
AI에게 “이번 달 실적률이 왜 떨어졌나요?”라고 묻는 일은 이제 그리 어렵지 않습니다. 질문을 입력하면 SQL이 만들어지고, 숫자가 나오고, 그래프가 그려집니다. 흩어져 있던 데이터가 잠시 한곳에 모이고, 우리는 무언가를 본 것 같은 느낌을 받습니다.
하지만 보았다는 느낌과 이해했다는 확신은 다릅니다.
그 숫자를 임원 보고 자료에 그대로 올릴 수 있느냐고 물으면, 많은 사람은 잠시 멈춥니다. 이 숫자는 정말 우리가 알고 싶었던 그 숫자인가. 이 계산은 우리 회사가 오래 써 온 기준을 따르고 있는가. 내가 볼 수 있는 데이터만 본 것인가. 나중에 누군가 근거를 물으면 설명할 수 있는가.
이 망설임의 이름은 신뢰입니다.
AI가 답을 내놓는 일과, 그 답을 믿고 결정을 내리는 일은 같지 않습니다. “맞아 보이는 답”과 “책임질 수 있는 답” 사이에는 생각보다 긴 거리가 있습니다.
차이는 모델이 아니라 맥락에서 생긴다
앞으로 기업이 쓰는 AI 모델의 차이는 점점 줄어들 것입니다. 어떤 회사는 OpenAI를 쓰고, 어떤 회사는 Anthropic이나 Google 모델을 쓰고, 또 어떤 회사는 내부망에 올린 sLLM을 쓸 수 있습니다. 모델은 계속 좋아지고, 기업은 필요에 따라 여러 모델을 바꿔 쓰게 될 것입니다.
그렇다면 차이는 어디에서 생길까요. 모델 자체가 아닙니다. AI가 우리 회사의 데이터와 지표, 업무 방식, 권한 체계, 의사결정 기준을 얼마나 정확히 이해하느냐에서 생깁니다. 기업 AI의 승부처는 모델이 아니라 맥락(Context)입니다.
기업 데이터에는 숫자만 있는 것이 아닙니다. 숫자 뒤에는 늘 기준이 있고, 규칙이 있고, 예외가 있습니다. revenue라는 컬럼이 있다고 해서 그것이 곧 “우리 회사가 말하는 매출”은 아닙니다. 취소 건을 포함하는지, 세금을 제외하는지, 청구일 기준인지 수금일 기준인지는 컬럼 이름만으로 알 수 없습니다.
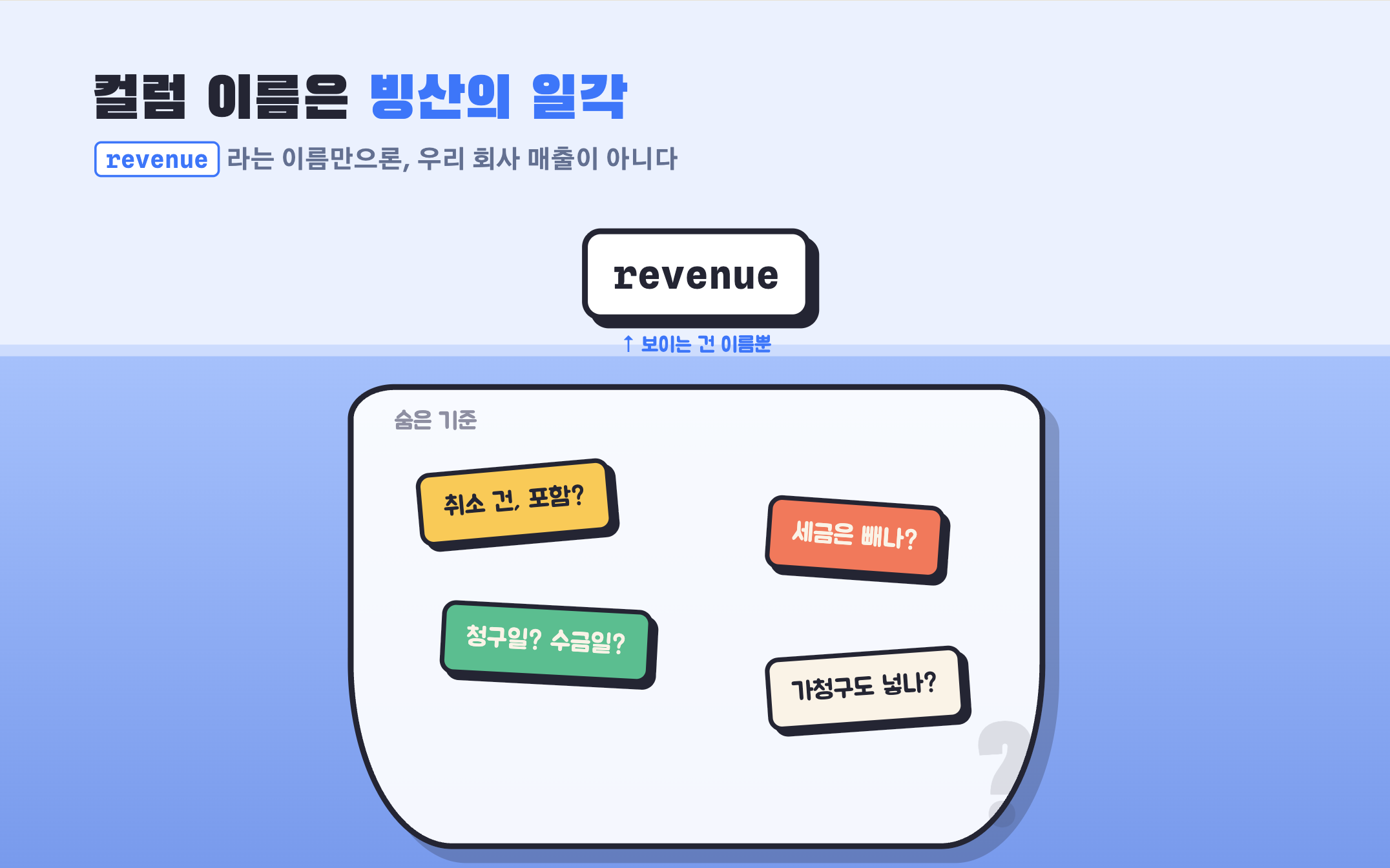
그 의미는 대개 다른 곳에 있습니다. 누군가의 머릿속에, 오래된 보고서에, 사내 위키 어딘가에, 퇴사한 담당자가 남기고 간 SQL에 있습니다.
AI가 기업 데이터를 제대로 다루려면, 바로 이 숨은 기준을 이해해야 합니다.
기업이 원하는 것은 조회가 아니라 판단의 근거다
Text(NL)-to-SQL은 자연어 질문을 SQL로 바꾸는 기술입니다. 빠르고 직관적이며, 데모에서는 특히 인상적입니다.
하지만 기업이 실제로 원하는 것은 단순 조회가 아닙니다. “이번 달 매출은 얼마인가?”도 물론 중요합니다. 다만 의사결정의 자리에서는 곧바로 다른 질문이 따라붙습니다.
이 매출은 확정 기준인가. 취소나 보류 건은 빠졌는가. 누구의 권한 범위에서 본 숫자인가. 기존 보고서의 기준과 맞는가. 다음 달에 같은 질문을 다시 해도 같은 기준의 답이 나오는가.
기업이 AI 데이터 분석에 기대하는 것은 숫자를 빨리 뽑는 일이 아닙니다. 그 숫자를 회사의 기준에 맞게 해석하고, 결정의 근거로 삼을 수 있게 만드는 일입니다.
문제는 회사마다 지표의 정의가 다르다는 데 있습니다. 마케팅팀의 전환율과 데이터팀의 전환율이 다릅니다. 어떤 리포트는 활성 고객을 최근 30일 기준으로 세고, 다른 리포트는 90일 기준으로 셉니다. 매출을 확정 기준으로만 보는 부서가 있고, 가청구까지 포함하는 부서가 있습니다. 예산 대비 실적도 보류·취소 건을 포함하느냐에 따라 숫자가 달라집니다.

이런 상태에서는 AI가 SQL을 아무리 잘 만들어도 믿고 쓸 답이 나오기 어렵습니다. 관건은 질문을 SQL로 바꾸는 능력이 아니라, 그 SQL이 회사의 기준과 권한과 업무 규칙을 따르고 있느냐입니다.
데이터가 많아도 KPI가 개선되지 않는 이유
기업에는 이미 데이터도, 대시보드도 충분히 많습니다. 그런데도 데이터가 곧바로 KPI 개선으로 이어지지는 않습니다. 이유는 대체로 세 가지입니다.
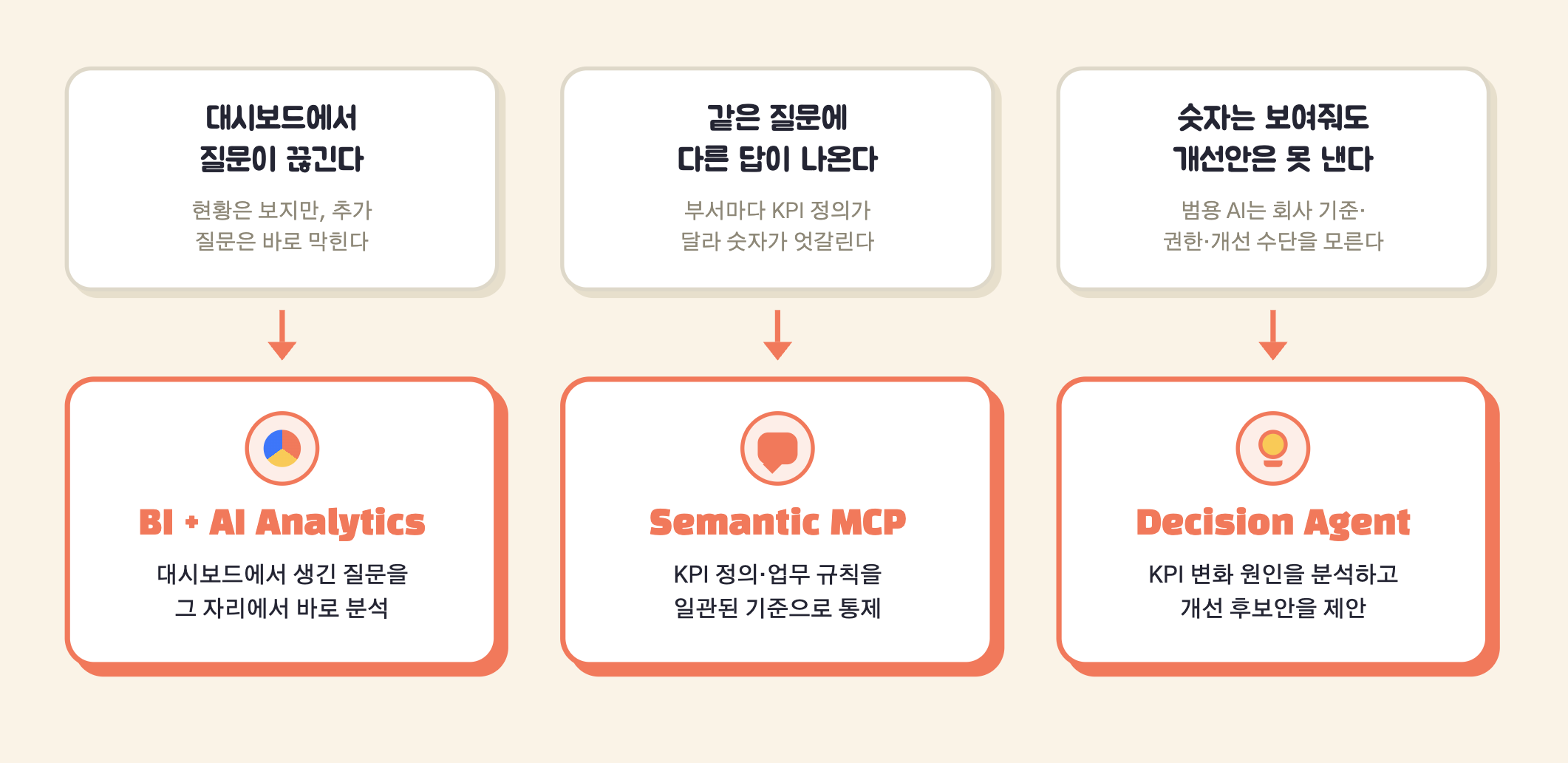
먼저, 대시보드에서 질문이 끊깁니다. 대시보드는 KPI의 현황과 추이를 보여 줍니다. 그러나 “왜 변했는가”로 한 걸음 더 들어가려면 다시 데이터를 내려받고, 별도 분석을 요청하고, 누군가 해석해 주어야 합니다.
다음으로, 분석이 행동으로 이어지지 않습니다. 많은 리포트는 무슨 일이 일어났는지는 보여 주지만, 무엇이 영향을 주었는지, 어디를 먼저 봐야 하는지, 어떤 조치를 검토해야 하는지까지는 제시하지 못합니다.
마지막으로, 데이터팀과 현업팀이 다른 언어로 말합니다. 한쪽은 테이블과 컬럼과 집계 기준으로 말하고, 다른 쪽은 고객과 상품과 손해율과 상담 품질로 말합니다. 이 간극이 좁혀지지 않으면 분석은 분석대로 남고, 실행은 멀어집니다.
대시보드의 질문을 KPI 개선 의사결정으로 연결하기
기업은 결국 KPI를 통해 성과를 확인합니다. 그러나 KPI를 들여다보는 것만으로 성과가 나아지지는 않습니다. 중요한 것은 대시보드에서 발견한 변화를 분석으로 이어가고, 그 분석을 다시 개선 의사결정으로 연결하는 일입니다.
HEARTCOUNT는 이 과정을 두 가지 방식으로 지원합니다. 고객의 목적과 준비 수준에 따라 BI + AI Analytics로 빠르게 시작할 수도 있고, Semantic MCP + Decision Agent로 KPI 개선 의사결정까지 확장할 수도 있습니다.
첫째는 BI + AI Analytics입니다.
기업은 이미 BI와 대시보드로 KPI를 보고 있습니다. 따라서 AI 분석도 낯선 화면에서 새로 시작할 필요가 없습니다. 대시보드에서 생긴 질문이 자연스럽게 AI Analytics로 이어질 때, 실무자는 흐름을 끊지 않고 바로 분석을 이어갈 수 있습니다.
이번 달 매출이 왜 줄었는지, 제품군별로 이익이 크게 빠진 곳은 어디인지, 상담 불만이 특정 유형에서 늘었는지, 할인율과 이익이 같이 움직이는지. 이런 질문을 데이터팀에 다시 넘기거나 다른 도구로 옮기지 않고, 기존 BI 데이터셋을 바탕으로 바로 분석할 수 있다면 업무 흐름은 크게 달라집니다.
BI + AI Analytics는 기존 BI 자산을 활용해 AI 분석을 빠르게 시작하고 싶은 고객에게 적합합니다.
둘째는 Semantic MCP + Decision Agent입니다.
Semantic MCP는 AI와 기업 데이터 사이에서 지표의 의미, 권한, 실행 기준을 통제하는 계층입니다. AI가 데이터베이스에 직접 접근해 임의로 SQL을 만들게 두지 않고, 회사가 정의한 KPI, 계산 기준, 업무 규칙, 권한 기준, 기존 BI 맥락 안에서 분석하게 합니다.
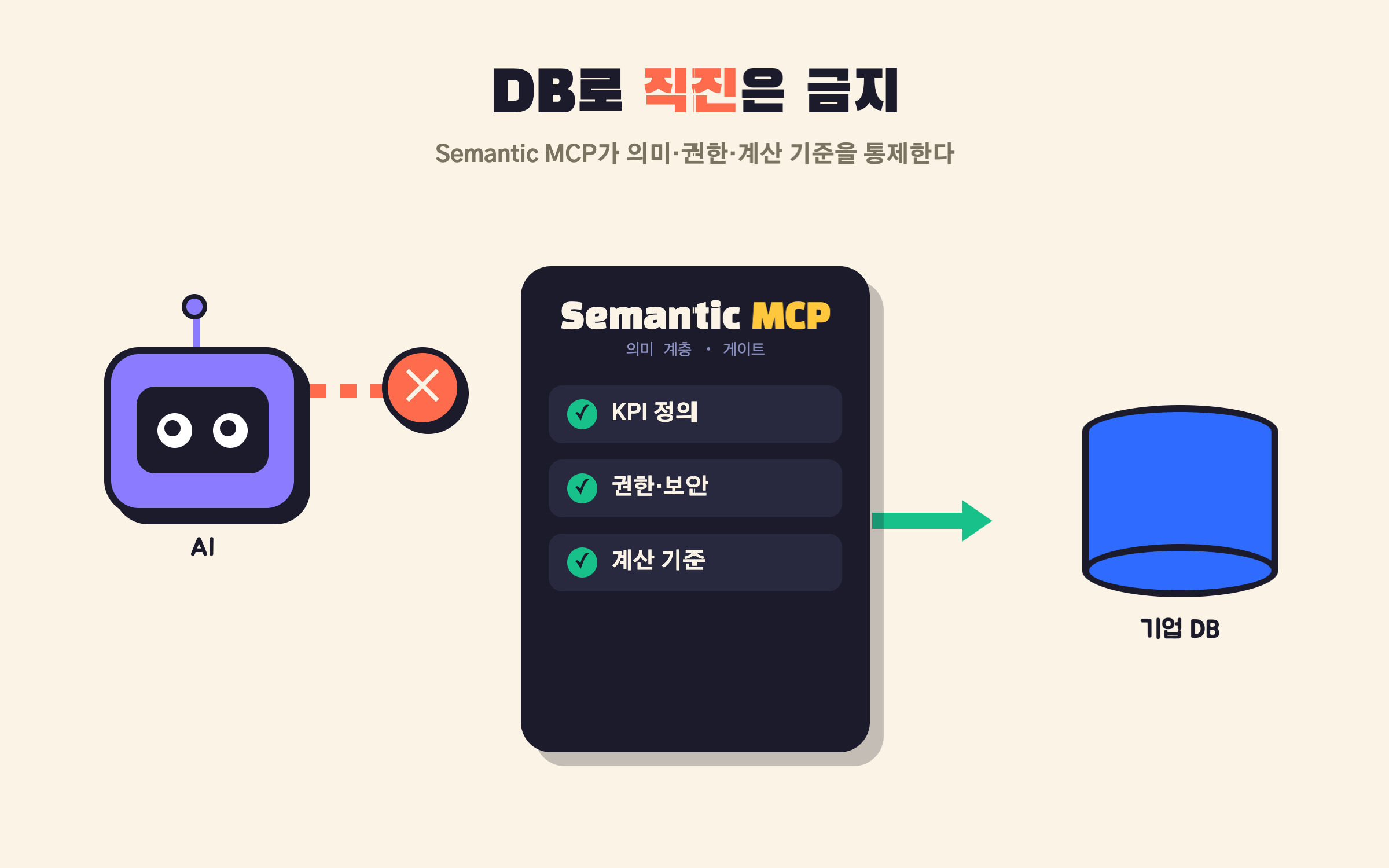
그 위에서 Decision Agent는 KPI 변화의 원인을 분석합니다. 어떤 원인 변수(Driver)가 영향을 주었는지, 어떤 개선 수단(Lever)을 검토할 수 있는지, 어떤 실행 후보(Action)를 고려할 만한지 함께 제안합니다.
이 방식은 대시보드의 질문을 분석하는 수준을 넘어, KPI 정의와 업무 규칙을 구조화하고 변화 원인 분석과 개선 후보안 제시까지 확장하려는 고객에게 적합합니다.
정리하면, HEARTCOUNT는 기업 데이터를 KPI 개선 의사결정으로 전환하기 위해 두 가지 출발점을 제공합니다.
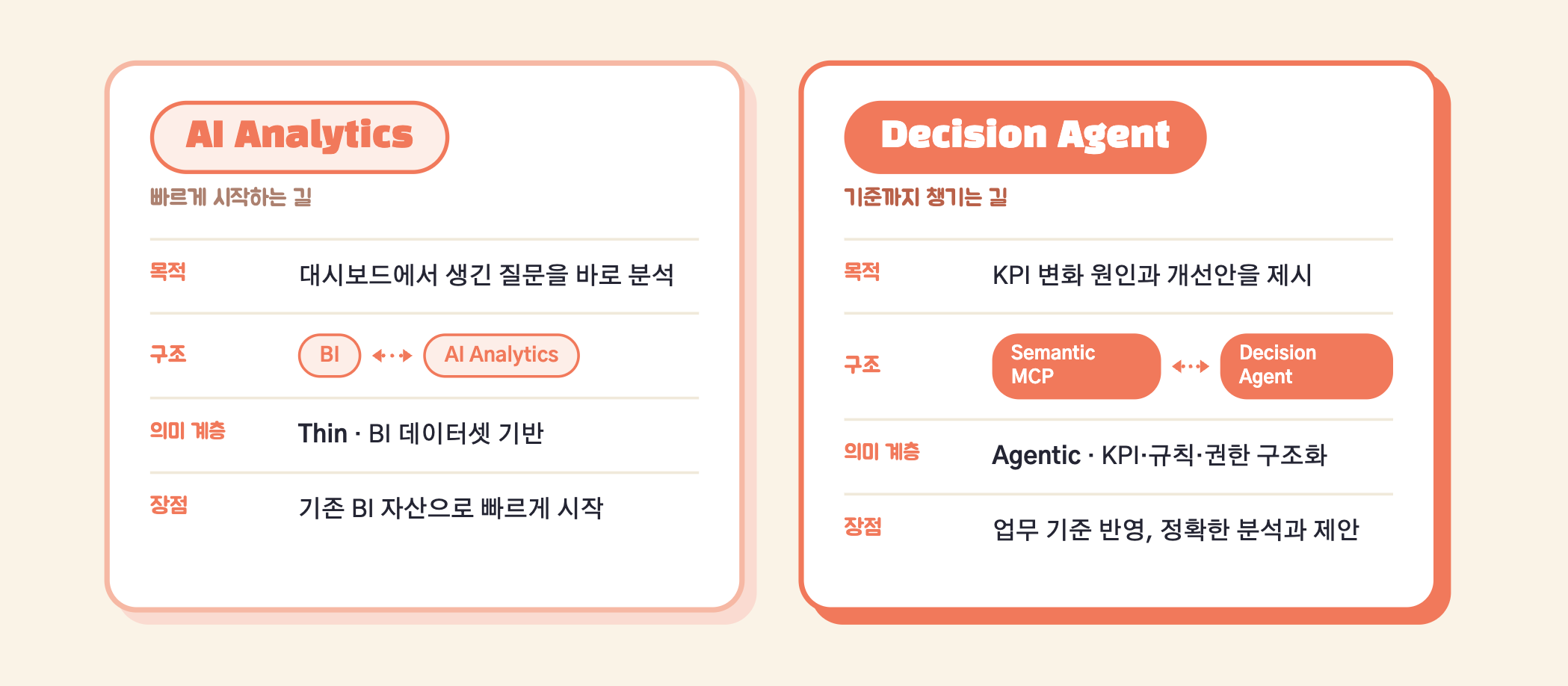
BI + AI Analytics는 기존 BI 데이터셋을 기반으로, 대시보드에서 생긴 질문을 바로 분석하게 합니다.
Semantic MCP + Decision Agent는 KPI 정의와 업무 규칙을 반영해 변화 원인을 분석하고, 개선 후보안을 제시합니다.
AI가 말한 숫자를 믿어도 되려면
기업 AI 분석에서 정작 중요한 질문은 “AI가 SQL을 만들 수 있는가”가 아닙니다. “그 SQL이 어떤 기준으로 만들어졌는가”입니다. Semantic MCP는 바로 그 기준을 관리합니다.
이를테면 보험사의 손해율은 loss_ratio라는 이름만으로는 충분하지 않습니다. 무엇을 뜻하는지, 어떤 식으로 계산하는지, 어떤 차원으로 나누어 볼 수 있는지, 누가 어디까지 볼 수 있는지가 함께 정의되어야 비로소 쓸 수 있습니다. 짧게 적으면 이런 모습입니다.

이렇게 정의되어 있으면, 누군가 “이번 달 손해율이 왜 올랐어?”라고 물어도 AI는 의미를 멋대로 추측하지 않습니다. 먼저 그 “손해율”이 회사 표준 지표인 loss_ratio임을 확인하고, 정해진 계산식과 분석 차원, 권한 범위 안에서 분석을 진행합니다. 그리고 어떤 기준과 데이터로 그 답에 이르렀는지를 되짚을 수 있게 남깁니다.
이것이 단순한 Text-to-SQL과의 차이입니다. Text-to-SQL은 질문을 SQL로 바꿉니다. Semantic MCP는 질문을 회사의 기준에 맞는 분석으로 바꿉니다.
Decision Agent는 어떤 기준으로 개선안을 제시하는가
Decision Agent는 경영 판단을 대신 내리는 시스템이 아닙니다. 중요한 결정과 최종 실행은 여전히 사람의 검토와 승인에 기반합니다.
Decision Agent의 역할은 사람이 판단하기 전에 봐야 할 근거와 개선 후보안을 빠르게 정리하는 것입니다. 기존 BI가 “지난달 매출이 목표 대비 8% 미달했다”처럼 무슨 일이 일어났는지를 보여준다면, Decision Agent는 한 걸음 더 나아가 왜 일어났는지와 무엇을 검토해야 하는지를 연결합니다.
여기서 중요한 점은 개선안이 단순한 AI의 추측이 아니라는 것입니다. Decision Agent는 KPI 개선 업무 규칙을 담은 경량 Ontology를 바탕으로 작동합니다. 이 Ontology에는 KPI가 어떤 원인 변수(Driver)와 연결되는지, 어떤 개선 수단(Lever)을 검토할 수 있는지, 어떤 조건에서 어떤 실행 후보(Action)를 제안할 수 있는지가 구조화되어 있습니다.

예를 들어 매출이 하락했다면 단순히 “프로모션을 강화하세요”라고 말하지 않습니다. 어느 상품군, 채널, 지역, 고객군에서 변화가 컸는지 먼저 분석하고, 그 결과를 업무 규칙과 연결해 검토 가능한 개선 후보안을 제시합니다.
즉 Decision Agent는 KPI 변화 감지 → Driver 분석 → Lever 탐색 → Action 후보 제시의 흐름으로 작동합니다. 다만 최종 판단과 실행은 사람이 맡습니다.
AI가 결정을 대신하는 것이 아니라, 사람이 더 나은 근거 위에서 결정할 수 있도록 업무 기준에 맞는 개선 후보안을 좁혀 주는 것. 그것이 Decision Agent의 역할입니다.
자연어로 묻는 것을 넘어서
기업 AI 데이터 분석의 다음 단계는 단순히 “자연어로 질문할 수 있다”가 아닙니다. 그것은 이미 상당 부분 가능해졌습니다.
진짜 과제는 AI가 데이터 뒤에 숨은 비즈니스 의미를 이해하게 하고, 사람이 더 나은 결정을 자신 있게 내리도록 돕는 일입니다. 그러려면 Text-to-SQL 기능만으로는 부족합니다. 회사 안에 흩어진 지식, 업무 방식, 권한 규칙을 AI가 활용할 수 있는 맥락으로 정리해야 합니다.
HEARTCOUNT는 기업 내부 데이터의 의미 계층을 정리하고, 그 위에 AI Analytics와 Decision Agent를 구현하는 방향으로 제품을 고도화하고 있습니다.
AI 데이터 분석을 실험 단계에서 의사결정 지원 단계로 옮기고 싶다면, 출발점은 거창한 AI 도입이 아닐 수 있습니다. 먼저 우리 회사의 핵심 KPI가 무엇인지, 어떤 기준으로 계산해야 하는지, 그 KPI를 움직이는 원인은 무엇인지, 그 답을 누가 어떤 권한으로 볼 수 있는지 정리하는 일에서 시작해야 합니다.
AI가 믿을 만해지는 순간은, AI가 더 많이 말할 때가 아닙니다.
AI가 어떤 기준으로 말하고 있는지를 우리가 설명할 수 있을 때입니다.
![[고객 사례] 수기 보고서에서 데이터 중심 경영으로, 도드람한돈의 BI 플랫폼 구축 전략](/ko/content/images/size/w360/2026/06/---------------------_---------------------------_-------------------------800_590.png)