こんにちは!HEARTCOUNTチームでAnalytics Engineeringを担当しているJadenです。
- データアナリスト(DA、BA、PA)、BIエンジニア、アナリティクスエンジニアの方。
- DWH、DMからデータを抽出してデータの可視化をしたり、EDAやモデリングを行う方。
運用系、分析系: その違いとは?
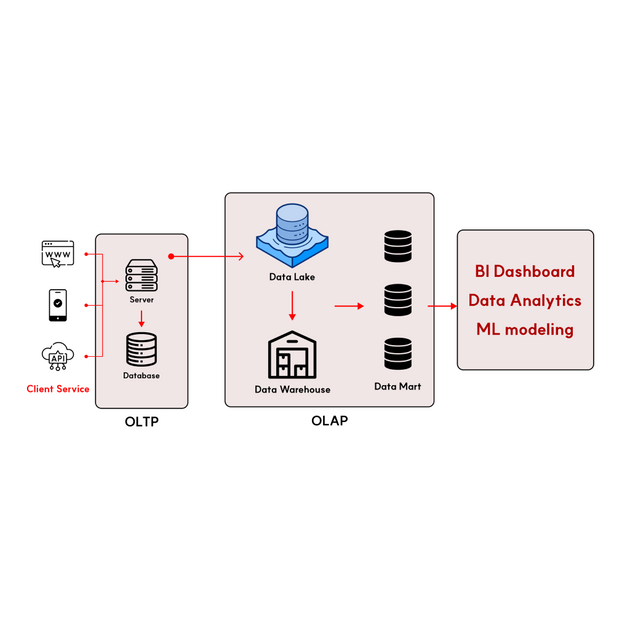
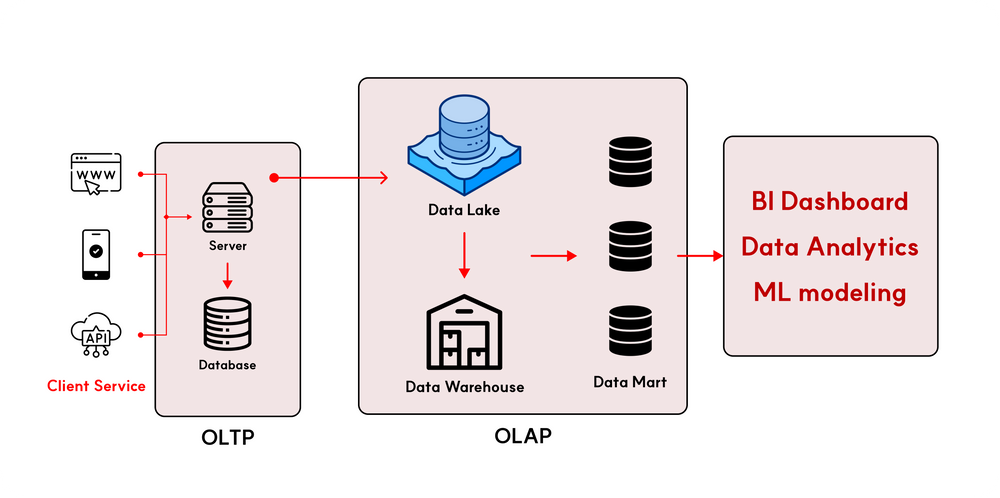
Database (DB: データベース)とData Warehouse (DWH: データウェアハウス)の違いを知るには、まず、データ管理システムがOLTP(運用系)とOLAP(分析系)に分かれていることを知っておく必要があります。
1.運用系システム (Operational Systems)
運用系のシステムは、組織の日常的なビジネスプロセスとトランザクションを支援します。
このようなシステムは、リアルタイムのデータ処理に重点を置いており、データの作成、更新、検索、削除などの基本的なデータ操作を迅速に処理できる必要があります。
例えば、オンライン販売システム、顧客管理システム、在庫管理システムなどが運用系システムに該当します。
これらのシステムはOLTP (Online Transaction Processing)の操作に最適化されており、データベース管理システム(DBMS)を使用して運用データを管理します。

2.分析系システム (Analytical Systems)
分析系のシステムは、大規模なデータを分析して組織の意思決定プロセスを支援することに重点を置きます。
これらのシステムは、DWH(データウェアハウス)を含む、履歴データや様々なデータソースから収集された情報を統合・格納し、それを分析するために使用されます。
分析系システムはOLAP (Online Analytical Processing)の操作に最適化されており、複雑なクエリ処理や大規模なデータセットの集計、分析を実行する機能を提供します。
それでは、上で登場したOLPTとOLAPの違いについて、詳しくみてみましょう。
OLTPとOLAPの違い
OLTP (Online Transaction Processing)
OLTPは「オンライントランザクション処理」を意味し、主にユーザーのトランザクションをリアルタイムで処理するために最適化されたシステムです。このシステムは、入力、修正、削除といった操作が頻繁に行われる運用系システムで使用されます。
銀行取引、オンライン注文、予約システムなどがOLTPの典型的なユースケースです。
OLTPシステムは主に行指向(row-oriented)データベース構造を使用し、各データ行はメモリに連続して格納されます。
この構造は、INSERT、UPDATE、DELETEなどのトランザクション操作を迅速に処理できるようにし、トランザクションの迅速な処理とデータ整合性の維持に重点を置いています。
行ベースのデータベースは、それぞれのトランザクションが個々のレコードに対して実行される場合に効率的であり、複雑なトランザクション管理、並行性制御、ロールバックおよび復旧機能を提供します。
OLAP (Online Analytical Processing)
OLAPは「オンライン分析処理」を意味し、大量のデータを分析してビジネスインテリジェンスを提供するために使用されます。
OLAPは主にデータウェアハウス環境で使用され、履歴データの分析、複雑なクエリの処理、レポートの生成、予測分析の実行に適しています。
OLAPシステムは主に列指向(column-oriented)データベース構造を使用し、データを列単位で格納します。
この構造は、分析クエリが特定の列のデータを一括でスキャンしたり集計する場合に非常に効率的です。OLAPは、大規模なデータセットに対する迅速な応答時間、多次元分析、データウェアハウスでの使用といった目的に合わせて最適化されています。
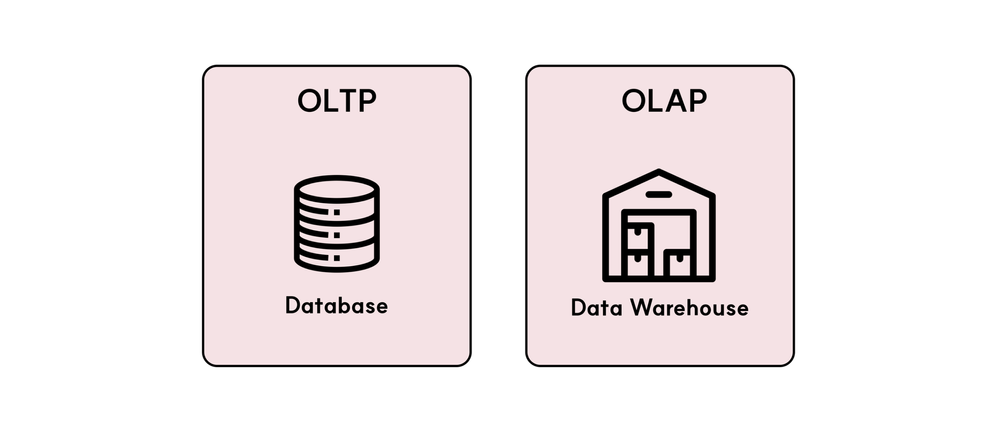
整理すると OLTP → Database、 OLAP → DWH
最終的にまとめると以下のようになります。
| 特性 | Database | Data Warehouse |
|---|---|---|
| 定義と目的 | リアルタイムデータの格納、管理、検索のためのシステム。日常業務の トランザクション 処理と運用データの管理に使用。 | 様々なデータソースから収集された情報を統合、クレンジング、格納する 大規模なデータストア。分析、レポート作成、BI、意思決定のサポートにフォーカス。 |
| 主な機能 | 行ベース ストレージ、リアルタイム処理、データ整合性の維持 | 列ベース ストレージ、履歴データ分析、データ統合、品質管理 |
| 適用例 | 顧客管理システム、オンライン販売プラットフォーム、在庫管理システム | 市場動向分析、顧客行動分析、ビジネスパフォーマンスのモニタリング |
| 最適化 | OLTP (Online Transaction Processing)に最適化 | OLAP (Online Analytical Processing)に最適化 |
データベースは主にリアルタイムトランザクション処理に適しており、データウェアハウスは大規模なデータ分析やレポート作成向けに設計されています。
データベースとは何ですか? その種類は?
データベースとは、構造化された情報もしくはデータの集合です。構造化されているため、ユーザーはデータを効率的に検索、更新、管理することができます。ご存じの方も多いと思いますが、代表的なデータベースの種類としては、RDB、NoSQLがあります!
1.リレーショナルデータベース(RDB)
データをテーブルで構成し、それらのテーブル間に定義された関係に基づいてデータを整理したものです。
各テーブルは列と行で構成されており、特定のルールに従ってデータの整合性を保証します。
とても難しい言いまわしですが、単に表形式でデータを管理することです。スプレッドシートと同じ構造でデータを管理することです。伝統的な方法です。
私たちはこれをかっこよくRDB(Relational Database)と呼んでいます。
RDB、つまり、リレーショナルデータベース(Relational Database)が「リレーショナル」と呼ばれる理由は、データをテーブル(table)形式で格納し、これらテーブルの間で定義された関係(relationship)を通じてデータを組織化するためです。
RDBはSQL(Structured Query Language)を使ってデータを管理します。
SQLを使ってデータを挿入(insert)、照会(select)、修正(update)、削除(delete)するといった操作をすることができます。SQLの強力なクエリ(query)機能のおかげで、複雑なデータ分析と管理が可能なのです。MySQL、PostgreSQL、Oracle DatabaseがRDBを管理するDBMSのカテゴリーに属します。
データベース管理システム(DBMS)は、データベースを管理するためのソフトウェアツール群です。
これもより簡単に表現すると、
表形式のスプレッドシートを管理するツール
- MSのExcel
- GoogleのGoogle Sheet
- AppleのNumbers
のような複数のソフトウェアと同様のものと考えてください。
RDBMSの代表的なものとしては、
- Oracle Database
- MySQL
- PostgreSQL
などを挙げることができます。
2.NoSQLデータベース
NoSQLデータベースは、リレーショナルデータベースとは異なり、固定のスキーマを必要とせず、様々なデータ形式を格納できる柔軟なデータストレージです。
「Not Only SQL」の略で、SQLに依存しない様々なデータストレージ技術を網羅しています。
では、なぜNoSQLは登場したのでしょうか? NoSQLが登場した背景について紹介します。
NoSQLデータベースが必要な理由と背景を理解するためには、まず、従来のデータベースシステムであるリレーショナルデータベース(RDBMS)の限界を確認する必要があります。
リレーショナルデータベースは厳密なスキーマ(データ構造)に従わなければならず、データはテーブルに格納されます。
このシステムは、一貫性、整合性、複雑なクエリのサポートのために最適化されています。
しかし、デジタルデータの量が爆発的に増大し、Webやモバイルアプリケーションの登場でデータの形式や活用方法が多様化し、従来のリレーショナルデータベースではそれらの要件を満たすことが難しくなりました。
リレーショナルデータベース(RDBMS)の限界のポイント
- データ量の爆発的な増加: ソーシャルメディア、IoT(モノのインターネット)デバイス、オンライン取引などで発生する膨大な量のデータを処理するには、より柔軟でスケーラブルなデータストレージソリューションが必要でした。
- 多様なデータ形式: リレーショナルデータベースは主に構造化されたデータに適していますが、現代のアプリケーションは非構造化データ(テキスト、画像、動画など)や半構造化データ(JSON、XMLなど)を扱うことがよくあります。これらのデータを効率的に管理するためには、より柔軟なデータモデルが必要でした。
- 迅速な開発と変化に対するニーズ: アプリケーションの迅速な開発と継続的な更新のためには、データスキーマの変更が容易でなければなりません。リレーショナルデータベースのスキーマを変更することは、多くの場合、複雑で時間のかかる作業です。
- 拡張性: 膨大な量のデータを処理し、世界中のユーザーに迅速なアクセスを提供するためには、データベースを複数のサーバーに分散して拡張できる必要があります。リレーショナルデータベースでは、このような水平方向の拡張に制限があります。
このような限界を解決できるNoSQLの特徴についてまとめると以下のようになります。
NoSQLの主な特徴
- 柔軟なスキーマ: NoSQLデータベースは柔軟なスキーマを提供し、様々な形式のデータを簡単に格納・管理することができます。
- 拡張性: ほとんどのNoSQLデータベースは水平方向の拡張性をサポートし、データ量の増大に対応してデータベースを簡単に拡張することができます。
- 高性能: 特定のタイプのデータモデルに最適化されており、高速な読み書き操作をサポートします。
- 多様なデータモデルをサポート: キーバリュー(key-value)、ドキュメント、グラフ、列ベースなど多様なデータモデルをサポートし、アプリケーションの要件に合わせて選択することができます。
NoSQLデータベースは大きく以下の4つのタイプに分類することができます。
- ドキュメント(Document)、 例: MongoDB
- キーバリュー(Key-Value)、 例: Redis
- 列(Column-family)、 例: Cassandra
- グラフ(Graph)、 例: Neo4j
NoSQLデータベースのタイプ
- ドキュメント指向(Document-oriented)データベース: データをJSON、BSON形式のドキュメントとして格納します。各ドキュメントは柔軟なスキーマを持ち、複雑なデータ構造を簡単に表現することができます。例: MongoDB、Couchbase
- キーバリュー(Key-Value)ストア: 単純なキーと値(バリュー)をペアで格納する最も基本的な形式のNoSQLデータベースです。高速データ検索に便利です。例: Redis、DynamoDB
- 列ベース(Column-family)ストア: 大規模な分散環境で高いパフォーマンスと拡張性を提供し、データをカラム(列)ファミリー単位で格納します。ビッグデータ分析に適しています。例: Cassandra、HBase
- グラフ(Graph)データベース: エンティティ間の関係をグラフ形式で格納し、複雑な関係を効率的に探索することができます。例: Neo4j、Titan
ソーシャルネットワーク、リアルタイム位置情報サービス、ビッグデータ分析など様々な分野でNoSQLデータベースが活用されています。
例えば、ソーシャルメディアアプリケーションでは、ユーザーとその関係性を効率的に管理するためにグラフデータベースを使用することができます。また、Webアプリケーションのセッション情報をすばやく処理するために、キーバリュー(Key-Value)ストアを活用することもできます。
さて、ここまでDatabaseについて説明しました! 次はData Warehouseについて説明します。
Data Warehouseとは何ですか?

データウェアハウス(Data Warehouse、DWH)は、企業や組織の様々なソースから収集したデータを統合、格納、分析するために設計されたシステムです。これは意思決定を支援するために不可欠な役割を果たします。
データアーキテクチャ(Data Architecture)とは? わかりやすく解説
DWHも最終的にはデータを表(Table)形式で格納するRDBです。しかし、Oracle、PostgreSQLのような従来のRDBMSとは異なります。
その違いは、データを格納する方法、つまり、行(Row)ベースと列(Column)ベースの構造上の違いにおいて特に顕著です。次の段落では、RowベースとColumnベースの違いについて詳しく説明します。
Rowベース vs Columnベース
OLAP DBのRowベースの構造
データベースは主にリアルタイムの取引処理と業務支援を目的としています。このため、データベースはRowベースの構造を採用することが多いです。
Rowベースの格納方式は、各行(row)が1つのレコードを表し、このレコードは様々な属性(column)から構成されます。
この方式は、リアルタイムでデータを追加、修正、削除するトランザクション処理に最適化されています。なぜなら、特定の取引や業務に関連するすべてのデータ属性にすばやくアクセスして変更することができるためです。
- データアクセスの局所性: Rowベースの構造では、関連するデータが物理的に隣接しているため、1回のディスクI/Oで必要なすべてのデータを読み込むことができます。例えば、顧客情報を更新したり、注文情報を照会する際、そのレコードのすべての情報(行)に簡単にアクセスすることができます。
- 書き込み操作の効率性: 新しいレコードを追加したり、既存のレコードを更新する際、そのレコードのすべての情報を連続したスペースに格納します。これにより、書き込み操作を簡素化し迅速に実行することができます。また、トランザクションログとともに作業を管理し、データの一貫性と復旧を容易にします。
OLAP DWHのColumnベースの構造
一方、データウェアハウスは分析と意思決定支援を主目的としており、大量の履歴データを格納・管理します。データウェアハウスは多くの場合、このような目的に適したColumnベースの構造を採用しています。
Columnベースの格納方式は、各列(column)が同じタイプのデータを含むため、大規模なデータセットに対するクエリ(query)を実行する際、必要なデータのみを選択的にスキャンして処理するのに効率的です。
これは、特に大量のデータから特定の属性に対する分析や集計を実行する場合にパフォーマンス上の利点を提供します。
- 選択的なデータアクセス: Columnベースの構造では、クエリが必要とする特定の列のデータのみを読み込んで処理することができます。大量のデータからいくつかの列のみを対象とする集計や分析作業を行う場合、不要なデータを読み込まないため、ディスクI/Oが大幅に減少します。
- データ圧縮の効率: 同じ列のデータは同じタイプであるため、データ圧縮が効率的に行われます。これにより、ストレージ容量を節約し、ディスクI/Oを削減することができます。また、圧縮されたデータはメモリ内でより高速に処理できるため、クエリのパフォーマンスが向上します。
正規化 vs 非正規化
データウェアハウス(DWH)とオンライントランザクション処理(OLTP)データベースは、データの管理・処理方法が根本的に異なります。
OLTPシステムは、データの冗長性を最小限に抑え、データの整合性を維持するためにデータを正規化します。これは、データを複数の関連するテーブルに分割し、それらのテーブル間の関係を定義することで実現されます。
一方、データウェアハウスは非正規化を採用することで、データ分析と照会プロセスを簡素化します。
ユーザーはデータにすばやくアクセスでき、複雑なクエリや多くのテーブル結合を実行することなく必要な情報を取得することができます。これにより、アナリストはより簡単にインサイトを得ることができ、迅速な意思決定を行うことができます。
スタースキーマは、中央のファクトテーブルとそれを囲むディメンションテーブルから構成され、データ分析やレポート作成を簡素化します。
スノーフレークスキーマは、より詳細なレベルでスタースキーマを正規化しますが、分析に最適化された構造を保持します。
「正規化を行わない」という言葉をより簡単な言い方で表現すると、データウェアハウスでは、データを格納する際に、情報を複数のテーブルに分割するのではなく、可能な限りテーブルとしてまとめておくという意味になります。
例えば、あなたが本をたくさん持っている図書館の管理者であると考えてみてください。図書館の訪問者が特定の書籍に関する情報(著者、出版年、ジャンルなど)をすばやく見つけたい場合、すべての情報を1か所にまとめておくと便利です。
- 正規化されたアプローチ(OLTPシステム): 本のタイトルはある本棚に、著者は別の本棚に、出版年は別の本棚に分類して保管します。これにより、スペースを効率的に使用することができ、重複を減らすことができます。ただし、ある訪問者が特定の書籍に関するすべての情報を知りたい場合、複数の本棚を巡回する必要があります。
- 非正規化されたアプローチ(データウェアハウス): それぞれの本に関するすべての情報を1冊の「情報集」にまとめます。この情報集には、本のタイトル、著者、出版年など、すべての情報が含まれます。これにより、訪問者は特定の本に関するすべての情報を1か所ですばやく見つけることができます。もちろん、同じ情報(例えば、同じ著者の別の本など)が複数の情報集で重複している可能性がありますが、情報を見つけるのははるかに高速で簡単です。
ビッグデータ分析用DWHにはどのようなソリューションがありますか?

クラウドベースのデータウェアハウス
| ソリューション | 説明 | 特長 |
|---|---|---|
| Google BigQuery | フルマネージドのサーバーレスデータウェアハウスで、大規模なデータセットの迅速な分析が可能 | サーバー管理不要、自動拡張、ストレージスペース最適化、リアルタイム分析をサポート |
| Amazon Redshift | フルマネージド、MPPデータウェアハウス、ペタバイト規模のデータ格納と分析をサポート | 高速なクエリパフォーマンス、拡張性、AWSエコシステムとの統合が容易 |
| Snowflake | クラウドベースのデータウェアハウス、柔軟なスケーリング、従量課金機能 | 使いやすさ、自動拡張性、ストレージとコンピューティングリソースの分離、多様なデータ形式をサポート |
| Azure Synapse Analytics | MPPデータウェアハウス、Azure Cloud Platformに統合された分析サービスを提供 | 高い拡張性とパフォーマンス、Azureエコシステムとの緊密な統合、セキュリティとコンプライアンス機能 |
| IBM Db2 Warehouse on Cloud | クラウドベースのMPPデータウェアハウス、多様なデータ形式の格納と分析が可能 | ロード時間の短縮、優れた拡張性とパフォーマンス、IBMクラウドサービスとの統合 |
オンプレミスのデータウェアハウス
| ソリューション | 説明 | 特長 |
|---|---|---|
| Oracle Exadata | 高性能データベースサーバーで複雑な分析や大規模なデータ処理が可能 | 優れたパフォーマンスと拡張性、統合されたハードウェアとソフトウェアシステム、セキュリティー機能 |
| Teradata | 大規模データウェアハウスソリューションで複雑なクエリや分析を迅速に処理可能 | 高いクエリパフォーマンスと並列処理能力、大規模データ処理、多様なデータ形式のサポート |
| IBM Db2 Warehouse | オンプレミス環境とクラウド環境の両方で利用可能なデータウェアハウスで、複雑な分析をサポート | 高いパフォーマンスとセキュリティ、柔軟な導入オプション、多様なデータソースのサポート |
| SAP BW 4HANA | 次世代データウェアハウスでリアルタイム分析や予測モデリングを提供 | 高度な分析機能、SAPエコシステムとの統合、大規模なデータ処理能力 |
| Microsoft SQL Server | リレーショナルデータベース管理システムで、幅広いエンタープライズクラスのデータウェアハウス機能を提供 | 広く使用され使い慣れたインターフェース、統合された分析・レポートツール、堅牢なセキュリティ機能 |
まとめ
今回は、データを扱う2つの重要なシステムであるデータベース(DB)とデータウェアハウス(DWH)について説明しました。
DBは日常的な業務処理とトランザクション管理のためのOLTP (Online Transaction Processing)システムで、データの正確性と迅速な処理が重要です。
一方、DWHはデータ分析と意思決定支援を目的とするOLAP (Online Analytical Processing)システムで、大量のデータを統合して複雑なクエリとレポートを可能にします。
DBとDWHの違いのまとめ
| 基準 | 運用系DB | 分析系DWH |
|---|---|---|
| 主な使用目的 | 日常業務におけるトランザクション処理 | ビジネス上の意思決定を支援する複雑なクエリや分析 |
| データ構造 | 正規化されたスキーマを使用して重複を最小化 | 非正規化されたスキーマ、多くの場合、スタースキーマ(Star Schema)またはスノーフレークスキーマ(Snowflake Schema)を使用してクエリのパフォーマンスを最適化 |
| クエリの複雑さ | シンプルで高速なトランザクション処理のための簡単なクエリ | 複雑なクエリ、大容量データに対する分析や集計 |
| データ更新頻度 | リアルタイムまたはほぼリアルタイム | バッチ処理による定期的な更新(日次、週次など) |
| 利用者 | フロントエンド・アプリケーション、カスタマーサービス担当者などの日常業務ユーザー | データアナリスト、ビジネスインテリジェンス専門家、意思決定者などの分析・レポート作成ユーザー |
| データ量 | 比較的小さい(GBからTBレベル) | 非常に大きい(PBレベルまで可能) |
| データの変更 | 頻繁な挿入、更新、削除操作 | 主に照会中心、データは定期的に追加される |
| 例 | ネットショッピングモールの受注処理システム、銀行の口座管理システム | 販売データ分析用データウェアハウス、市場動向分析用データマート |
今日も皆様のお役に立てれば幸いです。
"Everyone is an Analyst"、HEARTCOUNTチームのJadenでした!