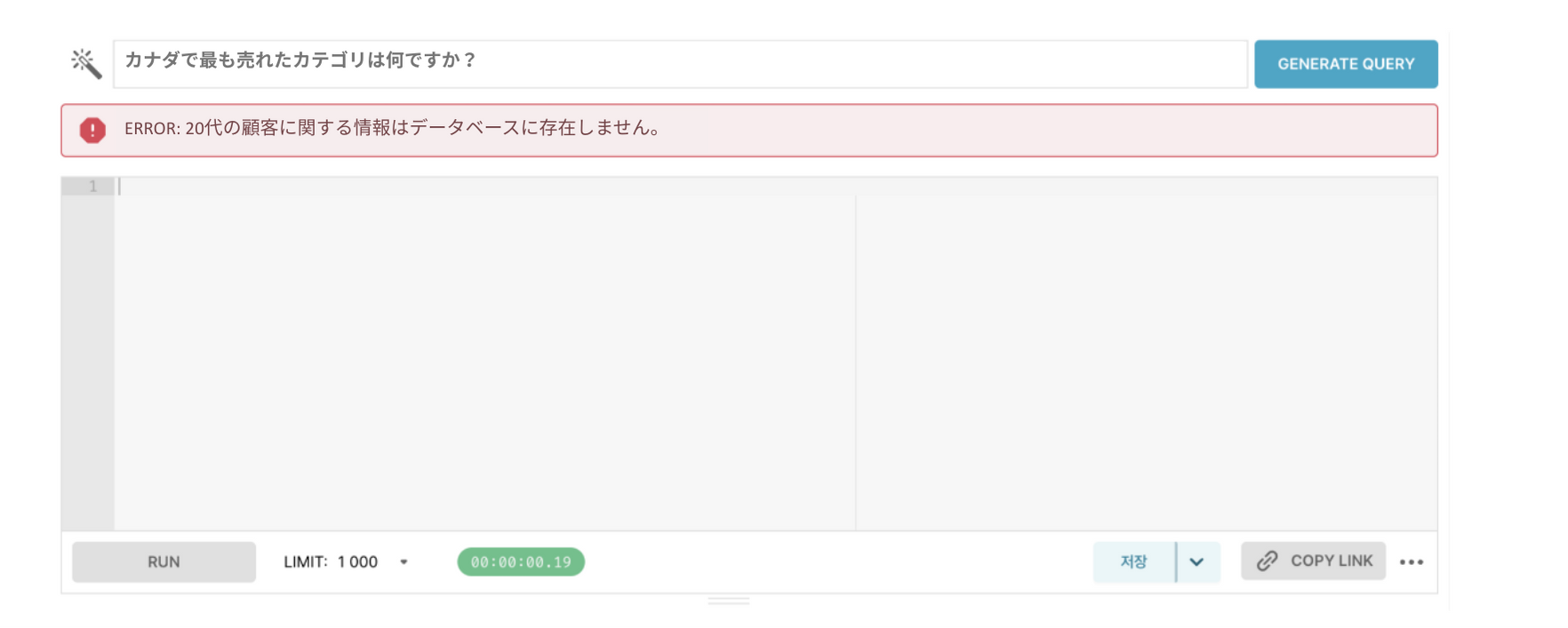
質問4:「20代の顧客が最も多く注文した商品の名前は何ですか?」
以前のモデルでは、「20代」というカテゴリ条件を数値として正確に解釈できないケースが多くありました。この質問では、年齢を基準に 20〜29歳の範囲条件を正しく計算するクエリを作成できるかが重要なポイント となります。
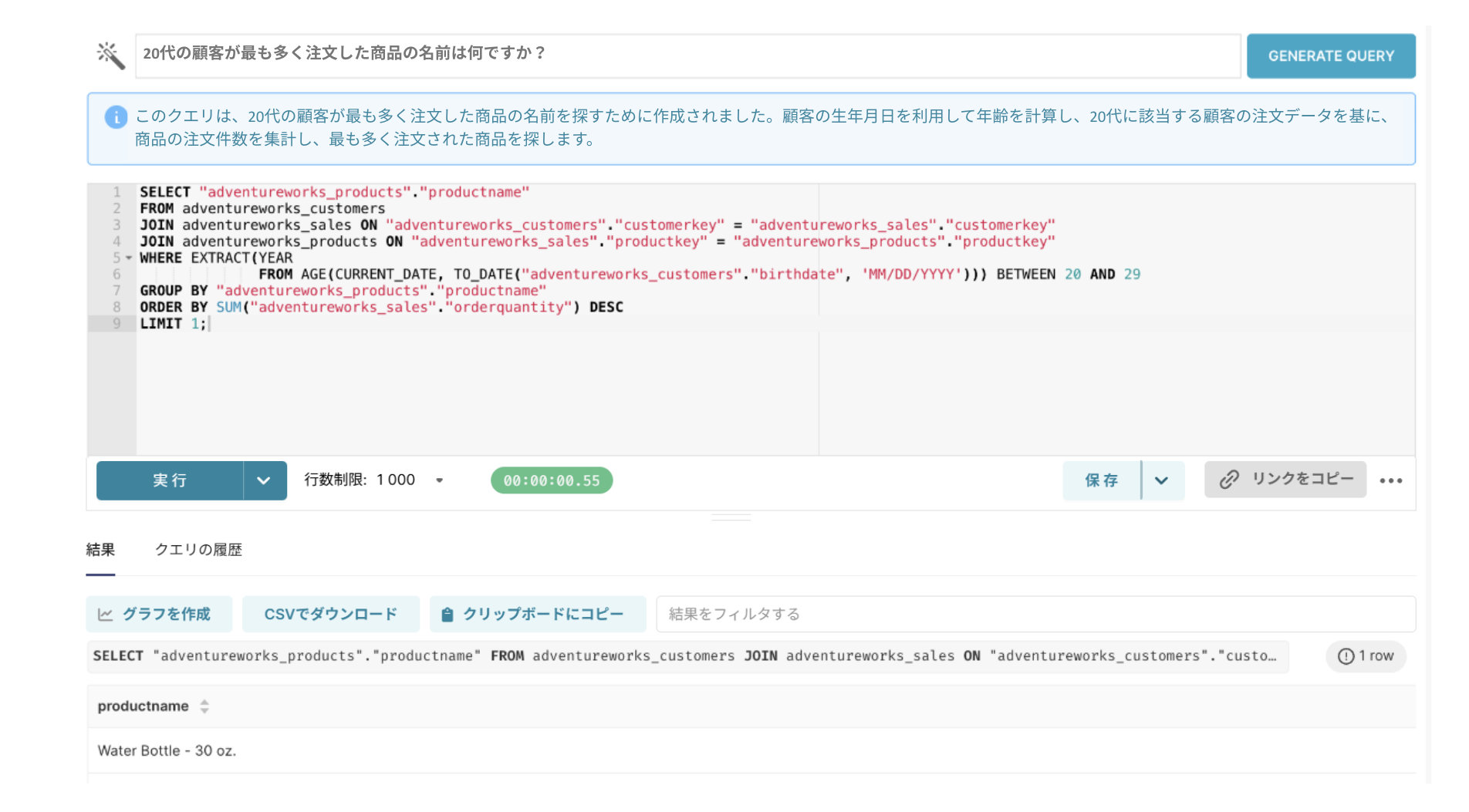
もし年齢層を計算するクエリがあらかじめ保存されていれば、LLMは類似する質問を検索してそのクエリを参照し、その中で使われている計算方法を基に新しいクエリを生成することができます。
結果を確認すると、LLMが類似する質問のサンプルクエリを参照し、
「20代の顧客」という条件を適切に反映していることがわかります。
このように、よく使われるテーブルやビジネスロジックの理解を助けるために、
質問とクエリのペア(質問-クエリサンプル)を事前に保存しておくことで、
LLMが文脈をより正しく把握し、より正確かつ高品質なクエリを生成できるようになります。
まとめ
HEARTCOUNT ABIのText-to-SQL 2.0は、単なるLLMベースのクエリ生成モデルにとどまらず、より正確で実用的なSQL生成のための構造へと進化しました。
複雑な条件や多テーブル結合、多様な表現パターンに対応するため、RAGアーキテクチャ、高性能な埋め込みモデル、検索アルゴリズム を組み合わせ、
さらに 質問の前処理、クエリサンプル設計、メタデータ活用 を含む全体のパイプラインを精密に設計。ユーザーの質問に対して必要な情報だけを的確に選び、
モデルが参照できる高品質なサンプルクエリを提供できるよう最適化しています。
また、質問とクエリの例がひとつの言語で保存されていても、
多言語の質問に対して意味ベースで正しく検索し、正確なSQL生成につなげられる という、効率的かつスケーラブルな構造を実現しました。
HEARTCOUNT ABIは、実際の利用現場に最適化されたText-to-SQLシステムとして、今後も 性能と実用性の両面で進化を続けていきます。