- Developers interested in improving database performance
- Data analysts looking to enhance data processing and management techniques
- BI professionals focused on boosting dashboard performance
- Database administrators responsible for overall system performance and resource optimization
Today, we're excited to share six essential tips for optimizing SQL queries and enhancing database performance!
Query tuning is critical because it directly impacts your system's performance. When dealing with large datasets, unoptimized queries can lead to slow response times, wasted resources, and even service outages. On the flip side, well-tuned queries can handle tasks more efficiently and reliably. Efficient query processing translates directly into cost savings and increased productivity for your company.
The six query optimization tips we’re about to introduce are practical and applicable for data engineers, developers, analysts, and anyone who works with databases. Each tip is explained using real-world examples, complete with code snippets to illustrate common issues and how to achieve better query performance.
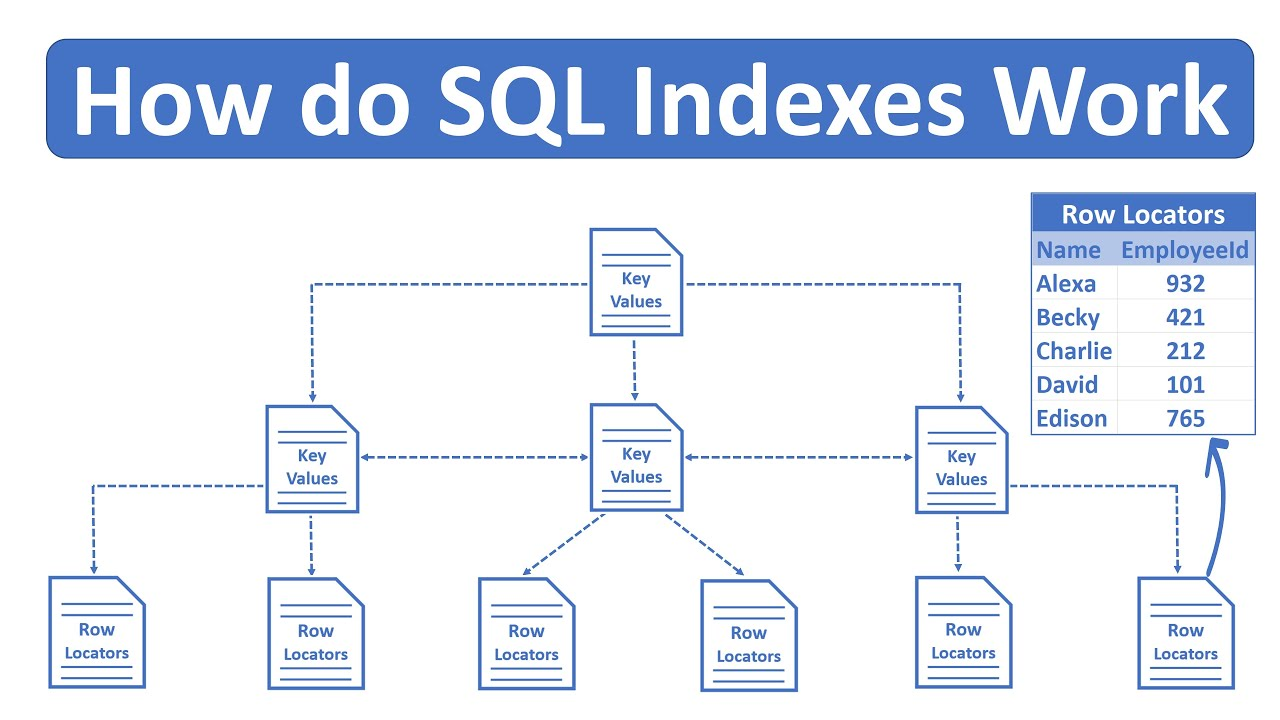
But before we dive in, there’s one key concept you should understand: Indexing. Let’s quickly review what an index is and how it affects query performance.
(Prerequisite) Understanding Indexing in Databases
Indexes help databases locate and organize data quickly, similar to how a book's table of contents helps you find specific sections. Think of indexing as creating a "shortcut" to data in your database, significantly speeding up searches and improving data management.
1. Avoid Performing Operations on the Left-Hand Side of a Condition
The Issue with Left-Side Operations
When writing SQL queries, we often use functions to filter or manipulate data. For example, if you want to filter data for a specific year, you might come up with a query like the following:
SELECT * FROM sales
WHERE YEAR(date) = 2021;
This query filters data from the sales table where the date column's year is 2021. While intuitive, this approach can severely hinder performance.
When you transform data in a query, the database cannot use indexes effectively, making it scan all records. Instead of leveraging an index, the database must compute the YEAR(date) for every row, which can be computationally expensive.
The Effective Solution: Filter Data on the Right Side
To optimize, compare the original data directly without altering it:
SELECT * FROM sales
WHERE date >= '2021-01-01' AND date <= '2021-12-31';
This approach allows the database to use the index on the date column efficiently, speeding up the query by narrowing down the search range.
2. Use UNION Instead of OR
The Problem with OR
Using OR in queries can cause performance issues because the database must scan for multiple conditions in a single pass, often leading to inefficient index usage.
SELECT * FROM employees
WHERE department = 'Marketing' OR department = 'IT';
Indexes are optimized for fast searches of single values, but when you use OR, the database has to look for multiple values simultaneously. This prevents the index from being used effectively, and the database ends up having to scan all the data, losing the advantage that the index provides.
As a result, with OR, the database might not fully utilize indexes, making the query slower, especially on large datasets.
The Better Approach: Use UNION
Replace OR with UNION, which executes each condition separately and combines the results.
SELECT * FROM employees WHERE department = 'Marketing'
UNION
SELECT * FROM employees WHERE department = 'IT';
This approach allows the database to optimize and execute each query independently.
For example, department = 'Marketing' and department = 'IT' can each be quickly processed using their respective indexes. Then, the UNION operation combines the results. During this process, any duplicate results are automatically removed.
If you're certain that there are no duplicates, you can use UNION ALL to skip the duplicate removal step and further improve performance. However, in most cases, it's recommended to use UNION to ensure accurate results.
Using UNION instead of OR is an effective way to optimize complex query performance. By executing separate queries for each condition and leveraging indexes, you can reduce the load on the database and significantly improve overall query performance.
3. Select Only the Necessary Rows and Columns
Efficient Row and Column Selection
Fetching more data than necessary is a common cause of performance degradation. Instead, always query only the data you need.
For instance, if you need names and emails of employees in the Marketing department with sales over 100,000:
SELECT name, email
FROM employees
WHERE department = 'Marketing' AND sales >= 100000;
This query selects only the relevant columns (name, email) and rows, reducing the load on the database.
Using Subqueries for Precise Data Extraction
To find the top performer in each department, you can use a subquery:
SELECT e.name, e.department, e.sales
FROM employees e
JOIN (
SELECT department, MAX(sales) AS max_sales
FROM employees
GROUP BY department
) d ON e.department = d.department AND e.sales = d.max_sales;
In this query, a subquery is used to calculate the maximum sales for each department, and then this result is joined with the employees table to extract only the necessary information.
By selecting only the department and max_sales columns in the subquery, unnecessary columns are excluded, minimizing the size of the intermediate results.
Based on this, the final query retrieves only the required information—employee name, department, and sales amount. This approach significantly enhances query efficiency.
When querying a database, it's crucial to select only the necessary rows and columns. By reducing the processing of unnecessary data, you can shorten response times and utilize system resources more efficiently. This is one of the fundamental practices for optimizing database performance.
4. Leverage Analytic Functions to Boost Query Efficiency
Understanding Analytic Functions
Analytic functions like ROW_NUMBER(), RANK(), DENSE_RANK(), LEAD(), and LAG() are powerful tools that allow for complex, efficient data analysis within your queries. These functions enable detailed calculations on each row within complex datasets. They allow for flexible execution of various statistical operations and computations across the entire dataset.
Analytical Functions That Improve Query Efficiency
Using analytical functions can significantly enhance the efficiency of SQL queries in various ways.
First, unlike traditional aggregate functions, analytical functions do not require data to be grouped in advance. This reduces unnecessary resource consumption and helps improve query performance. Additionally, these functions minimize the need to store and reprocess intermediate results during complex data analysis, which can greatly reduce query execution time.
Ranking Functions for Ordering Data
Functions like ROW_NUMBER(), RANK(), and DENSE_RANK() are particularly useful for assigning ranks to each item within a dataset. For example, to rank employees by salary within each department:
SELECT
name,
department,
salary,
ROW_NUMBER() OVER (PARTITION BY department ORDER BY salary DESC) AS rank
FROM employees;
This query assigns a unique rank to employees in each department based on their salary in descending order. While RANK() and DENSE_RANK() operate similarly, they differ in how they handle ties. RANK() assigns the same rank to identical values but skips the subsequent ranks, whereas DENSE_RANK() maintains a continuous ranking without gaps.
Tracking Data Changes with Analytical Functions
The LEAD() and LAG() functions allow you to reference data from the previous or next row relative to the current row. These functions are particularly useful for calculating changes, such as salary increases for employees:
SELECT
name,
salary,
LAG(salary) OVER (PARTITION BY department ORDER BY hire_date) AS prev_salary,
salary - LAG(salary) OVER (PARTITION BY department ORDER BY hire_date) AS salary_increase
FROM employees;
In this query, employees are ordered by their hire date within each department, and the difference between the current and previous salary is calculated to determine the salary increase.
These functions are especially valuable when analyzing time series data or continuous datasets where comparisons with previous data points are necessary.
Optimizing Data Filtering with Analytical Functions
If you need to extract only the top 3 highest-paid employees in each department, you can use the ROW_NUMBER() function as follows:
WITH ranked_employees AS (
SELECT
name,
department,
salary,
ROW_NUMBER() OVER (PARTITION BY department ORDER BY salary DESC) AS rank
FROM employees
)
SELECT *
FROM ranked_employees
WHERE rank <= 3;
This query first ranks employees by salary within each department and then selects only those with a rank of 3 or less. This approach allows you to quickly filter out the necessary results without scanning the entire dataset.
By utilizing analytical functions, you can greatly enhance the efficiency and performance of your SQL queries. I highly recommend incorporating these functions into your data processing and analysis tasks moving forward!
5. Place Wildcards(%) at the End of Strings
The Impact of Wildcard Positioning
The placement of wildcards in LIKE queries can drastically affect performance. Consider the difference:
Using a wildcard at the beginning:
SELECT * FROM users WHERE name LIKE '%John';
This forces the database to search all possible string combinations, making it impossible to use an index efficiently. As a result, the database consumes a significant amount of resources, and the query speed inevitably slows down.
Instead, place the wildcard at the end:
SELECT * FROM users WHERE name LIKE 'John%';
This query searches for all names that start with 'John'. By doing so, the database can effectively narrow down the search range using the index.
The database quickly locates the first entry that begins with 'John' in the index, and then it only searches until it finds the first entry that does not start with 'John'.
Therefore, when using the LIKE operator with a wildcard (%), it's generally better to place the wildcard at the end of the string. This helps the database make better use of the index, resulting in faster and more efficient searches.
6. Precompute and Store Calculated Values
Processing complex calculations in real-time can place a heavy burden on query performance, especially when dealing with large datasets. In such cases, a highly effective optimization strategy is to precompute frequently used values and store them for quick retrieval when needed.
The Inefficiency of Real-Time Calculation
Consider an e-commerce site where various statistics, such as average purchase amount per product, total sales, number of purchasers, and repurchase rate, need to be calculated in real-time.
SELECT
p.product_id,
AVG(od.quantity * od.unit_price) AS avg_order_amount,
SUM(od.quantity * od.unit_price) AS total_sales,
COUNT(DISTINCT o.customer_id) AS num_purchasers,
COUNT(DISTINCT CASE WHEN o.customer_id IN (
SELECT customer_id
FROM orders
WHERE product_id = p.product_id
GROUP BY customer_id
HAVING COUNT(*) > 1
) THEN o.customer_id END) * 1.0 / COUNT(DISTINCT o.customer_id) AS repurchase_rate
FROM
products p
JOIN order_details od ON p.product_id = od.product_id
JOIN orders o ON od.order_id = o.order_id
GROUP BY
p.product_id;
This query joins the products, order_details, and orders tables to calculate various metrics, such as average order amount (avg_order_amount), total sales (total_sales), number of purchasers (num_purchasers), and repurchase rate (repurchase_rate) for each product (product_id).
The problem with this approach is that every time the query is executed, it has to read through vast amounts of order and customer data and perform complex calculations. This is especially taxing when calculating the repurchase rate, which involves a subquery, further slowing down the query.
If these statistics are frequently used, repeatedly performing the same complex calculations can result in significant resource wastage.
Storing and Utilizing Precomputed Values
To address the issues of real-time calculation inefficiency, we can store the results of these calculations in a separate table.
CREATE TABLE product_stats AS
SELECT
p.product_id,
AVG(od.quantity * od.unit_price) AS avg_order_amount,
SUM(od.quantity * od.unit_price) AS total_sales,
COUNT(DISTINCT o.customer_id) AS num_purchasers,
COUNT(DISTINCT CASE WHEN o.customer_id IN (
SELECT customer_id
FROM orders
WHERE product_id = p.product_id
GROUP BY customer_id
HAVING COUNT(*) > 1
) THEN o.customer_id END) * 1.0 / COUNT(DISTINCT o.customer_id) AS repurchase_rate
FROM
products p
JOIN order_details od ON p.product_id = od.product_id
JOIN orders o ON od.order_id = o.order_id
GROUP BY
p.product_id;
This query creates a new table called product_stats and precomputes the complex statistics for each product. By doing this, the necessary statistics are stored in advance, so when these metrics are needed later, they can be retrieved directly from this table. This approach eliminates the need for complex real-time calculations, significantly speeding up query performance.
Periodic Update of Calculated Results
Of course, the statistics will need to be updated whenever new order data is added. However, this doesn't have to be done in real-time.
Instead, you can perform a batch update at regular intervals (e.g., once a day) to refresh the statistics.
UPDATE product_stats ps
SET
avg_order_amount = (
SELECT AVG(od.quantity * od.unit_price)
FROM order_details od
WHERE od.product_id = ps.product_id
),
total_sales = (
SELECT SUM(od.quantity * od.unit_price)
FROM order_details od
WHERE od.product_id = ps.product_id
),
num_purchasers = (
SELECT COUNT(DISTINCT o.customer_id)
FROM order_details od
JOIN orders o ON od.order_id = o.order_id
WHERE od.product_id = ps.product_id
),
repurchase_rate = (
SELECT
COUNT(DISTINCT CASE WHEN o.customer_id IN (
SELECT customer_id
FROM orders
WHERE product_id = ps.product_id
GROUP BY customer_id
HAVING COUNT(*) > 1
) THEN o.customer_id END) * 1.0 / COUNT(DISTINCT o.customer_id)
FROM order_details od
JOIN orders o ON od.order_id = o.order_id
WHERE od.product_id = ps.product_id
);
This query updates the statistics in the product_stats table based on the latest order data. Each statistic is recalculated using a subquery and the results are used to update the corresponding values in the product_stats table.
By storing calculated results and updating them periodically, you can greatly reduce the burden of complex real-time queries. Remember, precomputing and storing frequently used statistics and aggregate values is a key optimization technique that can significantly enhance performance!
Summary:
- Avoid altering data on the left-hand side of conditions; directly compare original data to leverage indexing.
- Replace
ORwithUNIONto optimize individual query conditions and improve performance. - Select only necessary rows and columns to reduce data processing load.
- Use analytic functions like
ROW_NUMBER()andLEAD()for efficient and complex data analysis. - Position wildcards at the end of strings in
LIKEqueries to enhance index usage. - Precompute complex calculations and store the results, updating them periodically to reduce real-time processing demands.
I hope these tips help you optimize your SQL queries effectively!
Log in with your Google account and start using it now.