AIはなぜ「知らない」のか?情報の価値と意思決定の質の関係
「AIは情報を知らないけれど、CEOは知っている」。
もしCEOが100の情報を知っていて、AIはゼロだとしたら──
AIがCEOのサポートを受けながら意思決定をする方が、AI単独で判断するよりもずっと合理的に思えますよね。
でも、ここで重要なのは「情報の量」ではなく、「情報の価値」や「文脈とのつながり」なのです。
たとえば、こういった問いに直面したとします:
「今月、売上が落ちてしまった。どうすればいいのか?」
このとき、ChatGPTのようなAIが、製品データや顧客情報、競合の動き、さらには社内のメール、Slack、レポート、ダッシュボードまで幅広く横断的に分析できたとしたら──
そのAIがCEOの意思決定を支えるどころか、CEOよりも的確な答えを導く可能性だってあるわけです。
つまり、CEOがAIよりも良い判断を下せるのは、「人間だから」ではなく、
質問の背景にある文脈を理解し、それに関連する情報へスムーズにアクセスできるからなんです。
ここで少し想像してみてください。
AIが社内の構造化データ(たとえばデータベース)だけでなく、非構造化データ(メールやメモ、議事録などのテキスト情報)にも自由にアクセスできるようになったら…?
そして、いま注目されている技術、
「無制限のコンテキストウィンドウ」や「RAG(関連情報の自動抽出)」といったAIの進化が加わったら──
果たしてAIは、CEOや社員の“勘”や“経験”を超えて、
組織全体で最適な意思決定を導き出す存在になり得るのでしょうか?
AIにとっての情報アクセスと「No True Scotsman」の論理
AIがどんな仕事もこなせないのは、「すべての情報に本当にアクセスできるわけではない」という事実に起因するという主張は、No True Scotsman(本物のスコットランド人ではない論法)に似ています。これは、「スコットランド人なら砂糖入りのおかゆなんて絶対に食べない」と言ったときに、実際にそれを食べるスコットランド人がいた場合、「それは本当のスコットランド人じゃない」と言い張るような論理です。つまり、自分の主張を守るために、都合の悪い事例を除外しようとする詭弁です。
このように、AI時代のビジネスインテリジェンス(BI)においては、「情報にどうアクセスできるか」と「その情報の文脈をどれだけ理解できるか」が、人間とAIの意思決定の質を大きく左右します。今後は、情報非対称性をいかに解消できるかが、企業の競争力に直結していくでしょう。
※参考:「良い意思決定」=「データドリブンな意思決定」
私たちは「結果が良ければ、それは良い意思決定だった」と考えることに慣れています。たとえば、同じ情報とプロセスで家を購入し、その後家の価値が上がれば「良い判断だった」とし、逆に値下がりすれば「悪い判断だった」と受け取ってしまいます。
しかし、「良い意思決定だったかどうか」は通常、結果が出た後にしか判断できません。しかも、その判断は本質的に限界があります。私たちはひとつの選択肢しか実行できないため、「選ばなかった別の選択肢がどんな結果をもたらしたか」は確認できないからです。
それでもなお、人類がデータを意思決定に活用してきた歴史は、証拠と事実に基づき、偶然と不確実性の影響を減らしてきた過程だと言えます。
因果関係の知識がなくても、「統計的な事実」によって世界を改善できるという信念によって、人々は「世界は制御不可能な混沌ではなく、分析可能な秩序を持つ構造である」と認識し始めました。
哲学者イアン・ハッキング(Ian Hacking)は著書『偶然を飼いならす(The Taming of Chance)』の中で、19世紀に統計学と確率論が発展したことにより、偶然は「測定可能で予測可能なもの」になったと述べています。収集・蓄積されたデータは政策決定や社会の管理に活用され、「管理可能な偶然(Governable Chance)」という考えが生まれました。
今や偶然とは、避けられない運命ではなく、数値として分析され、制御できる対象となったのです。
データの限界とデータ分析の限界
企業における「データに基づく意思決定」もまた、経営に伴う不確実性を減らし、業務を最適化しようとする取り組みの一つです。しかし、完璧なデータや情報にアクセスすることは現実的に不可能であり、そのため最終的な意思決定には、ある程度「人間の判断力」が関与するのが実情です。
このことが、「本当にデータは価値あるのか?」という疑問を生むきっかけにもなっています。
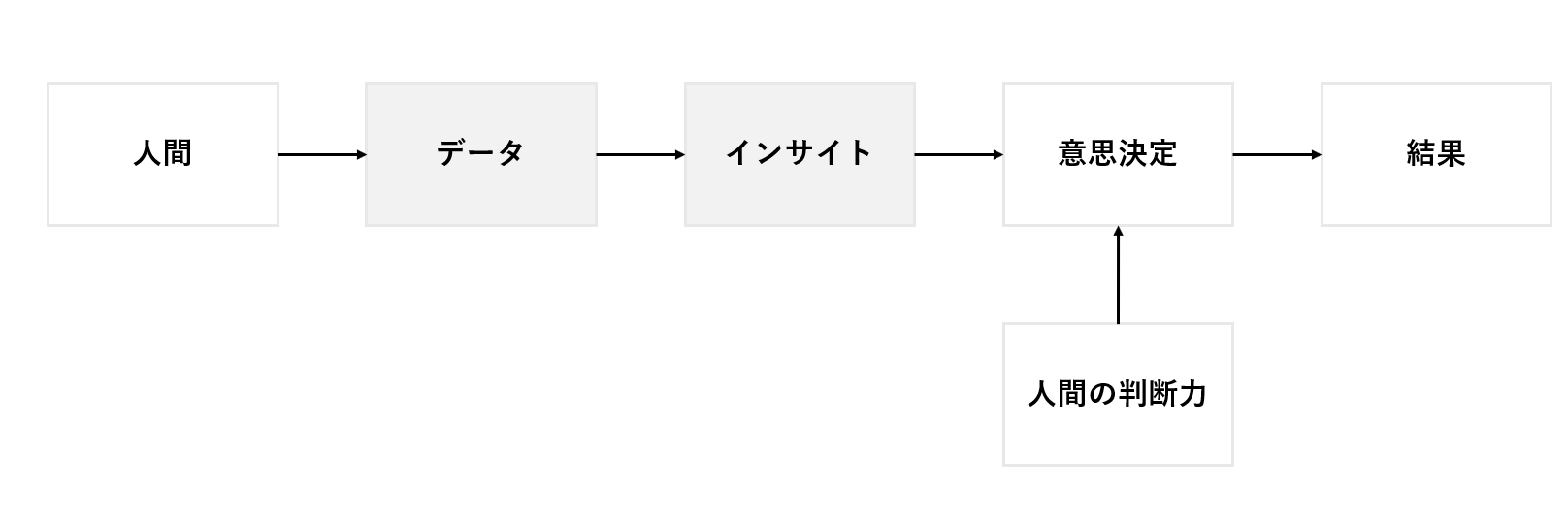
データを使った意思決定には、明確なメリットがありますが、完璧ではありません。ここでは「データそのものの限界」と「それを分析するプロセスの限界」に分けて考えてみましょう。
データの限界:その“理由のさらに奥にある理由”
たとえば、
- 今月の売上が前月より1.5億円減少
- A製品の売上が1億円(50%)減少
- その90%がB流通チャネルでの減少だった
これは企業内のデータに基づいた正確な事実です。
しかし「なぜBチャネルで売上が下がったのか?」と“理由の理由”を問い始めると、すぐに構造化データの限界に直面します。
たとえば、
- 製品の品質問題(VoC)
- プロモーションの縮小(予算上の都合)
などであれば、非構造化データ(報告書・チャットなど)を通じて、人やAIが理由を見つけられる可能性があります。
ところが、
- MDが陳列場所を変更した
- 商品が企画展示から外された
- 内部アルゴリズムが変わり露出が減った
といった「流通チャネル内の事情」になると、内部データからの把握は困難になります。
さらに、「なぜそのMDが方針を変えたのか?」という“理由の理由の理由”になると、それは人間の内面に属する領域であり、データに記録されることはまずありません。
(もちろん、AIが意思決定の中心になる未来においては、その“内面”自体が重要でなくなる可能性もあります。)
データ分析の限界:すべての仮説を検証するのは困難
「売上が1.5億円下がった」という事実を見て、BIダッシュボードを操作する担当者の頭には様々な仮説が浮かびます:
- 特定の地域で減少があった?
- 季節性の影響?
- 特定の営業部門やチャネルの成果が悪かった?
しかし、従来のBIツールはこうした仮説検証のためではなく、KPIなどのモニタリング目的で設計されています。
仮説を検証するには、関連する別データを抽出して、EDAツールやPython、AIツールなどで手動分析が必要です。
その結果、すべての仮説を検証することができず、いつもの見慣れた視点から判断を下してしまうのです。
組み合わせ爆発(Combinatorial Explosion):与えられた指標をスライス&ダイス(分割)して見る変数(列、次元)とその値の組み合わせが増えることで、検証すべき仮説の数が指数的に増えてしまう現象。 例:20商品 × 10地域 = 200通り。
人の限界がAIの限界
人が作ったデータ、分析手法、ツールを活用しなければならないAIにとって、人間の限界はそのままAIの限界となり得ます。
それでも、これまで一部の人しかできなかったことが、AIの支援で誰でも簡単にできるようになるなら、それは大きな前進です。
売上が落ちた、どうすればいい?(モニタリングから改善へ)
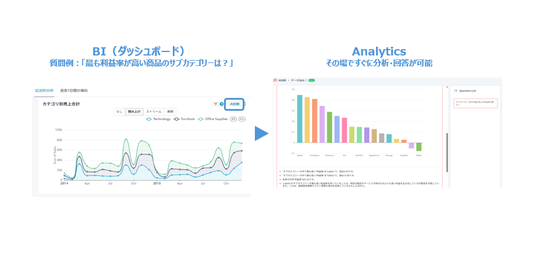
企業がデータを経営判断に活かす際、主に使われるのはBI(ダッシュボード)です。 BIは成果のモニタリングには適していますが、改善のためのアイデア発掘には向いていません。
では、AIデータ分析ツールがこの壁をどう超えるべきか? 筆者は、仮説の生成と検証の自動化が第一歩だと考えています。
指標の変動(Variation)を理解する:売上のような「指標の変動」を正しく理解することは、企業運営がある程度の安定状態(Equilibrium)にあるときに、非常に重要な作業のひとつです。特に、国内で10年以上の歴史があり、年商1,000億円を超える企業(約3,000〜4,000社)が取り組むべきデータ活用として、この分析は欠かせません。
重要なのは、主要な経営指標の変動が「偶然による一時的な揺らぎ」なのか、それとも「注目すべき経営環境の変化」によって引き起こされたものなのかを見極めることです。
従来のAIデータ分析による「成果改善アイデア」の限界
以下は、manusを通じて今回の四半期の売上変動要因をすべてのケースに対して分析したプロセスとその結果を整理した内容です。
言語モデルに基づいた分析にはいくつかの根本的な問題があります。
- 意図や条件をテキストでやり取りするため、誤解が生じやすい
(例:集計方法の解釈違い、重要な変数の抜けなど) - 誤解があったかどうかに気づくのは作業が終わったあと
→ 目的の結果にたどり着くまでに試行錯誤を繰り返すことになる - 分析結果との対話が限られている
→ 欲しい情報だけを簡単にフィルタリングして見るのが難しい
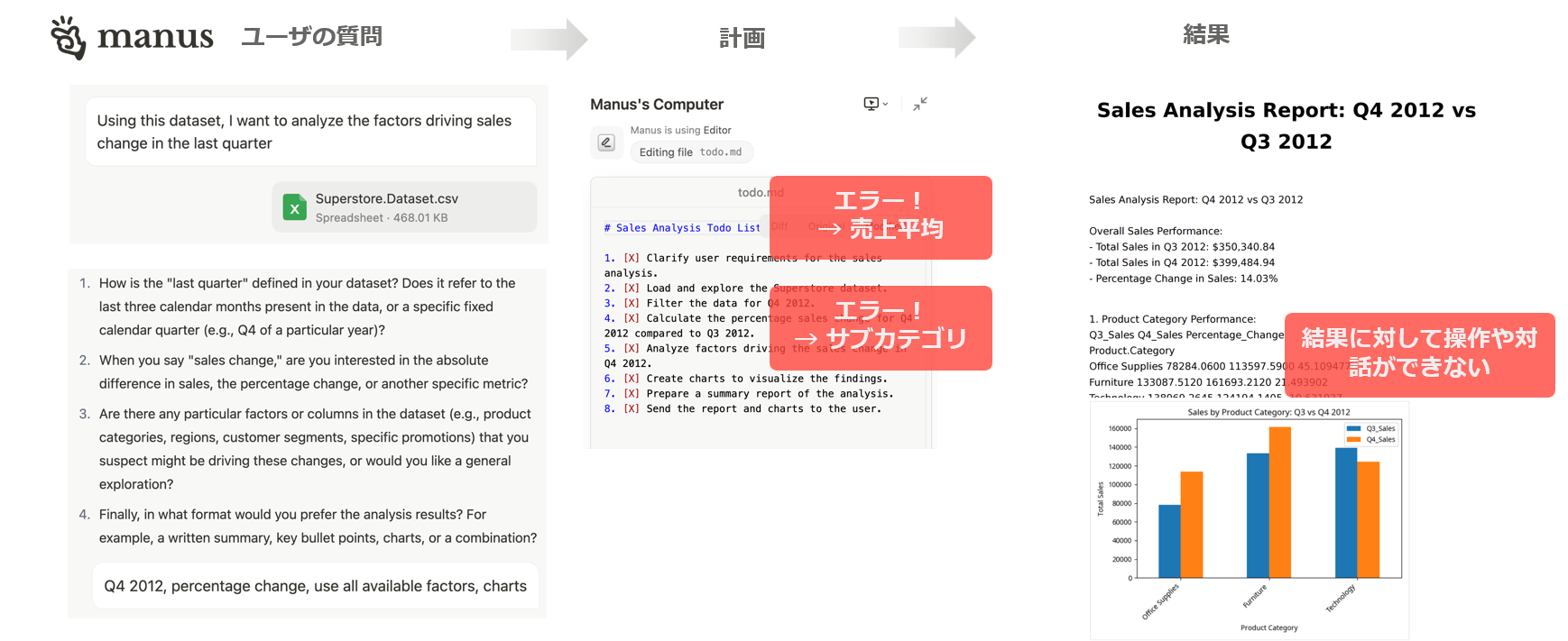
HEARTCOUNT AIデータ分析 - Dialogue
ある仕事をする最善の方法や、AからBへ行く最適なルートがすでに決まっているのであれば、その方法とルートを選ぶのが合理的です。
同じ分析手順や方法を実行するためのコードを毎回新たに作成するのは、資源の無駄です。
ダイアログ(Dialogue) - 私は語らない。私に問いかける。
ダイアログ(Dialogue)は、意思決定の文脈において構造化データを使い、仮説の検証、視覚化(EDA)、説明モデルの作成方法を熟知しているAIエージェントが、問答形式で与えられた質問に答えるための最適な分析方法、すなわちAからBへ至る最適なルートを教えてくれるAIデータ分析ツールです。

AIによるデータ分析:HEARTCOUNT ダイアログ
下の図のように、
ユーザーの分析目的と意図が把握されると、その意図に適した最適な分析方法がマッピングされます。
その後、分析の詳細な条件を確認し、
インタラクティブな形式で分析結果が提供されます。
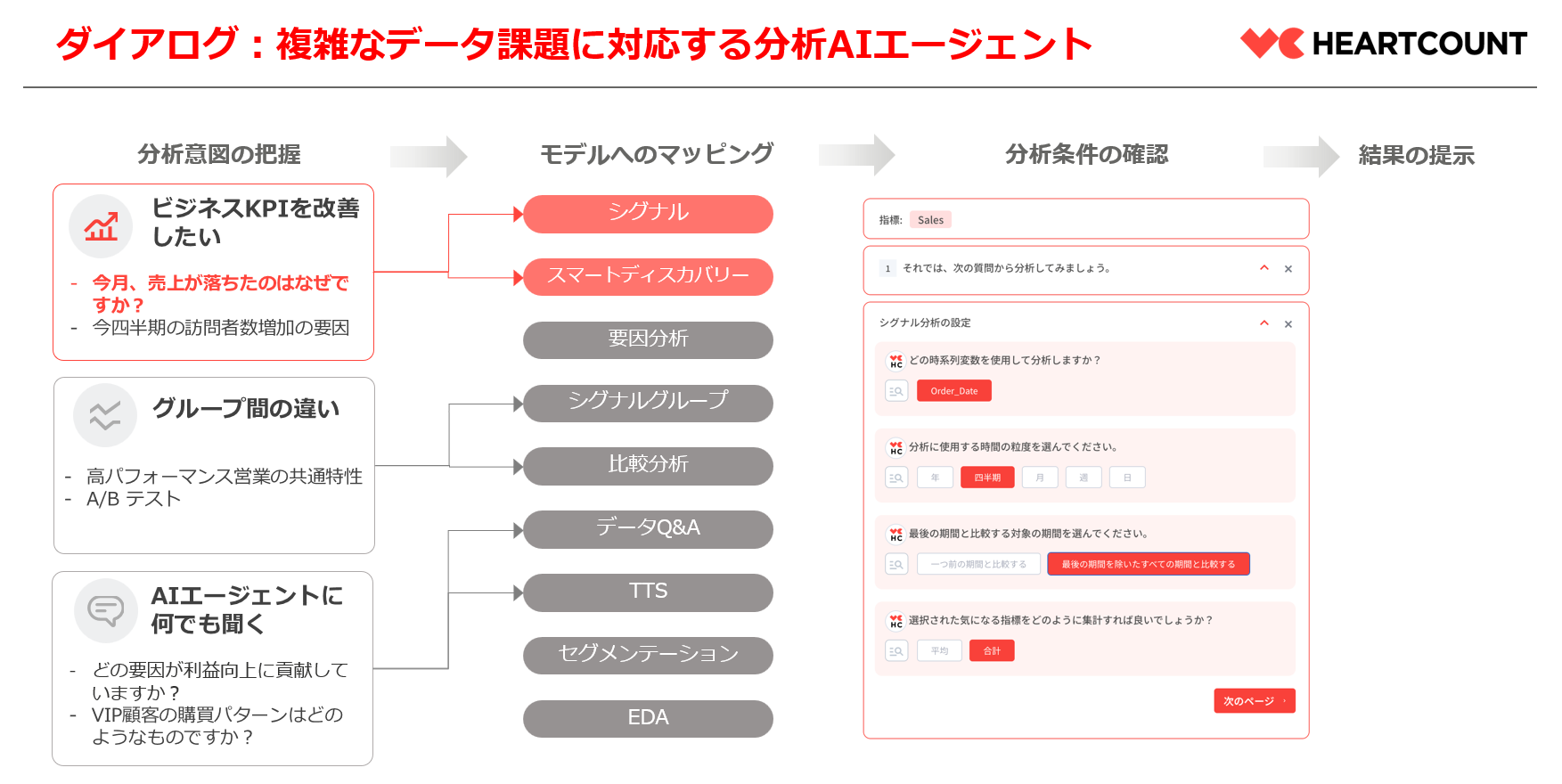
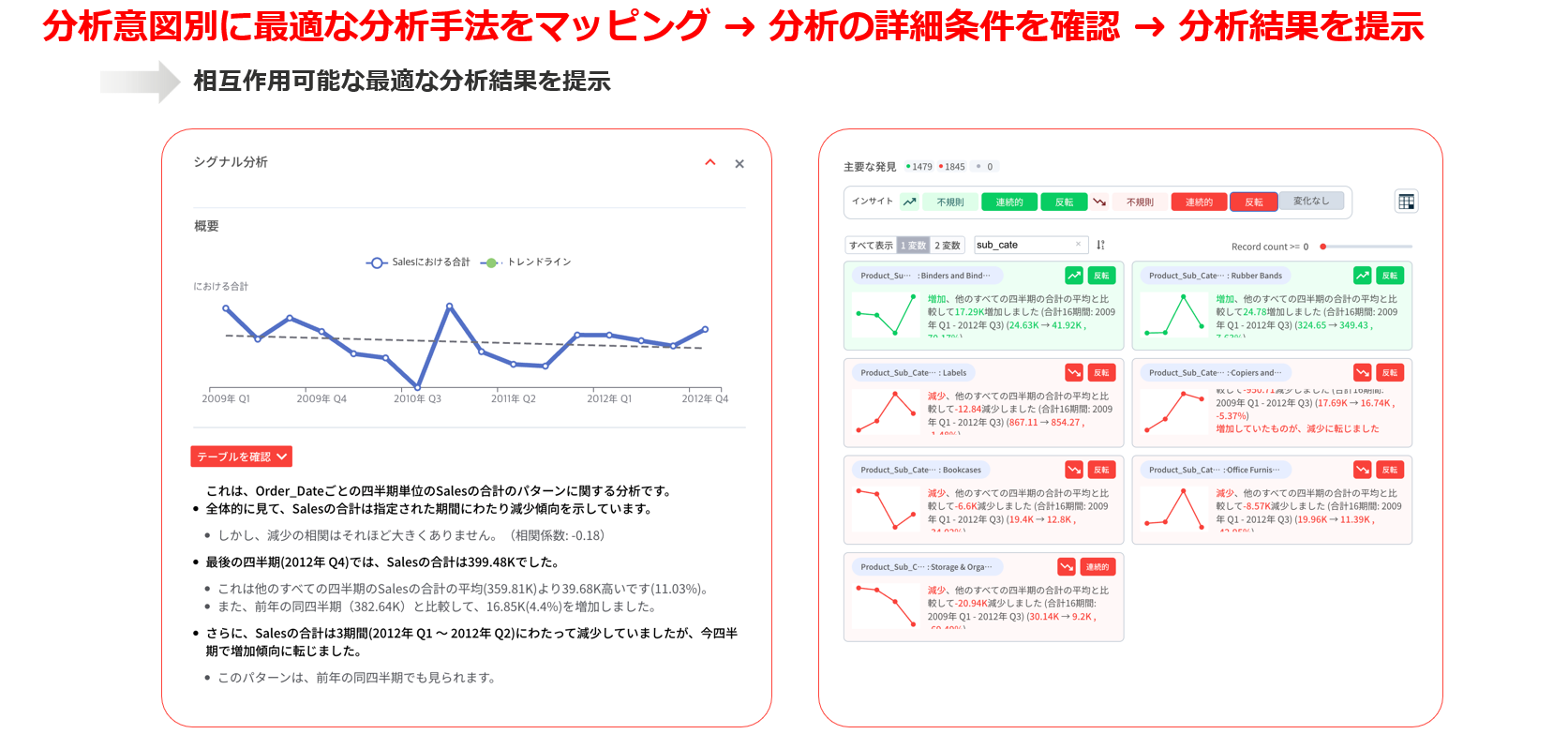
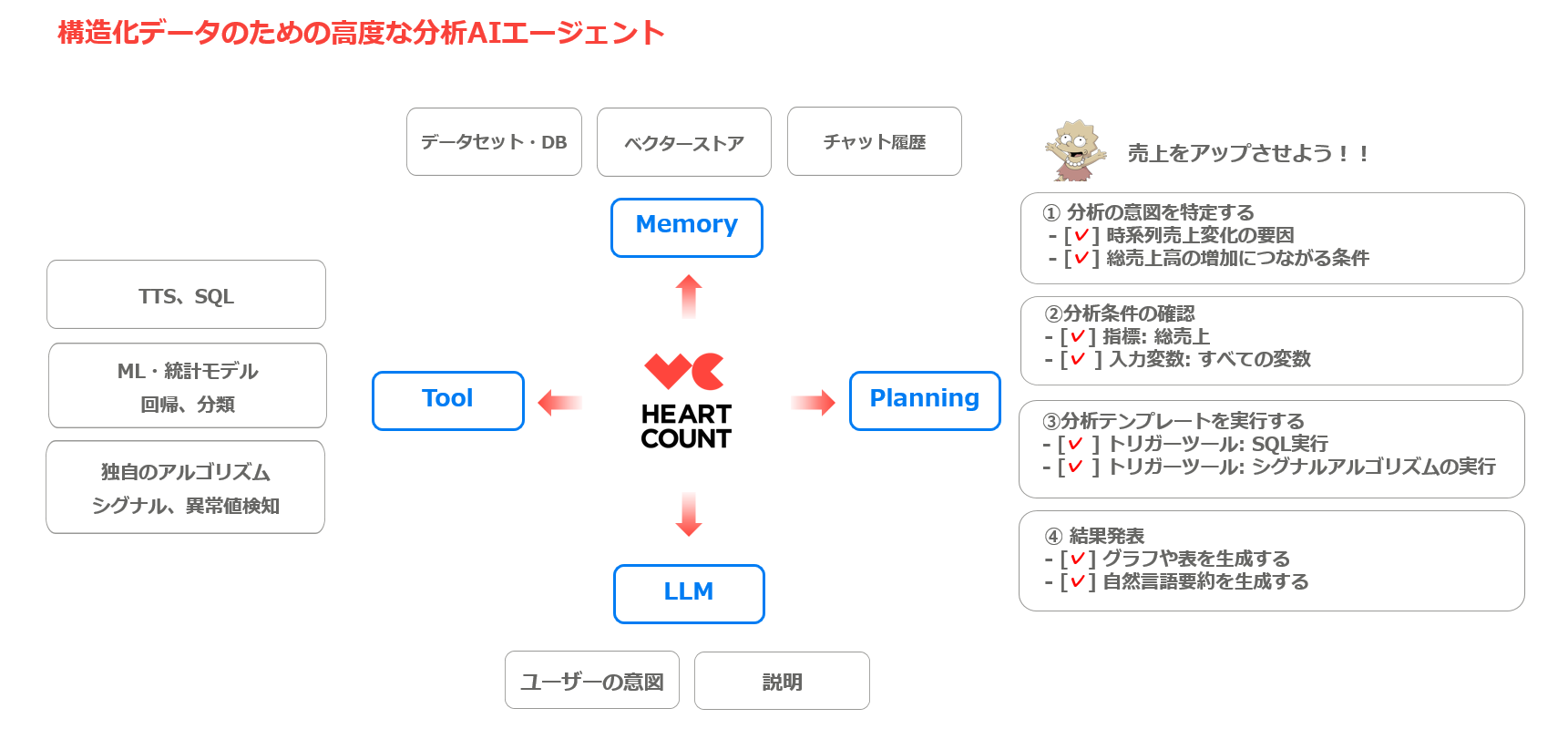
分析型AIエージェント、HEARTCOUNT Dialogue
AIエージェントの観点から構成要素を見てみると、以下の通りです:
- Memory(メモリー):分析に使用するデータセット、データベース、およびユーザーの分析履歴
- Tool(ツール):統計モデル、可視化ツール、SQLツールの使用
- Planning(プランニング):分析の目的に応じた最適な細かいタスクの定義
- LLM(大規模言語モデル):自然言語での質問の意図を理解し、分析結果を自然言語で説明
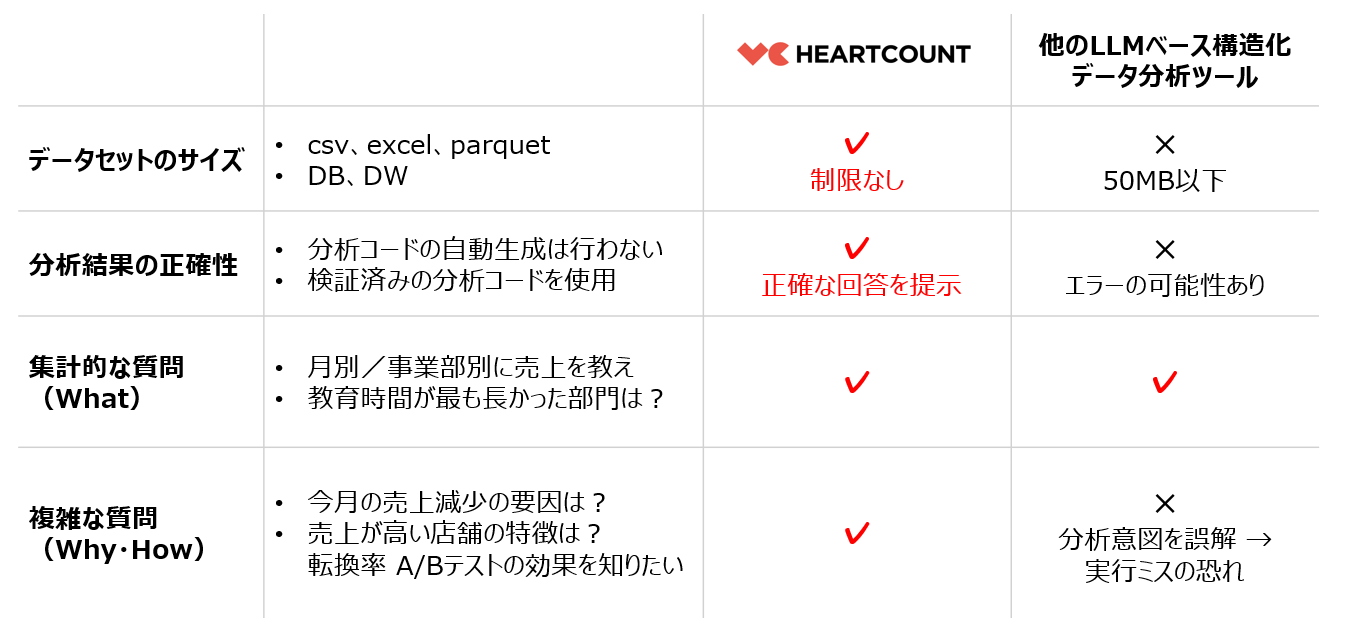
HEARTCOUNT Dialogue vs LLMベースのデータ分析ツール
他のLLMベースの構造化データ分析ツールとの違いは、以下の表の通りです。
- 分析できるデータセットのサイズに制限がない
- 集計タイプの質問だけでなく、売上減少の原因分析やVIP顧客の特性抽出といった複雑な質問にも対応可能
- すべての分析がブラウザ内で実行されるため、データセットが外部に流出する心配がない
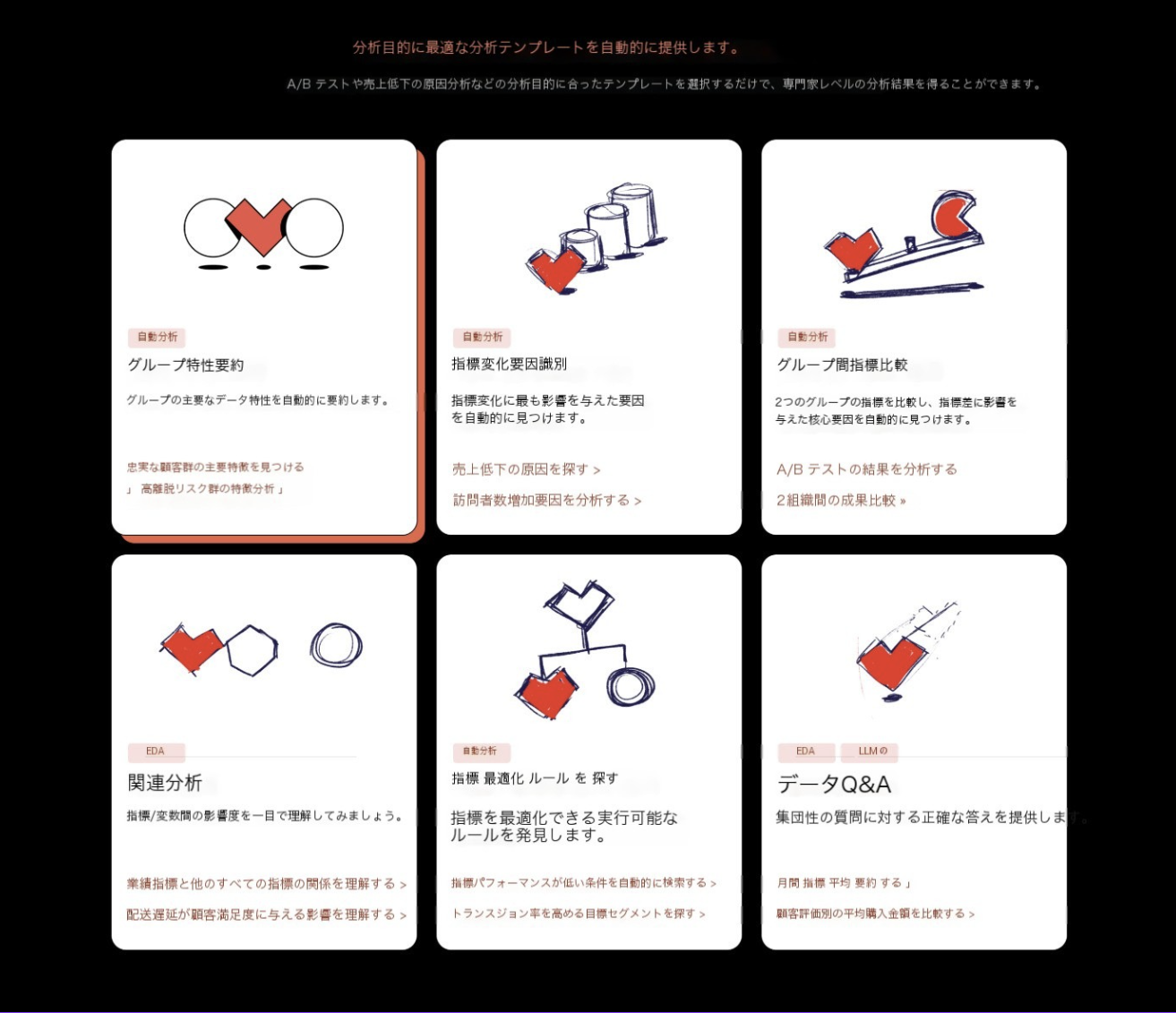
- 分析目的別テンプレート提供(2025年6月予定)
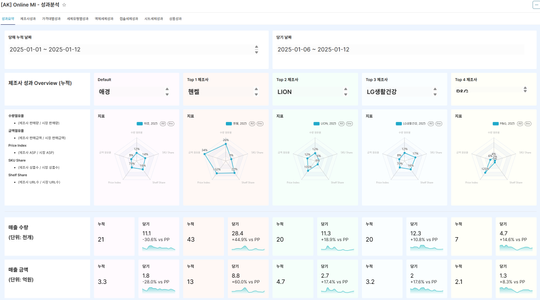
HEARTCOUNT AIアナリティクスの実践例
今回は、組織文化のサーベイデータをDialogueで分析した結果と、そのデータから発見された事実をChatGPTが解釈した結果を一緒に見ていきます。
まず、集団間の指標差分析テンプレートを選択し、関心のある指標を選びます。
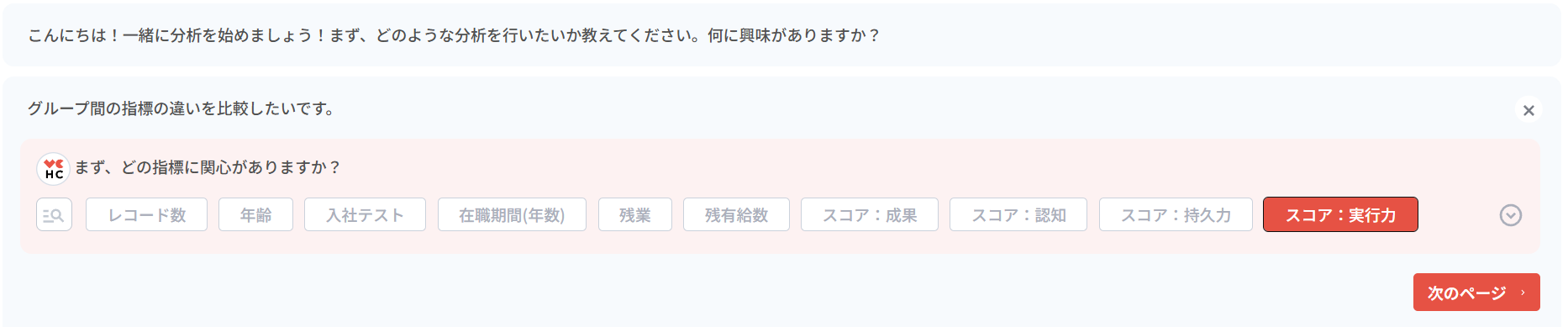
- 分析の詳細な条件も設定します。
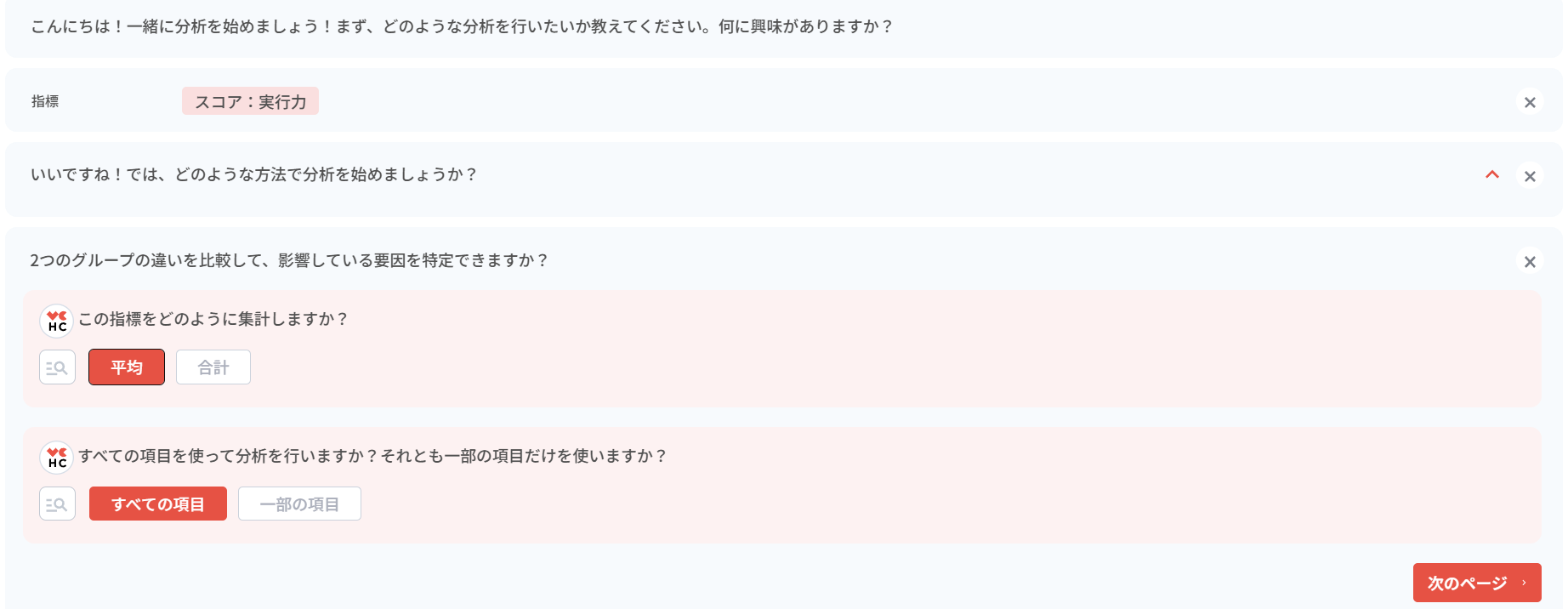

- すべてのケースに対して出てきた分析結果を、職位(ポジション)変数でフィルタリングしてみました。

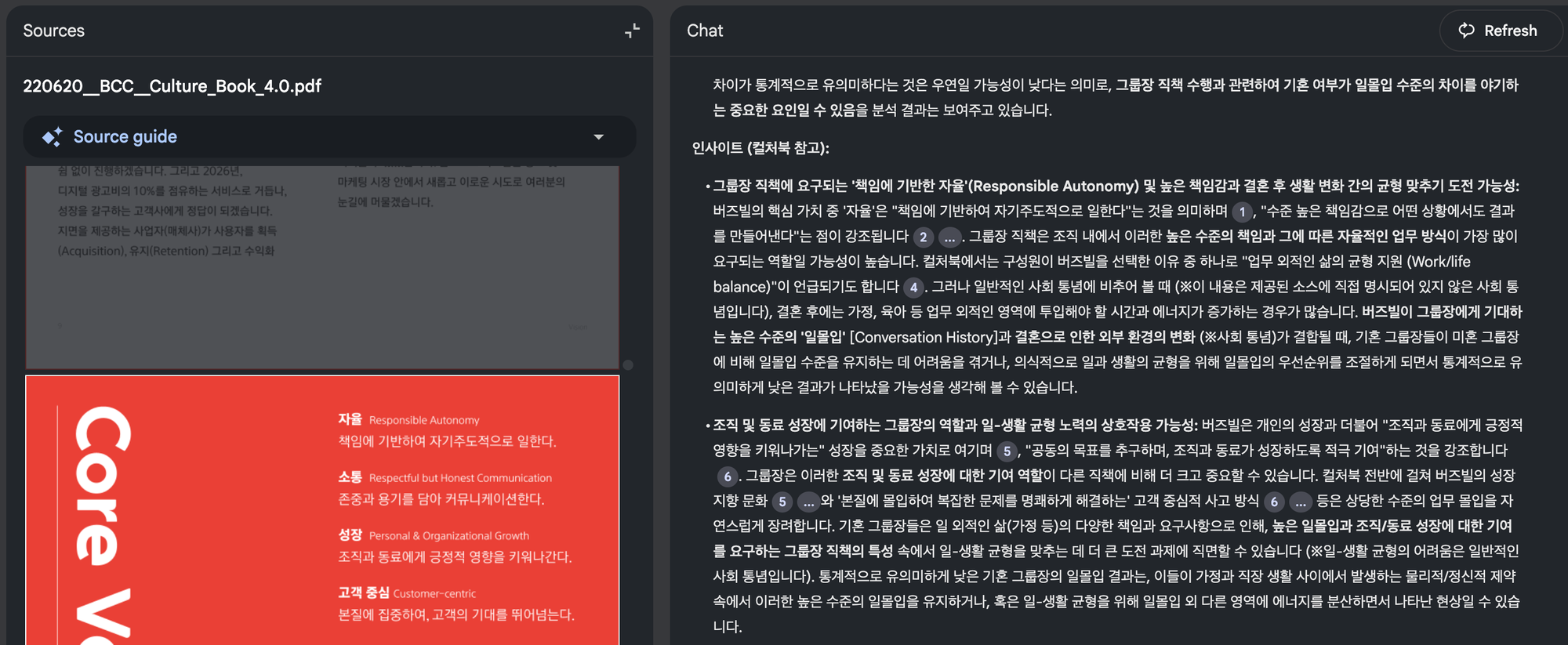
- そのカードに書かれていた内容をもとにプロンプトを作成し、ChatGPTに解釈を依頼してみました。
結果は、いわゆる“社会通念”レベルではうまく要約されていて、まずまずの仕上がりでした。とはいえ、もしAIが社内文書にまでアクセスできていたら、もっと具体的で、文脈に即した解釈ができたのではないかとも感じました。
※ちなみに、近く「Dialogue」には、LLMによる事実要約機能や、社会通念レベルでの自然な解釈機能が搭載される予定です。

- 最後に、Google NotebookLMに公開されている国内企業「バズビル」のカルチャーデックをアップロードし、同じプロンプトを使ってインサイトを生成してみました。
もちろん、これは企業の全資料を使ったわけではなく、1つの文書をもとにしたものですし、内容の正確性を厳密に検証する必要もないものでした。それでも、社会通念レベルの解釈よりも、より共感できる、文脈に沿った回答が得られたことは印象的でした。
運営最適化のためのHEARTCOUNT Dialogue
30年前、企業は「数字」よりも「人の目」と「現場の勘」をより信頼していました。一枚の損益計算書を見ながら戦略を立て、顧客とのやりとりや現場での感覚を通じて需要を予測していたのです。
数字は意思決定の補助的な道具にすぎず、判断の中心には「直感」と「経験」がありました。
世界はシンプルで、そのシンプルさの中に確信があったのです。
15年前から、海外のいくつかの企業が、より多くのデータとより高度な分析を武器に大きな富を築き始めました。
「私たちはデータに基づいて働いています」という言葉は、企業の新たな倫理となりました。
A/Bテストは主要戦略となり、予測と自動化は革新の象徴となったのです。
2025年現在、データをうまく活用して高く飛躍した一部の企業を除けば、多くの企業にとってデータは依然として「純粋なコスト(負担)」です。
「私たちはデータ中心の組織です」という言葉は、もはや中身のない象徴のように消費されています。
Data ROI(データ投資対効果)
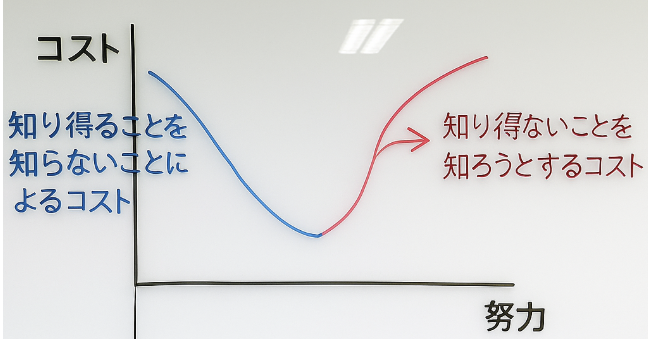
企業の運営がある程度の平衡状態(Equilibrium)に達した、一定規模以上の企業がAI時代にすべきことは、最小限のコストで、データが出せる最良の答えを得ることだと考えます。
HEARTCOUNT、実務者にとって頼れる唯一無二のデータツール
従来のデータ活用ツールでは、実務担当者が質問に関連するデータへ迅速にアクセスし、自主的に答えを導き出すという課題を解決できていません。
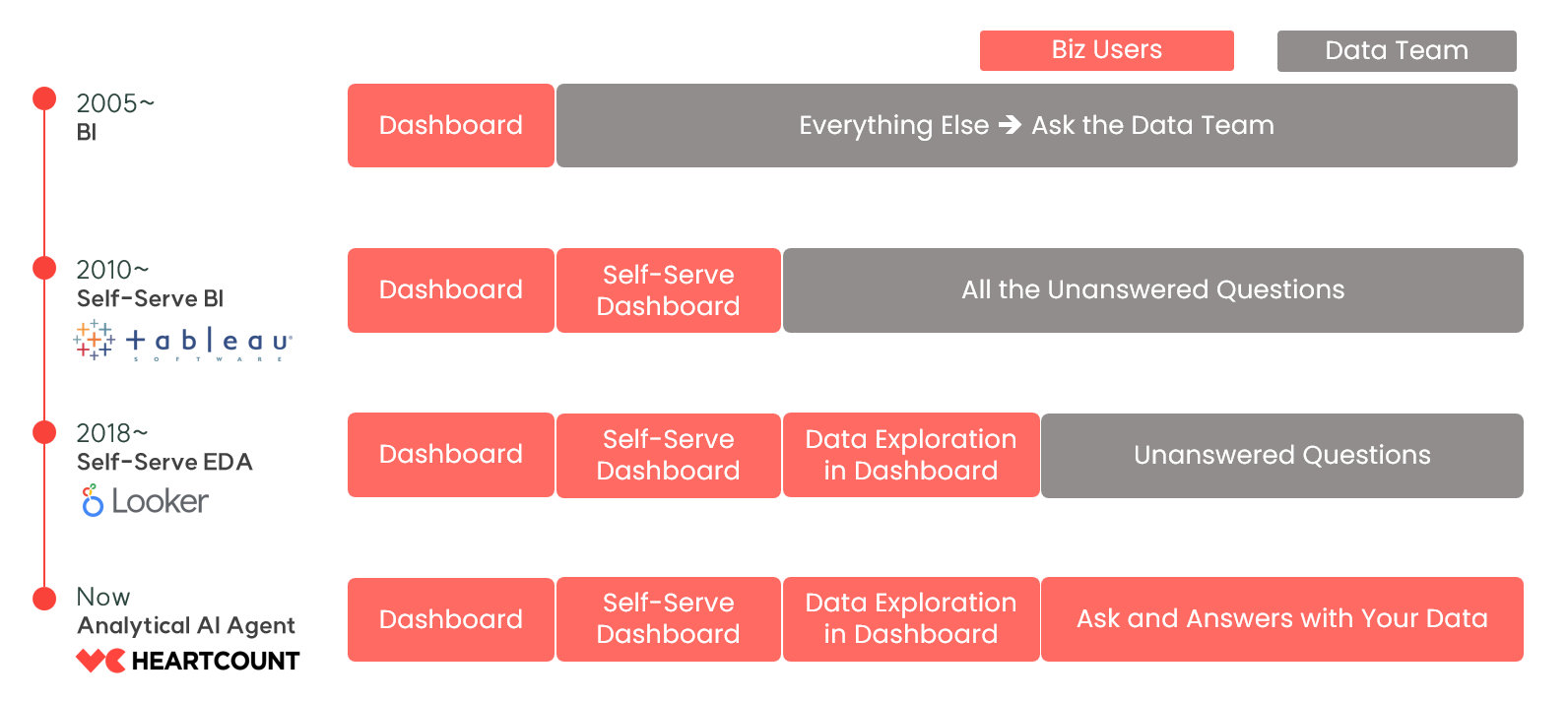
HEARTCOUNTは、構造化データに基づいて指標に関する質問に自動で回答するデータツールです。
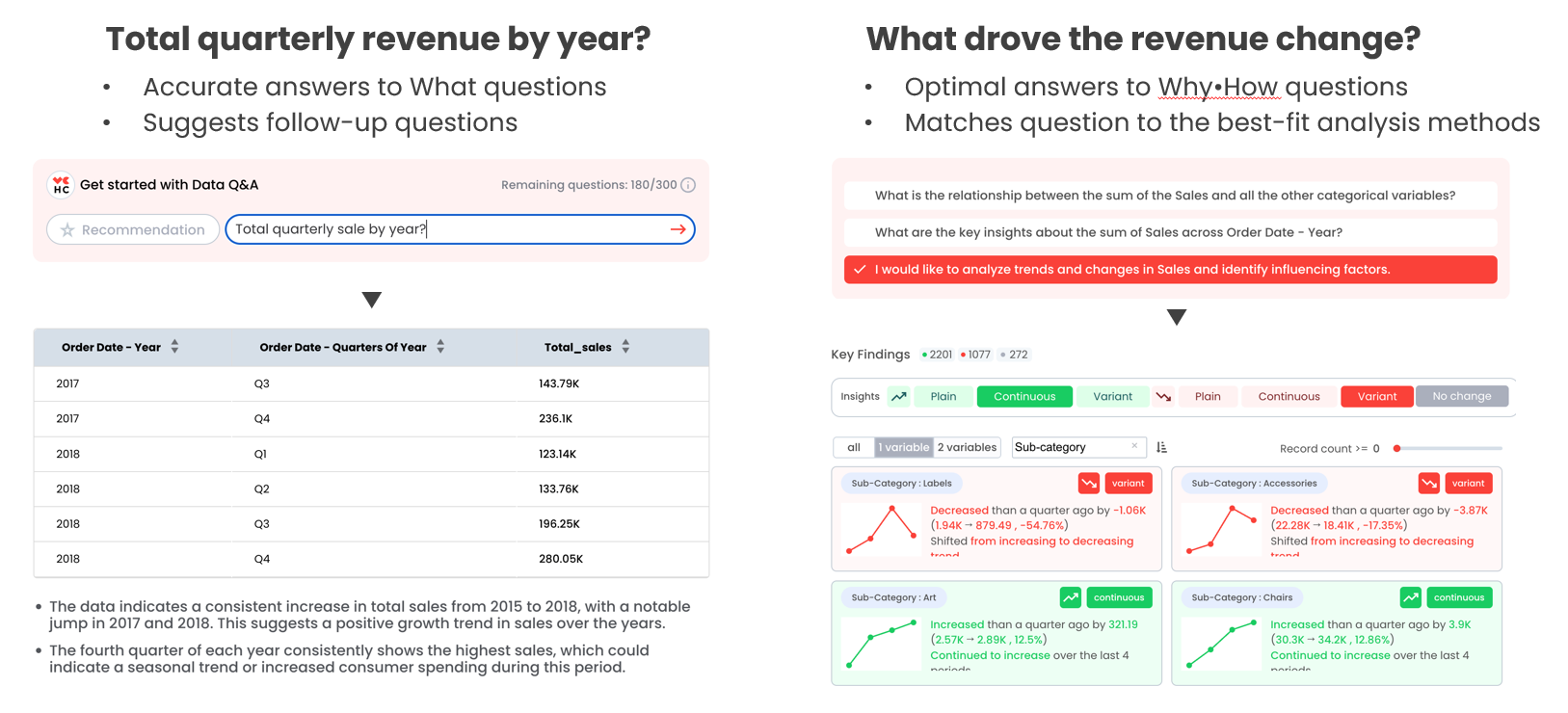
指標のモニタリングから、指標改善のための仮説検証、事実と証拠、そしてそれを取り巻く文脈に基づいた実行可能なアイデアの提示まで、最も迅速かつ効率的にこなすAIデータ分析ツールとなります。