
イントロ: アンケート分析について
行動データ vs アンケートデータ
ビッグデータの時代に、観察データが豊富にあるにも関わらず、なぜ従来のアンケートによる質問を続けるのかという疑問に対し、「質問できるから質問した」という回答も一つの考え方だと申し上げます。
多くの方がアンケートデータの代わりに行動データを利用することが一般的だと考え、アンケートデータを低く見ていることがありますが、これに対しては、長年にわたる社会科学の研究伝統と方法論を、最新のデータサイエンスと組み合わせて新しいアプローチを探ることも有効な方法です。
社会科学+データサイエンス(Social science + Data science)
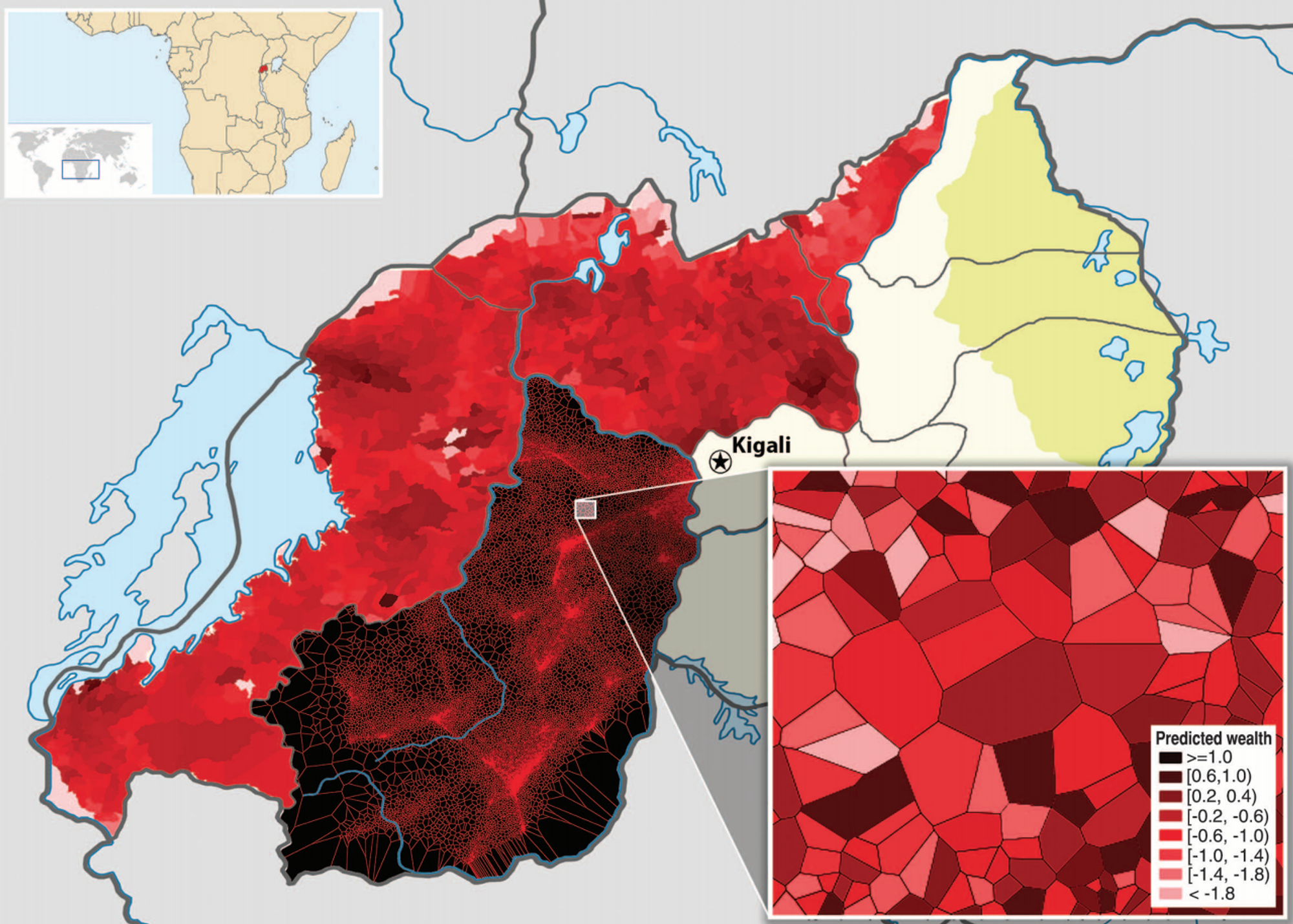
最小限の努力と費用でルワンダ全土の所得水準分布を正確に確認するにはどうすればよいでしょうか?
2009年、Joshua Blumenstock(貧困国や紛争地域に住む人々の社会的・経済的状況をデータを通じて説明する有益なプロジェクトを行っているUC Berkeley大学の助教授)は、この問題をわずか856人に電話をかけ、解決しました。
その内容を簡単に要約すると、ルワンダの1位の無線通信事業者が保有する150万人以上の加入者のCDR(Call Detail Records;誰がどこに住んでいて、誰とどのくらい通話したかを記録したログ)データと、電話アンケートで確認した所得/経済レベルのデータを組み合わせて、CDR情報で所得レベルを予測するモデルを作ったのです。
アンケートで確認した850人余りの所得/経済水準(Y)と彼らの携帯電話通話履歴(X; CDR)を機械学習アルゴリズムを使って学習した後、予測モデルを作り、CDR情報(X)だけで所得/経済水準(Y)を予測するようにしました。社会科学の研究方法であるアンケートとデータ科学を組み合わせて、安価かつ迅速に有用な情報を得た素晴らしい事例です。
アンケートデータ分析実施時の注意点
ショウジョウバエを研究する人は、ショウジョウバエをよりよく理解するためにショウジョウバエの行動を観察するしかないでしょう。
しかし、人を研究する人は、人の行動を観察することに加えて、人に直接質問することもできます。
アンケート調査結果には一般的に2つのエラーがあると言われています。
- Representation Error-代表性エラー:アンケートに参加した人々の回答を持って集団(population)に対する推論(一般化)をする過程で発生するエラー; *全職員を対象に実施する調査のようにsample=populationである場合は、non-response(アンケートに応じない人)がある程度randomly(均等に)分布している場合、代表性エラーは無視してもよい。[*著者の主観的な意見である].
- Measurement Error-測定エラー: 言ったことから考えや行動を推論する過程で発生するエラー; 同じ質問でも質問の構造(聞き方)によって回答が異なる。
*企業内調査の場合、匿名性や調査の効用に対する不信感から、従業員が建前上、適当に回答する傾向がある。[※著者の主観的な意見である].
行動データでは絶対にわからないこと
こうしたアンケートの明らかな限界にもかかわらず、行動データからは絶対にわからないことがあります。
例えば、人の行動を予測する要因(driver; cause)は、感情、認識、知識、意見など内面の状態(inner state)に関連するものですが、私たちの頭蓋骨にぎっしりと詰まっている内面の状態を知ることができる最善の、そして現時点で唯一の方法は、やはり尋ねることです。また、企業環境内で測定可能な従業員の行動データ(例えば、平均メール送信件数)は、多くの場合、私たちが理解/予測しようとする行動(ハイパフォーマンス)の原因(cause)ではなく、症状(symptoms)になりがちです。
例えば、成果スコアとメール送信件数との間に高い相関関係が発見された場合、メールをたくさん送ったから(cause)高成果者(effect)だと解釈するよりも、高成果者だから仕事をたくさんして結果的にメールをたくさん送ったと解釈する方が妥当です。 そして、ルワンダの事例で確認したように、アンケートデータを行動(ビッグ)データと組み合わせる場合、行動データだけでは不可能だった深くて波及力のある分析が可能になることもあります。
Analysis in HEARTCOUNT
Dataset: 幸せに関するアンケート調査
公開されたアンケートデータをHEARTCOUNTで分析してみましょう。
分析に使用したデータは、2013年度に英国のある統計授業で学生にアンケートを実施した結果です。 合計150の項目で構成されており、ほとんどが5点満点(Strongly disagree:1点、Strongly agree:5点)のいずれかを選択するように設計されています。
質問を構成する主な項目は:
- 音楽・映画に対する好み (例えば、私は音楽を聴くのが好きです。)
- 趣味、健康習慣、消費習慣(例えば、私は詩を書くのが好きです。)
- 性格、人生観、怖いもの (例えば、私は怒ると物を壊したことがあります。)
- 人口統計学的特徴(年齢、性別、教育程度、兄弟姉妹の数など)
設問のうち「Happines in Life: I am 100% happy with my life(幸福度;私は私の人生に完全に満足している)」に対する回答と他の設問との関係を通じて、幸福の要因(What Drives Happiness)を探してみましょう。
Small Multiples: 全体を一目で確認
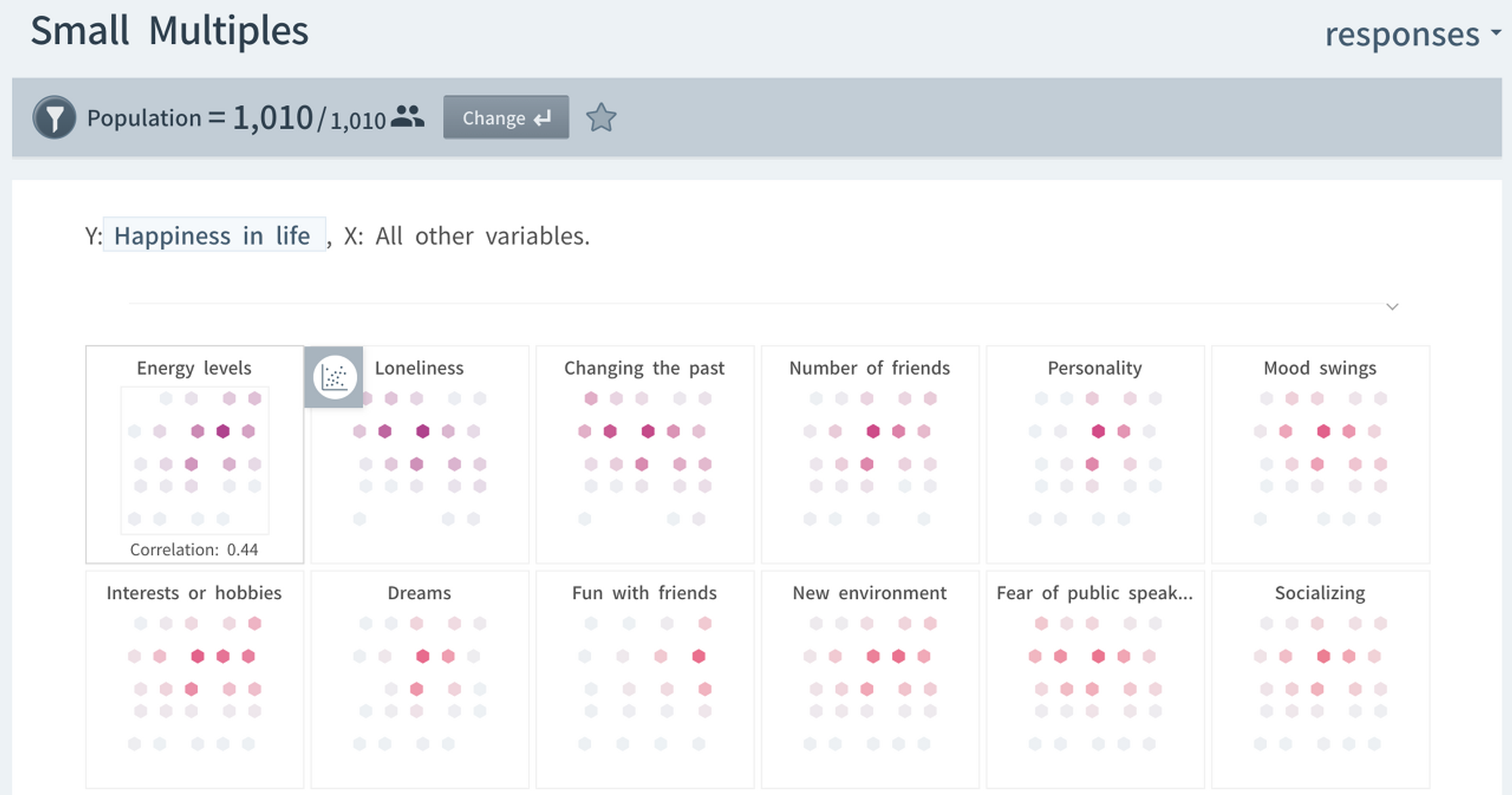
まず、HEARTCOUNTの可視化機能の一つであるSmall Multiplesで[Happiness in Life]項目に対する回答スコア(5点満点)と他の項目回答スコアとの相関関係(Correlation)を降順で確認してみました。
<レシピ>
<分析結果の解釈>
相関係数の絶対値の大きさを基準に上位のネガティブを見ると:
- 1位: "Energy Level: 私はいつも元気である"と最も大きな正の相関関係 (+0.44)
- 2位: "Loneliness: 私は孤独である"と次に大きな負の相関 (-0.44)
- 3位: "Changing the past: 私は過去に戻って自分がしたことを元に戻したい。"と負の相関関係 (-0.35)
- 4位: "Number of Friends: 私は友達が多い"と正の相関関係 (0.32)
ここで、Energy LevelとLonelinessは(Un)Happyの要因(Cause)ではなく、(Un)Happyの症状(Symptoms)に近いです。相関関係の高い他の項目がCauseかSymptomかという判断は、データ分析の領域ではなく、むしろ常識の領域と言えます。
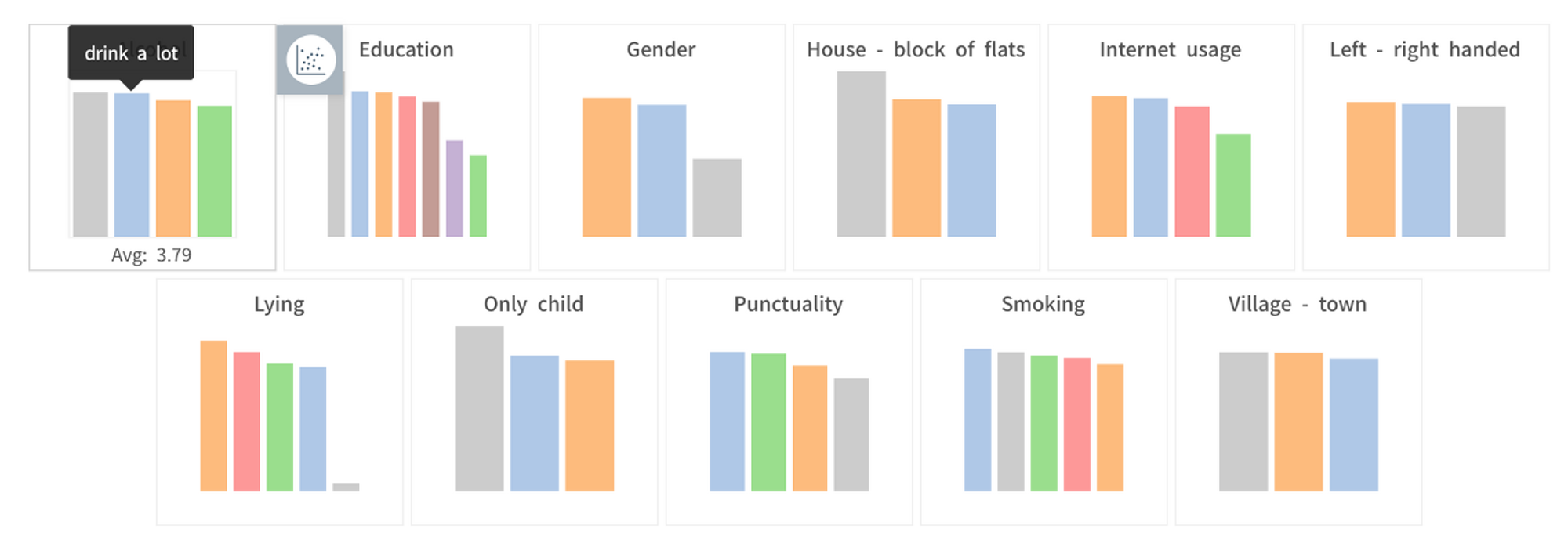
5点尺度以外の多肢選択式の質問のうち、飲酒/喫煙習慣に対する回答タイプ別に幸福度平均点を比較してみると、(幸福度全体の平均点:3.71)
- 飲酒習慣: よく飲む(平均: 3.79) > 飲まない(3.73) > たまに節制して飲む(3.67)
- 喫煙習慣: 現在喫煙中(平均: 3.78) > 吸ったことがない(3.72) > 過去に吸ったが今はやめた(3.63)
Drill-Down: 変数の組み合わせによるランキング
先ほど、常習的な飲酒、喫煙行為を示す集団が高い幸福度を示した結果に勇気づけられ、ドリルダウン機能(同じくハートカウントの可視化機能、無料ですぐに使用可能:お試しください)を使って、飲酒と喫煙習慣の組み合わせによる幸福度スコアを比較してみました。
<レシピ>
- ドリルダウンで平均を比較したい変数を選択します。
- 合計3つの形のうち最後の形を選択すると、「全体平均」を基準に遠い順に一目で確認することができます。
- より有意義な分析のために、以下の例のように最小レコード数を設定することができます。
- ドリルダウンする条件(変数の組み合わせ)を追加し続けることができます。
<分析結果の解釈>
- 驚いたことに、タバコもお酒も口にしたことがない集団が平均3.87点で一番幸せであった(右側第一列)。
- 一方、お酒は飲まないが、タバコはかつて吸ったが今はやめた集団が3.54点で一番不幸だったことが分かりました。 左の最初の行)。
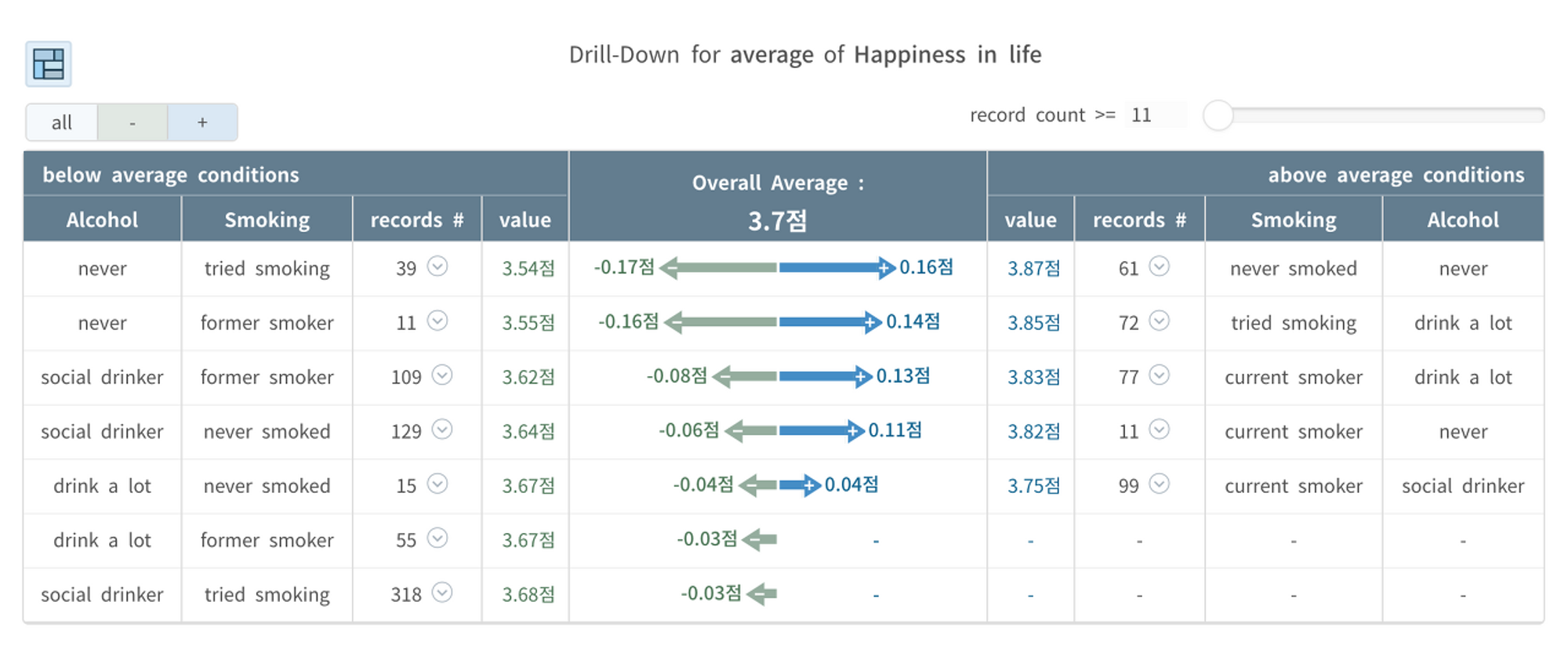
飲酒と喫煙それぞれについて、一つの視点(次元;変数)で幸福度の平均を比較したときと結果があまりにも異なることがわかりますよね?
納得がいかないのでGender(性別)変数を追加して3つの視点の組み合わせで幸福度スコアを分割(Drill-Down)してみました。
- お酒もタバコもしない女性の場合、幸福度が3.94で非常に高い(右列2列目)
- お酒もタバコもしない男性の場合、幸福度が3.79で平均を少し上回る(右下)
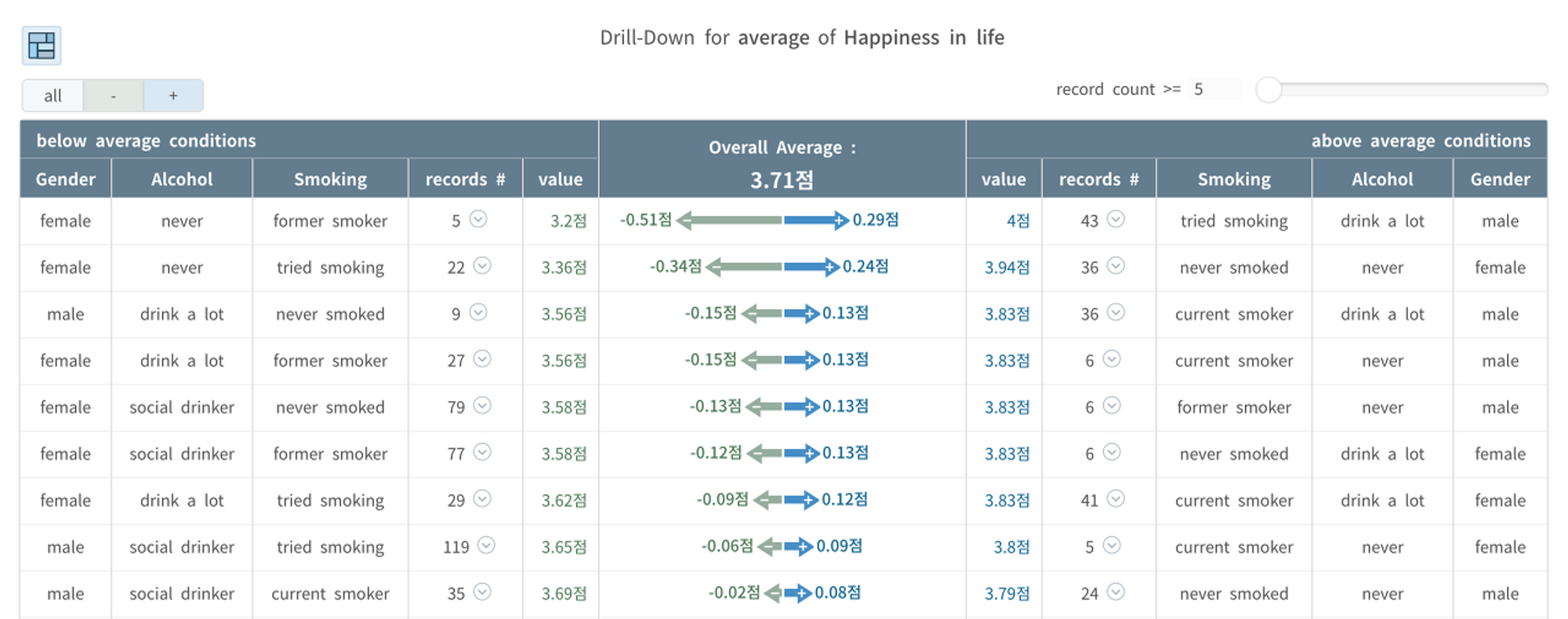
上記で性別を区別せず、飲酒、喫煙の2つの視点の組み合わせだけで比較した場合、酒もタバコも絶対にしない集団の幸福度が最も高いのは女性の影響が大きいことが分かりました。
3つの組み合わせで比較した場合、
男性は、
- タバコを吸っていて今はやめたが、お酒をよく飲む男性が一番幸せだった。
- 次いで、お酒とタバコを習慣的に吸う友達が幸せだった。 (※調査対象は15~30歳の英国の学生と学生の知人。)
関係分析: Driver Analysis (統計的に有意な要因)
今回は関係分析機能(要因分析)を使ってHappiness項目と残りの149項目との間で回帰分析を行ってみます。
<レシピ>
要因分析で、違いをもたらした要因を分析したい数値型KPI(Happiness)を選択し、[分析]をクリックします。
<分析結果の解釈>
- 個別変数の重要度による回帰分析結果のランキングを見ると、Small Multiples画面で見た相関関係の大きさの順番と同じように出てくることが確認できます。これは個別独立変数と従属変数間の関係を分析する単純回帰分析の場合、回帰分析結果の重要度である決定係数(R²)が数学的に相関係数(r)を二乗した値だからです。 (*. エネルギーレベルの相関係数である0.44を二乗すると、0.194)
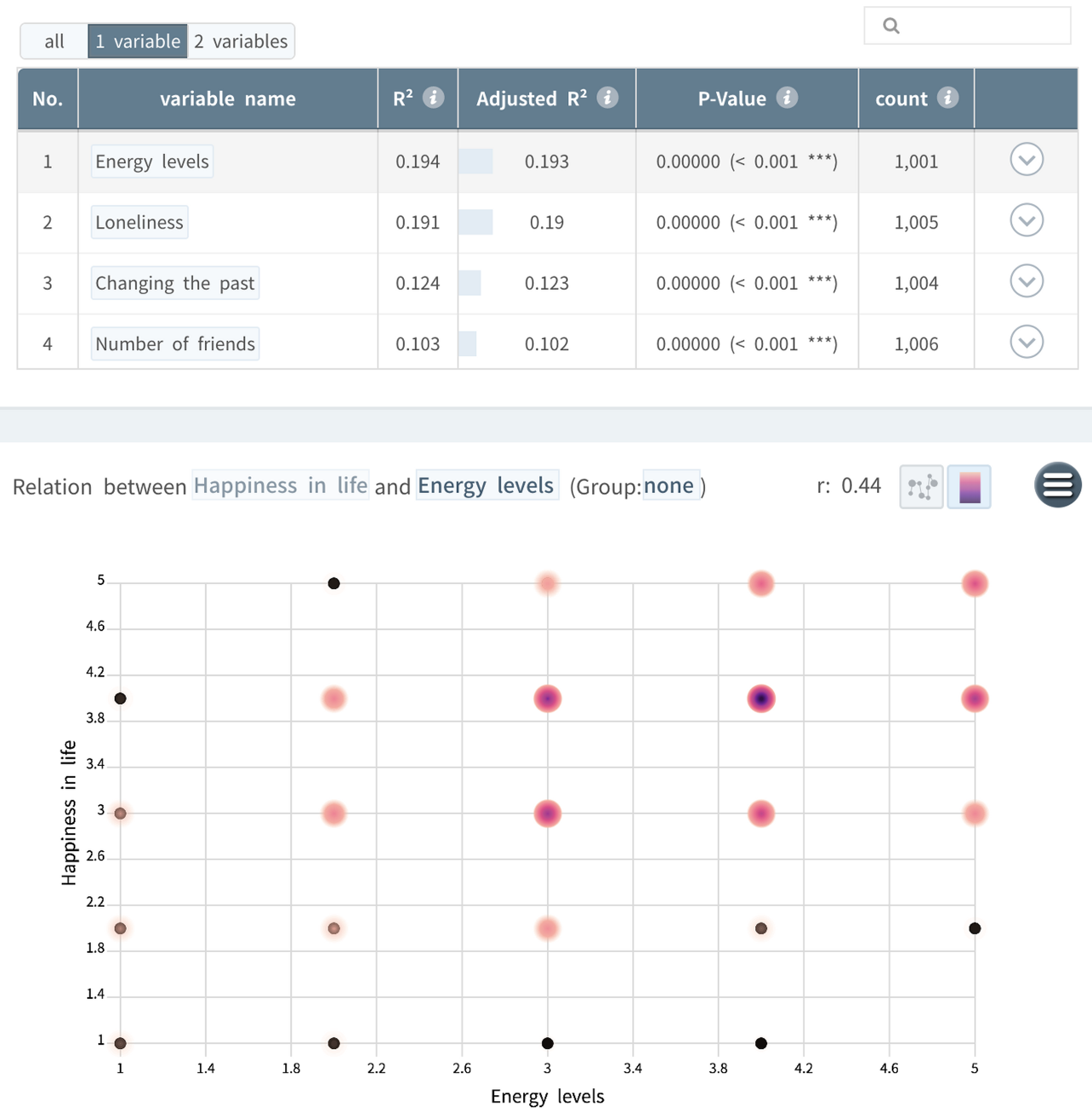
- しかし、喫煙や飲酒習慣は関係分析の結果、表には出てきませんでした。 喫煙習慣や飲酒習慣による幸福度スコアの差が統計的に有意ではないからです。
統計的有意性について簡単に説明すると、集団内(お酒を飲む集団)の幸福度の差よりも集団間(お酒を飲む集団と飲まない集団の間)の差が大きくなければ統計的に有意な差が存在すると主張することができますが、下の図のように、個々の集団ごとに平均スコアは異なりますが、95%信頼区間平均スコアを比較すると、信頼区間が重なり、集団間の差が統計的に意味がないと判断されたためです。
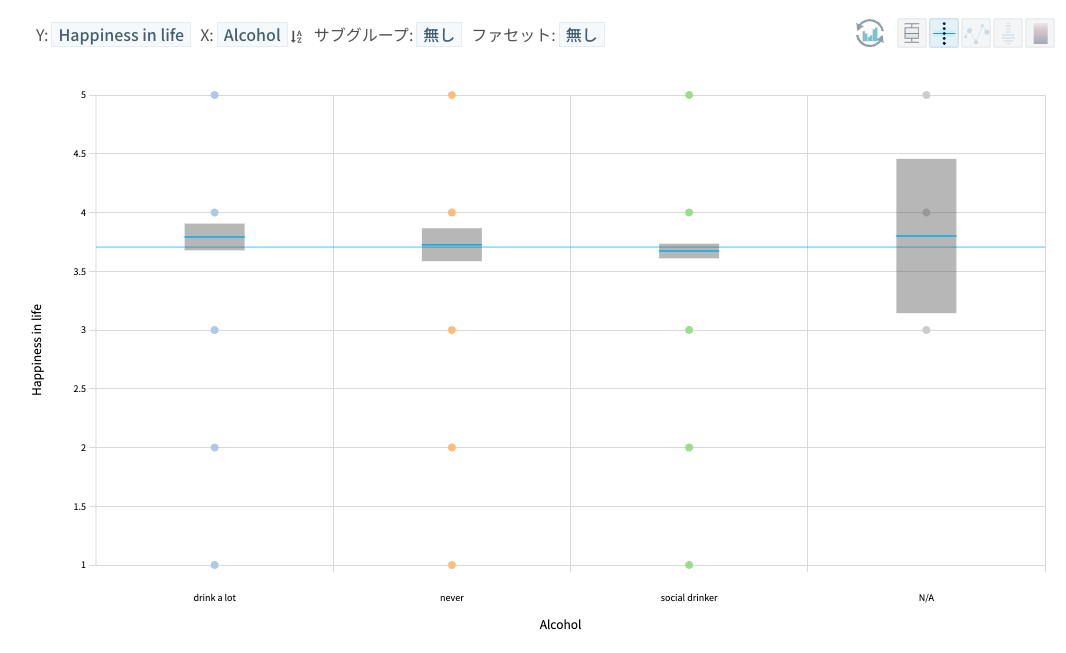
統計的に有意なもの(Statistical Significance)よりも、実用的な観点から有意なもの(Practical Significance)が会社に利益をもたらすという趣旨でデータを分析する現場の立場でより重要です。
Micro-Segmentation: 両極を比較する非常に良い習慣
最後に、セグメンテーションを通じて、男性と女性それぞれが幸せを最大化できる条件を探してみましょう。
「Happiness in life」に5点と答えた確実に幸せな集団(似ていたい集団;73名)と、1~2点と答えた確実に不幸な集団(30名)をターゲットとし、2つの集団(セグメント)を区別する論理的なルールを見つけようとします。
<レシピ>
まず、HEARTCOUNTの共通機能であるフィルタリング機能を利用して、以下のように分析条件を設定しました。
- 性別の場合、男性のみ分析
- 分析に使用する合計150個の変数のうち、幸/不幸の原因というよりは結果に近い[Loneliness]と[Energy Level]変数を除く。
最適化ルールを探す変数として「Happiness in life」を選択し、詳細設定で直接ターゲットをカスタムしました。
- デフォルト:数値型変数の場合、上位20%グループvs下位20%グループの分類ルール分析
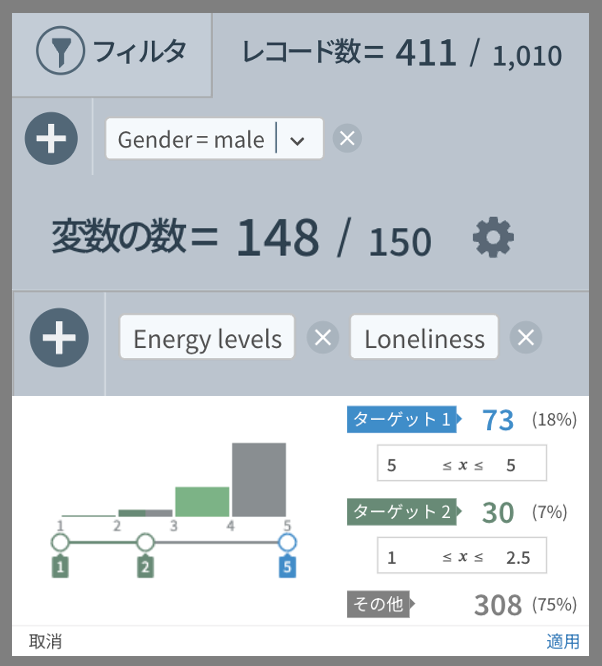
<分析結果の解釈>
決定木の結果を見ると、
- 男性の場合、友達の数が多ければ(4点以上回答)無条件に幸せ: 4.76点
- 友達の数があまり多くないが(3点以下回答)、過去に執着しないようにすれば(2点以下)幸せ: 4.3点
- 友達も少ないのに(3点以下回答)、過去にとらわれながら生きていると(3点以上)大きく不幸: 2.32点
先ほどのお酒の話に戻ると、飲酒を常習的にする行為は、友達が多いことの直接的な結果だと考えられます。男性の場合、友達の数が幸福度と飲酒頻度の両方に影響を与え、飲酒頻度と幸福度の間に関係が見られたのかもしれません。
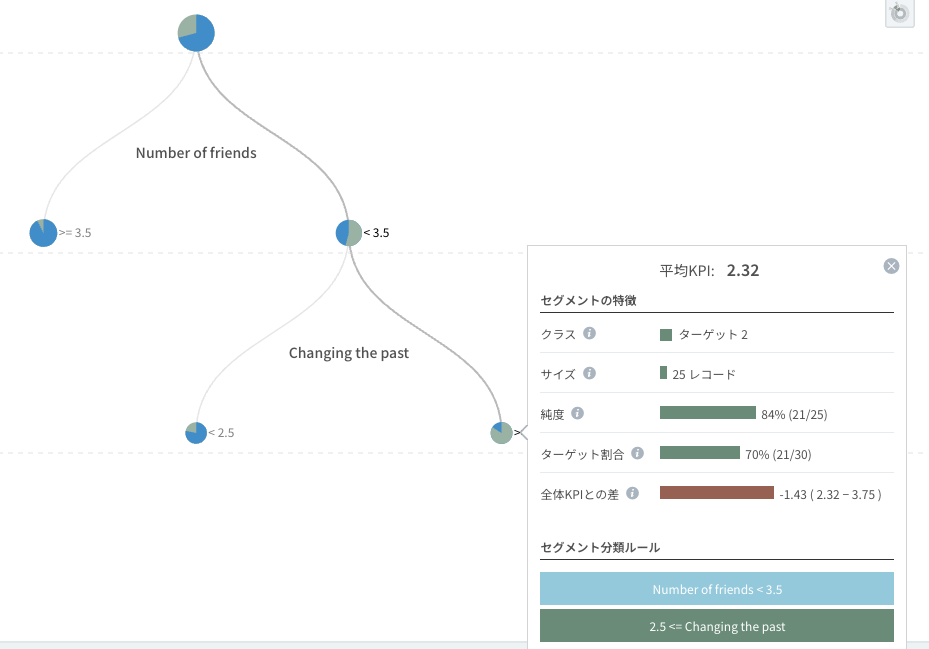
女性も同じように、幸せな集団と不幸な集団が高い純度で密集しているセグメントの条件を探しました。
女性の場合、
- 過去のことを後悔せずに生きる(2点以下回答)無条件の幸せ: 4.76点
- 過去について執着するが(3点以上回答)、肯定的な夢を抱いて生きる(Dreams: 4点以上)幸せ: 4.33点
- 過去について執着し(3点以上回答)、未来に対するバラ色の夢もないが(Dreams: 3点以下)、経済/経営に高い関心を持っていれば幸せ: 4.4点
- 過去から抜け出せず、未来は灰色で、経済/経営に興味もなければ、完全に不幸: 2.2点




![[HEARTCOUNT実習例] HR dataset - I(人事分析)](/ja/content/images/size/w540/2024/10/------_--------_-----_--------_-1-.png)