こちらのブログではデータ分析にとって非常に重要になる、基本的なデータの型・タイプについての説明です。統計、機械学習などを活用したデータ分析を行う場合、ここに書かれているデータの型の理解が非常に大事になります。
カテゴリ型データ - 名義型(Norminal), 順序型(Ordinal)
まず、カテゴリ型(Categorical)データ(変数)は大きく名目型(Nominal)と順序型(Ordinal)に分けられます。
Nominal Data (名目型データ)
- nominal dataは、nameの形容詞であるnominalという修飾語が示すように、カテゴリ型変数に属する個々の値(水準・classと呼ばれる; 例として、チームというカテゴリ型変数に属する青チーム、白チーム、赤チームのような個々の値)に固有の優劣や順序がなく、お互いを区別する用途しかない場合です。
- nominal dataにたった二つのclass(男/女あるいはYes/No)しか存在しない場合、binary data(2値データ)と呼びます。
Ordinal Data (順序型データ)
- カテゴリ型変数(データ)に属する個々のカテゴリ(class)間に明らかな順序がある場合、ordinal dataといいます。
- 例えば、「評価等級」というカテゴリ型変数に(5, 4, 3, 2, 1)という値が含まれていて、その数値が「5.非常に高い。4.高い。3.中立、2.低い。1.非常に低い"という意味であれば、その変数は数値型変数ではなく、異なるカテゴリ間の順序(優位性)を持つカテゴリ型変数として扱う必要があります。
- ちなみに、数字で表現された順序型変数に対して平均を計算してはいけないという見解があります。これは、非常に高いに5を、高いに4を割り当てるとき、それぞれの数字(5、4)に(5000円、4000円の場合のように)厳密な数学的/科学的な意味と差があるわけではないからです。
数値型データ - 離散型(discrete)、連続型(continuous)
数値型(Numerical)データ(変数)は大きく離散型(discrete)と連続型(continuous)に分けられます。しかし、実務の文脈で両者の区別はあまり重要ではないので、参考程度にしてください。
Discrete Data(離散型データ)
測定された変数の値が整数でぴったり落ちる場合(例えば、年齢(歳): 20, 21, 22,... or 顧客数(人): 520, 435,...) を離散型データといいます。
Continuous Data(連続型データ)
連続した無数の値のうちの一つの値を取ることができる場合(例えば、温度(度): 21.4, 25.7) 連続型といいます。
データ型分類のサンプル
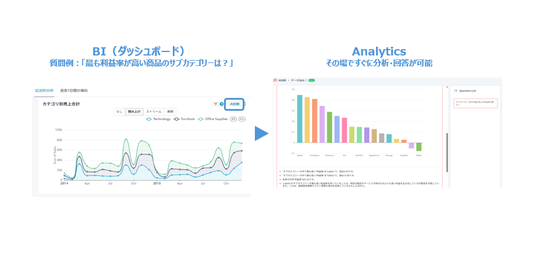
HEARTCOUNTでは、分析のための最適なデータタイプを自動的に分類してくれます。以下の内容を参考にしていただき、HEARTCOUNTにログインしてください。
💡
参考:"interval" と "ratio data"伝統的な統計学の教科書では数値型変数を区別するタイプとしてintervalとratio typeを一緒に紹介します。実務の文脈ではあまり重要ではない区分法ですが、参考までに下記にまとめました。ratio data (比率データ)• 現在時刻が13:30なのに、私が時計を見て13:00から計算して"30分"待ったねと言うとき、"30分"はratio dataである。• ratio dataの場合、interval dataと違って絶対的な原点(meaningful zero point)が存在し、interval dataで00:00という値は(待った時間が)"0"秒という意味です。• 年齢、お金、体重のようなデータ(変数)がratio dataとして扱われます。interval data (間隔データ)• データの連続した測定区間の間隔が同じ場合、interval dataと呼ぶ。(11:00と11:05の差は15:55と16:00の差と同じ; なぜなら、毎分は60秒だから)• ただし、絶対的な原点(zero point)がない。どういうことかというと、00:00という値は測定した時間の値がないのではなく、ただ真夜中に時間を測定したという意味です。年齢(age)を例に挙げると、年齢は基本的に数値型変数であり、discrete(離散型)とratio(比率型)タイプに分類することができます。しかし、私たちが年齢を年齢層で収集/加工する場合(例えば、21~25歳、26~30歳、31~35歳)、年齢は年齢層という順序型カテゴリ型変数になることもあります。
🤍