- Excelデータをただただ溜め込んでいる方
- 分析するのに適したデータセットの形式に関心のある方
Excelデータ、どのように蓄積していますか?
ここ数年、社会全体で「データ」を通じて得られる「インサイト」の効果と重要性が大きく強調されています。しかし、実際にデータ分析をしようとすると、Excelデータが適切に整形されていない形であったり、あちこちに散らばっていて、すぐに分析が難しい場合をよく見かけます。実際、多くの実務者がExcelでデータをどのような形で蓄積すべきかよく分からないためです。
適切なデータ(テーブル)の構造
「Garage In Garage Out」という表現があります。ゴミを入れると結果もゴミになるしかありません。データ分析を活用した業務はまさにこのようなものです。良い品質のデータを入れることができなければ、良い品質の結果を期待することはできません。Excelの高度な機能を習得したとしても、データそのものに対する理解が不足していれば、成果のある良い分析はできません。
会社でデータ分析が難しいケースの多くは、「ドキュメント」と「テーブル」が区別されずに遂行された業務からインサイトを見つけなければならない場合です。
データとドキュメントを区別し、目的に合わせて分離して使用することができなければなりません。これはExcelのどのような関数や機能を習得するよりも重要であり、優先されるべきです。Excelで作ったからといって、すべて分析できるデータではありません。
分析に適したテーブルの形式と内容を整えて初めて分析が可能です。特に、よく「基礎データ」「マスターデータ」と呼ばれる各業務領域で中枢的な役割を果たすデータは、徹底的によく計画し、管理する必要があります。人事チームの従業員名簿、運用チームの取引先リスト、営業チームの商品リストなどは、データの品質を最大限維持されなければなりません。
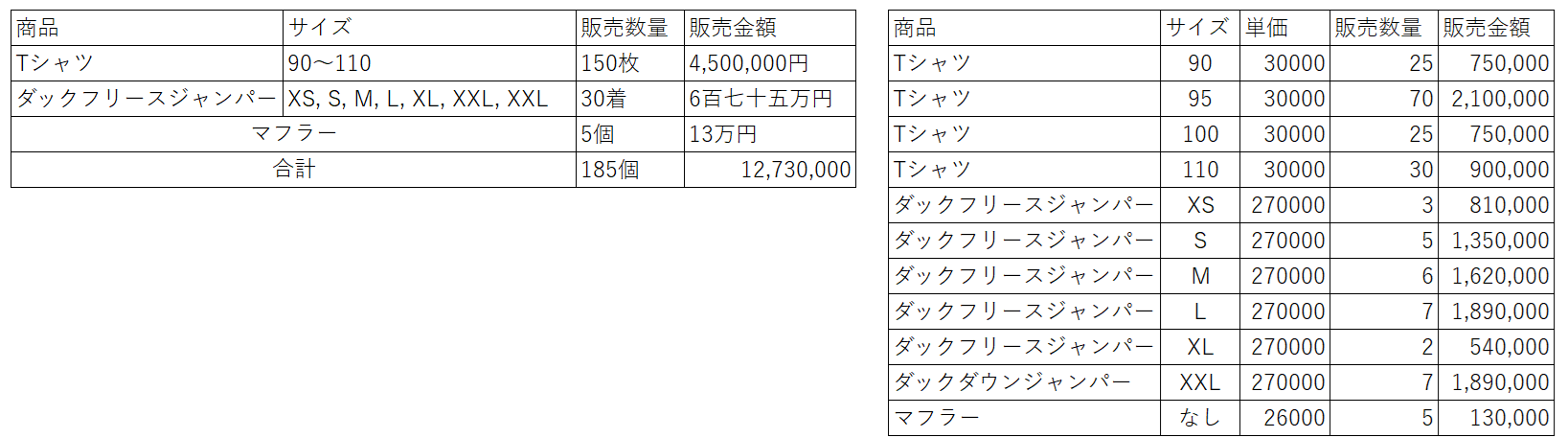
では、データをデータらしく分析するのに適したテーブルの構造とはどのようなものでしょうか? 下図の2つのテーブルは同じ内容を含んでいます。しかし、左のテーブルは分析が不可能で、右のテーブルは様々な分析が可能です。読者の皆さんの理解を助けるために少し誇張して作りましたが、実務では左のように作られたデータが溢れています。いくつかのルールさえ守れば、十分に分析しやすいデータになります。
ここからは、基本的な分析に適したデータの構造的要件9つを紹介します。これらの数点のみ理解して身につけ、そうして作られたデータでExcelが提供する強力な機能を活用すれば、私たちの仕事は一段と高いレベルに跳躍することができるでしょう。
分析に適したExcelデータのための9つの条件
1.リスト形式にする
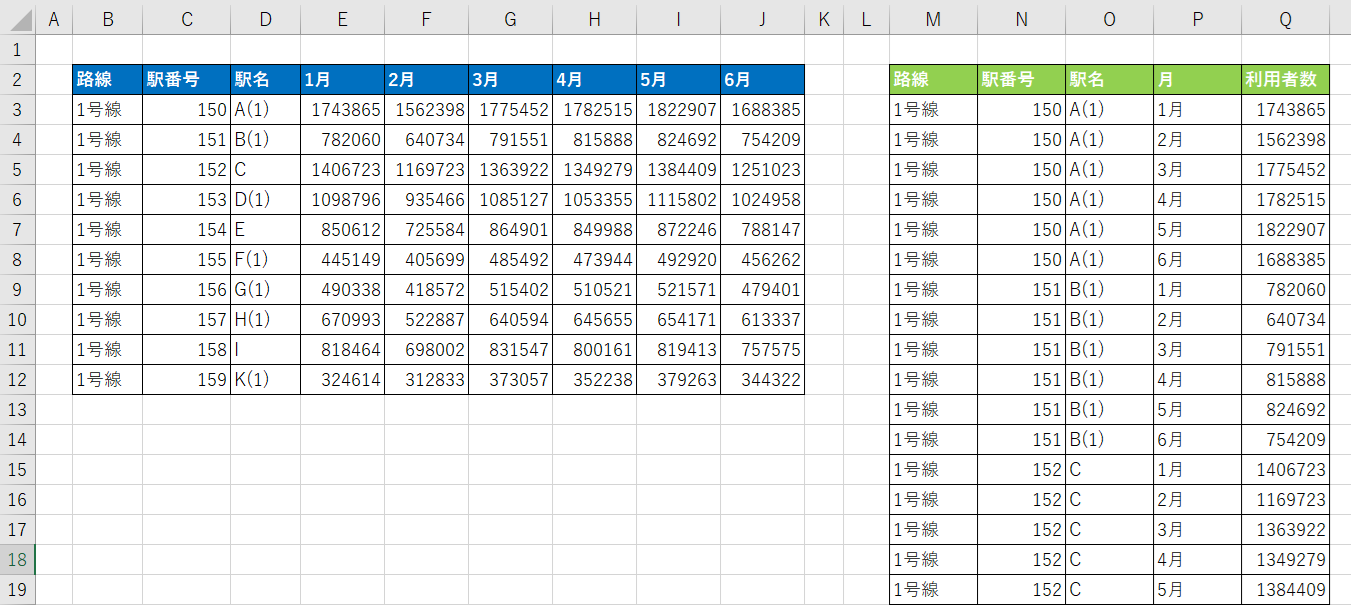
分析のための元データはリスト形式でなければなりません。左のテーブルはクロスタブ(cross tab)形式で、行と列に元データではなく、分析の結果もしくは加工されたデータ(合計)が入っています。このようなテーブルは要約、集計、分析のプロセスを経た結果であり、基礎となる元データとしては不適切です。一方、右のテーブルはリスト(list)形式で、システムでデータを保存する基本構造です。リスト形式のデータは多様な分析が可能であるだけでなく、データ(行)や変数(列)を追加し続けても分析結果に反映することができます。
2.セルをマージしない
2つ以上のセルを1つにまとめる機能をマージ(merge)といいます。この機能は、レポートのように一目で分かりやすいようにテーブルを作るときによく使います。しかし、マージはデータ分析でエラーを発生させたり、結果の値を歪めたりする代表的な機能です。Excelでは、セルはデータを保存する最小単位であり、行と列が交差するすべてのポイントをアドレスとして持ちます。例えば、[C] 列と [5] 行が交差するポイントのセルは [C5] というアドレスを持ちます。これは非常に重要な原則ですが、セルをマージをするとこの原則が崩れます。
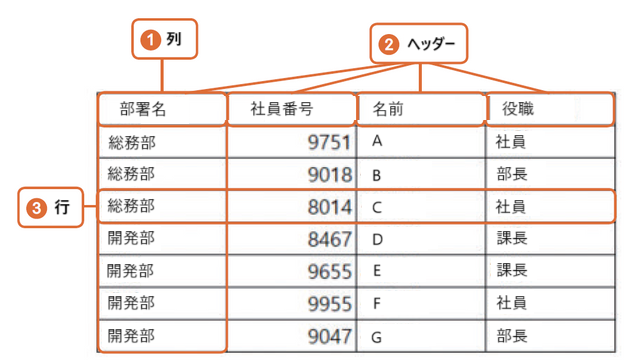
3.ヘッダーは直感的かつ正確に重複なく使用する
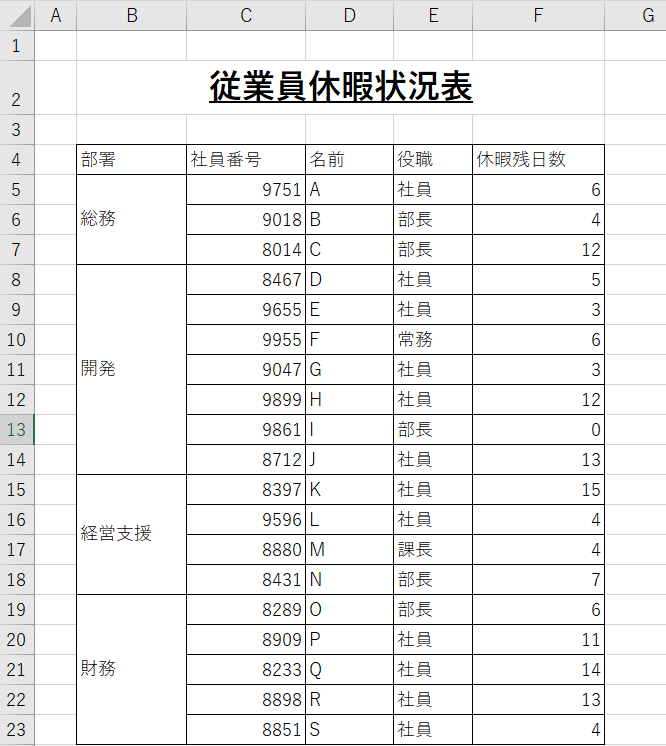
データテーブルは以下のように行と列で構成され、列にはヘッダーが必要です。部署名、社員番号、名前、役職など、列のタイトルを「ヘッダー」といいます。データ分析の過程で、列は1つの変数として列と列を計算・組み合わせたり、その関係性を調べる場合に使用するため、列の名前であるヘッダーは変数の名前として重要な役割を果たします。 そのため、日本語の単語を英語の発音で表記したり、ユーザーが分かりにくい略語を使うなど、直感的でない使用は避けなければなりません。
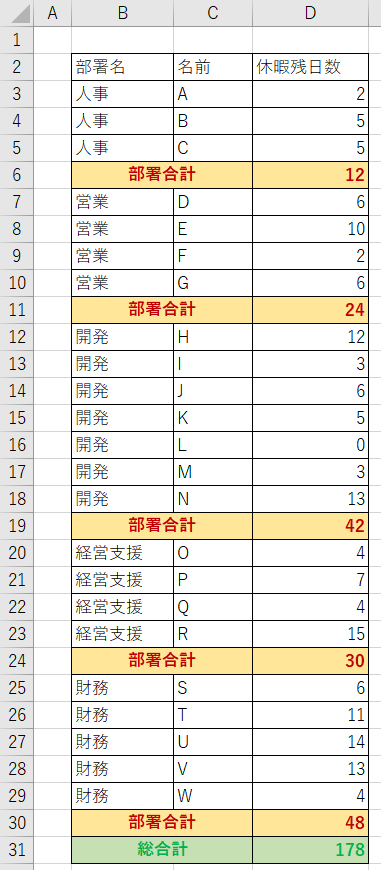
4.要約(合計)行を使用しない
レポートでテーブルを使用する場合は、各列や行の合計や平均などの代表値を表示するのが一般的です。しかし、データ分析で使用する元のデータには、要約行があってはなりません。
5.空白のセルを埋める - 欠測値を除去する
データがあるべき位置にデータがない場合を欠測値(missing value)といいます。 欠測値は「空白値」とも呼ばれますが、欠測値が発生する原因は、データベースシステムのエラーもしくは操作した人のミスであったり、測定できなかったために空白となった可能性があります。
ここで注意すべき点は、「0」は欠測値ではないということです。「0」はそれ自体がデータなので、データが存在しないのとは全く異なる状況です。ここでは、いかなるデータもなく、セルが空白の場合を意味します。
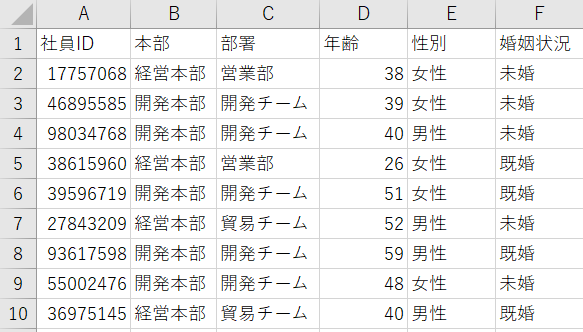
6.重複値を把握する
属性によって同じデータが2つ以上あってはいけない列もあれば、同じデータがあるしかない列もあります。以下の画面では、[A] 列は社員を識別できる [社員ID] 列で、重複した値があってはいけません。しかし、部署、年齢、性別などは社員同士で同じである可能性があるため、当然のことながら重複している可能性があります。
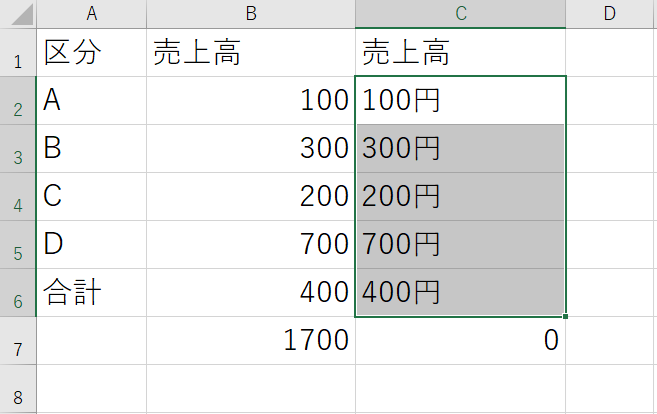
7.数値データを「単位」と一緒に使用しない
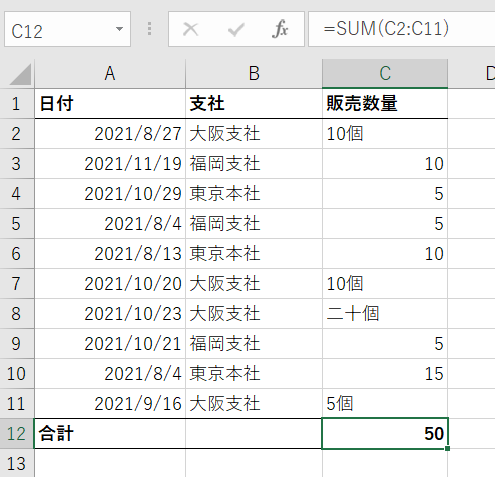
数値データの特徴は、数字以外に他の文字が含まれるとすべてテキストデータに置き換えられることです。代表的な例として、500円、60kg、25歳などのように数字を単位と一緒に使用する場合を挙げることができます。このようなデータは演算に利用することができないので、テキストを削除して数字のみを残す必要があります。
8.同じ列のデータは1つのデータ型に統一する
同じ列のデータは、必ず数値かテキストのいずれかの形式に統一する必要があります。 特に実務では、複数の会社、部署、担当者のデータをまとめて作られたデータで分析することが多いです。このようなデータでよく発生する問題は、複数のデータ型が混在している場合が多いことです。
9.1つの行には1つのデータのみを使う
データテーブルでは、列はフィールド(Field)またはカラム(Column)と呼ばれ、行はレコード(Record)とも呼ばれます。データテーブルは何らかの事実をフィールドごとに記録することで構成されます。つまり、個々の事実は行として「記録」されますが、その場合に行を構成する項目は列です。
したがって、1つの行に2つ以上のデータが入ることは、データテーブルを構成する基本原則に反します。複数のサイズのTシャツを1つの行としてテーブルを構成すると、どのような分析もできません。それぞれのサイズが一つの「事実」であるためです。したがって、必ず1つの行には1つのデータ、つまり1つの記録(レコード)のみが使われなければなりません。
データは人ではなく、コンピュータとコミュニケーションしやすい形式でなければなりません
ここまで、分析しやすいExcelデータの9つの条件について紹介しましたが、読み終えた方が不思議に思われる部分があると思います。それは、データの見栄えが良くないという点です。そうです。データは基本的に人がコンピュータとコミュニケーションするための形式であって、人と人とのコミュニケーションのための形式ではないためです。 そのため、良い実務のデータ作業とは、データはデータそのものとして良い品質で管理しながら、それを活用したレポートは別々に作成する方法です。
つまり、データとドキュメントを分離することです。 これはExcelのピボットテーブルの基本原理です。ピボットテーブルは、元データを保存したまま、別のキャッシュメモリにデータを保存した後、元データを「ピボット」、つまり変換して要約、集計分析します。そのため、高速かつ強力です。
データをデータそのものとして、そしてデータとレポートとを分離して使うようになって初めて、私たちはより速く、より正確で、より成長することができます。