DeepSeek-R1(ディープシーク-R1)とはなんですか?
DeepSeek-R1 は、中国の人工知能スタートアップである『DeepSeek』が オープンソースとして公開 した生成型AIモデルです。特に、R1はOpenAIの最新モデルである o1 と同様の 推論型言語モデル です。
DeepSeek は、R1モデルを発表する以前にも V3、VL2 など様々なモデルをオープンソースとして公開してきました。

ディープシーク-R1(DeepSeek-R1)がここまで話題になっている理由は何でしょうか?
最も重要なポイントは以下の3つです。
- 非常に低コストで訓練されたモデル(と主張されている)であること
- OpenAIの最新の推論型モデル「o1」と同等の性能を示したこと
- オープンソースとして公開されたこと
以下は論文に掲載されている性能テストの結果です。
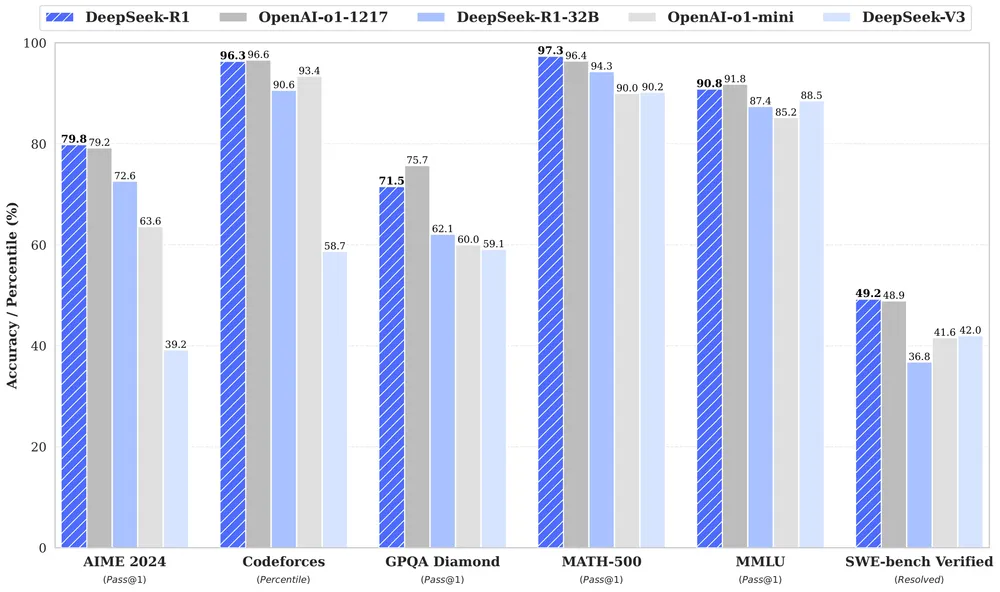
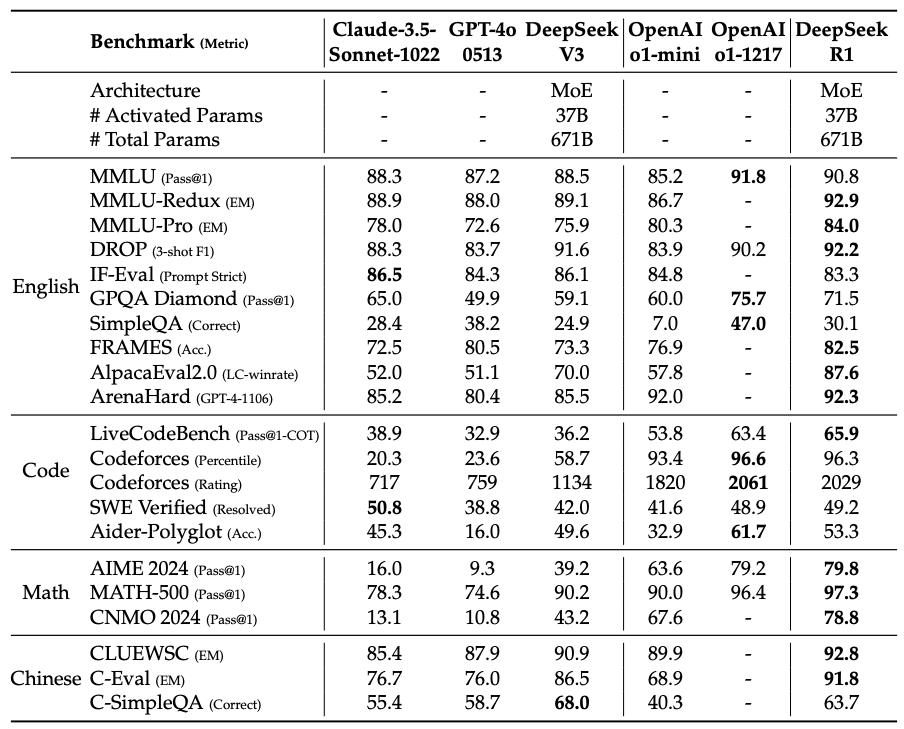

注釈:
MATH-500:AIの汎用的数学力(理論・証明含む)を幅広く見る
AIME 2024:AIが競技レベルの数学にどれだけ対応できるかを見る
LiveCodeBench:AIが実行可能なコードをどれだけ正確に書けるかを見る
このレベルのモデル学習にかかった開発費はわずか557万6000ドル(約8億円)で、OpenAIのGPT-4開発費の18分の1以下と言われています。
さらに注目すべきは、学習に使用されたGPUがNVIDIAのH100ではなく、性能の劣るH800およびHuawei製などの中国製チップ2000枚だけで学習されたという点です。
この発表によりビッグテック関連株は大きく下落し、依然として弱気相場が続いています。
特にNVIDIAの株価が下落した理由は、「もう高価なチップを使わなくてもOpenAI並みの性能が出せるのか?」という認識が市場に広まったからです。
ただし、最近SemiAnalysisというメディアが発表した資料によれば、この費用はあくまで事前学習コストのみを示しており、研究開発(R&D)、インフラ構築、運用コストなどの重要要素が除外されている可能性があるとの指摘もあります。
参考リンク:https://zdnet.co.kr/view/?no=20250203150355
1.企業が(比較的)低コストでOpenAI水準のファウンデーションモデルを開発できる可能性が出てきた点
2.DeepSeekがモデルをすべてオープンソースで公開したことで、既存の商用モデルの高額な有料APIビジネスモデルに打撃が避けられない点
3.セキュリティ上の理由で社内で言語モデルを使用できなかった企業も、OpenAI水準のオープンソースモデルを社内ネットワークで活用できるようになった点
DeepSeek-R1はどのように動作・訓練されたのか?
強化学習(Reinforcement Learning)で訓練されたDeepSeek
DeepSeek-R1は、単に学習データのパターンを模倣する従来の言語モデルとは異なり、"chain-of-thought"(思考の連鎖)と呼ばれる複数段階にわたる推論プロセスを自ら生成・洗練できる、最近注目の推論型モデルです。
最大の特徴は、従来のモデルが主に「教師あり学習(Supervised Fine-Tuning, SFT)」に依存していたのに対し、DeepSeek-R1は大規模な強化学習(Reinforcement Learning)を活用している点です。
(※ただし、この表現には少し語弊があるかもしれません。詳細は以下で説明します)
DeepSeek-R1は、教師ありファインチューニングを前提とせず、強化学習のみで推論能力を習得し、非常に高い性能を発揮しています。
Supervised fine-tuning(教師あり学習)は、従来のすべてのモデルが事前学習で用いていた方法です。簡単に言えば、あらかじめ用意された「正解集(初期データ)」をモデルに与え、それを正しく当てられるように訓練する方式でした。その後、人間がモデルの出力に対してフィードバックを与えることで、さらに性能を向上させていきました。
ところが、R1の場合、ファウンデーションモデルに対して強化学習の手法を用いることで、教師あり学習と同等レベルの性能を達成したのです!
強化学習とは?
囲碁AI「AlphaGo」などで使われた機械学習の一種で、以下のような流れで学習が行われます:
- 正しい答えを出したときに「報酬」を与える(例:「問題1つ正解したらキャンディ1個あげる!」)
- モデルはこの報酬を最大限得ようとして自己訓練を繰り返す(例:「20問正解したらキャンディ20個じゃん!」)
R1の学習プロセス
- DeepSeek-R1-Zero(初期推論モデル)
- 訓練方法:
ファウンデーションモデル(DeepSeek‑V3‑Base)に対し、SFTなしで「Group Relative Policy Optimization(GRPO)」などの手法を用いた強化学習のみで訓練。 - 特徴:
この手法により、モデルは自然と強力なchain-of-thought推論と自己検証(self-verification)能力を身につける(とされています)。 - 問題点:
事前に整えられた例や形式化されたデータでガイドされていないため、出力結果が反復的、読みにくい、多言語が混在するなどの問題が発生する可能性があります。
- 訓練方法:
- DeepSeek-R1(最終モデル)
- 中間段階:
R1-Zeroの出力品質問題を改善するため、「コールドスタート」データ(標準化されたchain-of-thoughtプロンプト付き)を使ってSFTを一部実施。
※この段階で教師あり学習が使われていますが、R1-Zeroの訓練には使用されていません。 - 最終的な強化学習:
フォーマットや正確性に加えて、出力の一貫性(例:英語や中国語中心の学習によって他言語指示でも英語で出力される)や有用性(helpfulness)も評価指標に含めてさらなる強化学習を実施。 - 結果:
R1-Zeroの強力な推論能力を維持しつつ、より読みやすく一貫したアウトプットを実現した実用的なモデルが完成。
- 中間段階:

既存のLLMとの違い
従来の大規模言語モデルが使用するRLHF(Reinforcement Learning from Human Feedback)は、主に教師あり学習(SFT)の後に、実際のユーザーや専門家からのフィードバックを基に、モデルの出力を安全かつ適切な方向へと調整することを目的としています。
まず、大量の精錬されたデータを用いて基本的な言語能力を学習させた後、
人間が提供した評価データを通じて、モデルの応答が望ましい方向へと調整されるように強化学習を適用します。
一方で、DeepSeek-R1は単に最終的な正解を導くことを目的とするのではなく、
問題を複数の段階に分けて、自ら推論プロセスを構築し、それを検証する能力を身につけるように設計されています。
初期段階であるR1-Zeroでは、教師あり学習を一切行わず、GRPOのような純粋な強化学習手法のみを用いて、この推論プロセスを自律的に発展させることを目指しています。
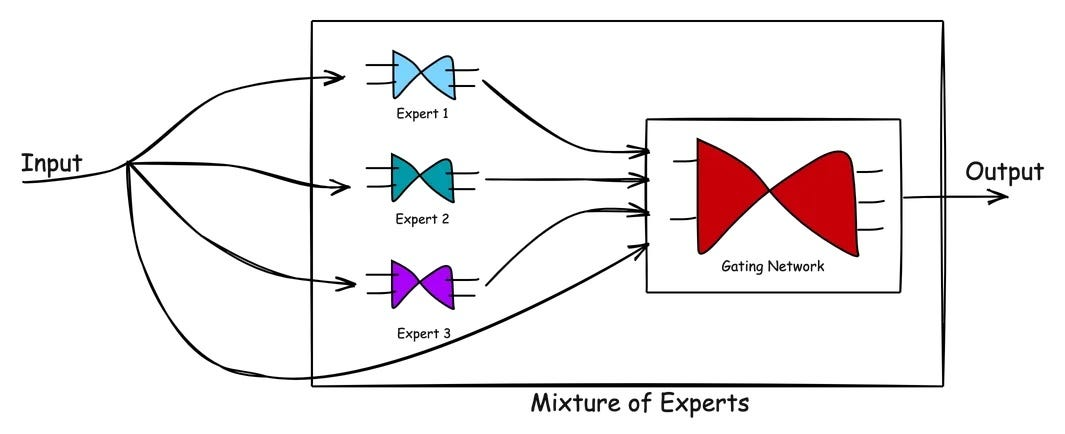
Mixture of Experts (MoE) 構造
R1-Zeroのパラメータ数はなんと6710億(671B)ですが、実際の利用時には37Bパラメータしか活性化されません。
つまり「必要なときに必要な部分だけ使う」という仕組みです。これを「Mixture of Experts(専門家の混成)」方式と呼びます。
https://newsletter.languagemodels.co/p/the-illustrated-deepseek-r1
DeepSeek-R1はどう使えるのか?
すべてのモデルはHuggingFaceにてオープンソースで公開されています。
特に軽量モデルについてはすぐにダウンロードして使えるようになっており、「ディスティルドモデル(distilled model)」とも呼ばれます。これは大きなモデルの知識を小さなモデルに圧縮したものです。
例えば32Bモデルは、OpenAIのo1-mini相当の性能があるとされています。
Chatバージョンはこちらから試すことができます:
https://chat.deepseek.com/sign_in
※セキュリティ上の懸念がある点にはご注意ください。
LLM開発コミュニティ・企業の反応
オープンソース化されたことにより、多くの企業や開発者がさまざまな試みを行っています。
例えば、Unslothという企業は最小構成のモデルに対し、「Dynamic Bit」方式を適用したモデルを公開しました。
R1(671B)のモデルサイズを720GBから131GBへと、約80%削減したというのです。
特定レイヤーは4bit、それ以外は1.58bitで圧縮しているとのこと。
今後もオープンソース界隈では、R1モデルを使った追加ファインチューニングや最適化が進み、より高効率なモデルの登場が期待されています。
データ分析市場に与える影響は?
これまで見てきたように、推論型モデルはAIおよび言語モデル市場における核心技術であり、今後の方向性を示すものとして高く評価されています。
特に、正しい推論を通じて正確な答えを導き出す必要がある「データ分析」の領域では、その影響力は非常に大きいと言えるでしょう。
しかしながら、国内市場では多くの企業がセキュリティ上の懸念から、商用モデル(OpenAIのAPIなど)の導入を敬遠しているのが現状です。
一部の企業では自社モデルの開発やプライベートLLM構築を試みていますが、
「最低でもChatGPT-o1レベルの性能は必要だよね」というように、求められる性能水準がすでに非常に高く、
その期待に応えきれていないという課題もあります。
こうした状況において、オープンソースとして公開された推論型モデルが商用モデルと同等レベルの性能を示すならば、話は大きく変わってきます。
データの外部流出を心配することなく、社内ネットワークや社内サーバー環境で高性能な推論モデルを活用できるようになれば、
今後、企業におけるデータ分析の地平は飛躍的に広がっていくことが期待されます。
さらに、オープンソース市場における競争もこれまで以上に激化していくことが予想されます。
加えて、DeepSeek-R1の公開直後には、OpenAIがさらに進化した推論モデル「o3」を限定公開したことも注目に値します。
推論モデルを活用したデータ分析の未来が、まさに大きく動き出そうとしているタイミングと言えるでしょう。
HEARTCOUNTは、個人から企業まで、用途に応じて柔軟に活用できるデータ可視化・AI自動分析ツールです。まずは無料で、その効果を体感してください。
※HEARTCOUNTは、DeepSeek-R1のAPIは使用しておりません。
出典・参考資料の一覧:




 InvestR
InvestR