1. 텍스트 분석(Text Analytics)에 관심이 있으며 이 분야의 기본 지식과 분석 기법을 이해하고 싶은 분
2. ChatGPT를 포함한 대규모 언어 모델(LLM)이 텍스트 분석의 자동화에 어떻게 기여할 수 있는지 알아보고자 하는 분
3. 기존의 텍스트 분석 방법과 AI 기반의 새로운 접근 방식의 차이점과 장단점을 이해하고자 하는 분들.
LLM의 등장: 시대의 변화
2023년은 기술계에 있어 획기적인 해였습니다.
모든 전문가들이 주목한 중심에는 OpenAI가 출시한 ChatGPT가 있었습니다. 이 AI 모델은 일상과 업무 방식에 지대한 영향을 미쳤습니다.
이 같은 변화의 흐름 속에서, Meta의 LLaMa 2는 7월 18일에, Google의 Gemini는 12월 6일에 각각 공개되었습니다.
이러한 혁신적인 거대 언어 모델(LLM)들은 단순한 텍스트 분석을 넘어, 데이터 처리와 해석 방법을 근본적으로 바꾸고 있습니다.
2024년에는 또 어떤 기술 혁신으로 우리를 놀라게 할지 상상조차 어렵습니다.
이러한 상황에서 취할 수 있는 가장 지혜로운 행동은 무엇일까요?
문득, 아이작 뉴턴의 말이 떠오릅니다.
“If I have seen further it is by standing on the shoulders of Giants.”
"내가 더 멀리 볼 수 있었다면, 그것은 거인들의 어깨 위에 올라섰기 때문이다.”
우리는 거인의 어깨에 올라서서 새로운 관점으로 세상을 바라볼 수 있습니다.
ChatGPT는 기존의 텍스트 분석 방법과 비교하여 어떤 새로운 기회를 제공할까요?
이번 블로그에서는 이 질문에 대한 답을 탐색해 보고자 합니다.
텍스트 분석이란
먼저, 텍스트 분석에 대해 알아봅시다.
아래 그림들을 보신 적 있으신가요?

여기에 나타난 것들은 텍스트 데이터를 분석하고 시각화하는데 사용 되는 전통적인 기법들입니다.
왼쪽에서부터 순서대로, 코드 다이어그램은 개체 간의 상호관계를 시각적으로 나타내는 방법, 워드 클라우드는 자주 등장하는 단어를 크기와 색깔로 구분하여 표현하는 방법, 동시 출현 네트워크는 함께 등장하는 단어 간의 관계를 네트워크 형태로 시각화하는 방법입니다.
다양한 텍스트 분석 기법
텍스트 분석에도 다양한 분야가 있습니다.
본 글에서는 텍스트 데이터를 주제별로 군집화하고 키워드를 추출하는 몇 가지 기법들에 주목해 보고자 합니다.
- Latent Dirichlet Allocation (LDA)
- LDA는 토픽 모델링 분야에서 가장 대중적인 알고리즘 중 하나로, 문서를 여러 주제의 조합으로 보고, 각 주제가 특정 단어들로 구성된 확률 분포로 표현될 수 있다고 가정합니다.
- LDA에서는 두 가지 Dirichlet 분포를 사용합니다. 각 문서에 대해, 어떤 주제들이 얼마나 중요한지를 나타내는 문서 내의 주제 분포와 각 주제에 대해, 그 주제를 구성하는 단어들이 얼마나 중요한지를 나타내는 주제 내의 단어 분포입니다. LDA를 사용하면 각 문서에 대한 주제 분포를 추정할 수 있으며, 이를 바탕으로 주제별 키워드를 추출할 수 있습니다.
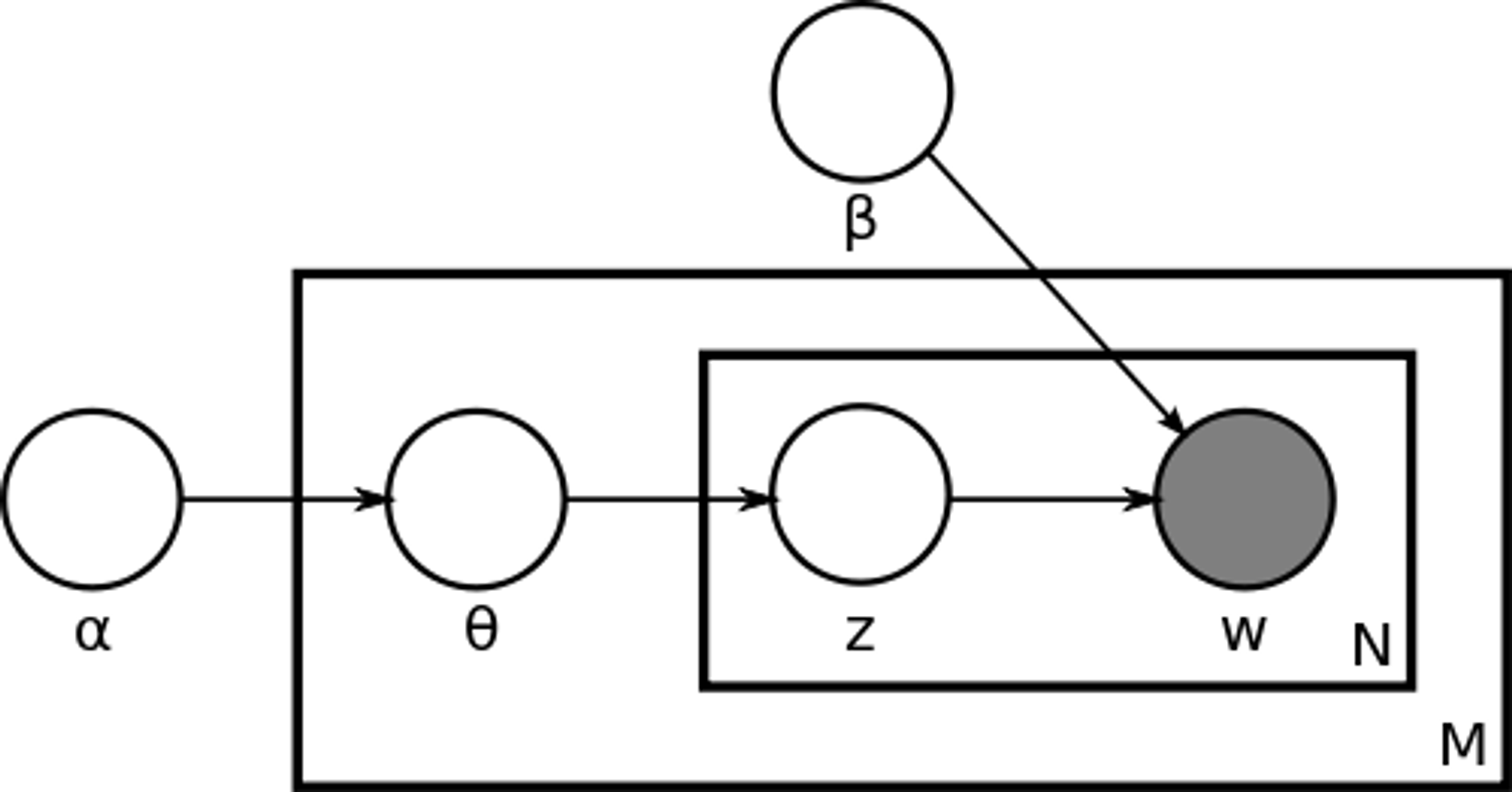
2. Non-negative Matrix Factorization (NMF)
- NMF는 고차원 데이터를 더 낮은 차원의 두 행렬로 분해하는 기법으로, 이 과정을 통해 문서 내 주제의 중요도를 결정하는 가중치를 도출할 수 있습니다.
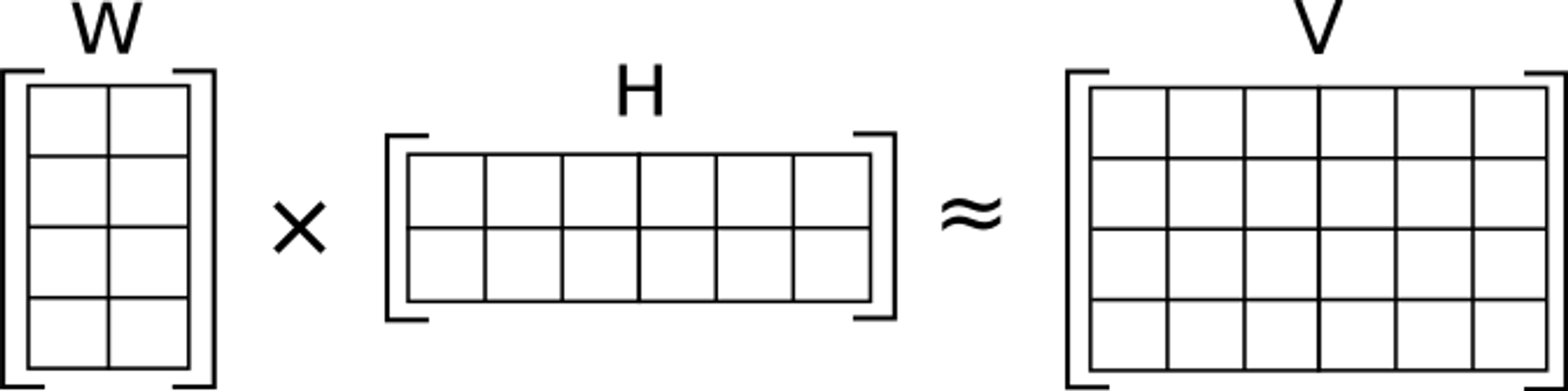
- 주어진 V(문서-단어 행렬)를 W(문서-특성 행렬)와 H(특성-단어 행렬)로 분해합니다. 이 과정에서 V ≈ WH라는 조건을 만족하도록 합니다. 분해되는 모든 요소는 음수가 아니어야 합니다(Non-negative). NMF를 통해 각 주제에 대해 식별한 대표적인 단어들을 키워드로 사용할 수 있습니다. Scikit-Learn 라이브러리의
NMF를 import 하여 구현할 수 있습니다.
3. K-means 클러스터링
- K-means는 텍스트 데이터를 벡터 공간 모델로 변환하고 이를 기반으로 데이터 포인트들을 K개의 클러스터로 분류하는 일반적인 클러스터링 방법입니다.
- 먼저, K개의 중심점(centroid)을 무작위로 설정하고, 각 데이터 포인트를 가장 가까운 중심점의 클러스터에 할당합니다. 그런 다음 중심점을 재계산하고 이 과정을 반복합니다. 목표는 클러스터 내의 분산을 최소화하는 것입니다. 이 클러스터링 결과를 바탕으로 각 클러스터에 속하는 문서들에서 주요 키워드를 추출할 수 있습니다. Scikit-Learn의
KMeans와TfidfVectorizer를 사용하여 구현할 수 있습니다.
4. Word Embedding 기반 접근
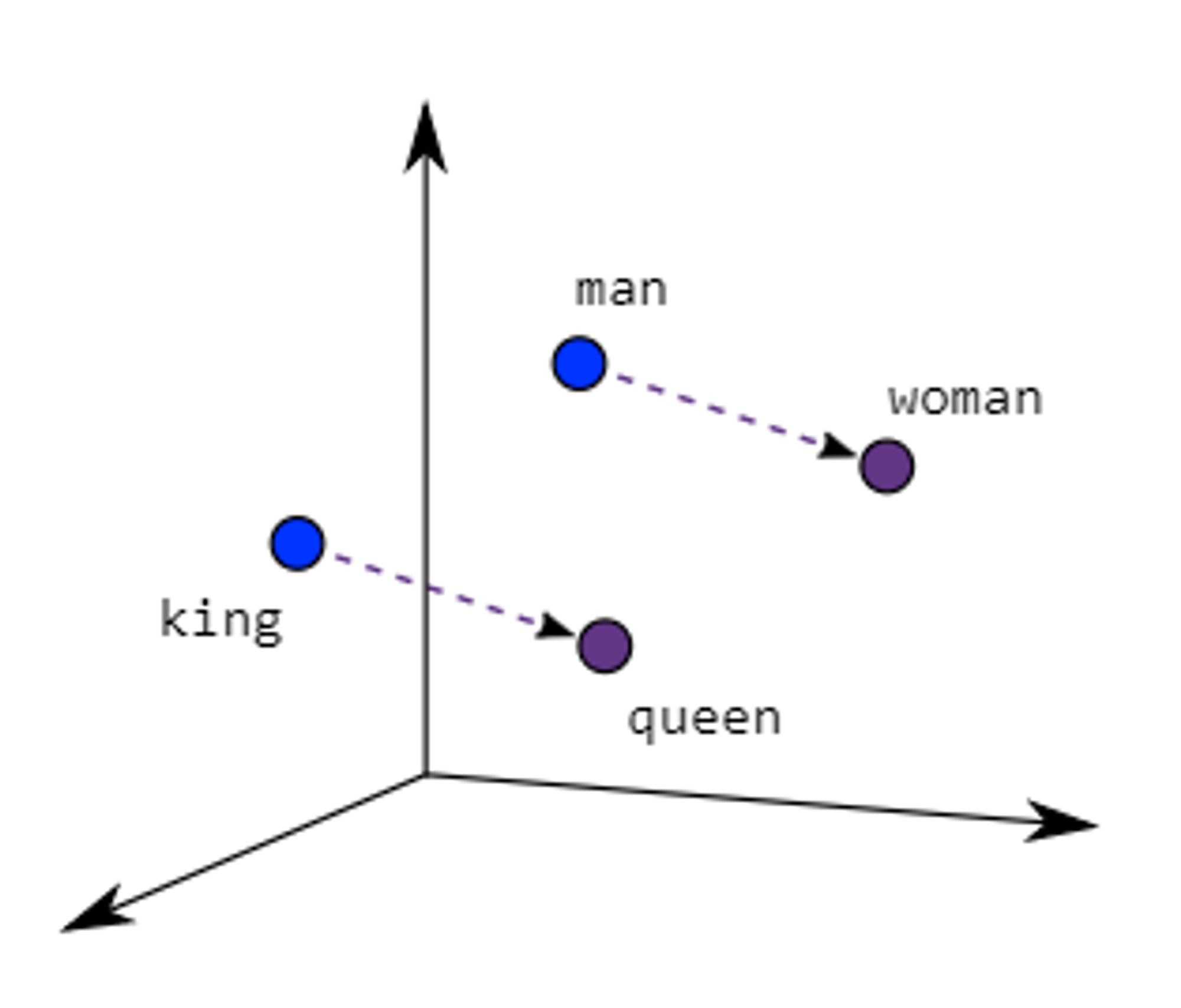
- Word2Vec 및 GloVe와 같은 워드 임베딩 모델은 단어들을 그들의 공동 출현 빈도와 문맥에 따라 밀집 벡터 형태로 표현합니다. 즉, 단어 간 유사도나 의미적 관계를 수치적으로 표현할 수 있습니다.
- 임베딩된 단어 벡터를 클러스터링 기법 등을 사용하여 유사한 단어를 군집화하고, 이를 바탕으로 주제별로 키워드를 추출할 수 있습니다. Word2Vec의 경우, 구글의
gensim라이브러리를 사용할 수 있습니다.
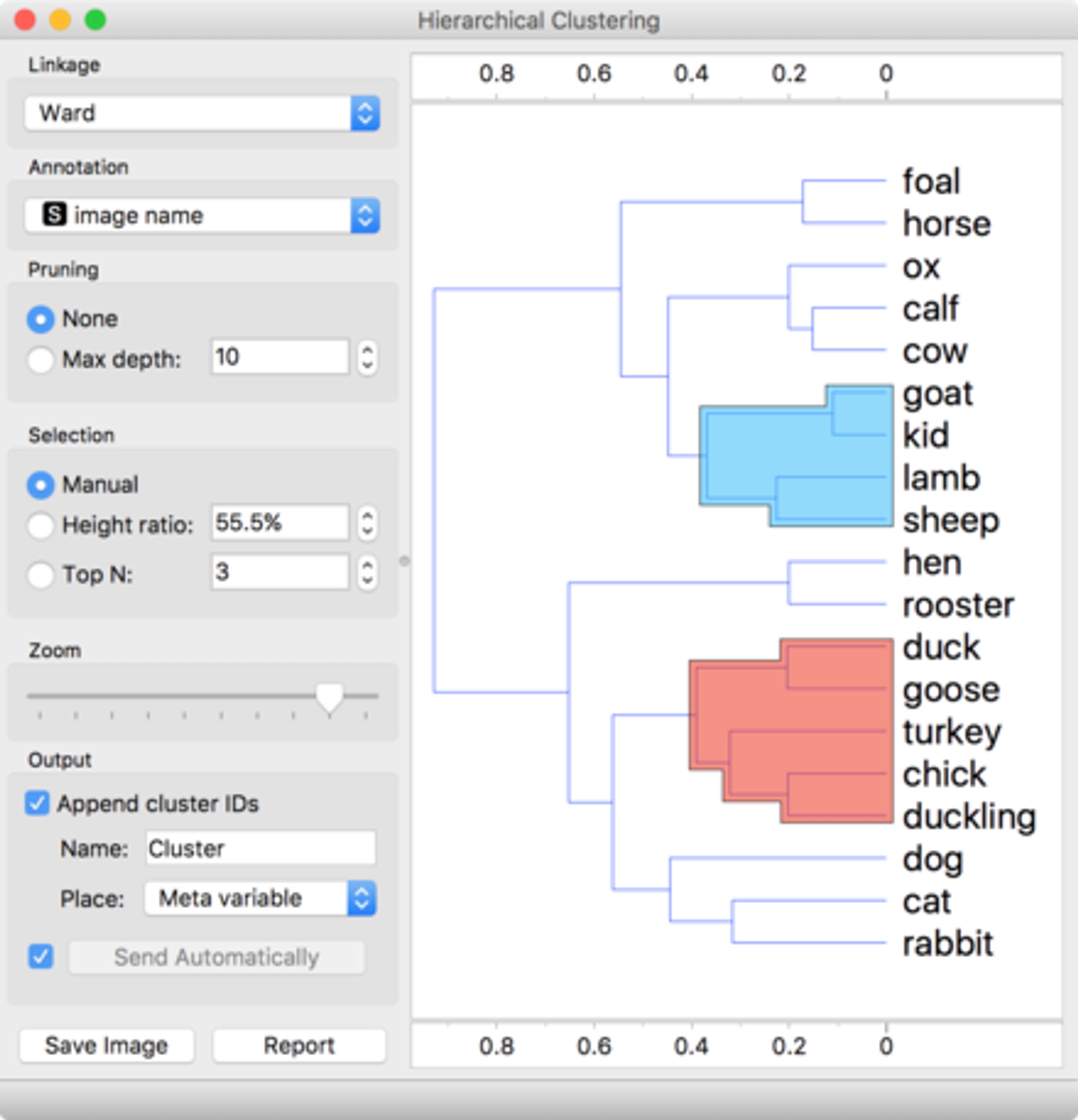
5. Hierarchical Clustering
- 계층적 클러스터링 방법은 데이터 포인트를 트리 형태의 구조로 묶어서 그룹화하는 과정입니다. 이 알고리즘은 각 데이터 포인트를 하나의 클러스터로 시작하고, 가장 유사한 클러스터들을 점차적으로 병합해 나갑니다. 또한, 클러스터 수를 미리 지정하지 않아도 됩니다.
- 계층적 클러스터링을 통해 텍스트 데이터를 다양한 수준에서 그룹화하고, 각 그룹의 대표적인 키워드를 추출할 수 있습니다. Scikit-Learn의
AgglomerativeClustering을 사용할 수 있습니다.
텍스트 데이터의 주제별 구조를 파악하고 각 주제에 대한 핵심 키워드를 식별하는 데 유용한 기법들을 소개하였습니다.
실습을 위한 준비
먼저, 분석을 위해 Kaggle에서 하나의 데이터셋을 선택해 다운로드해보겠습니다.
'News Category Dataset'은 Kaggle에서 제공되는 2012년부터 2022년까지의 Huffington Post 뉴스 기사 약 20만 개를 포함하고 있으며, 텍스트 분류와 클러스터링 연습에 적합합니다.


전통적인 텍스트 분석 실습
이어서, 텍스트 기법의 전통적인 방법인 Word Embedding 수행 후, K-means 클러스터링을 적용하는 과정과 그 결과를 살펴보겠습니다.
- output 파일 (전체)
- 데이터 준비: 분석을 위해 JSON 형식의 텍스트 데이터 파일을 불러옵니다.
- 코드
import pandas as pd
import json
# JSON 파일에서 데이터 로드
data = []
with open('./News_Category_Dataset_v3.json', 'r') as file:
for line in file:
data.append(json.loads(line))
# 데이터프레임으로 변환
df = pd.DataFrame(data)
2. 텍스트 전처리: 텍스트를 정제하고 표준화하는 과정을 거치며, 이에는 대소문자 일치, 특수 문자 및 불용어 제거, 그리고 토큰화 등이 포함됩니다.
- 코드
import pandas as pd
import gensim
from gensim.parsing.preprocessing import preprocess_string, strip_tags, strip_punctuation, strip_multiple_whitespaces, strip_numeric, remove_stopwords, strip_short
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
#'headline'과 'short_description'을 합친 새로운 'text' 컬럼 생성
df['text'] = df['headline'] + ' ' + df['short_description']
CUSTOM_FILTERS = [lambda x: x.lower(), strip_tags, strip_punctuation, strip_multiple_whitespaces, strip_numeric, remove_stopwords, strip_short]
def preprocess_text(text):
return preprocess_string(text, CUSTOM_FILTERS)
# 'text' 컬럼 전처리 및 토큰화
df['processed_text'] = df['text'].apply(lambda x: preprocess_text(x))
3. Word2Vec 모델 학습: Word2Vec 모델을 이용하여 텍스트 데이터 속의 단어들을 고정된 크기의 벡터로 변환하는 작업을 수행합니다.
- 코드
from gensim.models import Word2Vec
# Word2Vec 모델 학습
model = Word2Vec(sentences=df['processed_text'], vector_size=100, window=5, min_count=1, workers=4)
4. 문서 벡터화: 문서 또는 문장 단위의 벡터를 생성하기 위해, 단어 벡터들의 평균을 취하는 방식을 적용합니다.
- 코드
import numpy as np
# 단어 벡터의 평균을 이용해 문서 벡터를 생성하는 함수
def document_vector(word2vec_model, doc):
# 사전에 없는 단어 제거
doc = [word for word in doc if word in word2vec_model.wv]
if len(doc) == 0:
return np.zeros(word2vec_model.vector_size)
return np.mean(word2vec_model.wv[doc], axis=0)
# 각 문서에 대해 함수 적용
df['doc_vector'] = df['processed_text'].apply(lambda x: document_vector(model, x))
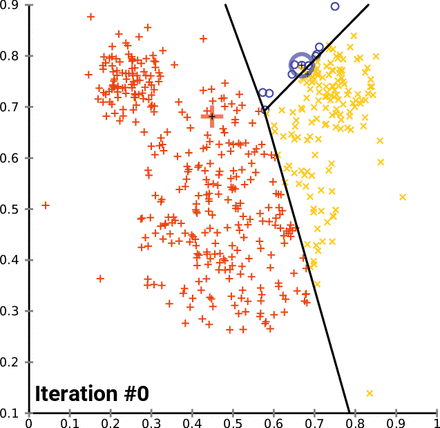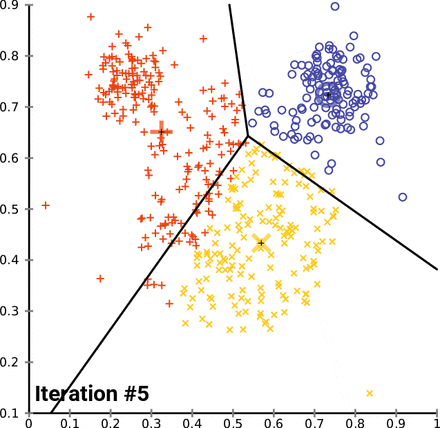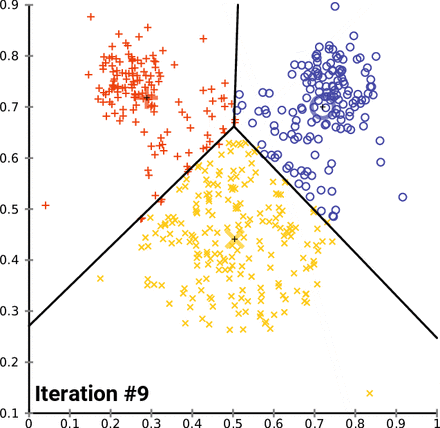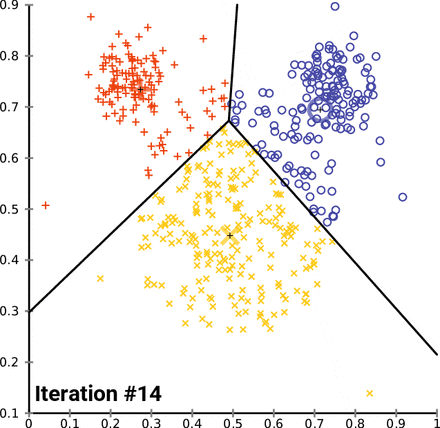
5. K-means 클러스터링: 데이터를 군집화할 클러스터의 수 k를 결정합니다 (본 예시에서는 6개의 클러스터를 선택하였습니다). 이후 벡터화된 데이터에 K-means 알고리즘을 적용하여 데이터 포인트들을 k개의 클러스터로 나눕니다.
- 코드
from sklearn.cluster import KMeans
# 클러스터 개수 지정 - 비교할 수 있도록 6개로 진행
n_clusters = 6
# K-means 클러스터링
kmeans = KMeans(n_clusters=n_clusters, random_state=0)
kmeans.fit(X)
# 데이터프레임 'cluster'열에 행별로 label 저장
df['cluster'] = kmeans.labels_
6. 결과 해석: 클러스터링의 결과를 엑셀 파일로 저장하고, 각 클러스터별로 중요한 단어나 표현들을 키워드로 선정합니다.
- 코드
# 클러스터 데이터를 저장하기 위한 리스트 초기화
clustered_data = []
# 각 클러스터 순회
for i in range(6):
cluster = df[df['cluster'] == i]
cluster_texts = cluster['text'].tolist() # Convert text column to list
cluster_headlines = cluster['headline'].tolist() # Convert headline column to list
# 클러스터 데이터를 리스트에 추가
for text, headline in zip(cluster_texts, cluster_headlines):
clustered_data.append({'Cluster': i, 'Headline': headline, 'Text': text})
# 리스트에서 DataFrame 생성
clusters_df = pd.DataFrame(clustered_data)
클러스터 = 0: Travel 분야로 추정
클러스터 = 1: Style & Beauty 분야로 추정
클러스터 = 2: Economics 분야로 추정
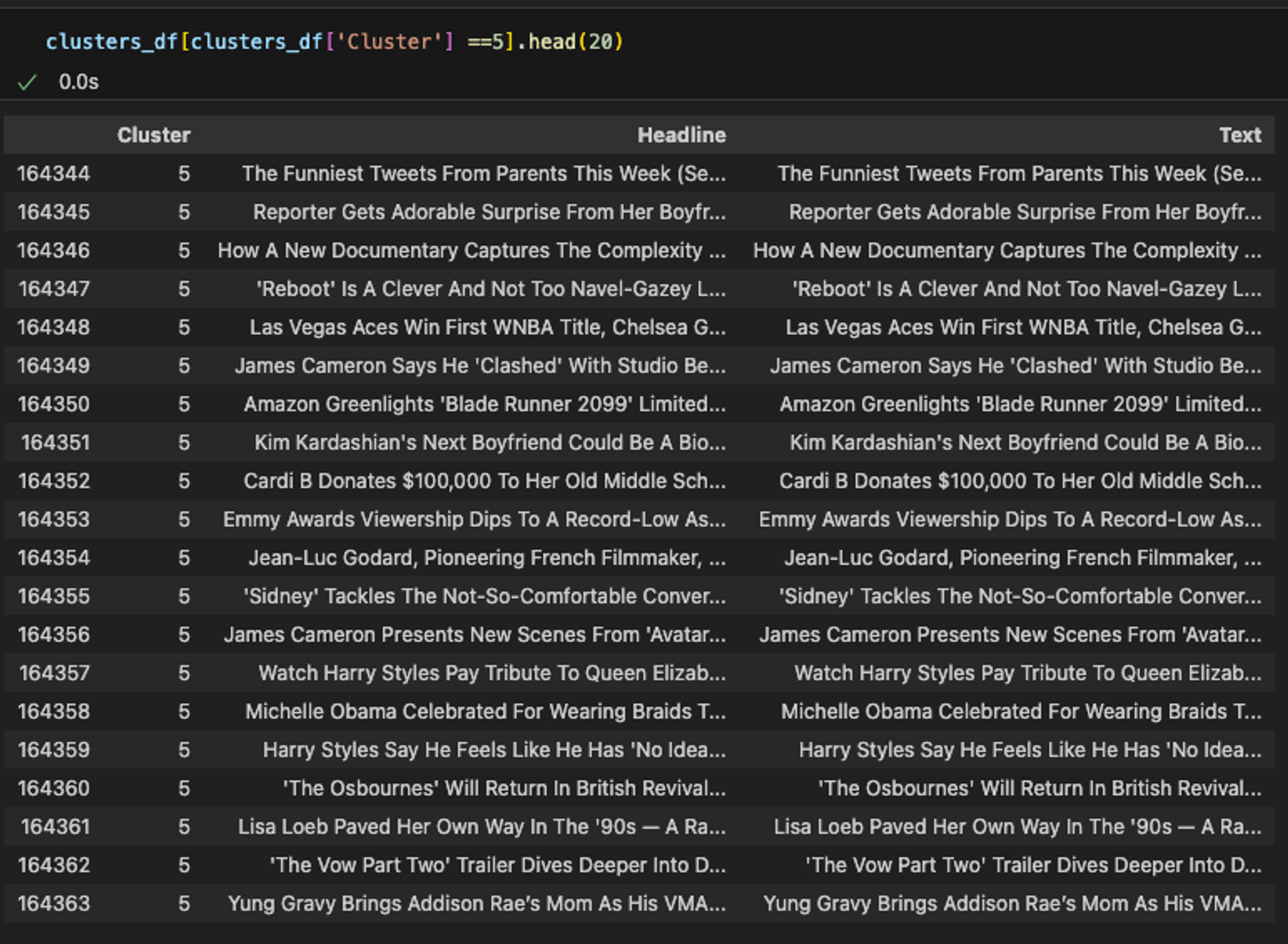
클러스터 = 3: Wellness 분야로 추정
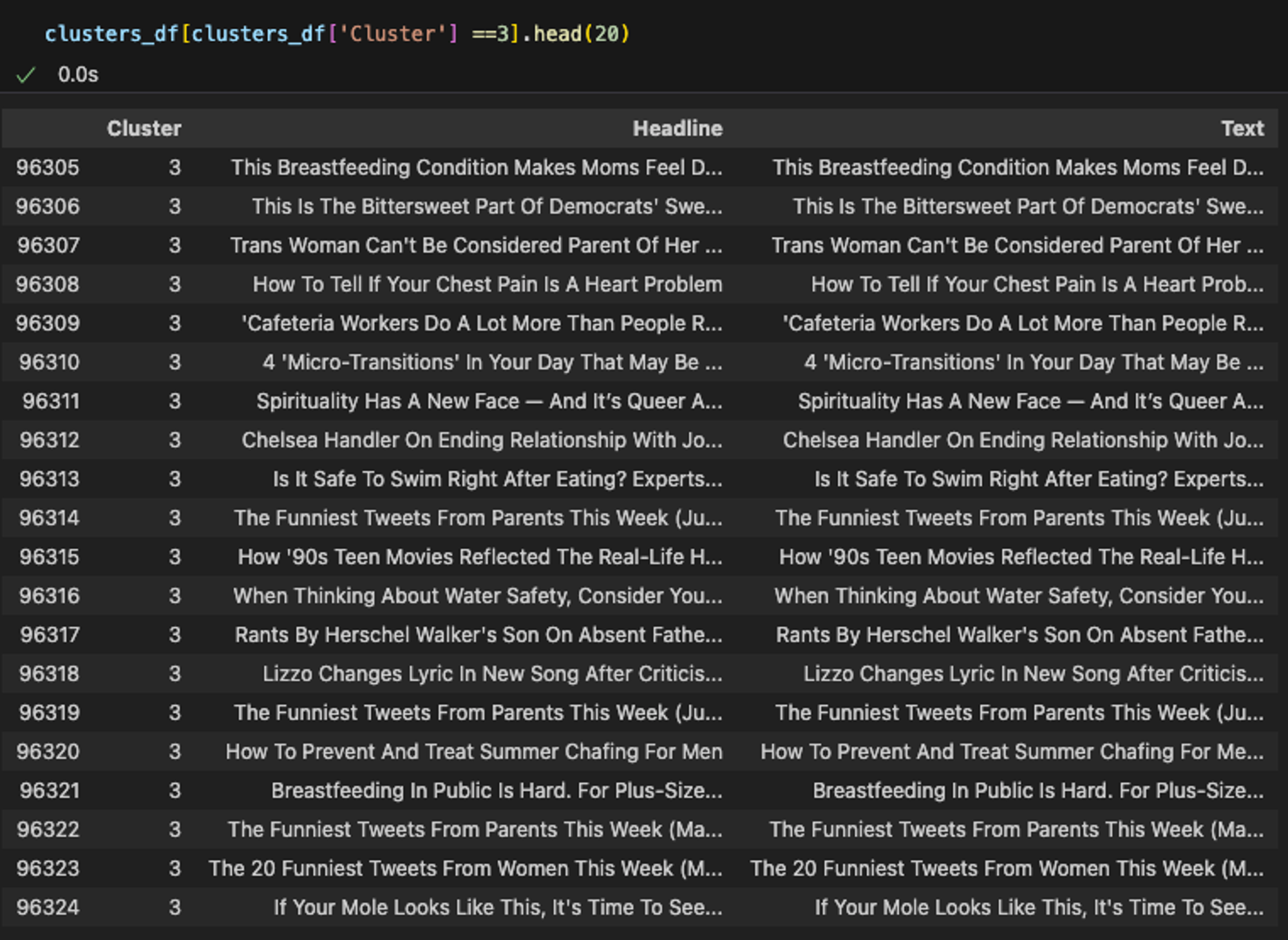
클러스터 = 4: Politics 분야로 추정
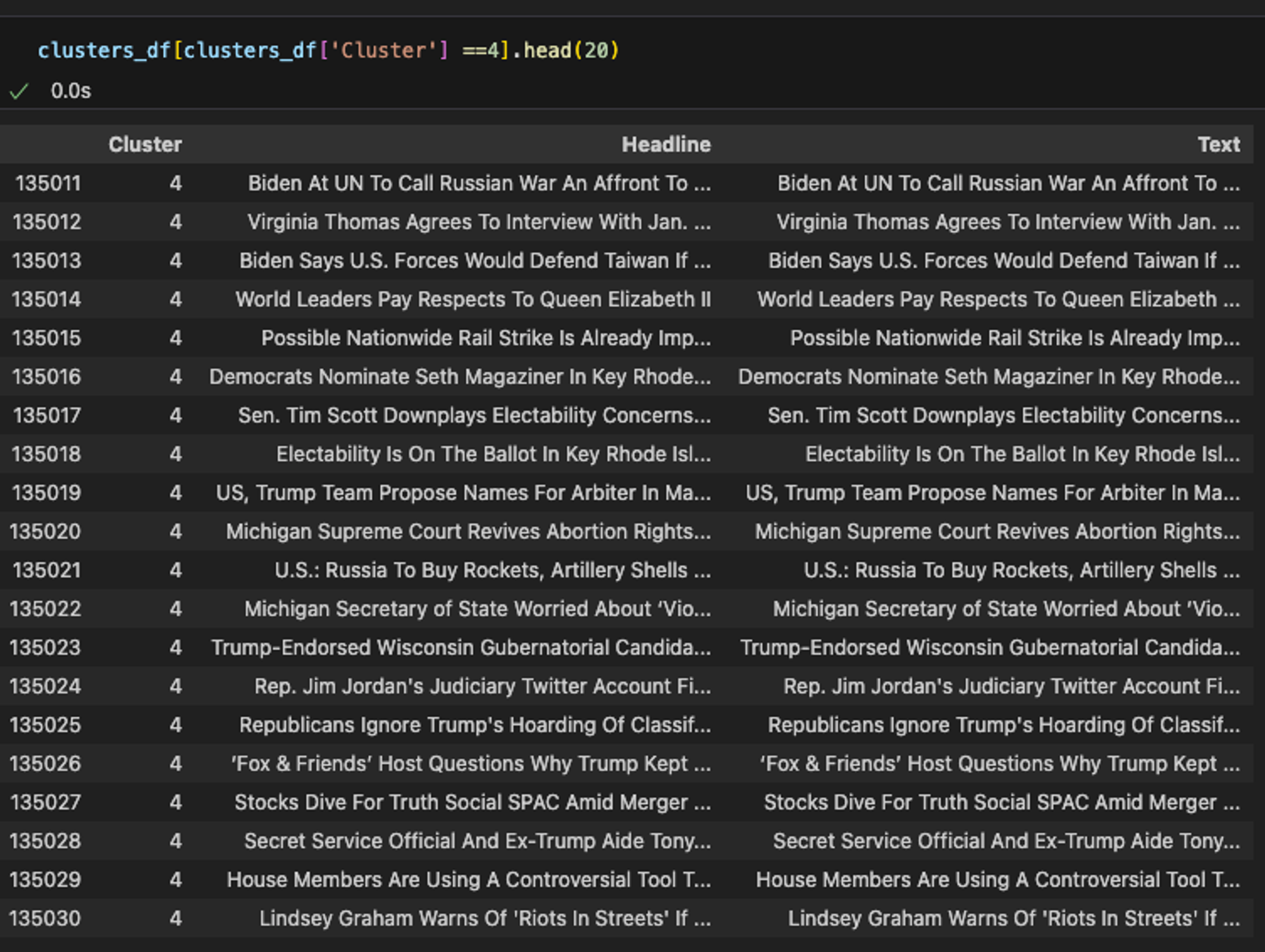
클러스터 = 5: Entertainment 분야로 추정
클러스터링을 활용한 분석 결과
분석 결과를 살펴보면,
우리의 두 가지 목표가 잘 수행된 것 같나요?
| 목표 | 결과 | |
|---|---|---|
| 1 | 텍스트 데이터를 주제별로 군집화 | ○ |
| 2 | 키워드를 추출하는 작업 | ✕ |
보시다시피, 클러스터링은 주제들을 직접 추출하지는 않지만, 유사한 문서들을 그룹화하는 데 도움을 줍니다. 이러한 그룹화를 통해 공통된 테마나 주제를 파악할 수 있습니다.
각 클러스터가 비슷한 주제별로 잘 군집화된 것을 확인할 수 있습니다. 하지만 구체적인 주제어(keyword)를 결정하기 위해서는 각 데이터를 개별적으로 살펴보고 결정해야 합니다.
이러한 과정들을 LLM에게 위임할 경우, 어떤 결과가 나올까요?
🎬 스포일러
전통적인 텍스트 분석 도구는 특정 유형의 데이터에 최적화된 반면, ChatGPT는 다양한 형태와 스타일의 텍스트 데이터를 유연하게 처리할 수 있습니다. 또한, 고급 언어 이해 능력을 바탕으로 복잡한 문맥과 뉘앙스를 파악하는 데 강점을 가지고 있습니다.
LLM(대규모 언어 모델)을 통한 실습
반대로, ChatGPT API를 사용한 결과를 살펴보겠습니다. ('GPT_6'는 데이터셋에서 가장 많은 데이터를 포함한 상위 6개 주제를 기준으로 분류한 결과입니다.) 클러스터별로 상위 25개의 데이터를 각각 출력하였습니다.
- 코드
# 필요한 라이브러리
import os
import time
import openai as ai
import pandas as pd
import numpy as np
import json
# 2023년 8월 기준 새로 나온 gpt-3.5-turbo-0613 사용 - 16,385 tokens
ai.api_key = '발급받은_API_키'
model="gpt-3.5-turbo-0613"
# 데이터 불러오기
Data =pd.read_json(open("./News_Category_Dataset_v3.json","r",encoding="utf-8"),lines=True)
Data = Data[['category','headline','short_description']]
Data.head(3)
# 각 주제별로 가장 많은 데이터를 가진 상위 6개의 주제 선택
topics = list(pd.DataFrame(Data.groupby(['category']).agg(Count = ('category','count'))['Count']\\
.nlargest(6)).reset_index()['category'])
# 선택된 주제에 해당하는 데이터만 필터링
Data = Data[Data['category'].isin(topics)]
# 각 카테고리별로 25개의 샘플 선택
Data = Data.groupby(['category']).sample(25)
# 요청된 응답을 반환하는 함수
def generate_gpt3_response(user_text, print_output=False):
"""
Query OpenAI GPT-3 for the specific key and get back a response
:type user_text: str the user's text to query for
:type print_output: boolean whether or not to print the raw output JSON
"""
time.sleep(5)
completions = ai.Completion.create(
engine='text-davinci-003',
temperature=0.5,
prompt=user_text,
max_tokens=500,
n=1,
stop=None,
)
# 원하는 경우 중간 결과 출력
if print_output:
print(completions)
# 첫 번째 응답 텍스트 반환
return completions.choices[0].text
# 더 의미 있는 주제를 얻기 위해 제목과 설명을 하나의 열로 추가
Data['Head_Description'] = Data['headline']+" :"+ Data['short_description']
# 각 뉴스 항목의 주제를 추출하는 프롬트 엔지니어링
Data['GPT'] = Data['Head_Description'].apply(lambda x: \\
generate_gpt3_response\\
("I am giving you the title and short description \\
of the news article in the format [Title:Description], \\
give me the Broader category like News, sports, entertainment,\\
wellness or the related high level topics in one word in the \\
format[Topic: your primary topic] for the text '{}' ".format(x)))
# ChatGPT에서 생성된 출력 처리 및 주제 추출
Data['GPT'] = Data['GPT'].apply(lambda x: (x.split(':')[1]).replace(']',''))
# 데이터프레임을 엑셀 파일로 저장
Data.to_excel('data_output.xlsx', index=False)
- output 파일
- Entertainment
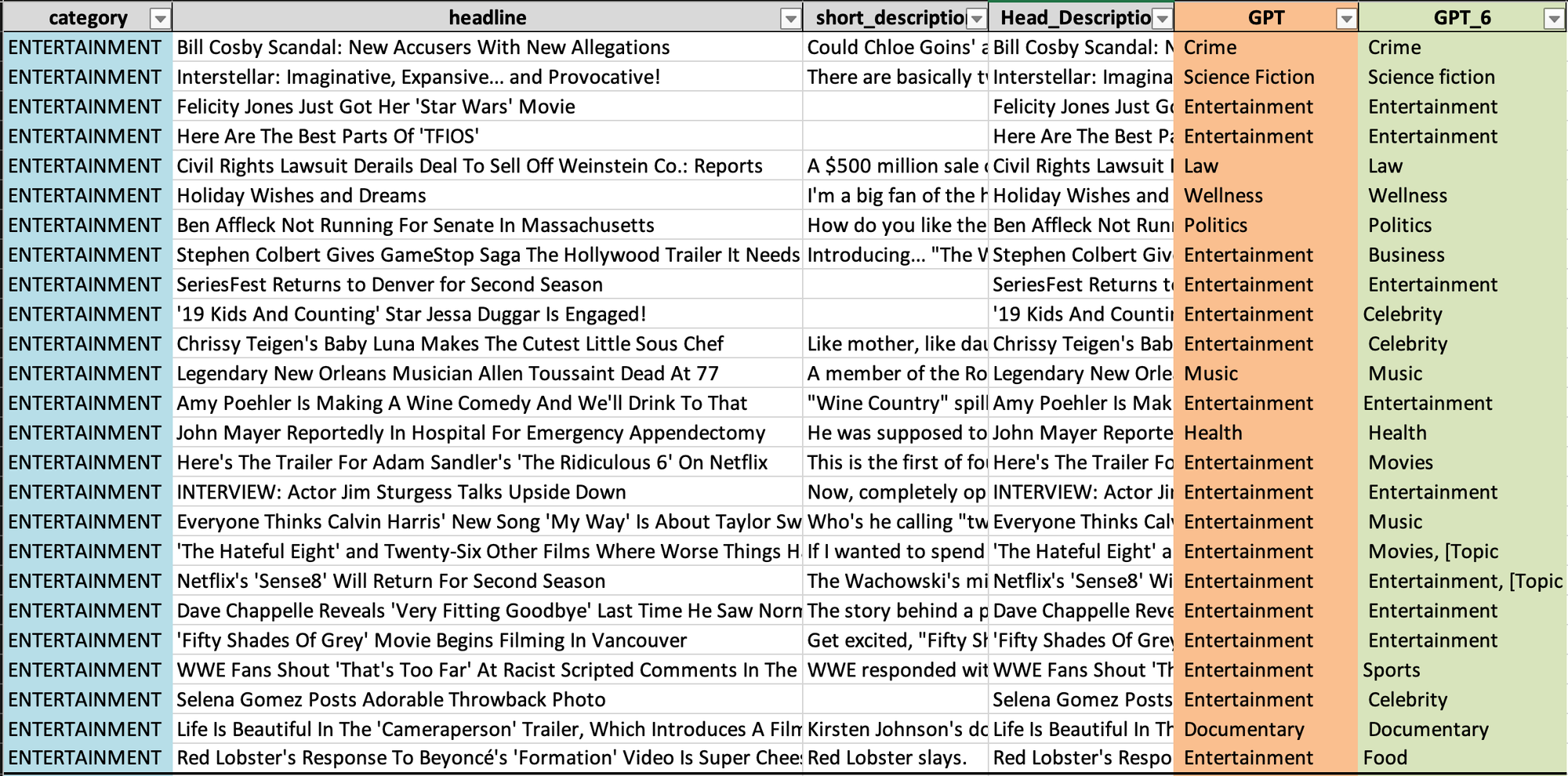
2. Parenting
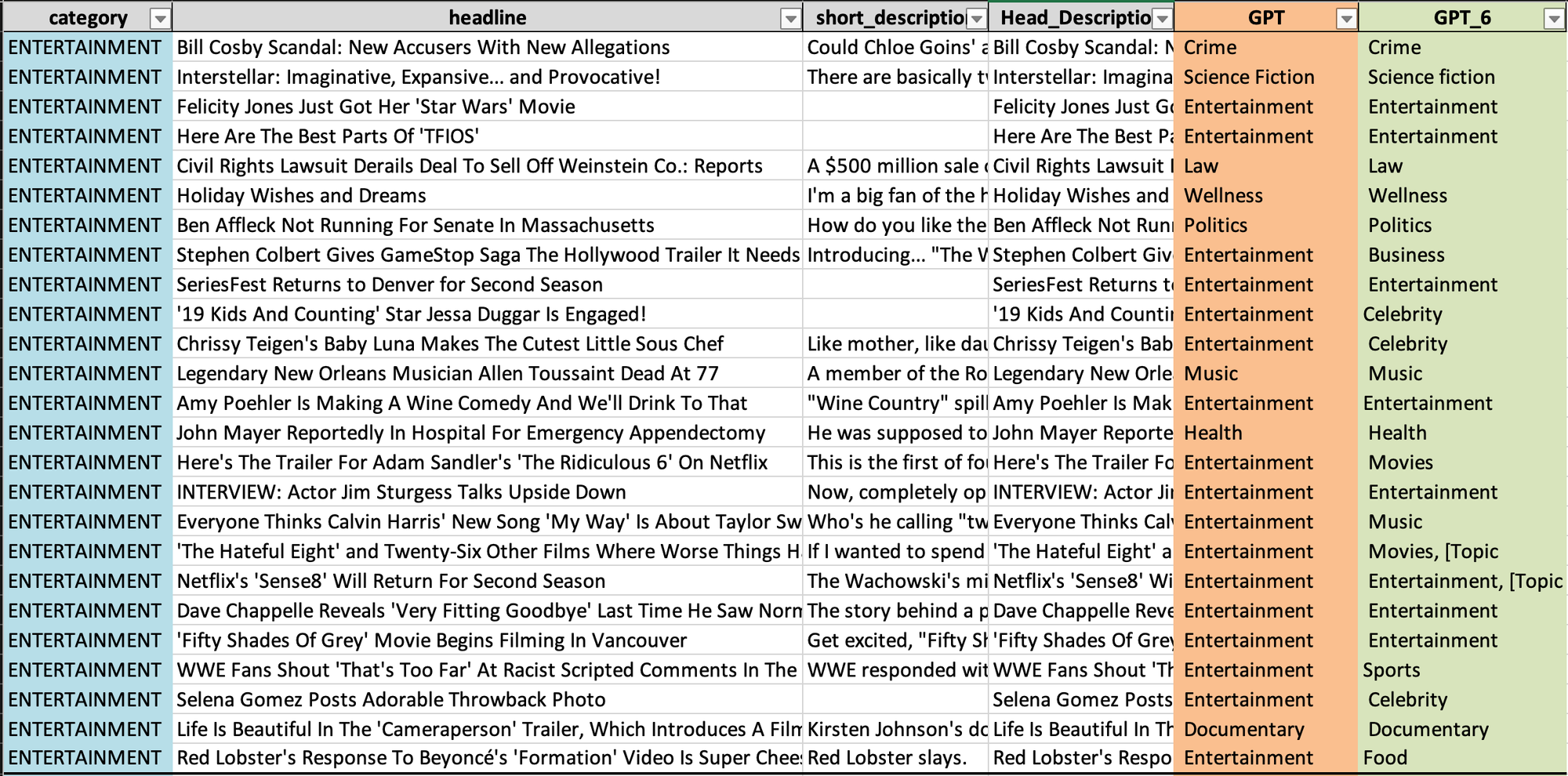
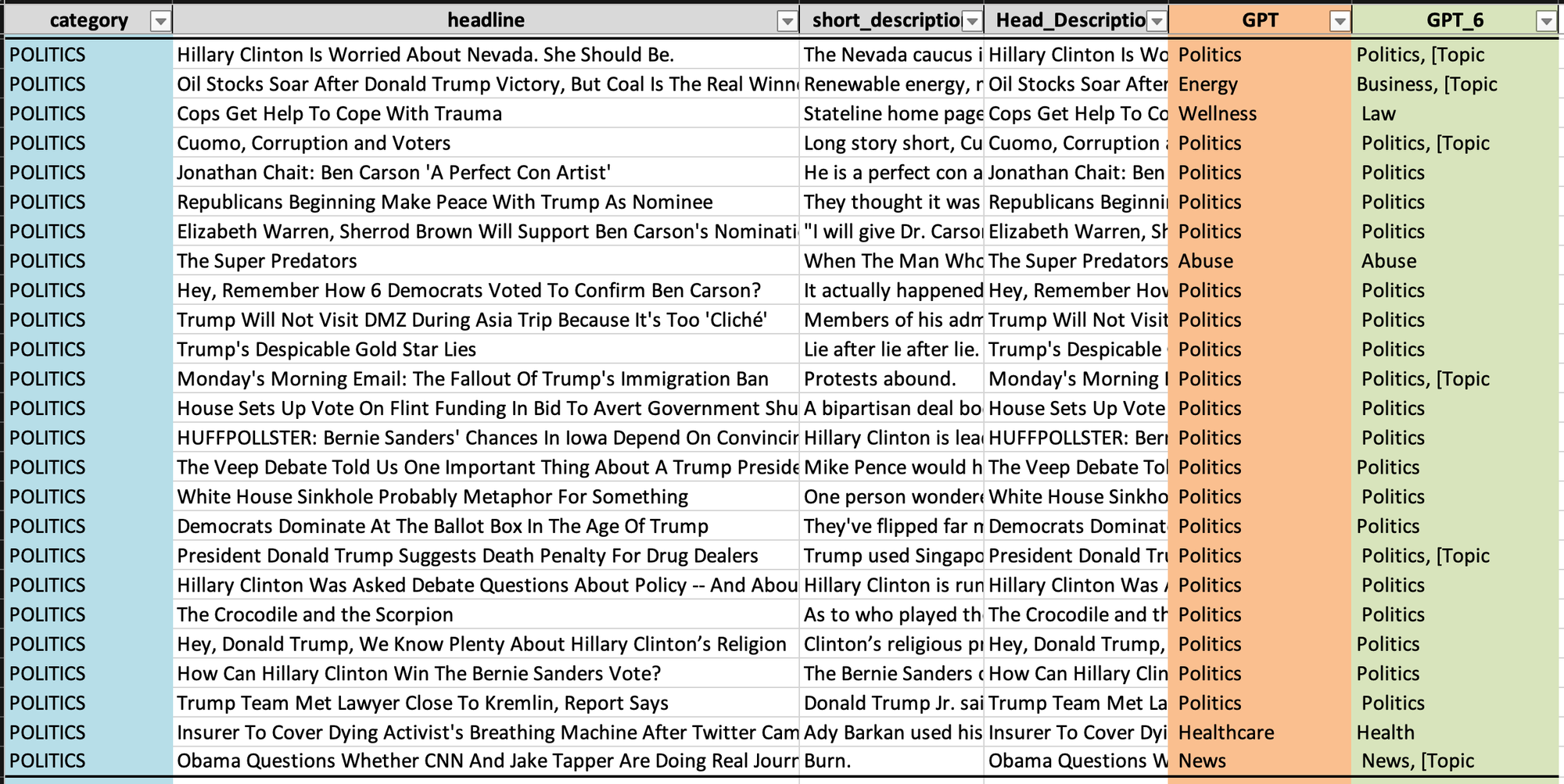
3. Politics
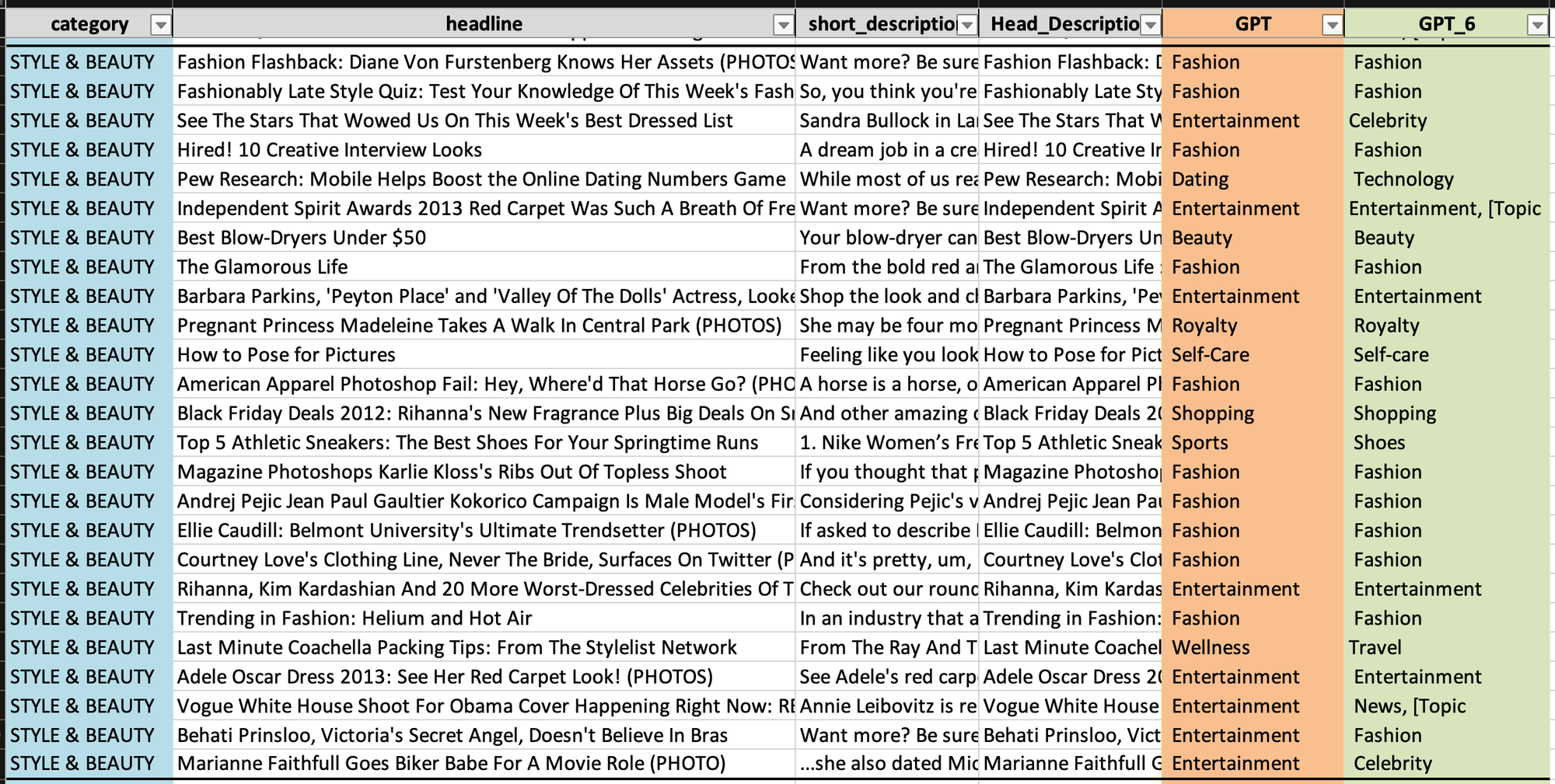
4. Style & Beauty
5. Travel

6. Wellness

LLM을 활용한 분석 결과
‘GPT’ 열을 기준으로 정리하자면,
- Entertainment: 실제 카테고리는 25번 중 18번 올바르게 엔터테인먼트로 예측되었습니다. 음악, 법률, 건강 등 다른 카테고리에 대한 예측도 있지만 수는 적습니다.
- Parenting: 실제 카테고리는 25번 중 10번 올바르게 예측되었습니다. 교육, 건강, 음식 등 다양한 다른 예측도 있습니다.
- Politics: 실제 카테고리는 25번 중 21번 올바르게 예측되었습니다. 예측 결과의 정확도가 가장 높습니다.
- Style & Beauty: 패션, 뷰티, 엔터테인먼트 등 다양한 카테고리에 대한 예측이 혼합되어 있으나, 스타일&뷰티와 유사한 카테고리인 패션을 합하면 가장 높은 빈도로 10회 이상을 차지합니다.
- Travel: 실제 카테고리는 여행이며, 25번 중 14번 올바르게 예측되었습니다. 광고와 기술 등의 카테고리에 대한 예측도 있습니다.
- Wellness: 실제 카테고리는 25번 중 16번 올바르게 예측되었습니다. 건강, 영성, 관계, 과학 등의 카테고리에 대한 예측도 있습니다.
ChatGPT를 사용한 결과를 분석하면서, 두 가지 주요 장점이 눈에 띄었습니다.
2. 개별적인 주제어 추출의 번거로움을 줄일 수 있습니다.
Transformer의 구조 이해
ChatGPT는 어떤 모델 구조를 가지고 있기에 이처럼 만족스러운 결과를 신속하게 도출할 수 있는 걸까요?
자연어처리에 익숙한 분들이라면 알겠지만, Transformer 모델이 바로 그 핵심입니다.
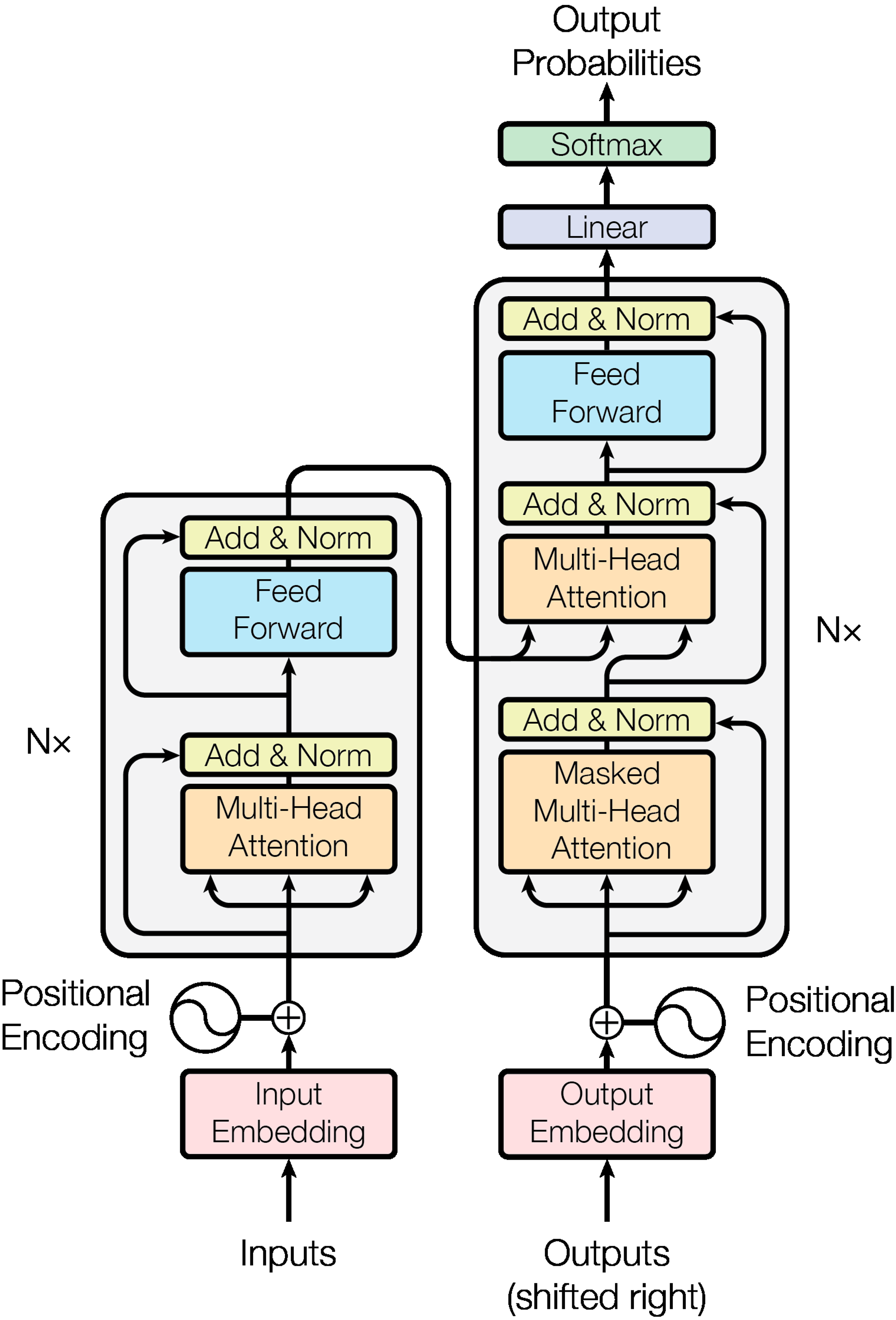
모델 구조가 처음 접하는 분들에게는 복잡하게 느껴질 수 있습니다.
모든 것을 이해하려고 하기보다는, 이 글을 Black Box라고 느껴졌던 인공지능에 대한 더 친근한 이해를 위한 과정으로 가볍게 읽어보시길 권합니다.
ChatGPT의 구조와 텍스트 처리 과정
다음은 ChatGPT의 구조와 텍스트를 처리하는 과정에 대한 설명입니다.
1. 모델의 기반인 Transformer 아키텍처
- Transformer의 핵심인 '주의(Attention)' 메커니즘은 마치 우리가 대화를 들을 때 중요한 부분에 더 집중하는 것과 비슷합니다. 모델은 문장 속에서 특정 단어나 구절에 더 많은 '주의'를 기울이며, 이를 통해 어떤 정보가 더 중요한지를 결정합니다. '자기 주의(Self-Attention)'는 어텐션의 한 형태로 문장 내 각 단어가 서로 어떻게 연결되어 있는지를 모델이 이해하게 합니다. 예를 들어, "The cat sat on the mat"라는 문장에서 'cat'과 'sat' 사이의 관계를 파악하는 것과 같습니다.
- Transformer는 일반적으로 인코더와 디코더로 구성됩니다. 인코더는 입력된 문장을 처리하고 이해하는 역할을 하며, 디코더는 이 정보를 바탕으로 새로운 문장을 생성합니다. 각 인코더와 디코더는 여러 '레이어'로 구성되어 있으며, 각 레이어는 Attention 및 해당 출력에 동일한 가중치를 적용하는 등 다른 연산을 수행하는 Fully Connected Layer로 이루어져 있습니다.
- Transformer는 단어가 문장에서 어디에 위치하는지 직접적으로 알 수 없기 때문에, 'Positional Encoding'을 사용하여 각 단어의 위치 정보를 추가합니다. 이는 각 단어의 순서와 위치가 문장의 의미를 이해하는 데 중요하기 때문입니다.
- 각 레이어의 출력은 'Layer Normalization'을 통해 정규화되며, 이는 데이터를 안정적인 범위 내에서 처리하도록 돕습니다. 'Residual Connections'은 입력을 각 레이어의 출력에 직접 더하는 구조로, 깊은 네트워크에서도 정보가 손실되지 않고 효과적으로 전달됩니다.
- 최종 출력은 먼저 선형 변환을 거친 후, 'Softmax' 함수가 적용되어 각 토큰의 점수를 확률 분포로 변환합니다. 이 과정이 연속적으로 반복되면서 순차적으로 전체 문장을 완성합니다.
2. 대규모 데이터셋에서의 사전 학습
- ChatGPT는 책, 웹사이트, 뉴스 기사 등 다양한 소스에서 수집된 방대한 양의 텍스트 데이터를 사용하여 학습됩니다. 이러한 광범위한 학습 과정을 통해 모델은 문법, 문맥, 다양한 주제에 대한 지식을 습득합니다.
3. 파인 튜닝 및 조정
- 일반적인 사전 학습 후, 모델은 특정 작업(예: 질문 응답, 텍스트 생성)에 맞게 추가적으로 조정됩니다. 또한, RLHF(Reinforcement Learning from Human Feedback) 방식을 통해 인간의 피드백을 기반으로 추가 학습을 진행하여 모델의 성능을 개선합니다.
4. 텍스트 처리 및 응답 생성
- 사용자의 입력을 받은 모델은 이를 분석하고 적절한 응답을 생성하기 위해 다양한 계산을 내부적으로 수행합니다. 이때, 모델은 사전 학습과 파인 튜닝을 통해 습득한 지식을 활용하여 응답을 생성합니다.
LLM의 효율성과 한계
정교하게 구성된 ChatGPT에 대해 더 많이 알아갈수록 더 의지하고 싶지는 않으신가요?
위에서 진행한 ‘News Category Dataset’에 대한 텍스트 분석 결과에서 볼 수 있듯이, LLM의 사용은 기존 통계적 모델링 접근법에 비해 효율성 면에서 월등한 이점을 보여줍니다.
K-means는 일정 수준의 데이터 전처리와 모델링 과정을 필요로 하지만, ChatGPT는 즉각적이고 직관적인 결과를 제공합니다.
OpenAI의 ChatGPT, Google의 Gemini 등과 같은 생성형 인공지능(Generative AI)이 계속 발전하고 성능이 개선됨에 따라, 이 간극은 더욱 확대될 것으로 예상됩니다.
그러나, 이 고도의 언어 처리 능력을 갖춘 AI를 긍정적으로만 바라봐도 되는 걸까요?
빛이 있는 곳에 반드시 어둠이 있기 마련입니다.
ChatGPT에게 그것의 한계에 대해 직접 질문했을 때, 다음과 같은 답변을 받았습니다.


따라서, ChatGPT의 무분별한 사용과 과도한 의존은 피해야 합니다.
AI 사용 시 문화적, 윤리적 민감성에 대한 이해가 아직 충분하지 않으며, 잘못된 정보에 대한 책임소재가 명확하지 않다는 점을 인식해야 합니다. 과정을 생략하고 결과만을 추구하는 경향은 비판적 사고와 문제 해결 능력을 저하시키며, 독립적인 사고와 창의성 발달에 장애가 될 수 있습니다.
GPT-4는 출시 당시 토큰 수가 128,000까지 늘어났지만, 여전히 입력 토큰의 제한이 존재한다는 점을 인식해야 합니다. (LangChain, RAG를 사용하는 등 간접적인 해결 방법이 존재하기는 합니다.)

ChatGPT가 빠르고 편리한 결과를 제공하지만, AI에만 의존하는 것은 위험할 수 있으며, 모델에 대한 통제력을 잃을 수 있음을 인지해야 합니다. 데이터 분석가, 엔지니어, 과학자들은 데이터 관련 작업 시 ChatGPT를 책임감 있게 사용하는 것이 중요합니다.
또한, 정확한 문제 정의의 중요성이 더욱 강조되고 있습니다. 분석과 개발에서 요구되는 역량이 단순한 프로그래밍 기술에서 효과적인 질문과 명확한 지시로 전환되고 있음을 부정하기 어렵습니다.
글을 마치며
물론, 10년, 5년, 하물며 1년 뒤에는 또 어떻게 바뀌어 있을지 모르겠습니다.
기술 발전에 대한 경계심을 유지하는 것이 중요하지만, 그와 동시에 변화와 발전에 대한 기대감을 갖는 것은 이 시대를 살아가기 위해서는 필수적입니다.
하트카운트는 ChatGPT와 같은 AI 기술을 활용하여 새로운 기회를 모색하는 여정에 여러분과 함께하겠습니다.