
People Analyticsが実用的なものになるためには
人事データ分析、またはPeople Analyticsの実用性は、管理可能な要素と不可能な要素を区分し、管理可能な要素に焦点を当てて変化を促すことにあります。
従業員のパフォーマンスは複雑であり、その全体像を完全に把握するのは難しいです。しかし、これを理由に手を付けない姿勢や、少ない情報から全体を推測する還元主義的なアプローチは、組織にプラスの変化をもたらしません。実際に、これらの対照的な態度は同一人物から状況に応じて見られることがあります。
この記事では、筆者がPeople Analyticsの分野での多くのプロジェクトを経験し、特に「従業員のパフォーマンス分析」について学んだこと、効果的なアプローチについて語ります。これは筆者の実体験に基づくもので、People Analyticsにおける実践的な洞察を提供します。
成果の違いをもたらす要因(Performance Driver)
成果を定義することは非常に難しいです。パフォーマンスを正確に測定することは全く不可能です。
しかし、人によって成果に差があることには容易に同意することができます。あいつがあいつより2倍仕事が上手だと言うのは難しいですが、あいつとあいつが働く姿を長く観察した人なら、比較的あいつがあいつより仕事が上手だと主張することができるでしょう。
相対的にあいつがあいつより仕事が上手だという(線引きする)判断自体の不当性と不条理さを論じるなら、成果分析は全く始めることができません。 真価(true value)を測定することもできず、推定した値(成果等級)間の相対的な差を認めることもできない変数に対する分析が無意味だからです。
しかし、主観的で定性的な性能評価方式が個人間の性能差を観察、測定できる現実的な唯一のツールであることを認めるなら、「従業員性能分析」は性能等級(スコア)の差をもたらす要因を探すことだと言えると思います。
社員のパフォーマンス、データでどれだけ予測できるのか?
このブログは、従業員のパフォーマンスを分析する2つの異なる方法について考察しています。まず、従業員のパフォーマンス差の30%がデータを通じて定量的に説明できるという事例(A)を挙げています。これは、伝統的な人事データに基づいて分析し、結果として得られた成果の差を意味します。しかし、このアプローチは実証的な証明には十分でないと指摘されています。
次に、従業員の行動データだけで成果を90%の精度で予測できるという事例(B)が示されています。これは、データとアルゴリズムを使用して行動から成果を予測するアプローチですが、筆者はこの方法に少し不安を感じています。
実際の事例として、筆者は2年前にある顧客企業で実施したプロジェクトを挙げています。このプロジェクトでは、意図的に単純なアルゴリズムを使用し、学歴や人間性などの伝統的な人事データに基づいて成果の差を分析しました。この方法では、成果の差は30%程度とされましたが、これが大きいのか小さいのかは、比較対象が不十分であるため判断が難しいとされています。
このブログでは、筆者がB顧客と共に実施した高パフォーマンス予測モデルの策定に関するプロジェクトについて説明しています。このプロジェクトの特徴は、社員の会社生活を通じて残された様々なデジタル行動データを使って、予測精度が非常に高い(90%レベル)モデルを作成したことです。
一般的に、行動モデルを作る際には、正確または有用なモデルは作れるが、両方を兼ね備えたモデルを作るのは困難とされています。しかし、このプロジェクトでは、単に正確なだけでなく、実際に現場で使える有用なモデルを作成するために、「解釈可能な機械学習」という分析技法を採用し、モデルの動作方式を透明にしました。
このプロジェクトでは、従業員の行動データを使用して、高成果者と低成果者を高い精度で予測するブラックボックスモデルを作成しました。さらに、このブラックボックスモデルの内部動作を理解しやすい形で示し、高成果者と低成果者の特徴的な行動を把握することができました。
筆者は、この予測モデルの実用性に関してはいくつかの限界があることを明らかにし、その内容について詳しく説明しています。このブログの最後には、「解釈可能な機械学習」についてさらに詳しく知りたい読者のために、関連する追加情報へのリンクも提供されています。
従業員パフォーマンスモデル:行動データでパフォーマンスを予測(説明)するモデルが実効性を持つためには
このブログは、個人の成果(Performance)を能力(Talent; Ability)と努力(Effort; Motivation)の2つの要素に基づくものとして定義しています。この普遍的な成果モデルでは、個人の能力(talent)と努力(effort, motivation)が組み合わさり、具体的な行動へとつながるとされています。会社では、この個々の行動に価値を与え、それを成果として評価します。
簡単に言えば、このモデルは個人の成果が、彼らの能力と努力の両方に依存しているという考え方に基づいています。能力は個人の天賦の才能や能力を、努力はその人のモチベーションや努力を指します。これらの要素が結びつき、個人が行う具体的な行動に影響を与えると考えられています。そして、企業はこれらの行動を評価し、それを成果として定義しています。
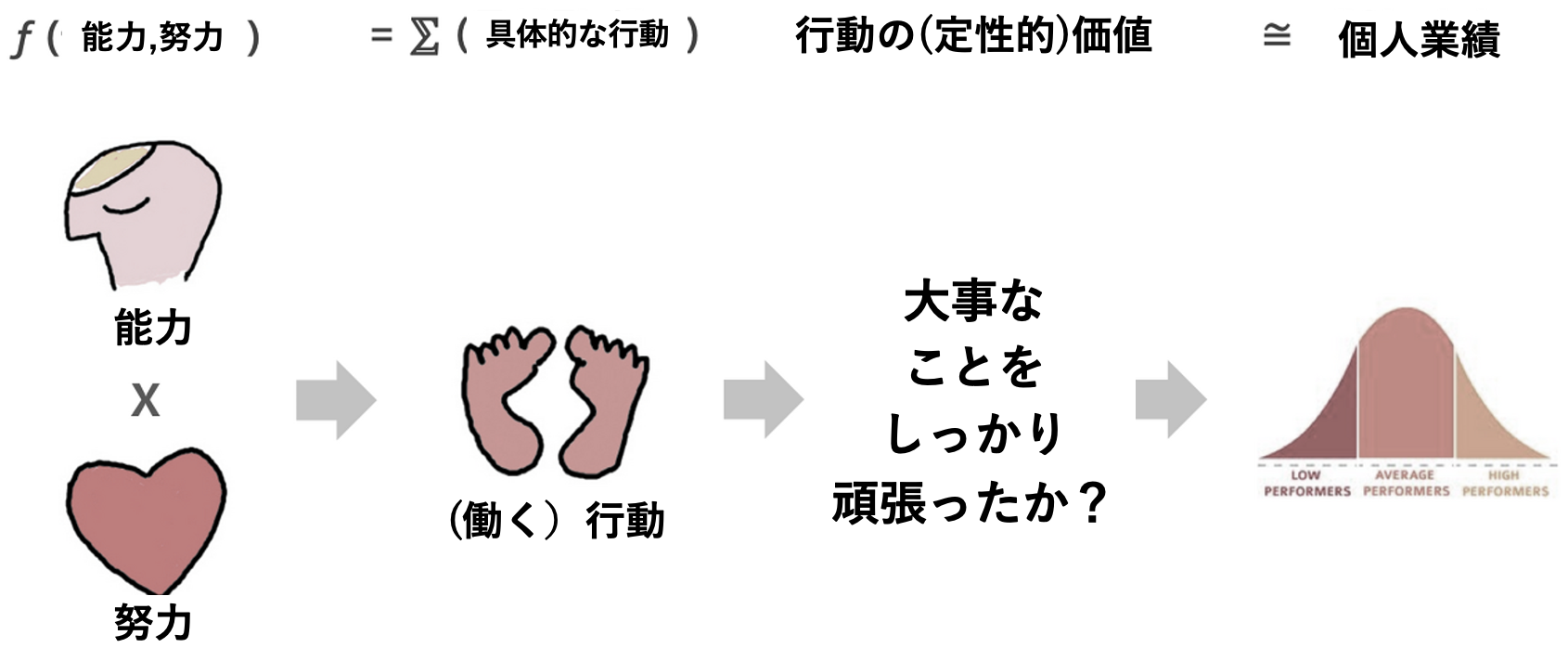
従業員の能力(Talent)の定義は、業界や職種、そして人に対する見方によって異なりますが、一般的には、能力を発揮して努力を重ね、重要な仕事に協力的に取り組む人ほど高い成果を出すと言えます。
もし、能力と努力を示す行動データを使って、高成果者と低成果者を区別し、成果のスコアを正確に予測できるモデルを作れれば、成果評価の主観性を補い、最終的にはそれを置き換えることが可能です。ただし、これには大きな問題があります。
行動データに基づく成果予測モデルが効果的であるためには、そのモデルの入力変数としての行動データが、能力と努力を代表するもの(代理変数)として、協調性、熱心さ、質の良さといった行為の定性的な側面を十分に反映している必要があります。しかし、現在測定可能な定量的な行動データでは、これらの能力と努力の定性的な側面を十分に取り入れることができていません。

上記の表のように数字で表せるほとんどの行動データが、実際には仕事をどれだけ頻繁に行うかを示すに過ぎず、その行動がなぜ、どのように行われたのかという詳細は含まれていないことを説明しています。予測モデルを使用することで、高成果者(低成果者と区別される)の典型的な行動パターンを把握できます。
例えば、メールの発信量が職級平均に対して特定のパーセンテージである、夜勤を平均より多く行うなどのパターンです。これらのパターンを用いると、高成果者をかなり正確に予測することが可能です。
しかし、このアプローチには限界があります。なぜなら、モデルの入力変数として成果の原因(能力×努力)ではなく、事後的な行動パターンを使用しているためです。このため、予測モデルは高成果者のパフォーマンスを持続的に維持する方法や、低成果者のパフォーマンスを向上させる方法を知るための実質的な助けにはなりにくいです。つまり、予測モデルはあくまで行動パターンを識別するのには役立ちますが、そのパフォーマンスを改善するための具体的な手段を提供するまでには至っていないのです。
私たちが介入できる個人の能力や努力にはどんなものがあるのか?
「能力×努力・行動・成果」モデルをさらに詳細に分析し、そのモデルに使用できるデータの種類(定量的データと定性的データ)と、そのデータにどのように介入できるか(介入が可能かどうか)、そしてもし制御が可能であればどのような方法で制御できるか(ターゲティングか変更か)に基づいて構築されたモデルを図解しています。
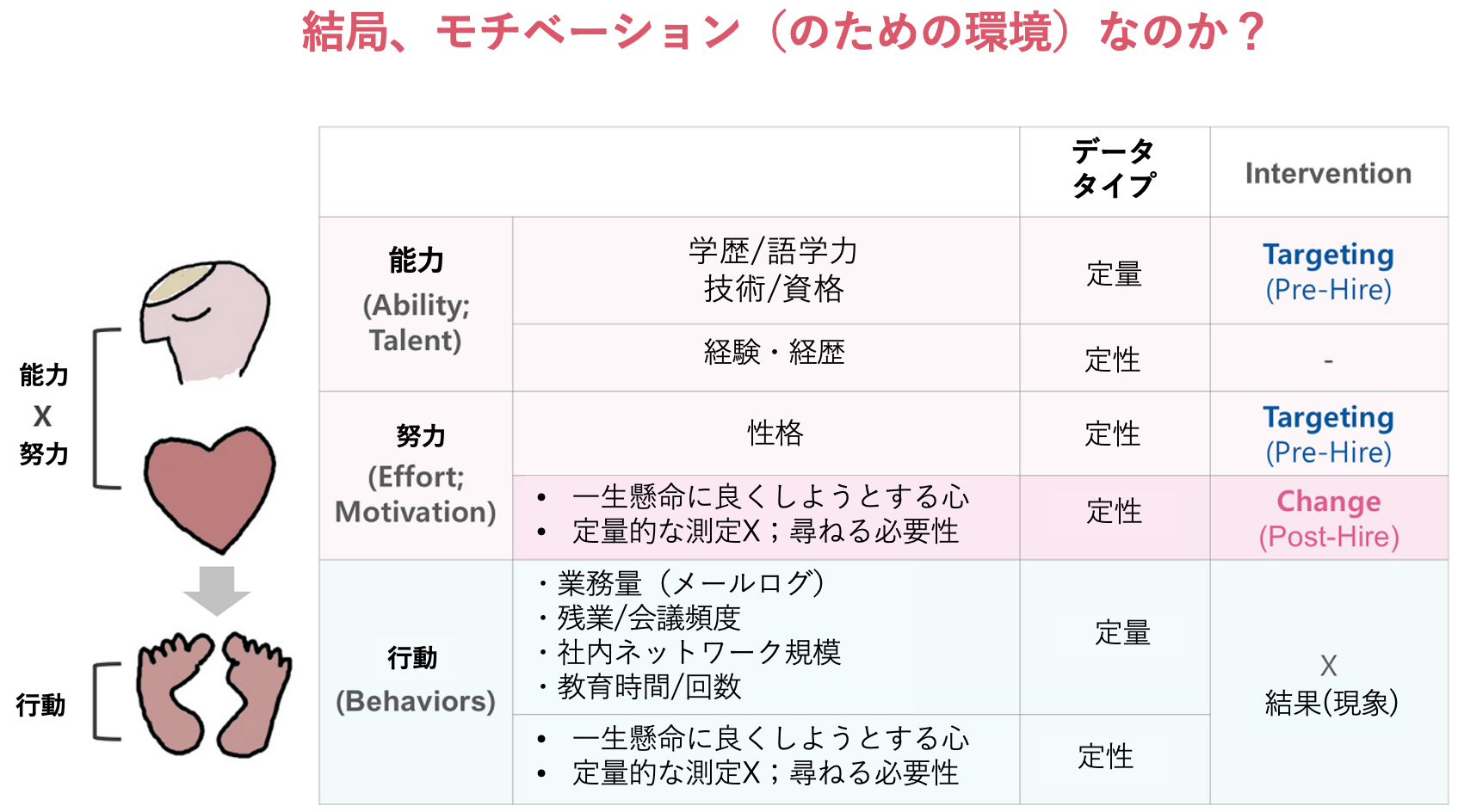
- 介入 = ターゲティング(採用前): 成果と関連する入力変数(例えば、理工系の学歴や誠実さ)を特定した後、これらの変数を採用プロセスに活用することができます。例として、理工系出身で誠実な志願者に採用時に加点を付与するなどが挙げられます。ただし、一度採用してしまうと、それ以上の介入は難しくなります。
- 介入 = 変更(採用後): 従業員が選択された後、人事部ができる介入には、社員が没頭して生産的に働きたくなるような職場文化、リーダーシップ、協働方法の改善などが含まれます。
要するに、採用前の介入は志願者の特定の特徴を採用基準に取り入れること、採用後の介入は職場環境や文化を改善して、従業員のパフォーマンスを向上させることを目的としています。
Maximum Performance vs. Actual Performance
個人の能力(Talent)は、個人が発揮できる最高値のパフォーマンス(Maximum Performance)を決定すると思います。
そして、人によって到達できる最高パフォーマンスレベルは人によって差があり、一定時点以降は簡単に変わりません。 (私たちは皆、普通以上の能力を持っていると思いますが、ドライバーの90%以上が平均以上の運転能力を持っているという信念のように根拠が希薄でしょう...)
しかし、実際に具体的な職場で個人が見えるActual PerformanceはMaximum Performanceではなく、[Maximum Performance ✖️ 努力(動機、没入レベル)]です。企業がEngagementを強調する理由でしょう。

モチベーション要因(X), 成果スコア(Y): これでは何も出ません
しかし、モチベーションによるパフォーマンスの予測と説明には、大きな問題があります。個人のパフォーマンスやスコアを目的変数(Y)とし、モチベーションを助ける環境を示す要因(例えばリーダーシップや働き方)を入力変数(X)として分析すると、はっきりとしたパターン(XとYの間の関係や規則)が見られません。
これは、どんなチームでも成績の良い人も悪い人もいるということです。リーダーシップのようなモチベーション要因は、成績の良い人と悪い人を区別するのにあまり役立たなかったことを意味しています。例えば、リーダーシップが低いAチーム長のチームでも、リーダーシップが高いBチーム長のチームでも、成績が良い人と悪い人は似たような割合でいます。
成果測定は結局モチベーションなのか?
Xを変えてYを改善するには以下の2つの条件が必要です、
- XとYの間に社会通念上の因果関係が存在する
- Xに対する制御(Intervention)可能性
この二つの条件をすべて満たす唯一のPeople Dataは、どうやら以下のようです。
- Y: モチベーションレベル
- X: モチベーション要因そして、没頭しているかどうか、没頭するためには何が必要なのかは、聞いてみないとわかりません。
エンゲージメントを測定するには、アンケートデータを活用する
モチベーション(努力)に関する唯一の問題は、アンケート以外の方法で科学的に測定するのが難しいことです。簡単に成果の高い社員の行動を分析し、モチベーションの手がかりを得ようと考えるかもしれませんが、残念ながら、ほとんどの企業では合法的に手に入る行動データからは、特定の行動の頻度や回数は分かるものの、モチベーションのような質的な側面を把握するのは難しいです。
- 従業員がどれだけ没頭しているかを測る方法として、熱画像カメラで撮影してエネルギー代謝が増えているかを見るという話を聞いたことがあります。
- また、瞳孔の大きさで没頭度が分かるという研究も読んだことがあります。
- ログから得られた行動データを使って、例えば残業の頻度などを分析することで、従業員の活動をある程度理解することはできます。ただし、これらは数字による分析なので、限界があります。
アンケートデータの限界と不信感
質的な要素を知るために質問するのは、悪いことではありません。たとえば、Facebookのような企業も、ユーザーが何を考えているか、なぜある行動をしたのかを知るために、デジタルログだけでなくアンケートも使っています。記事をクリックした理由などは、聞かなければ分からないからです。
しかし、国内企業の現場には、アンケートに対する根強い不信感が存在します。アンケート結果が一度も実用的に使われなかったことがその理由だと思いますが、もう少し構造化してみると
- 質問があらかじめ決まっている: 動機づけのための個人のニーズは様々であるはずなのに、事前に定義された質問に個人のニーズを全て盛り込むのは難しい。
- 正直に回答しない: 不利益を恐れたり、これが何の意味があるかという心理的な理由もあるだろうし、多肢選択式の回答ではどうせ自分の正直な声を伝えることもできない。
そこで、下記がその代わりとなるのではないでしょうか?
制御できるものとできないものをよく区別し、制御の効果が大きい要因に集中する
従業員に焦点を当てるべき要素はたくさんあります。たくさんの良い文章を考えることで、選択肢が多すぎて困ってしまうこともあります。
政府が市場を規制する理由は、市場の原理を完全に理解して正しい決定を導くことではなく、市場参加者が複雑すぎる判断に迷わないようにすることです。
Googleの有名なプロジェクトの価値も、内容が新しいことではなく、優れたリーダーの行動を具体的に8~10個に絞り、リーダーが従業員に関する決定をする際の迷いを減らすことにあります。

https://rework.withgoogle.com/blog/the-evolution-of-project-oxygen/
考え方が大きく変わるためには、新しい考え方で、以前の考え方ではうまく解決できなかった問題を解決する必要があります。People Analyticsが新しい考え方として受け入れられるためには、成果や生産性に関する問題を実際に解決する方法を見つけなければなりません。これは長い道のりになるでしょう。
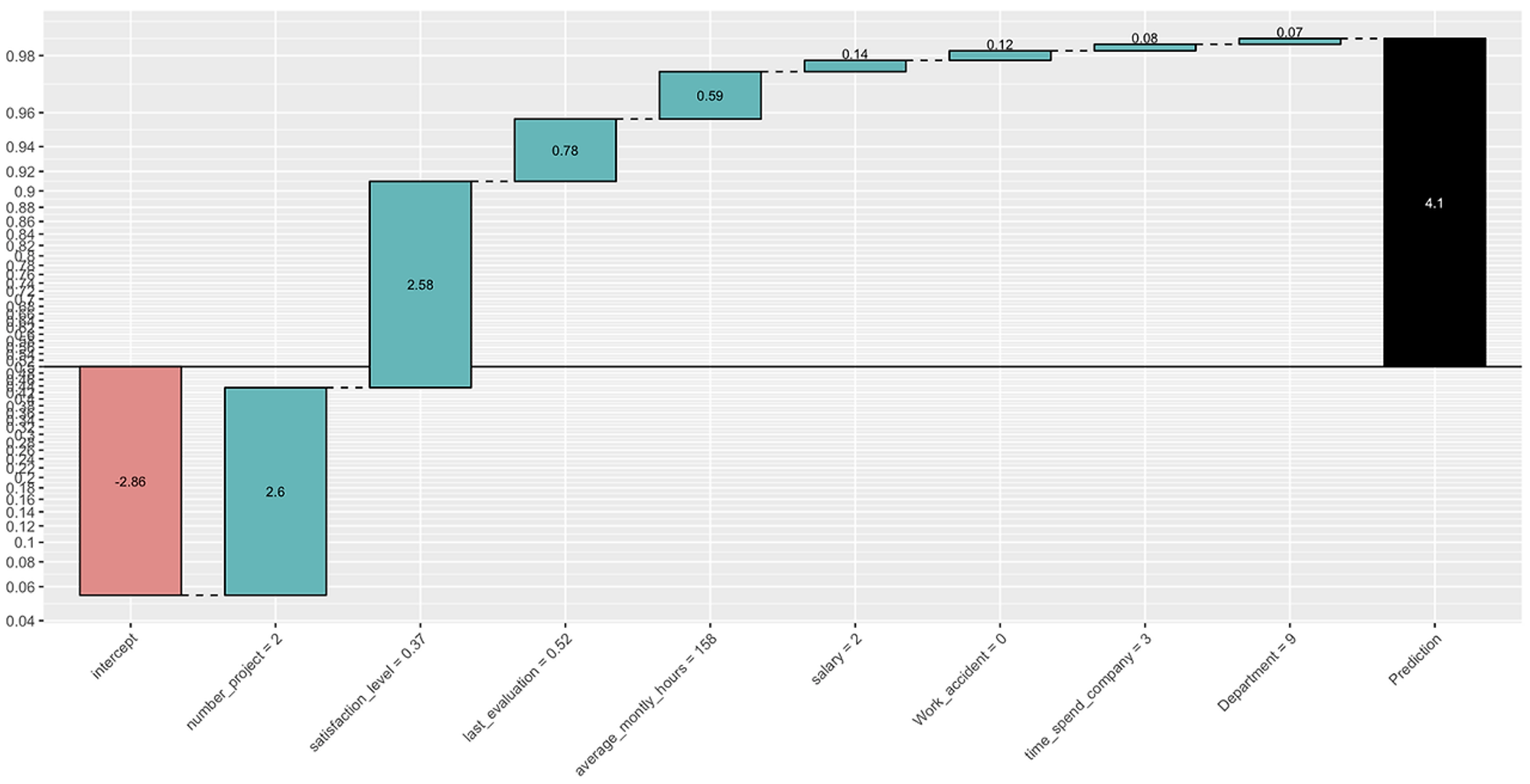
説明しやすいモデル(例えば回帰分析や決定木)は、なぜある従業員が成績が良いかをわかりやすく教えてくれますが、予測の正確さはそれほど高くありません。一方、予測が得意なモデルは、どうして動くのかがよくわからないため、なぜある従業員が成績が良いか、または悪いかについて納得できる説明を提供できません。これがモデルの信頼性や実用性を下げる原因になります。
解釈可能な機械学習(Interpretable Machine Learning)は、モデルの説明力と予測力のバランスをとる方法です。まず予測力が高い複雑なモデルを作ります。その後、そのモデルがどう動いているかを人が理解できるように説明します。これにより、モデルが間違ったパターンを学習していないかをチェックし、成果を上げるためにどう入力を変えるべきかを教えてくれます。この方法はモデルへの信頼性と実用性を高めるため、最近多くの関心を集めています。
Interpretable Machine Learningについて詳しく勉強したい方
https://christophm.github.io/interpretable-ml-book/


![[HEARTCOUNT実習例] HR dataset - I(人事分析)](/ja/content/images/size/w540/2024/10/------_--------_-----_--------_-1-.png)



