- データ分析の始め方が分からなかった方
- お気に入りのデータ視覚化/分析ツールを見つけるのが難しかった方
- データアナリスト(組織)が不在で、自分が行っているデータ分析が正しいかどうか迷っていた方
はじめに
ChatGPTに代表される巨大言語モデル(以下、LLM)の登場とともに、データ分析の世界にもLLMを導入しようとする市場の大きな動きについて紹介しました。
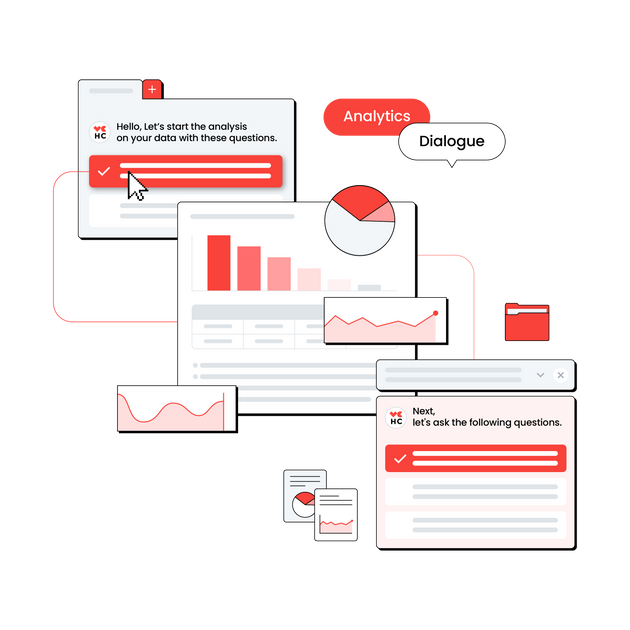
HEARTCOUNTは今年6月、AI Analytics製品である HEARTCOUNT Dialogue を新たにリリースします。HEARTCOUNT Dialogue は、与えられたデータに対してユーザーに適切な分析の質問を推奨し、正確で迅速な視覚化の結果やテキストサマリーを生成する、データ専門家ではないすべての人のためのAIベースのデータ分析製品です。
HEARTCOUNTがどのような哲学と悩みを込めてこの製品を作ったのか、一緒に共有したいと思います。
ソフトウェア、自由度と精度の間で
データ分析製品も大きなカテゴリーで見ると「ソフトウェア」とみることができます。
すべてのソフトウェアは以下のように分けてみることができます。
A) ユーザーが創造性を存分に発揮できる製品
B) 人々が間違いを犯さずに与えられた目的を達成できるようにする製品
A)タイプの代表的な製品は Adobe Photoshop でしょう。ユーザーに非常に高い自由度を提供し、才能と技能をもつユーザーのために自分の能力を最大化するのを助けます。しかし、そうでないユーザーは、自分の弱点がそのまま現れてしまうような製品です。ユーザーに何かをする(例えば、キャラクターの作成)ベストプラクティスを提示し、正しい道に行くように、つまり間違いを犯さないように導いてくれる優しさはありません。当然、多くの教育と労力と時間を必要とします。もちろん、それが悪いことではないでしょう。一定量の努力と時間(+才能)が担保されれば、本人が望む結果値に達することができるでしょうから。
B)タイプの代表的な製品は年末調整のようなプログラムです。正確な結果を得ることが重要であり、それが存在理由であるこれらのツールは、間違った値を入力したり、決められた作業順序に従わないことを許容しません。
それでは、データ分析ソフトウェアはどうでしょうか?
データ分析ソフトウェアは大きく BI と EDA/Analytics ツールに分けることができます。まず、伝統的な意味でのBIは B) のタイプに近い製品です。ダッシュボードを見ながら発生する追加的な質問にすぐに答えを得ることができないという事実は不安ですが、あらかじめ定義されたメトリックを決められた方式(ダッシュボード)で使用するので安全です。(変換レイヤー(transformation layer)を含むパイプライン(pipeline)を管理することは A) に近い作業ではありますが)。
一方、EDA/Analyticsツールは A)のタイプに属する製品です。もし、自分が抱く質問が頻繁に発生する定型化された質問であれば、あえてEDAツールを使う必要はありません。そのような場合は、メトリックをよく定義してダッシュボードを上手く作ればいいからです。一方、ビジネス/サービス環境で発生する質問は時々、定型化されていない質問(ad-hoc question)、ダッシュボードを見た後に事後的に発生した質問である場合があります。 この場合、実務者の立場では EDA/Analyics ツールあるいはデータ専門家/組織の力を借りるしかありません。

しかし、Photoshopの例で示されているように、データ分析について無知または熟練度の低い95%の一般人は、自分が抱いている質問に対する正解を得るために、自由度が高すぎる EDA/Analytics ツールをどこからどのように扱えばいいのか、ただただ途方に暮れるだけでしょう。そうすると、結局、分析に慣れていて専門知識(expertise)を持つ残りの5%(アナリスト、分析組織)に頼るしかないのが現実です。全世界がデータ民主化(Data Democracy)というスローガンを叫んでいますが、実際にはデータエリート主義(Data Elitism)が蔓延しているのです。これが EDA/Analytics ツールが知識労働者の普遍的な業務ツールとして定着することに失敗した原因だと思います。

だからといって、EDA/Analytics ツールが B) のような年末調整のようなツールになることはできませんし、なるべきではありません。むしろ、ユーザーが望む目的地に到達できるように、データがユーザーのインスピレーションと出会い、無限の可能性を開いておく(open-ended)一方で、親切な標識をたどっていくと、いつの間にか目的地に到着しているような方法(guided data journey)を提示することが EDA/Analytics が進むべき究極の方向性だと思います。
ビジネスのためのデータ分析にLLMをどのように活用するのか?
昨年から始まった巨大言語モデル(以下、LLM)の洪水の中で、BI/Analytics 製品もLLMを自社製品に組み込んでいることを紹介しました。LLMの言語理解能力であれば、95%の一般ユーザーが持っている内面的な閉塞感を質問で投げかけられたとき、それを適切な分析結果に置き換えることができるという期待から生じた結果でしょう。
しかし、HEARTCOUNTはその波にただ流されないために、少し一歩下がってLLMの根本的な側面に目を向けました。LLMが何ができるのか、何に限界があるのかを考えてみました。
- LLMは基本的に言語モデルであるため、それ自体ではデータ分析の成果物を導き出す様々な演算を実行する能力がありません。言い換えれば、自力では実行できない演算/結果の導出プロセスを処理できる Analytics ツールと必然的に組み合わせるしかないということです。
- LLMは明らかに世界を揺るがす革新的な概念の、これまで登場した技術の中で最も「人工知能」的な技術であることは間違いありません。とはいえ、LLMをデータ分析のすべてのプロセスに無闇に使用することはできないでしょう。分析の各プロセスにおいて、LLMがどのような役割を果たすことができるかを考える必要があります。
ビジネス環境でのデータ分析のプロセスは、通常、次のような分析的推論(Analytical Reasoning)のプロセスを経ることになります。
2.EDA/Analyticsツールの分析の質問に置き換えた後
3.分析の質問を分析言語に変換し
4.結果を導き出し(視覚化、テーブル)、ユーザーが理解しやすい言語の形でサマリー
5.ユーザーのビジネスに当てはめて解釈し適用する
それぞれのプロセスをもう少し詳しく見ていきましょう。
1→2) ビジネス上の質問を分析の質問に置き換える
- ユーザーが持っている漠然としたビジネス上の質問(1) は、データの言語、分析の質問(2) とは離れている可能性が高いです。
- 例えば、「今月はいったいなぜこんなに売上が落ちたのか」というのは分析の言語ではありません。純粋なビジネス上の質問です。「今月の売上と前月、前年同期の売上を様々な要因別に集計した後、互いに比較し、最も売上の落ち込みに大きな影響を与えた要因を冷静に探してみようか?」でなければ、分析の質問と呼ぶことはできません。
- 95%の一般ユーザーの立場、つまり分析用語に慣れていない人の立場では、良い分析の質問を思いつくのは無理なことです。結局、この部分は、良いパフォーマンスを持つLLMが言語理解能力を十分に発揮して、ユーザーの漠然としたビジネス上の質問をよく理解し、良い分析の質問に変える役割を果たしてくれるものと期待することができます。
- 伝統的には、この部分が社内のデータアナリストの能力が最も必要とされる領域でもあります。ビジネスのコンテキストを理解し、上層部/他の部署のスタッフのビジネス上の質問を良い分析の質問に変えることです。問題は、多くの企業がそのようなアナリストを保有していないのが事実であり、たとえそうだとしても、ある程度の規模の会社の多くの部署で発生するすべての質問に対する回答を提供できる余裕のあるアナリスト/組織は多くはないでしょう(5%)。結局、回答を得るために長い時間を待たなければならない状況が生まれます。
- この部分を解決するために、企業はBI製品の導入やデータリテラシーの教育に力を注いできましたが、実際に企業環境で「データを活用した意思決定」にどれだけ役に立ったかは未知数です。上で説明したように、1次元的で繰り返しの質問に対する回答はBIを通じて得ることができますが、時々発生する複雑な分析質問(ad-hoc)には、通常、アナリストが必要であるためです。
3) 分析の質問を分析言語に変換する
- 以下は、分析の質問を分析言語(R、Python、SQLなど)に変換し、分析結果を導き出すプロセスです。
- 上記の例で議論を続けると、「今月の売上と前月、前年同期の売上を様々な要因別に集計した後、互いに比較し、最も売上の落ち込みに大きな影響を与えた要因を冷静に探したい」という分析の質問を大体次のようなコード、分析言語に置き換える必要があります。
与えられたタスクに対する擬似コード:
- 与えられたデータから
- {今月}、{前月}、{前年同期} を定義し(特に、日/分/秒単位で構成されるデータの場合、その時系列データに対する追加の前処理作業が必要)、
- {複数の要因} から {商品カテゴリ}、{地域}、{顧客セグメント} などの変数を選択する。
- {商品カテゴリ}、{地域}、{顧客セグメント} ごとに {売上} を {今月}、{前月}、{前年同期} ごとに集計して {売上合計} を計算し
- {今月} と {前月}、{今月} と {前年同期} の {売上合計} の差を計算する。
- 複雑に見えますが、すでに分析言語に慣れている5%に属する人であれば、巧みにコードでその内容を記述することができるでしょう。もちろん、95%の一般的な実務者は例外ですが。
- また、LLMが十分なデータ(分析言語で書かれたテキスト)を学習すれば解決できると市場が期待している領域でもあります。
4) 結果を導き出す
- 今回のステップ3で計算したデータを、ユーザーが理解しやすいように視覚化(グラフ、テーブル)し、結果をサマリーするステップです。
- 視覚化は既存の視覚化方法を活用することになります。例えば、Tableauなどの視覚化ツールを活用したり(この場合はそのツールの視覚化の文法を理解する必要があります)、またはR/Pythonなどの分析言語でよく使用されるMatplotlib、ggplot2などのライブラリを活用することになります。この場合、ステップ3のプロセスで生成したデータを再びそのライブラリ用のコードで2次置換するプロセスが必要です。
- 次に、視覚化の結果(グラフ、テーブル)を言語の形でまとめる作業です。視覚化で注目すべき事実を発見し、ユーザーが注目すべき事実を捉えて言語の形で理解することです。分析に慣れていない人にとっては、この部分も難しいかもしれません。単純な視覚化であれば問題ないのですが、何が「注目すべき」かを判断するのが難しい場合(例えば、視覚化が多層的に構成されて複雑な場合)が存在するためです。
- この点も、LLMが今後うまくやってくれるのではないかと市場で期待されている分野でもありますが、データ分析のクオリティを決定づける重要な要素の一つが「正確性」であることを考えると、ハルシネーション現象が視覚化の結果に対する誤解を生み出すことが懸念されるのも事実です。
5) ユーザーのビジネスに適用する
- 最後にステップ4の作業の結果を自分のビジネスに適応させるステップです。分析の結果(視覚化、サマリー)を自分のビジネス(ドメイン、データが生成された背景)の理解と組み合わせて、「インサイト」を導き出すステップです。
- 伝統的にステップ4までの作業を記述的(descriptive)、ステップ5の作業を処方的(prescriptive)と命名することもあります。
各ステップの担当範囲を整理してみると、ステップ2とステップ3はLLMの言語能力に期待できる領域であり、ステップ4は EDA/Analytics ツール自体の役割(分析言語を結果に変換する)でしょう。一方、ユーザー自身が良い質問を思いつくステップ1と、導き出された結果を解釈して自分のコンテキストに合わせて活用するステップ5は完全にユーザーの役割でしょう。
ChatGPT-4o、本当にデータ分析に使えるのでしょうか?
ここまでだけで見ると、LLMとユーザーがそれぞれの役割分担(?)をうまく行えば、LLMをデータ分析に活用することは本当に難しくないように見えます。しかし、本当にそうでしょうか?
まず、分析の質問を分析言語に置き換える部分は、最新レベルのトランスフォーマーベースの言語モデル(例えば、GPT)であっても、まだよくできていません。これは少し前に市場を沸かせた OpenAI の最新のプロダクションレベルのモデルである GPT-4o も同様です。GPT-4o が公開され、ChatGPT はデータ分析機能に関連したUI(列の選択、列に対する質問、グラフとインタラクション、Googleドライブ連動など)を新しく追加しましたが、実際に使ってみると、それほど優れた性能を発揮することはできません。
- 今回の公式ドキュメントを見ると、2つの期間/集団間の差を比較する際に便利なウォーターフォール(Waterfall)チャートをサポートすると書かれていました。それで、実際のデータを渡して描画してほしいとリクエストしたところ、5回ほどコード作成に失敗した後、コードを実行できないのでユーザー本人のローカル環境で直接回してみるように、という不合理な(?)回答をくれました。何度もプロンプト・エンジニアリングで試してみても同じような結果を得ました。95%の一般ユーザーの立場ではコーディングをしないようにGPTを使用するはずなのに、逆にコードを理解して実行するようにというのは不合理な話でしょう。
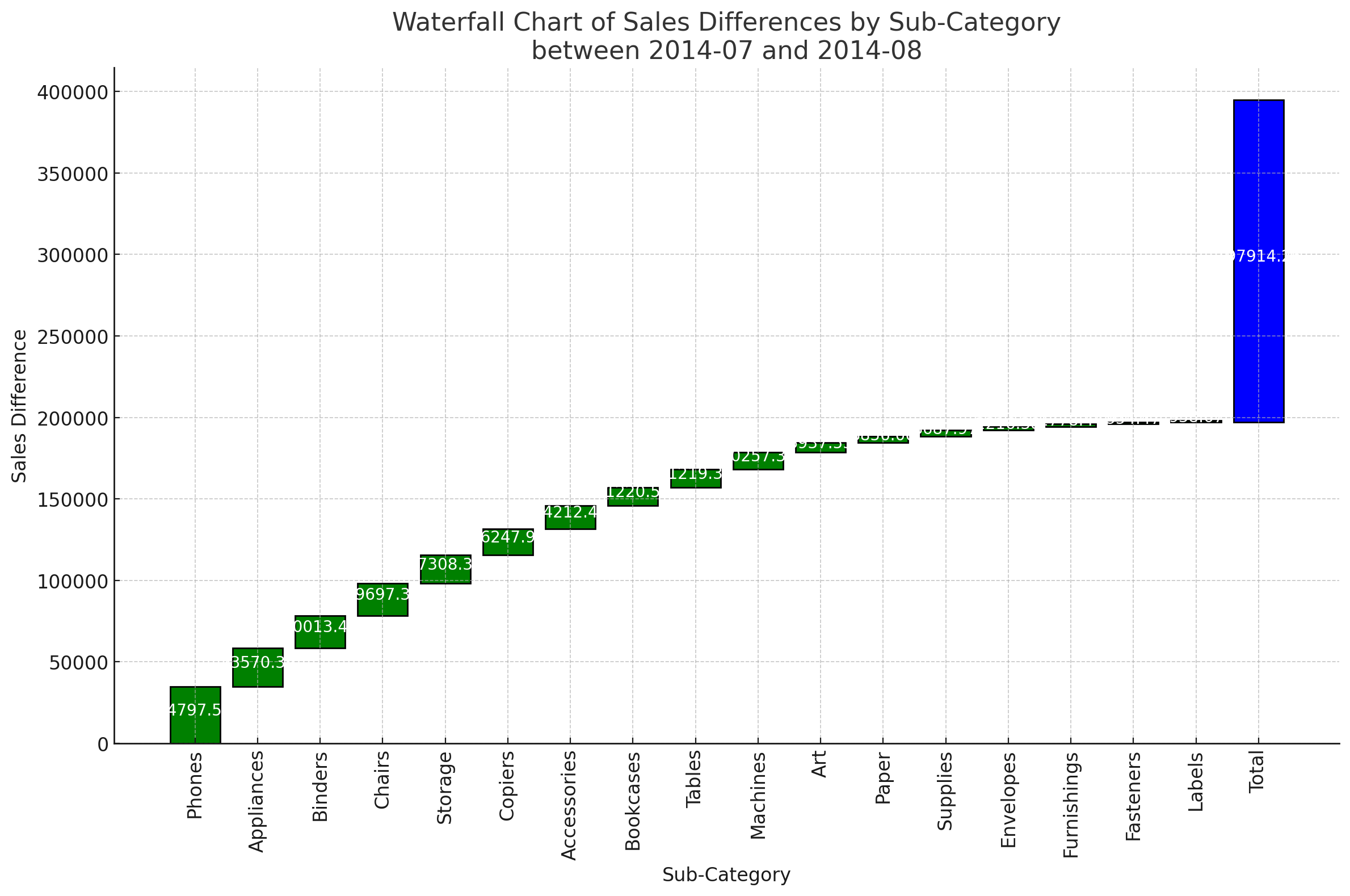
- さらに、複数のタスクを経て生成されたチャートの結果が正確ではありません。以下は GPT-4o を使用して生成したウォーターフォールチャートです。両方とも正確なウォーターフォールチャートとして見るのは難しいです。チャートを生成するために作成された Python-Matplotlib コードが正確でないためです。ステップ4で失敗したのです。
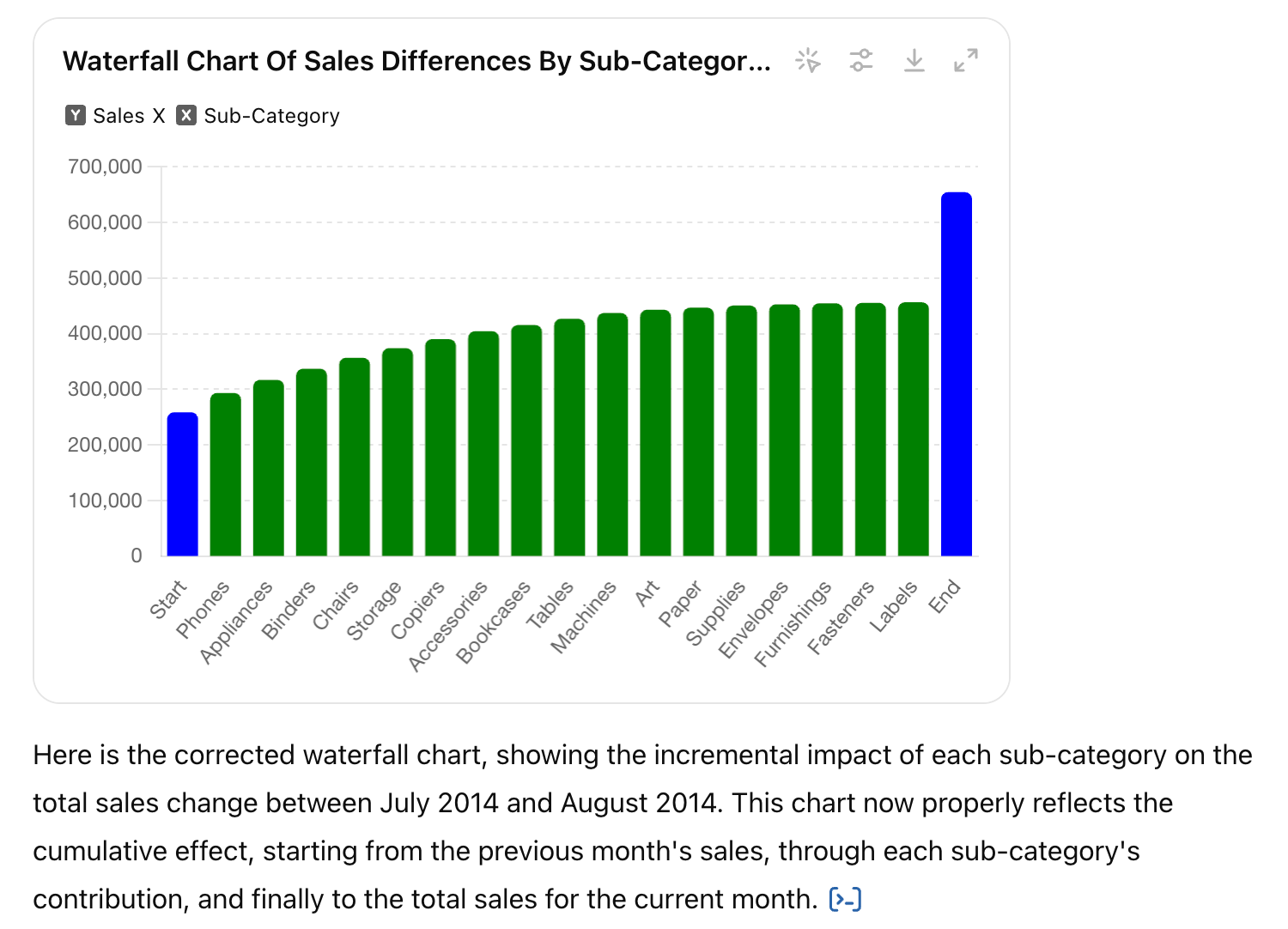
- DataGPTなどのLLMベースのデータ分析製品は、このことを防止するために、LLMが作成したコードとロジックをユーザーに「透過的に」公開し、これを直接確認してハルシネーションを防止するようにすることもあります。また、ChatGPTの場合は、データ分析機能を使用する際にすべてのコードを表示するか、表示しないかを選択できるオプションもあります。そのオプションをオフにしてこの機能を使用する場合、「LLMがうまくやってくれるだろう」という漠然とした信頼に基づいて分析をしなければならない状況なのです。

- 結局は、LLMが生成した分析言語(コード)を解釈し、うまく作成されたかどうかをチェックして実行する残りの5%の専門家の役割が再び浮上するしかない状況です。
- また、視覚化の結果の導出まではある程度うまくできたとしても、結果を解釈(ステップ4) する部分にも注意が必要です。チャートやテーブルから有意義な情報を導き出し、解釈する部分でハルシネーションが発生すれば、ユーザーが間違った結論を導き出す可能性が存在するためです。GPTが導き出した分析的推論の結果に対して再度チェックし、正確性を確認しなければならない作業が追加で発生することになります。
このように、データ分析の各ステップにおいて、LLMはエラーを引き起こす可能性が存在します。そして、ユーザーが指摘するまでは自分がエラーを発生させたことすら気づかないのが現状です。
データサイエンス用語に誤差伝播(error propagation)というものがあります。あるステップ i で発生したエラー(error_i)は次のステップ i+1 に伝播され、i+1 での計算はすでに前のステップで発生したエラーを含む計算となり、結果としてエラーを再生成します。このステップが繰り返されると、最終的にはエラーが積み重なって最終的な結果を信頼できなくなるという概念です。まるで「静寂の中の叫び」のようなゲームをしていると、最初の提示語がステップを経るたびにずれてしまい、結果的には全く間違った答えを出すことになるようなものです。
LLMをデータ分析に活用することもこのような危険性があります。各ステップで少しずつ蓄積されたエラー(幻覚)は、最終的にユーザーに不正確な結論を提示することがあり、これは信頼性と正確性が必要なデータ分析においては致命的です。
結論として、分析的推論(Analytic reasoning)の作業をLLMに全面的に依存することは、現時点では適切ではないと思われます。
HEARTCOUNT AI Analyticsは何が違うのですか?
From Creation To Selection: ユーザーの煩わしさを減らし、精度を上げます。
そこで、HEARTCOUNTはまさにこのような問題、つまり市場の期待と実際のLLMが提供できる成果物とのギャップを埋めるために、AIデータ分析(AI Analytics)機能である HERATCOUNT Dialogue を発表しました。
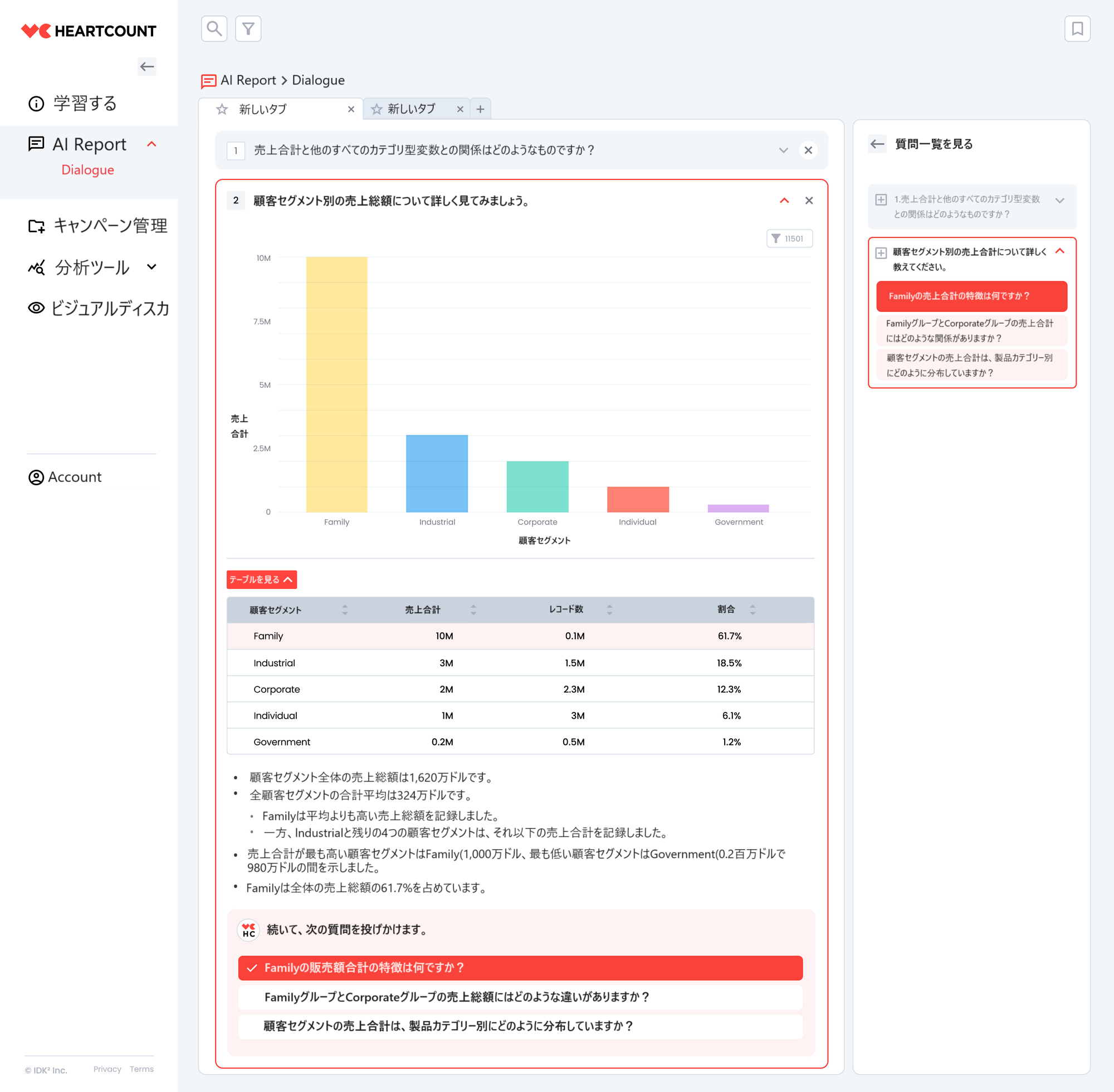
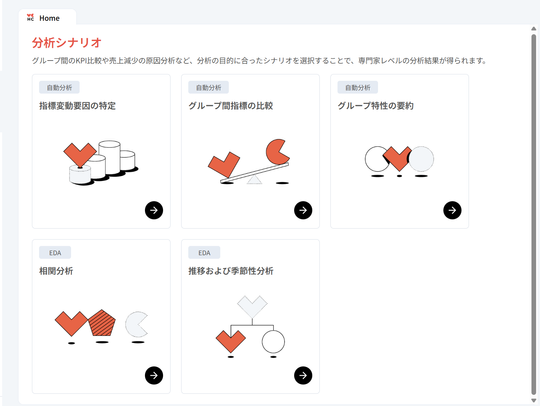
- Dialogueは、ユーザーの前に Blank State (白紙)を提供する代わりに、与えられたデータに対して分析的に適切な選択肢(分析の質問) を直接提示することで、ユーザーの煩わしさを解消し、質問を思い浮かべることから始まる認知的負荷(cognitive overload)を減らしたいと考えています。(1番目から2番目のステップ)
- また、ユーザーが選択した質問に対して適切な可視化結果と解釈を導き出してユーザーに提供します。結果の導出は、すでに既存の HEARTCOUNT が保有している明確に定義された視覚化/分析エンジンを活用し、エラーが発生しません。(3、4番目のステップ)
- 特に、解釈を導き出すことはLLMの力を借りずに、独自の自然言語分析モデル(ALM, Analytical Language Model)を活用しました。質の高いデータ分析レポートを参照し、現在の選択肢に対する最適な分析的解釈、注目すべき事実を識別して導出するモデルです。LLMのトランスフォーマーアーキテクチャーが根本的に抱いているハルシネーション現象の発生可能性はありません。また、難しい用語を使用することを最大限防止し、ビジネスの用語として開発することで、誰でも簡単に理解して活用することができます。
HEARTCOUNT AI Analytics, Dialogue は、2024年6月中にリリースされる予定です!
HEARTCOUNT AI Analytics、これからがより楽しみです!
分析結果(視覚化、サマリー)の精度と信頼性がデータ分析の重要な核心の一つであることを考慮して、HEARTCOUNT のAI分析機能である Dialogue の核心価値である成果物を生成し、結果をテキストでサマリーするプロセスは、当社の分析言語モデルである Analytical Language Model の手に今後も委ねる予定です。
だからといって、LLMを完全に否定するわけではありません。ただし、LLMが得意なこと(言語能力)とそうでないこと(分析的推論)をよく区別し、得意なことをよりよくできるようにすることを目指しています。そこで、今年の残りは次のような方向に Dialogue をさらに発展させ、改善していく計画です。
自分のデータとドメインに適した分析で
Notionが成功したのは、おそらく製品に付属している多数のテンプレートが一役買っていると思います。Dialogue が投げかける質問は、現時点ではドメインとは無関係のユニバーサルなテンプレートですが、今後はドメイン固有の質問を提示するレベルまで進化していくでしょう。
- この部分でLLMを積極的に活用することができると思います。Dialogue が現在保有している、そして今後さらに充実する質問のリストをユーザーのデータセットに合うように言い換える(rephrasing) ことができるようになります。データセットの列名やカテゴリ変数などは、ドメインの言語的なコンテキストをLLMに伝えることができる良い情報になります。
- また、ユーザーが Dialogue を通じた分析のプロセスで行う選択の道をさらに改善していきます。プロセスとしてのデータ分析(分析レポートの作成)は、数多くの選択の連続です。ユーザーが選択するデフォルトの選択をメトリックツリーの観点から、よりスマートに改善していく予定です。例えば、もし与えられたデータでユーザーが現在関心のある指標(metric)が「売上」であれば、LLMの言語理解能力はこれと因果的に関連性がありそうな他の指標の因果関係を「予想」することができます。例えば、以下のようにです。

あなたの迷いだらけの質問を素晴らしい分析に
上記の1番目から2番目のステップ、つまりビジネス質問を分析の質問に置き換えるプロセスは、ユーザーのビジネス言語をよく理解し、分析の質問に置き換える言語的理解が必須であり、LLMの言語能力はこの部分で大きな力を発揮できると思います。
- 今後はユーザーがビジネス言語で直接入力する質問を受け入れて、それをDialogueが提示する分析の道、分析的に適切な分析の質問への変換の役割をLLMがしっかり果たしてくれることで、自分の漠然とした質問が自分のドメイン/ビジネス的に適切な答えにつながる、guided journeyの経験をユーザーに提供したいと考えています。
- さらに現在は Dialogue が提示する分析の長さが制限されており、自分のドメイン/データセットに合った正解を得るための道には見えないかもしれません。そのため、徐々に様々なドメインに適したjourneyを広げていき、また、ユーザーが直接自然言語で入力した質問に対する回答を提供する部分まで開発していきます。
インサイトからレポート作成まで
Dialogue を通じて到達した結論をユーザーのビジネスコンテキストに合わせてうまく活用するためには、分析の結果をビジネスの言語に落とし込む必要があります。
- 単純に「ある地域で売上が異常に低い」という結果自体は単に事実を述べたもの(fact statement)ですが、「その地域で追加的なプロモーション活動や点検活動が必要」などの実用的なインサイト(actionable insight) まで導き出されれば、データ分析は明確な価値を持つことになります。
- もちろん、これはアルゴリズムや言語モデルに完全に依存することができない、ドメインとビジネスに対する「勘」が不可欠な部分です。ただし、そのような決定と判断を下すのに役立つように、Dialogue を通じて分析した fact statement (定量的領域、正確性/信頼度重要)を総合(synthetization)し、データセットドメインに適したインサイトを整理(定性的領域、言語能力が重要) する部分では、LLMが大きな威力を発揮することができます。
- 結果として、Dialogue で正確かつ信頼性の高い生成された fact statement → fact statement を総合して、ドメインに適した整理されたインサイトまで、ユーザーが簡単かつ迅速に到達できるようにすることが目的です。その上で、ワードプロセッサなどの形で、その内容をまとめたデータ分析レポートのドラフトを提供することができればなおさらです。
おわりに
HEARTCOUNTの新しい AI Analytics 製品である HEARTCOUNT Dialogue は、データ分析の民主化に向けた重要な一歩を踏み出しました。今後、HEARTCOUNT Dialogue の正確で信頼性の高い分析的推論能力とLLMの言語能力が統合され、あなたが抱いた漠然としたビジネス上の質問が有用なインサイトやレポートまで到達できるように、あなたの分析の旅(journey)をよく導いて(guide)くれます。これにより、データ分析が専門家の専有物ではなく、95%に含まれるあなたに開かれたツールになることを期待しています。
![[因果推論1] Potential Outcome Framework (潜在的結果フレームワーク)](/ja/content/images/size/w360/2024/06/----------------------5.png)