
Intro
정책이 실제로 어떤 영향을 미쳤는지 알고 싶다면, 가장 신뢰할 수 있는 방법은 무작위 통제 실험(RCT, Randomized Controlled Trial)입니다. 흔히 A/B 테스트로 불리는 이 방식은 인과 효과 추정의 'gold standard'로 여겨집니다. 그 이유는 아래의 예시를 통해 살펴보겠습니다.
다만, 현실에서는 윤리적, 기술적 제약으로 인해 A/B 테스트를 수행하기 어려운 경우가 많습니다. 특히 테크 기업이 아닌 일반 조직에서는 실험 환경이 제대로 갖춰지지 않았거나, 있다 해도 모든 정책에 A/B 테스트를 적용하기엔 시간과 비용의 부담이 큽니다.
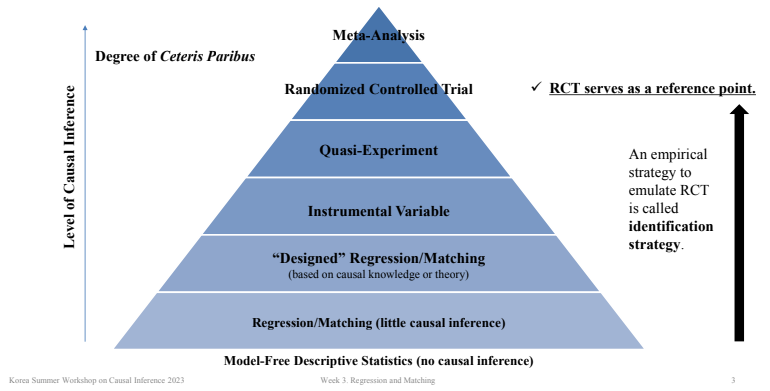
이러한 제약 속에서 우리는 무작위 실험을 모사(emulate)할 수 있는 다양한 방법론을 사용합니다. 아래 인과 추론의 계층 구조에서도 볼 수 있듯이, RCT는 가장 신뢰할 수 있는 방법 중 하나지만, 이를 대체하거나 보완하기 위한 다양한 방법들이 존재합니다. 이번 글에서는 매칭(Matching) 기법을 HEARTCOUNT의 AI 분석 기능을 활용해 직접 실습하며 이해해 보겠습니다.
왜 A/B 테스트(RCT)가 gold standard인가?
간단한 예시를 통해 살펴보겠습니다.
어느 보험사에서 사내 연수를 시행했고, 이 연수가 직원의 수입에 어떤 영향을 미쳤는지 알아보려고 합니다.
아래는 연수를 받은 그룹입니다.
| 사번 | 연수참가여부 | 나이 | 수입 |
|---|---|---|---|
| 1 | 1 | 28 | 17700 |
| 2 | 1 | 29 | 6100 |
| 3 | 1 | 25 | 20800 |
| … | … | … | … |
| 17 | 1 | 28 | 11500 |
| 18 | 1 | 27 | 10700 |
| 19 | 1 | 28 | 16300 |
그리고 아래는 연수를 받지 않은 그룹입니다.
| 사번 | 연수참가여부 | 나이 | 수입 |
|---|---|---|---|
| 20 | 0 | 43 | 20900 |
| 21 | 0 | 50 | 31000 |
| 22 | 0 | 30 | 21000 |
| … | … | … | … |
| 38 | 0 | 35 | 30200 |
| 39 | 0 | 32 | 17800 |
| 40 | 0 | 54 | 41100 |
하지만 데이터를 보면 연수를 받지 않은 그룹이 평균적으로 더 나이가 많다는 점에서, 나이와 수입 간의 상관관계가 교란(confounding)을 일으켰을 가능성이 있습니다.
RCT의 핵심은 바로 이러한 변수들이 두 그룹에 균등하게 분포되도록 무작위 배정을 하는 데 있습니다. 표본 수가 충분히 크다면, 나이처럼 수입에 영향을 줄 수 있는 요인들이 자연스럽게 균형 있게 분포할 가능성이 높아지고, 이는 곧 인과 효과를 정확히 추정할 수 있는 기반이 됩니다.
하지만 앞서 말했듯, 현실적으로 RCT를 매번 수행하긴 어렵기 때문에, 이를 대체할 수 있는 방법이 필요합니다.
Matching
Matching의 개념과 방식
Matching은 말 그대로 비슷한 특성을 가진 사람끼리 짝을 지어 비교하는 방법입니다.
예를 들어, 나이 28세인 사번 1 (연수 받음)과 사번 27 (연수 안 받음)을 비교할 수 있습니다. 이처럼 모든 나이에 대해 가능한 짝을 찾아 비교하면, 나이라는 변수의 영향을 통제한 상태에서 연수의 효과를 추정할 수 있습니다.
이러한 작업을 HEARTCOUNT의 AI 분석 기능을 활용하면 수작업이나 코드 작성 없이 간단히 실습할 수 있습니다.
AI 분석으로 실습하기
1) 데이터셋 준비
아래 데이터를 다운로드합니다.
HEARTCOUNT에서 캠페인 생성하기 → 파일 불러오기 → 다음 단계 클릭하여 캠페인을 생성합니다.

2) 기본 비교
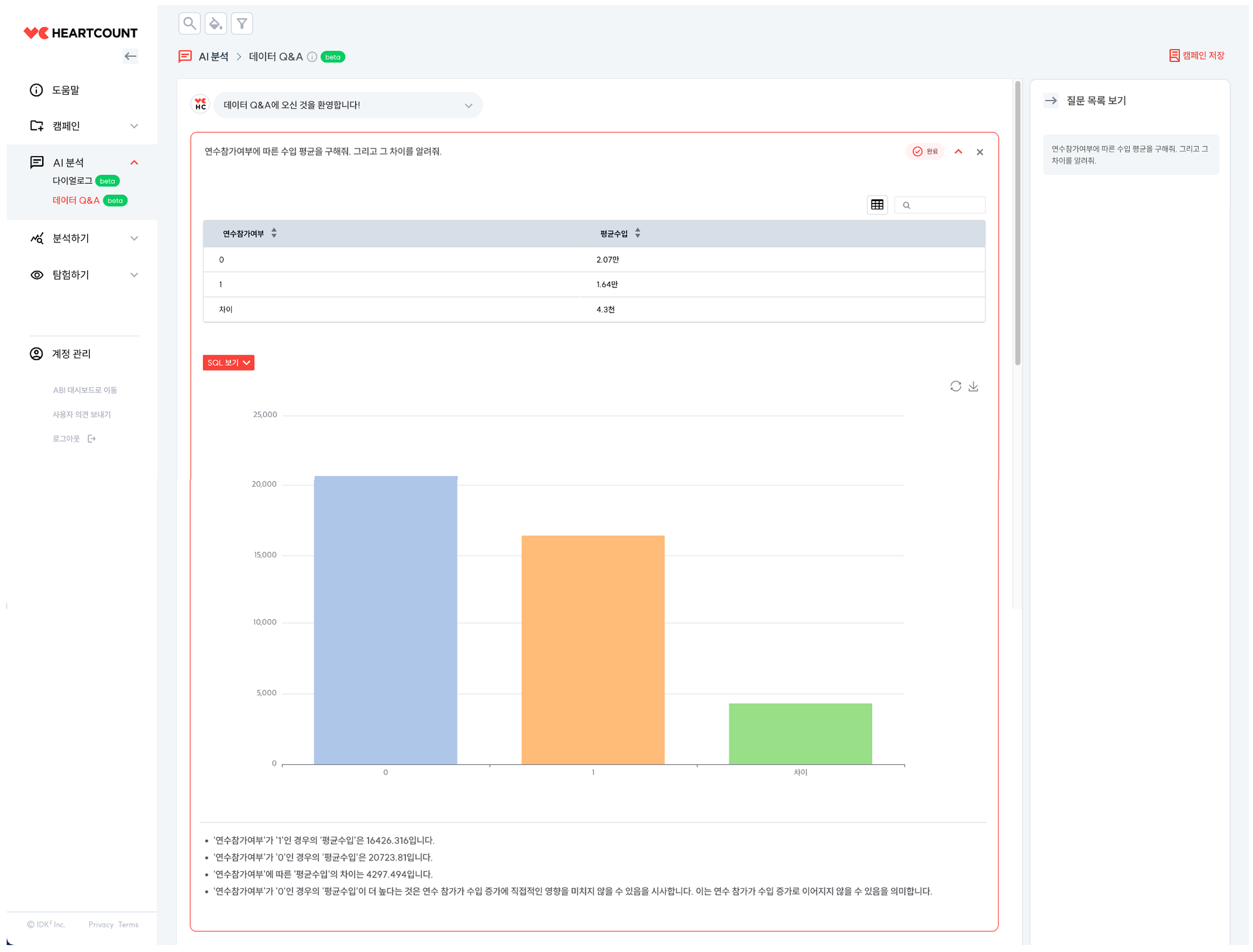
AI 분석 메뉴의 데이터 Q&A 기능을 이용하여 자연어로 분석 요청을 할 수 있습니다. 자연어 질문을 입력하면 SQL 쿼리와 시각화를 자동으로 생성합니다.
연수참가여부에 따른 수입 평균을 구해줘. 그리고 그 차이를 알려줘.
3) Matching을 통한 비교
같은 ‘나이’를 기준으로 ‘연수참가여부’가 1인 사람과 0인 사람을 모두 매칭하고, 각 쌍의 정보와 ‘수입’ 차이를 한 행에 보여줘.
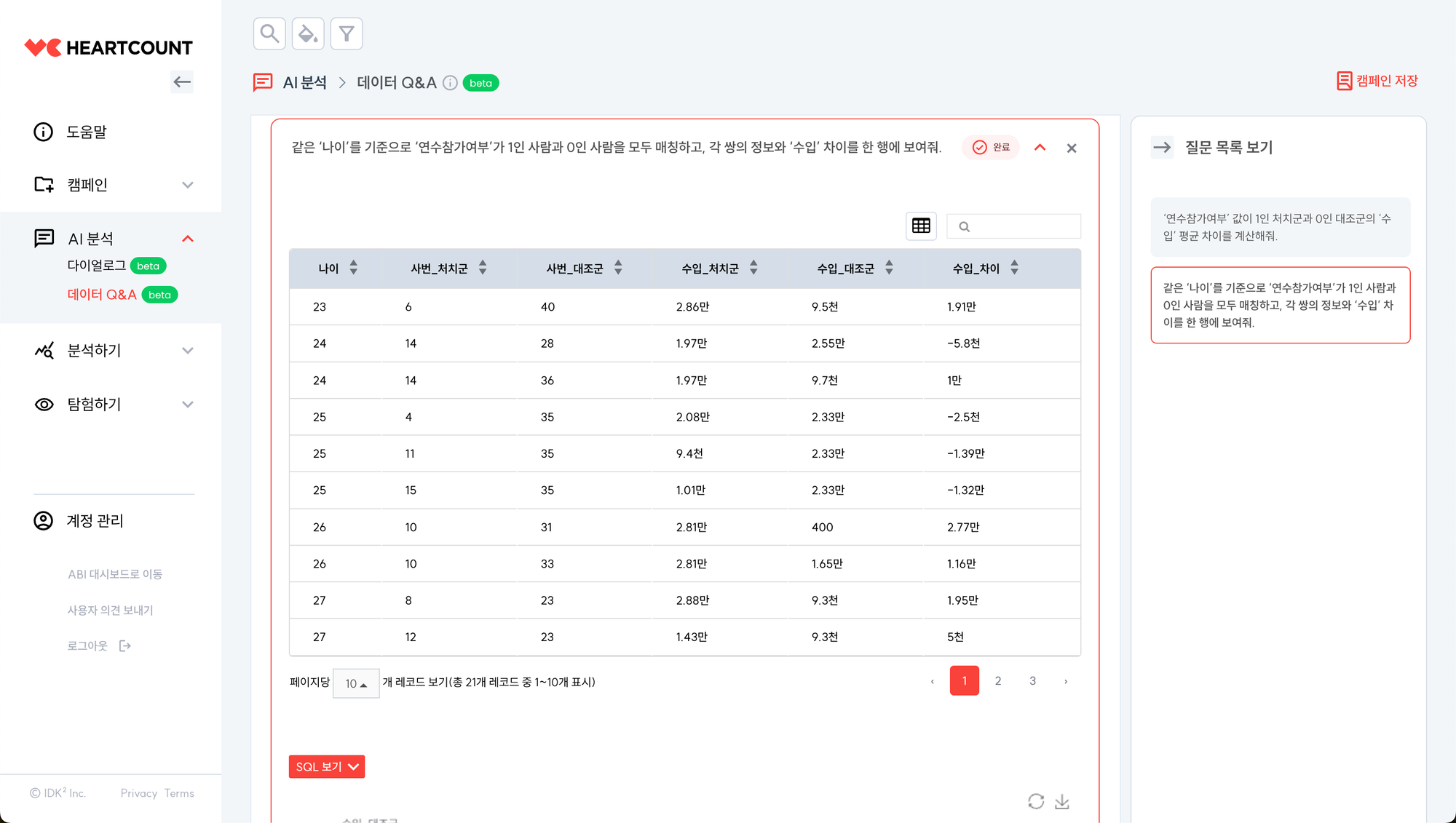
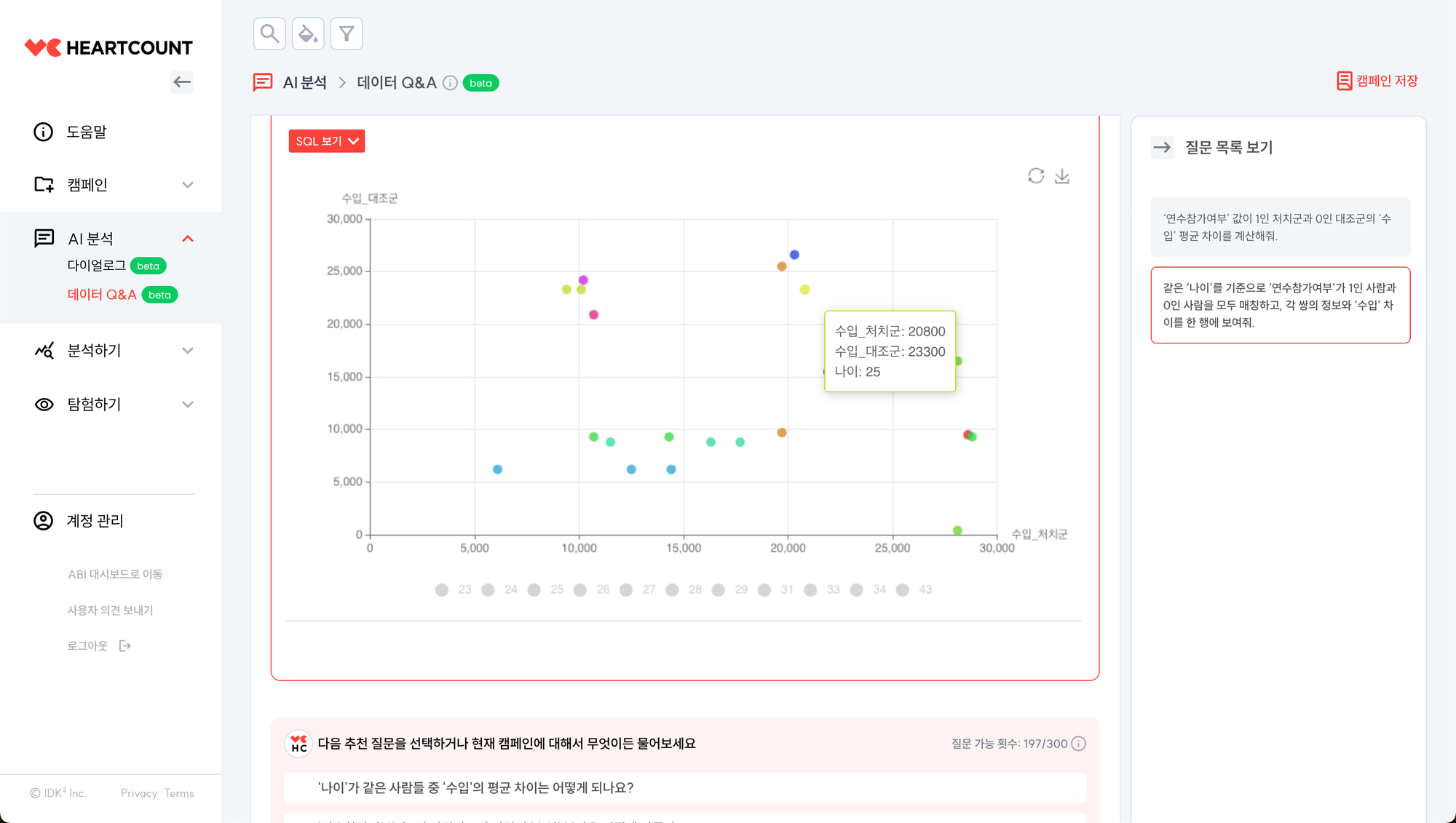
나이 기준으로 적절히 매칭되는 것을 확인할 수 있습니다. 이를 바탕으로 효과를 다시 추정합니다.
4) Matching 기반 효과 추정
같은 ‘나이’ 기준으로 매칭된 ‘연수참가여부’ 1과 0 그룹의 ‘수입’ 차이를 계산하고, 그 차이들의 평균을 구해줘.
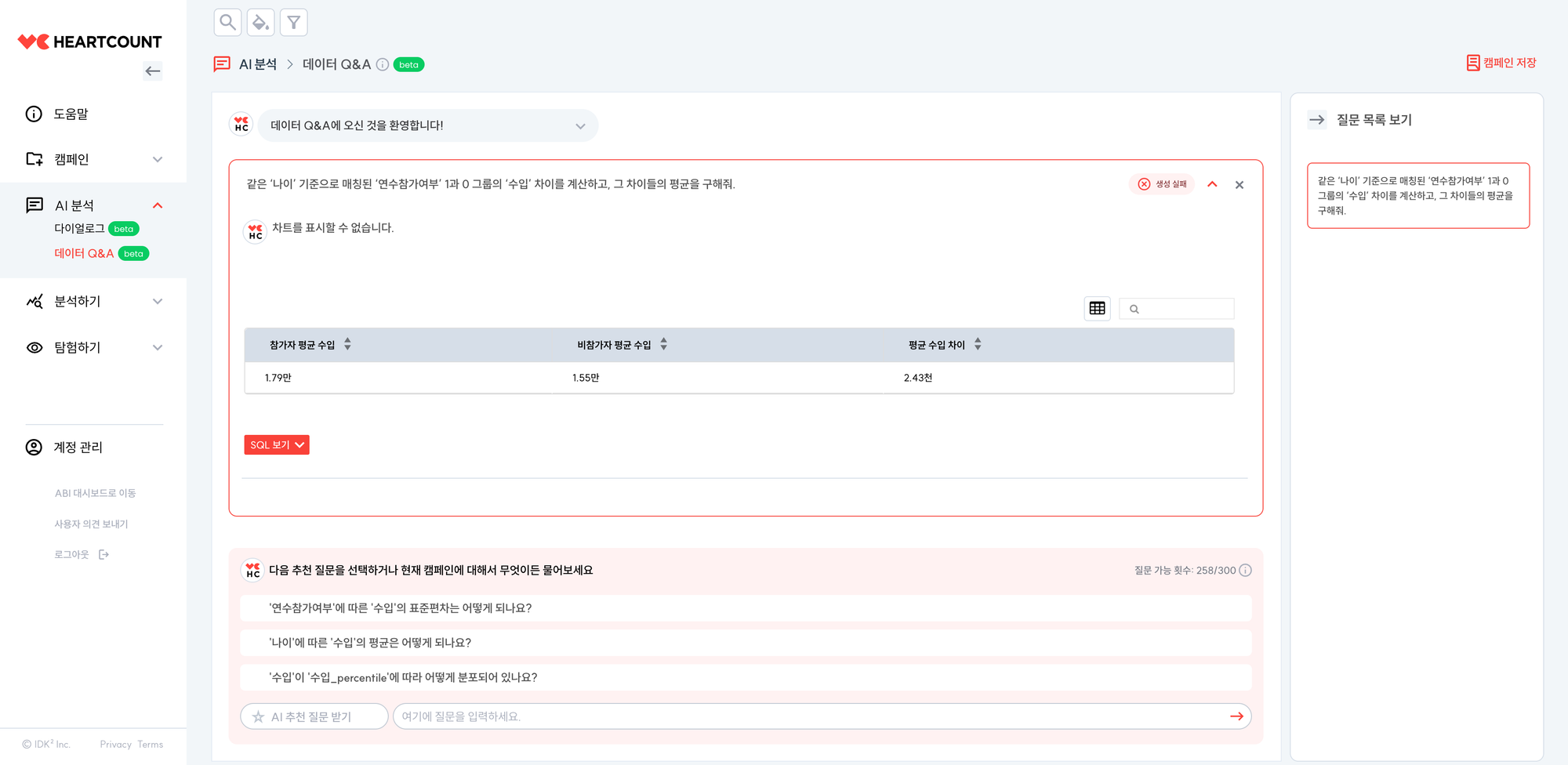
즉, 교란 요인(여기서는 나이)을 통제하자 인과효과 추정이 상당히 달라질 수 있음을 확인할 수 있습니다.
매칭의 한계와 확장
이번 실습에서는 단일 변수(나이)를 기준으로 Exact Matching을 수행했습니다. 하지만 실제 분석에서는 나이뿐 아니라 성별, 직급, 근속연수 등 다양한 혼란 변수(confounders)를 함께 고려해야 할 때가 많습니다. 이처럼 고려할 변수가 많아질수록, 모든 조건을 동시에 만족하는 짝을 찾기 어려워지고, 매칭 가능한 표본 수도 급격히 줄어듭니다. 이를 차원의 저주(curse of dimensionality)라고 합니다.
그 결과 많은 관측치가 제외되고, 추정에 사용되는 표본이 전체 모집단을 충분히 대표하지 못할 수 있습니다. 즉, 우리가 구한 인과효과는 전체가 아닌 일부 소표본에만 국한된 결과일 수 있다는 한계가 존재합니다. 이를 보완하기 위해 CEM, PSM, IPTW와 같은 다양한 기법들이 사용됩니다.
RCT가 어려운 상황에서도 관측 데이터를 활용해 인과 효과를 추정할 수 있는 방법들이 있습니다. 매칭은 그 중 하나이며, 이후 다른 기법들로 확장해 나갈 수 있습니다.
출처
자연어를 SQL, 시각화로 변환해주는 AI 분석 '데이터 Q&A'기능으로 무료로 매칭 기법을 실습해보세요. 분석 언어를 몰라도, 데이터에 질문만 하면 빠르고 정확한 답을 얻을 수 있어요.
함께 보면 좋은 글
 David Gu
David Gu Sun Jung
Sun Jung

![[인과추론 1] Potential Outcome Framework(잠재적 결과 프레임워크)](/ko/content/images/size/w540/2024/01/----------------------5.png)