![[인과추론 1] Potential Outcome Framework(잠재적 결과 프레임워크)](/ko/content/images/size/w2000/2024/01/----------------------5.png)
들어가며: Potential Outcomes Framework란
데이터 분석에 있어서 인과추론은 분석의 논리적 흐름에서 자연스럽게 따라오는 생각의 흐름에 대한 답이 되어 줍니다. 단순히 'What' 질문에 대해 SQL로 작성한 summary table 스러운 답변만으로는, 실제로 데이터를 만들어낸 Data Generating Process에 대해서 면밀히 파악할 수 없는 경우가 많죠. 그래서 수학/통계/경제학자들은 끊임없이 '경제적 효과'라는 것을 분명하게 하기 위해, 즉 'Why' 질문에 대한 답변을 할 수 있는 체계적인 수학적 방법론, 곧 인과추론의 방법론을 정립해 왔습니다.
Potential Outcomes Framework(잠재적 결과 프레임워크)는 그 방법론들 중 하나입니다. Potential Outcomes Framework의 가장 큰 장점(?)은 인과추론이라는 것이 어떠한 것인지에 대한 맥을 잡기에 가장 효과적이라는 것입니다. 복잡하게 얽히고 섥힌 데이터에서 어떻게 인과적 관계를 파악해내는지에 대한 직관적이고 이해하기 쉬운 방법론입니다.
Randomized Controlled Trial (RCT) - A/B Testing
Potential Outcomes 이야기를 하기 전에 먼저 Randomized Controlled Trial(RCT)에 대해 이야기를 해 볼까요? RCT는 인과성 파악에 있어서 언제나 가장 최우선되는 방법론입니다.
어떠한 정책/이벤트(예: 출산 장려 정책)의 인과성(효과, 예: 정책 시행 후 출산율에 미친 영향)를 측정하고 싶다고 하면, 해당 정책의 수혜자 vs 비수혜자를 놓고, 정책 시행 전후를 각각 비교해 보면 될 것입니다. 정책의 수혜를 받은 집단과 그렇지 않은 집단의 지표에 뚜렷한 차이가 존재한다면, 이는 정책에 분명한 효과가 있었다고 할 수 있겠죠?
하지만, 실제로는 그렇지 않은 경우가 대다수입니다. 왜냐하면 현실 세계에서는 거의 언제나 이러한 방식의 추론을 불가능하게 하는 요소들이 존재하기 때문입니다!
연구자의 편견이 본인도 모르는 사이 개입할 수 있고(무의식적으로 효과가 있을 법한 사람에게 정책 수혜 부여), 수혜자의 다른 요인 때문에 지표 변화가 발생할 가능성도 존재합니다(그냥 시간이 흘러서 변했다든지, 건강 관련 정책이었다면, 정책 때문이 아니라 그냥 운동을 열심히 해서 그렇게 된 거라든지).
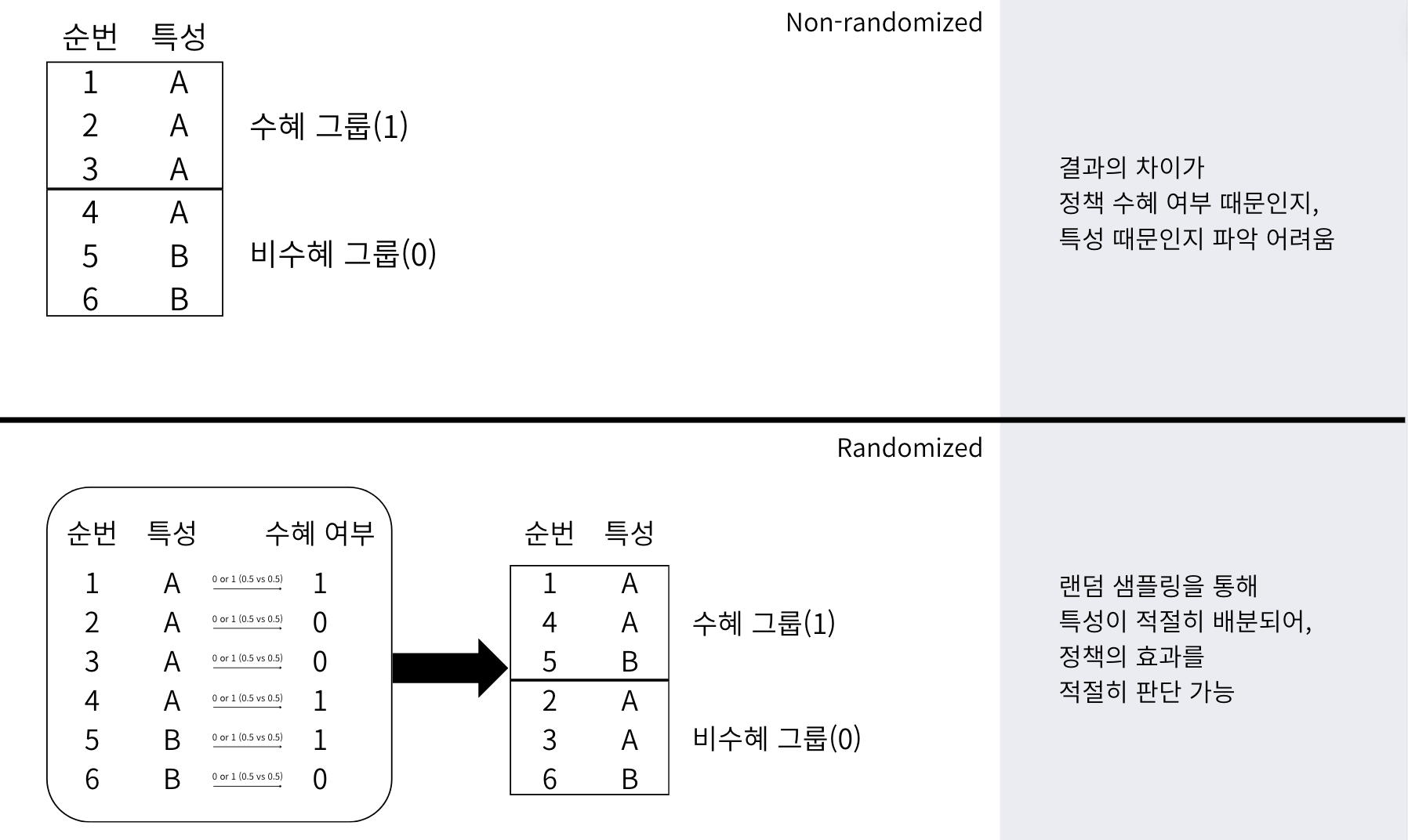
RCT(known as A/B testing)는 바로 그러한 요소들의 불확정성을 꽤나 상쇄시켜줄 수 있는 좋은 방법입니다. 왜 그런지에 대해 직관적으로 생각을 해 보면... 전체 집단을 수혜자 집단/비수혜자 집단으로 랜덤으로 나눈다고 해 보죠.
전체를 동일 확률 하에 랜덤으로 두 집단으로 나누는 것은 전체 집단에 속한 각 개인에게 0 또는 1의 꼬리표를 붙이는 작업으로도 이해할 수 있습니다. 이 때 각 개인이 0 또는 1에 속할 확률은 다른 개인이 0 또는 1에 속할 확률과 독립이기 때문에, 이 작업을 반복하면 인과성을 흐릴 수 있는 요소들이 상쇄되고 각 요소들이 최대한 고르게 분포될 것을 기대할 수 있습니다. 다만, 이는 충분한 샘플 사이즈가 보장되는 경우에만 잘 작동합니다(0 과 1을 돌아가며 뽑는 작업을 5번만 한다고 치면 1-1-1-1-1이 나올 수도 있기 때문...). 따라서 적절한 샘플 사이즈를 알기 위해 Power Analysis를 돌리게 됩니다.
인과추론의 근본적인 문제와 잠재 결과(Potential Outcome)
문제는 이러한 종류의 실험 설계는 항상 가능하지 않다는 것입니다. 많은 경우, 이미 발생한 과거의 데이터(Observational data)로부터 Data Generating Process를 추론하고, 인과관계를 파악해야 하는 경우가 발생합니다. 이 경우 꼭 짚고 넘어가야 하는 문제, 바로 인과추론의 근본적인 문제 Fundamental Problem of Causal Inference가 발생합니다.
정책 이야기로 돌아와서, 어떤 정책이 효과가 있었는지는 어떻게 알 수 있을까요? 예를 들어 요즘 사회적으로 핫한 이슈인 출산율을 증진하기 위한 정부의 새로운 정책이 있고, 정책이 실제로 출산율 증진에 효과가 있었는지를 알아보고 싶다고 합시다. 그 때 바로 다음의 값을 계산해 보면 됩니다.
(출산율 정책 효과) =
(출산율 정책의 혜택을 받은 후 정책 수혜 집단의 출산율) -
(출산율 정책의 혜택을 받기 전 정책 수혜 집단의 출산율)
만약 출산율 정책의 혜택을 받은 후 출산율이 5% 증가했다고 하면, 보통은 맘 편히 '출산율이 5% 증가하는 효과가 있었습니다'라고 이야기하기 쉽습니다. 여기서 문제가 발생합니다. '전후'라는 시간 개념이 도입되었기 때문입니다.
시간 개념의 도입으로 인해, 발생한 값이 정책의 효과 때문인지, 아니면 시간의 흐름 속에서 해당 정책 수혜 집단에 개입한 다른 요인 때문인지(갑자기 해당 집단에 속한 가정의 아버지들이 해가 바뀌면서 단체로 승진을 해서 월급이 올랐다든지) 불분명합니다. 그럼 시간 개념을 빼고 수식을 다시 정립해볼까요.
(출산율 정책 효과) =
(출산율 정책의 혜택을 받았을 때 정책 수혜 집단의 출산율) -
(출산율 정책의 혜택을 *만약* 받지 않았을 때 정책 수혜 집단의 출산율)
이번에는 '전후' 개념이 아닌, 동일한 시간대에 만약 해당 집단이 정책의 혜택을 받지 않았던 시나리오를 가정해 봅시다. 만약 이 상황에서 다시 이 값을 계산해 보아도 여전히 5%의 증가량을 보인다면, 이는 분명히 정책의 효과라고 할 수 있을 것입니다! 왜냐하면, 동일한 시간대를 가정함으로써, 해당 시간대 정책 수혜 여부를 제외한 다른 모든 요인을 통제하였기 때문이죠.
다시 말하면 이 시나리오에서는 해당 집단은 정책 수혜를 제외한 모든 조건이 동등함을 의미합니다!
그러나 실제로는 이 값은 현실에서는 구할 수 없습니다(출산율 정책의 혜택을 만약Potentially 받지 않았을 때 정책 수혜 집단의 출산율). 그래서 '만약 그랬다면 어땠을까'라는 의미에서 우리는 이 값을 잠재 결과(Potential outcome) 혹은 반사실 (Counterfactual)이라고 부릅니다.
Ceteris Paribus
그렇다면 우리는 정책의 인과 효과를 추정하는 것을 포기해야 할까요? 그렇지 않습니다. 바로 여기서 Ceteris Paribus가 등장한다. Ceteris Paribus는 "다른 모든 것들이 동등하다면"을 의미하는 라틴어다. 정책의 수혜를 받은 집단과 가장 유사한 집단을 찾아, 해당 집단의 출산율과 정책 수혜 집단의 출산율을 비교하는 것입니다.
(출산율 정책 효과) =
(출산율 정책의 혜택을 받았을 때 정책 수혜 집단의 출산율) -
(정책 비수혜 집단 중, 출산율 정책의 혜택을 받은 집단과 가장 유사한 집단의 출산율)
이 수식에서, (출산율 정책의 혜택을 만약 받지 않았을 때 정책 수혜 집단의 출산율)을 (정책 비수혜 집단 중, 출산율 정책의 혜택을 받은 집단과 가장 유사한 집단의 출산율)로 대체한 것을 볼 수 있습니다. 두 값은 동일한 값은 아닙니다. 그럼에도 불구하고, 만약 비수혜 집단 중 수혜 집단과 가장 유사한 집단을 찾아, 동일한 time period 하에 출산율을 비교해 보면, potential outcome을 추산할 수 있게 됩니다. 따라서 최대한 동등한 조건의 비수혜 집단을 찾는 것이 중요한 싸움이 되겠죠?
이해를 돕기 위해 unlikely한 예를 하나 더 들어 보겠습니다.
선인장 두 개를 키우게 되었다고 합시다. 두 선인장은 유전적인 성질이 모두 동일합니다. 키우는 위치도 동일하고, 일조량도 동일하고, 화분의 종류도 동일하고, 흙의 종류도 동일합니다. 두 선인장 A,B 중 A에만 물을 조금 더 주어, A와 B 중 무엇이 더 잘 자라는지 알아보려고 한다고 합시다.
그런데 실수로 B 선인장 화분을 쳐서 넘어트려 깨져버렸습니다! 급한 대로 다른 선인장을 가져와 동일한 화분에 동일한 흙을 담아 B와 동일한 양의 물을 주며 동일한 위치에 두었습니다(이를 B'라고 부르자).
그런데 B'의 유전적 성질은 A와 95%만 유사합니다. 아쉬운 대로 A와 B'를 비교해 보니, 물을 상대적으로 더 준 A가 더 잘 자랐다고 해 봅시다. 이 경우 5%의 차이로 인해 '물을 주는 것은 선인장을 더 잘 자라게 하는 효과가 있다'라는 절대적인 단언까지는 아니어도, 적어도 길가에서 아무런 풀잎이나 주어다가 B의 대체품으로 삼은 것보다는 '효과가 있는 것으로 보인다'라는 주장의 뒷받침 근거로 활용할 수 있게 됩니다.
결론 및 요약
위의 예시들에서의 수혜 집단을 Treatment group, 비수혜 집단을 Control group이라고 부른다. Potential Outcome Framework는 Counterfactual을 대체할 수 있는, Treatment group과 가장 유사한 Control group을 찾는 연구 디자인을 의미한다.
참고자료
- <Korea Summer Session on Causal Inference 2021> https://sites.google.com/view/causal-inference2021
- [Causality] Potential Outcome 이란? https://m.blog.naver.com/sw4r/221229953498
- Potential Outcome Framework https://yeong-jin-data-blog.tistory.com/entry/Potential-Outcome-Framework