![[무료 강의] EDA 101 (1): 분석하기 좋은 데이터셋, 변수 유형별 시각화 방법](/ko/content/images/size/w2000/2024/04/-----------------------_-001--6-.png)
📌 강의 목차
0:00 도입부
2:02 Data Analysis Maturity Model
3:44 Descriptive Data Analysis
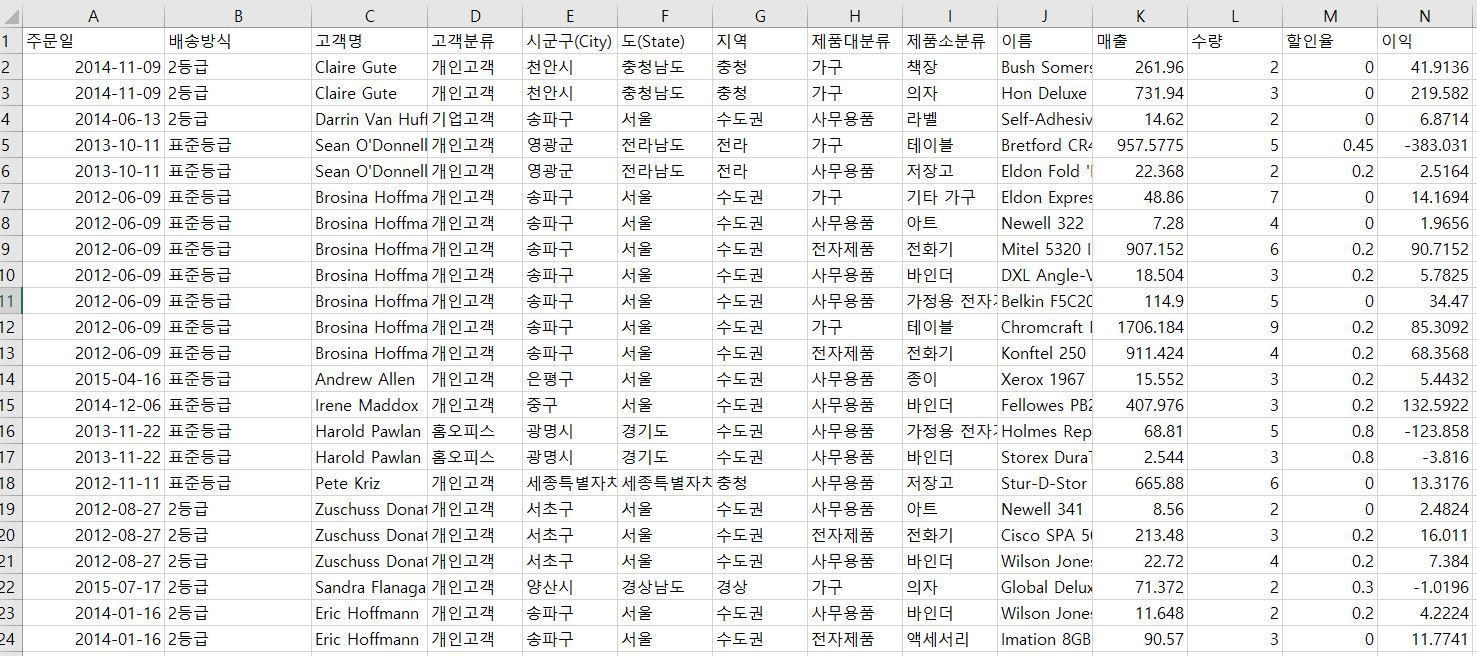
5:56 Rectangular Dataset and Key Terms
첫 번째 장표 오탈자 : 열(Column), 행(Row)가 맞는 표현입니다.
10:39 Features Engineering
12:22 Data Type에 따른 시각화 방법
🗒️ 요약 노트
1. 분석하기 좋은 데이터셋(Tidy Data)
Tidy Data 공식 지키기
Tidy Data이란? 깔끔한 데이터. Hadley Wickham의 논문에서 Tidy Data는 “각 변수가 열이고 각 관측치가 행이 되도록 배열된 데이터”라고 정의합니다.


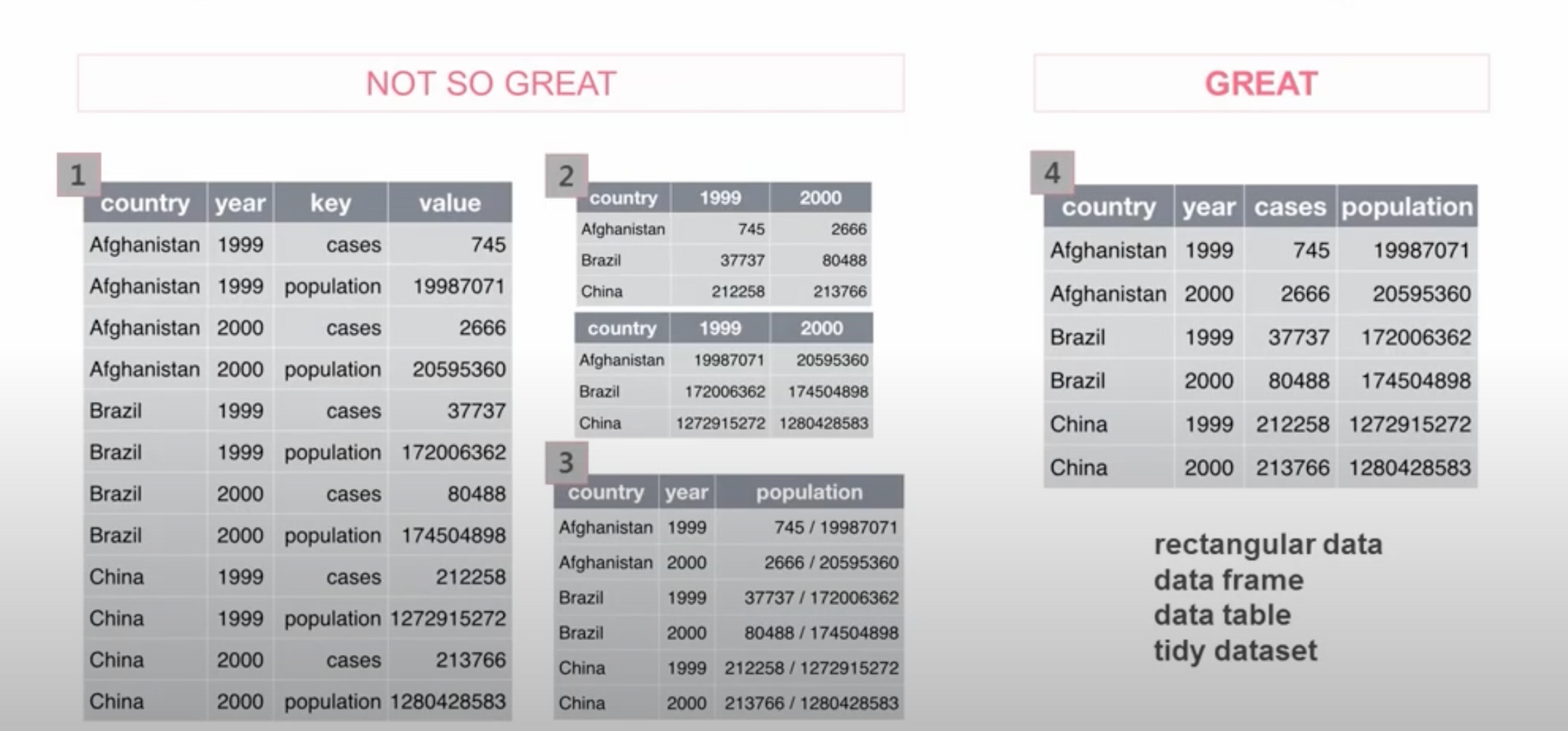
정리하면, 아래 내용들을 숙지하여 데이터셋을 구성해주시면 좋습니다.
- 열(column) : 하나의 변수(variables) e.g A열: 나라, B열: 이름 등..
- 행(row) : 변수의 관측치(observations)
- X(행): features, 독립 변수, input Y(칼럼/열): target(목표 변수), 종속 변수, output
- 열 이름(첫 번째 행은) 변수를 칭하는 이름으로 구성
- 여러 변수가 합쳐 하나의 열로 구성하는 것 지양 e.g ‘m1990’과 같이 성별+출생연도가 합쳐진 변수
- 데이터는 하나의 파일로 조인될수록 분석할 수 있는 폭이 넓어지며 편리해진다. 따라서 데이터 조인을 대비하여 공통으로 묶을 수 있는 id와 같은 키를 만들어두기
TIP
- Raw data vs Aggregated(요약된) data : 한 가지 질문이 아닌 데이터에 대한 꼬리에 꼬리를 무는 질문을 하려면, Raw data가 더 적절함.
- 우리가 궁금해하는 목표 변수(target/output)을 설명하기 위해 관측치들을 잘 분류하는 feature(속성)을 발굴하는 것이 중요함.
2. Type별 시각화 방법
Data Type(=변수 유형)에 따른 시각화 방법
변수는 숫자형과 범주형으로 나뉘며 우리는 보통 숫자와 숫자 사이의 연관성을 알아보거나 숫자의 차이를 가져오는 범주를 발견하기 위해 분석을 수행합니다.
- 숫자*숫자 : Scatterplot(산점도, 모든 데이터를 그래프상에서 점으로 표현하는 방법)
- 숫자의 구간을 쪼개어 범주로 처리 ⇒ Boxplot(상자그림, 대표값 시각화를 통해 데이터의 분포를 확인하는 방법)
📖 강의 교재
💡 관련 아티클
실무자를 위한 데이터의 기본 유형 설명(nominal, ordinal, numerical)
본 블로그는 2015년에 작성된 블로그(’기본적인 데이터 종류 이해하기’)가 데이터 유형을 교과서적으로 엄격하게 분류했던 것을 보완하여, 현업들이 실무 맥락에서 데이터 유형을 보다 쉽게 이해할 수 있도록 수정한 글입니다. 1. 기본적인 데이터 종류 이해하기2. [Revisited] 실무자를 위한 데이터의 기본 유형 설명(nominal, ordinal, numerical) 범주형 데이터 - 명목형(Norminal)
 heartcount
heartcount
🗣 후기 이벤트
학습 콘텐츠가 도움이 되셨나요? 블로그에 후기를 작성해보세요.
블로그에 하트카운트 학습 콘텐츠와 관련된 글을 작성 후 아래 폼을 제출해주시면, 추첨하여 네이버페이 5,000원 쿠폰을 전달드립니다. 내가 공부한 내용을 기록하고, 다른 사람들에게 추천해보세요.
![[하트카운트 실습 예제] Hansrosling dataset](/ko/content/images/size/w360/2023/10/--------_------------_-25-.png)
![[무료 강의] EDA 101 (2): 데이터의 모양 묘사하기 (히스토그램, boxplot, percentile)](/ko/content/images/size/w360/2024/04/-----------------------_-002--3-.png)