最近では「データドリブン型の意思決定」「データリテラシー」のような話はあまり聞かなくなりました。企業が運用の効率化を実現し、顧客や市場に対する精緻な理解で競争優位を占めて市場で生き残るためには、データを収集してデータに含まれるパターン(シグナル/インサイト)を発見して意思決定に活用しなければならない、という主張が、約15年前から企業にとって一種の定言命法のように機能していました。同じ文脈で、企業実務者が必ず学ばなければならない未来のスキルとして「データリテラシー」が脚光を浴びることもありました。
しかし、データの持つ世界に対する情報の貧弱さ(発生したことだけが収集され、発生する可能性があった数多くのことは除外される)と曖昧さ(意思決定に活用できるパターンなのか、偶発的なパターンなのかを区別することの難しさ)を理由に、最終的に信じるのは直感と個人的なノウハウだと考える人(Data Skeptic、反知性主義者?)もその数が着実に増えています。
このブログでは、
- 意思決定に活用できる3つの情報源の1つである定量的なデータの解釈について説明し、
- 定量的なデータ分析結果の3つのタイプのうち、ノイズ(noise)とシグナル(signal: 有用なパターン)の違いについて説明をして、
- (実験データではなく)観察データを使用して指標の違いを理解することの重要性とその実用的な方法について議論した後、
- データセットでノイズとシグナルを区別する分析のデモを行う予定です。
このブログが、データから見つけた道が、皆さんが踏み出している世界の道とつながることを願っています。私は HEARTCOUNT の Sidney です。
3x3
3x3-a: 意思決定のための3つの情報源
人が五感で世界を理解すると言っても、「視覚は信頼できる器官ではないので、聴覚にもっと集中しなければならない!」というような話はしません。同様に、企業内の主要な意思決定においても、以下の3つの情報源(感覚)を総合的に用いる必要があります。
- 直観: 経験を通じて蓄積された世の中の仕組みに対するメンタルモデル
- 定性的なデータに対する解釈: 顧客の定性的な意見、フィードバックに対する解釈(定性的なデータに対する標準化された解釈方法がないため、その解釈は直観による影響を大きく受けます)
- 定量的なデータに対する解釈
データ、もう一つの感覚器官
自分が知らない(直観が形成されていない)ある質問に対する答えを見つけたい(仮説を検証したい)場合、定性調査(顧客から話を聞いてみよう)と定量分析(実験を設計して収集したデータやすでに観測されたデータで仮説を検証してみよう)を活用するしかありません。
- 私たちの製品の存在をすでに知っている人が、なぜ私たちの顧客にならないのか?
- 既存の顧客のうち、製品を多く購入する顧客とそうでない顧客の違いは何だろうか?
最初の質問の場合は、市場調査(アンケート)などの定性調査を行う必要があるでしょうし、2番目の質問に答えるためには、顧客の行動データを分析して2つのグループの違いを理解する定量的な分析が必要でしょう。
データに含まれるパターンとその解釈が企業内の意思決定のための唯一の軸ではありませんが、直感とともにそれを補うような形で活用されるべき主要な軸であることに共感していただければ幸いです。このブログを読んでいる皆さんの心がそうであることを前提に話を進めていきます。
3x3-b: 定量的なデータの分析結果の3つのタイプ
定量的なデータの分析結果は、それがExcelのピボットやSQLクエリの結果であれ、Python/Rのコードによる統計分析の結果であれ、あるいはChatGPTが教えてくれた結果であれ、以下の3つのタイプのいずれかに属します。
- Confirmation: すでに知っていた事実(Known)の定量的確認
- Noise: 興味深いが(Unknown)醜い事実の発見
- Signal: 興味深い(Unknown)有用な事実の発見
- すでに知っていた事実の確認
「私たちがすでに知っていたこと(メンタルモデル)」がデータを通じて確証される場合です。知っていた事実が定量的により洗練された表現されることもありますが、大きな枠組みで既存の知識を確認することであると思います。(知識の生産と拡張X、知識の確認O) 例えば、「所得水準の高い顧客がより高価な製品を購入する」「寒い地域で冬服がより多く売れている」など、知っていた事実を確認する場合です。
- 興味深いが、意思決定に活用しにくい事実
私たちが知らなかったことですが、意思決定に活用しにくいパターンです。世の中のノイズ、運の影響により発生した一回限りの現象であったり、私たちが理解したり、コントロールできない存在の作用により発生した結果です。以下のようなものですね。
- Noise: コーヒーの販売量が前週比4%増加しました。ところが、販売量は毎週5%前後で安定して推移しています。(うごめくチャート)
- External Event: 先週、横浜のコーヒー販売量が200%増加しました。一方で、先週は横浜で国際映画祭が開かれました。
- Good to Know (So What?): 製品割引率が高いと純利益が減ります。1キロ圏内の競争相手の数が増えるほど、店舗売上が減る(負の相関関係)。でも、どうしろって...。
- 役に立つ情報、シグナル(Signal)
一方、新しい(Unknown)のに有用(Useful)な事実をシグナル(Signal)と定義することができます。私たちがまだ知らなかったこと(unknown unknowns)の中で意思決定に活用して実行に移すことができるパターンです。例えば、
- ウェビナーを通じて流入した顧客にサービス加入後24時間以内にパーソナライズされたメールを送信すると、有料サービスに転換する可能性がそうでない場合より20%高くなる。
- 1万円以上の注文時に送料無料を提供することがむしろ利益を減少させる。(1万円を少し超える注文)
シグナル - グループ間の違い(Variation)を理解する
私は、観察データからグループ間の経営指標の違い(Metrics Variation)を理解することが、費用効果的に知識の拡張と生産に貢献するという点で、データドリブン型の意思決定の核心であると思います。つまり、データが知識生産のための手段やツールになるためには、実務者が観察された指標の違いが無視してよい変化(ノイズ)なのか、注目すべき特別な変化(シグナル)の反映なのかを簡単に区別できなければなりません。
シグナルとノイズを区別する場合は、データの種類(実験データ vs. 観察データ)によって考慮すべきことがあります。その話から始めましょう。
- 実験データ: 具体的な質問に答えるために収集されたデータで、A/Bテストを考えてみるといいと思います。
- 観察データ: ビジネスの副産物として収集されたデータです。Webトラフィック、売上データなどが代表的です。費用効果的にシグナルを発見できるデータです。
実験データ
「ユーザーのオンボーディング時にAという変化を与えたところ、コンバージョン率が18%増加した」という主張に対する私たちの慣れ親しんだ反応は、おそらく「それは統計的に有意ですか?」でしょう。
実験をするのは費用がかかることなので、限られたデータで一般化された主張をするために、私たちは統計の検定方式を利用して、実験結果が偶然に発生した確率が5%以下であれば、統計的に有意であると結論付けることにしました。
 sidney yang
sidney yang
統計検定、統計的有意性について詳細を知りたい方は、このブログをお勧めします
観察データ
一方、「私たちの売上が先月より15%減少した」という話に対する私たちの反応はどうでしょうか? どうすればいいのでしょうか?
経験豊富な実務者であれば、「ちょっと待ってください、これがノイズによる自然なチャートのゆらぎなのか、それとも何らかの構造的な変化の反映なのか確認しましょう」と言えるはずです。
実験データで重要なことが、限られたデータで発見された具体的な事実に対する統計的(実用的)有意性を問うことであるのに対し、観察データで重要なことは、指標の変化と違い(Variation)を理解し、上手く扱うことです。
関連して、Donald J Wheelerの話
Donald J Wheeler は SPC (Statistical Process Control - 製造、サービス分野で指標の変動の原因を探し、品質やプロセスの効率化を図ることを扱う学問)の専門家ですが、関連して次のような話をしました。(原文を抜粋します)
data are a by-product of operations you will usually be trying to operate the process in some steady state. Here you will usually want to know whether or not an unplanned change has occurred. This is a completely different question from the one considered with experimental data.
Here we are not looking for a difference that we think is there, but asking if an unknown change has occurred. Before we sound an alarm we will want to be reasonably certain that a change has indeed occurred, making our approach to analysis conservative.
(中略)
Thus, with an Observational Study, we perform a sequential analysis using a continuing stream of data while looking for signals of any unknown or unplanned change which may occur. To minimise false alarms we require a trivial risk of a false alarm for each individual act of analysis.
------
(日本語訳)
データは、オペレーションの副産物であり、通常、プロセスをある定常状態で運用しようとするものである。ここで通常知りたいのは、予定外の変化が起こったかどうかである。これは実験データで考えるのとは全く異なる問題である。
ここでは、あると思われる違い(差)を探すのではなく、未知の変化が起こったかどうかを問うのである。アラームを鳴らす前に、私たちは変化が本当に起こったことを合理的に確信したい。
(中略)
従って、観察研究では、未知の、あるいは計画されていない変化のシグナルを探しながら、継続的なデータの流れを使って逐次分析を行います。誤報を最小限にするために、個々の分析行為に対して誤報のリスクを些少にする必要があります。
Donald J Wheeler の理論についてより詳しく知りたい場合
観察データから知識を生みだす
データドリブン型の意思決定の目的は、結局、費用効果的に新しい知識を生みだし、既存の知識を洗練することです。実務者が主に扱うデータが観察データであると考えると、具体的な質問に答えるために収集されたデータから因果的な知識を生みだす実験データの分析とは異なり、観察データから知識を生みだすためには、指標の違いを効果的に理解し、その中でシグナルを見つけることが重要です。
データの道が世界の道とつながるためには
ビジネス運営の副産物として蓄積された観測データから知識を生みだすことは、その重要性に比べて、まだ体系的な理論的基盤やベストプラクティスが普及していません。私たちがすでに持っているデータから見つけた道が、知識というフックで世界の道につながるための方法を丁寧に提示します。
ポンジ・スキーム(Ponzi Scheme)をうまく終わらせる方法
ポンジ・スキームを運営している人には、およそ3つの選択肢があります:
- 詐欺行為を続ける: 最終的にはより大きな罰を受けることになる
- 詐欺をやめる: 投資家に真実を明らかにし、贖罪して減刑を受ける
- 詐欺をビジネスに転換する: 残った資金を活用してビジネスを立ち上げて成功させる

上記の内容を「データドリブン型の意思決定」に注意深く当てはめてみることができます。データ分析が企業に大きな価値をもたらすと信ずることから始めて、このソリューションが導入され、制度が改善され、人たちが変われば、「晴天の霹靂の日」が来るだろうという希望で10年間を耐えてきました。 今、無駄な約束の代わりに、最小限のコストで価値を生み出す Data Economics (ROI)について話し合い、実践しなければなりません。
未知のことを知るためのコスト - Know When to Finish
例を一つ挙げてみましょう。
データが我が家の裏庭だと考えてみましょう。(広い庭を持つ米国の)誰かが庭で金塊を発見しました。誰もが我が家の庭にも金塊があると言います。金塊がなかなか見つからない、庭の大きさが問題だと言います。より多くのデータを収集します。庭の掘り方が問題だと思います。最新のデータツールを導入します。
みんなの庭に金塊があるという仮定が間違っているのではないでしょうか? 自分の(観測)データからわかることの限界を知り、努力の最適点を決める必要があります。

伝統的な試み - 異常値検出、SPC
運の影響で発生したデータの蜃気楼を追いかけることの無謀さを解決しようとする最も伝統的で代表的な方法は、予測モデルを使用することです。Prophet などの予測モデルを使用して、時系列上の予測範囲から一定レベル以上外れた場合を異常値(Anomaly)や外れ値(Outlier)とみなすことです。
異常値検出、そうじゃない
異常値検出アルゴリズムを注目すべき経営指標の変化とその原因を見つけるために活用する場合、(私の経験によると)2つの問題があります。
- ビジネス指標の場合、月や週単位で集計される指標の特性上、a.十分なデータポイントがない(月集計指標の場合、過去5年のデータを集めても60件に過ぎない)こと、b.収集されたデータでは、未知の外部イベントの影響のために安定した予測モデルを作ることが難しい。
- 安定した予測モデルを作ることができる場合であっても、売上指標が予測範囲から外れた(anomaly/outlier)という事実を知らせるだけで、指標変化の主な要因(特定の商品販売が特定の地域で大きく減少するなど)を知らせることはできない。
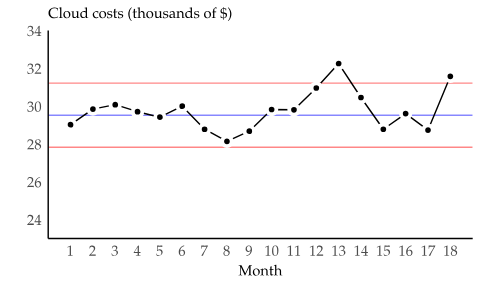
xMRチャートの再照明
ビジネス指標からシグナル(Signal)を見つけることに、最近、xMRチャートが新たに注目されています。xMRチャートは、従来、品質管理やプロセスモニタリングにおいて、異常値や異常なパターンを特定するために使用されてきたツールです。簡単に説明すると、指標の連続した観測値の差を計算(差分: differencing)して変動性を視覚化(xMRチャート)した後、変化量(差分値)の分布を考慮して上下限度を設定し、その範囲を超えた場合、外れ値(outlier)と判断する方式です。
ビジネス指標にxMRを適用する際に考慮しなければならない最大の現実的な問題は、差分値の上下限度を設定することです。 特に、急速に成長していたり、変動幅が大きい指標の場合、xMRは適切ではないと思います。 xMRについて詳しく知りたい方にはこちらの記事をおすすめします。
無数の可能性、境界線が必要です
「Facebook広告で流入した訪問者とウェビナーで流入した訪問者のコンバージョン率にどのような違いがありますか?」という質問とは異なり、「前四半期の売上はなぜ減少したのですか?」という質問に答えるためには、無数の可能性が存在します。
与えられた指標(売上)を収集している次元(カテゴリ型変数)に分割すると、無数の可能性が広がります。ランダムに組み合わされた次元の条件(地域x商品カテゴリー、流通チャネルx曜日...)が作り出す意味が全て対等であるとは言えません。意味付けを行うためには無数の可能性に境界が必要です。
ウンベルト・エコが「解釈の限界」で指摘したように、「できること」と「できないこと」の間に境界がなければ、テキスト(データ)は意味のある世界ではないからです。現実の世界の道やデータの世界の道、無数の可能性の中に境界を作ることが重要です。
sidney yang
シグナル発見(知識生産)における仮説の重要性について
データをあちこち探索していくと、多くの可能性(変数の組み合わせ)が広がり、必然的に興味深い発見をすることになります。しかし、データ分析がより実用的なものになるためには、仮説・理論のないデータ中心分析(Brute-force Data-centric Analysis)ではなく、仮説中心(Hypothesis-First)分析が必要だと思います。
仮説中心分析 (Hypothesis-First Analysis)
(データチーム/実務者が)データをあちこち分解(drill-down)すると出てくる無数の統計的に有意な違いがビジネスの文脈でも意味を持つためには、分析の条件が(ビジネス部門/意思決定者の)普段の疑問(仮説)と通じていなければなりません。
Growthチーム、営業などのビジネス部門や意思決定者は、すでに顧客に対する確固たる定性的・定量的な理解を持っていることが多いです。顧客と直接話をしたり、SNSをモニタリングしながら、顧客の行動データや売上データを観察しながら、顧客に対する直観を発展させていきます。
sidney yang
「データ分析レポートの2つの書き方」というブログで、行動可能なインサイト(Actional Insight)ではなく、知識の生産が必要だと話しました。 主な内容を要約すると、
データが今日の疑問を解決することを超えるためには、乾燥した事実の提供ではなく、意思決定者のmental modelを変えることに貢献する必要があります。意思決定者の経験や直感と争うことは避け、彼らの経験と直感を精巧に最新の情報に更新できる情報を提供する必要があります。「特定」の状況で「特定」のパターンが発見されたから「特定」の行動をとったほうがよいという主張は、System 1 (経験と直観)を変えられません。なぜなら、その発見が新しい知識や理論ではなく、単なる偶然と見なすことになるからです。理論や知識は、人々に世界を違った見方を要求する力があります。理論は私たちを止めさせ、反芻させるが、断片的な事実やインサイトに私たち(System 1)は微動だにしません。データから「行動可能なインサイト」の代わりに、世界とビジネスに関する知識と理論を生みだす必要があります。
まとめ - 日常としてのデータ分析
仮説を立て、関連する実験を設計してデータを収集し、限られたデータで仮説を危うく検証するのではなく、観察データセットに含まれる指標の変化を説明できる無数の可能性をデータツールが提供する必要があります。実務者が他人の助けを借りずに自分の仮説を主体的に検証できるようになると、実務者の日常の中にデータが自然に浸透し、データに含まれる道が世の中の道とつながる実用的で費用対効果の高いデータ活用が可能になると思います。
少し長いので、その要旨をまとめてみます。
- データ中心(Data-Driven)の組織になろうという話は、その目的や方法について具体的な話をしていないので、空虚です。
- Cloudに Modern Data Stackを構築すべきだとか、Analytics Engineerの職務を新設すべきだとか、GenAI技術でデータ分析の民主化を実現すべきだとか、これまで流行っていた、または流行っている議論は、「Data-Driven」の具体的な目的や指向点について教えてくれません。
- (データそのものがビジネスのコア価値を生み出さないほとんどの組織にとって) 費用対効果の高いデータから知識を追求して生みだすことがデータへの投資の目標であるべきです。
- そのためには、主要な経営指標の変化から、ビジネスを動かす制御可能な因果的要因(Signal)と制御できない、または偶然の影響(Noise)を、実務者が簡単かつ迅速に区別することが必要です。
- それが可能になると、実務者が自分の業務について抱いていた疑問(仮説)を素早くデータで確認し、戦略的、運営的な意思決定に主体的、能動的に活用できるようになります。データが個人と組織により正確で洗練された世界を示し、新しい可能性を広げる手段になることができます。
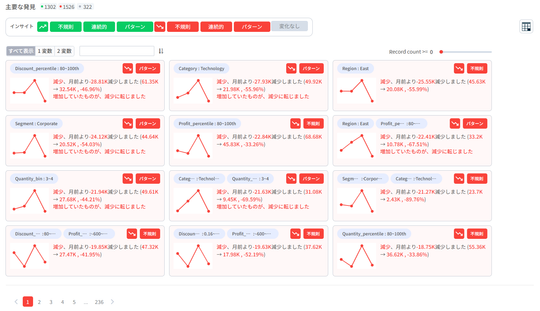
HEARTCOUNTでデータからシグナルを発見する
HEARTCOUNTのダイアログ(Dialogue)の新機能であるシグナル(Signal)のデモンストレーションを通じて、データツールが日常的な質問にデータで答える作業にどのように貢献できるかを一緒に見てみましょう。
HEARTCOUNT Signal
HEARTCOUNT Signalは、注目すべき指標の変化と指標の変化の要因を、寄与度、変化率など様々な観点から通知するダイアログ(Dialogue)の新機能です。
- 運(Noise)によって指標が変動した場合と、注目すべき環境変化によって指標が変化した場合(Signal)を区別して提示します。
- すべての変数の組み合わせから指標の変化を計算し、全体の指標レベルで変化がない場合でも、経営環境の変化を先制的に把握して対処することができます。
- 連続増加(減少)、急変動(outlier)、トレンド転換(trends shift)などを簡単な操作で検出することができます。
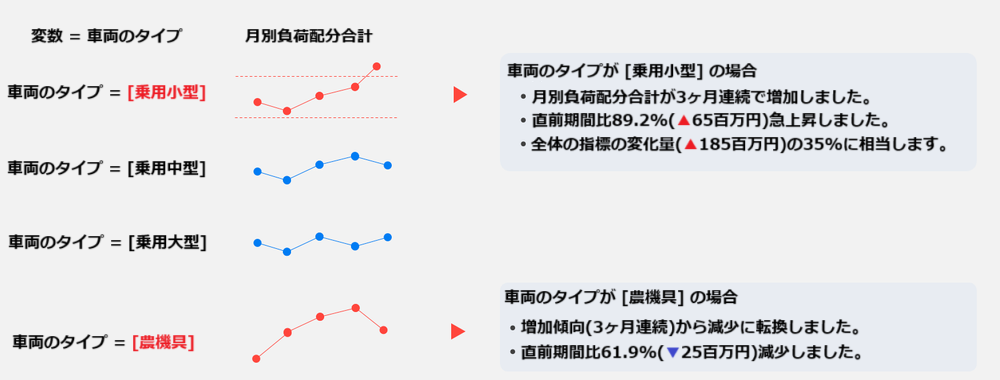
指標の変化はチャンスかもしれない
一貫した品質を維持することが重要な製造業では、指標の例外的な変動は望ましくない場合が多いです。しかし、他の産業における指標の変化は、むしろビジネスチャンスとして祝福につながる可能性があります。特定の条件下で指標が着実に増加(減少)したり、トレンド転換があった場合、その要因を除去したり、強化して指標改善に活用することができます。
HEARTCOUNTのシグナル(Signal)で指標の変化がもたらす指標改善のチャンスをお見逃しなく。
残された話
次の機会には、以下のテーマについてもう少し話を発展させていきたいと思います。
- W. Edwards Demingの生涯、彼の理論と功績
- (観察)データから知識を生みだす場合におけるデータツールの役割
- データから知識を生みだす場合における GenAIの役割
一緒に読むと良い記事
sidney yang
![[HEARTCOUNT実習例] HR dataset - I(人事分析)](/ja/content/images/size/w360/2024/10/------_--------_-----_--------_-1-.png)