안녕하세요, Analytics Engineer Jaden입니다.
이번 글에서는 데이터 마트(DM)에서 널리 활용되고 있는 Wide-Dataset에 대해 자세히 알아보고자 합니다.
Wide-Dataset이 무엇이고 어떤 특징이 있는지, DM에서 Wide-Dataset을 활용할 때의 이점과 단점, 그리고 Wide-Dataset이 DM에서 선호되는 이유에 대해 차근차근 살펴볼 예정입니다.
Wide-Dataset과 Long-Format Dataset
Wide-Dataset은 데이터를 테이블 형태로 표현할 때, 열(Column)의 수를 최대한 늘려 데이터를 폭넓게 저장하는 방식입니다. 한 테이블에 가능한 한 많은 속성을 포함시켜 데이터를 저장하는 것이 핵심인데요.
이와 대비되는 개념으로 Long-Format Dataset이 있습니다. Long-Format Dataset은 행(Row)의 수를 늘려 데이터를 길게 저장하는 방식으로, 데이터를 정규화하고 중복을 최소화하는 데 주로 사용됩니다.
쉬운 이해를 위해 온라인 쇼핑몰의 고객 구매 이력 데이터를 예로 들어볼게요.
Wide-Dataset 예시
| 고객 ID | 이름 | 이메일 | 총 구매 금액 | 구매 횟수 | 구매 상품 카테고리 | 마지막 구매일 | 첫 구매일 | 평균 구매 주기(일) |
|---|---|---|---|---|---|---|---|---|
| 1 | 김영희 | yh.kim@email.com | 1,500,000 | 15 | 의류, 잡화, 식품 | 2023-04-15 | 2022-01-10 | 45 |
| 2 | 박철수 | cs.park@email.com | 2,000,000 | 20 | 전자기기, 도서, 식품 | 2023-04-10 | 2021-12-15 | 30 |
Long-Format Dataset 예시
| 고객 ID | 속성 | 값 |
|---|---|---|
| 1 | 이름 | 김영희 |
| 1 | 이메일 | mailto:yh.kim@email.com |
| 1 | 총 구매 금액 | 1,500,000 |
| 1 | 구매 횟수 | 15 |
| 1 | 구매 상품 카테고리 | 의류 |
| 1 | 구매 상품 카테고리 | 잡화 |
| 1 | 구매 상품 카테고리 | 식품 |
| 1 | 마지막 구매일 | 2023-04-15 |
| 1 | 첫 구매일 | 2022-01-10 |
| 1 | 평균 구매 주기(일) | 45 |
| 2 | 이름 | 박철수 |
| 2 | 이메일 | mailto:cs.park@email.com |
| 2 | 총 구매 금액 | 2,000,000 |
| 2 | 구매 횟수 | 20 |
| 2 | 구매 상품 카테고리 | 전자기기 |
| 2 | 구매 상품 카테고리 | 도서 |
| 2 | 구매 상품 카테고리 | 식품 |
| 2 | 마지막 구매일 | 2023-04-10 |
| 2 | 첫 구매일 | 2021-12-15 |
| 2 | 평균 구매 주기(일) | 30 |
Wide-Dataset은 한 테이블에 많은 정보를 담아 데이터 검색과 조회 속도는 빠르지만, 데이터 중복과 저장 공간 효율성은 떨어질 수 있습니다.
반면 Long-Format Dataset은 데이터 정규화로 중복을 줄이고 일관성을 유지하기 좋지만, 조회 시 복잡한 쿼리와 조인이 필요해 성능이 저하될 수 있죠.
데이터 마트에서 Wide-Dataset이 많이 활용되는 이유
그렇다면 데이터 마트(DM)에서는 왜 Wide-Dataset이 선호될까요? 여기에는 크게 세 가지 이유가 있습니다.
1. 쿼리 성능 향상
DM은 특정 부서나 비즈니스 도메인에 특화된 데이터 저장소이기 때문에, 해당 영역에서 자주 사용되는 데이터를 중심으로 구성됩니다. 이때 Wide-Dataset을 활용하면 필요한 데이터를 한 테이블에서 모두 조회할 수 있어, 복잡한 조인 연산을 줄일 수 있습니다.
예를 들어 마케팅 부서의 DM을 구축한다고 가정해 보겠습니다.
마케팅 활동에 필요한 고객 정보, 구매 이력, 캠페인 반응 데이터 등을 하나의 Wide-Dataset으로 구성하면, 마케팅 팀에서 필요한 데이터를 빠르게 조회할 수 있습니다.
SELECT
customer_name,
email,
total_purchase,
purchase_count,
product_category,
campaign_response
FROM
marketing_datamart
WHERE
campaign_name = 'Summer Promotion 2023';
위 쿼리처럼 하나의 테이블에서 필요한 데이터를 모두 추출할 수 있어 쿼리 성능이 향상되는 것이죠. 조인 연산이 없어 SQL도 간단해지고 개발 생산성도 높아집니다.
2. 분석 용이성 증대
DM의 주요 목적 중 하나는 비즈니스 의사 결정을 지원하는 것입니다. 이를 위해서는 데이터를 다양한 각도에서 신속하게 분석할 수 있어야 하는데, Wide-Dataset이 이러한 분석 용이성을 크게 높여줍니다.
Wide-Dataset은 분석에 필요한 다양한 속성을 하나의 테이블에 갖고 있어, 별도의 데이터 가공 없이도 즉시 분석에 활용할 수 있습니다. 또한 BI 툴이나 데이터 시각화 도구와의 연계성도 좋아 분석 과정이 훨씬 간편해집니다.
가령 영업 부서의 DM에 고객별 매출 데이터와 함께 고객 등급, 지역, 상품 카테고리 등의 정보를 Wide-Dataset으로 구성했다고 해 보겠습니다.
| 고객 ID | 고객명 | 매출액 | 고객 등급 | 지역 | 구매 상품 카테고리 |
|---|---|---|---|---|---|
| 1 | A 회사 | 10,000,000 | Gold | 서울 | 가전, 가구 |
| 2 | B 상점 | 5,000,000 | Silver | 부산 | 식품, 잡화 |
| 3 | C 기업 | 15,000,000 | Platinum | 서울 | 가전, 가구, 식품 |
이러한 구조라면 매출을 다양한 기준으로 쉽게 분석할 수 있겠죠?
고객 등급별, 지역별, 상품 카테고리별 매출 현황과 추이를 파악하고, 새로운 통찰을 도출하는 것이 훨씬 수월해집니다.
별도의 데이터 변환이나 가공 없이 원본 데이터를 그대로 활용할 수 있어 분석 속도와 효율성이 크게 향상되는 것입니다.
3. 업무 맞춤형 데이터 구조
DM은 특정 부서나 비즈니스 도메인에 최적화된 데이터 구조를 가지는 것이 특징입니다.
따라서 해당 업무에서 자주 사용되는 데이터를 Wide-Dataset 형태로 구성함으로써, 업무 효율성과 사용자 편의성을 높일 수 있습니다.
예를 들어 고객 서비스 부서의 DM을 구축한다면, 상담원들이 문의 처리 시 필요한 정보를 한 테이블에 모두 담아둘 수 있습니다. 고객 정보, 문의 이력, 주문 내역, 배송 상태 등을 하나의 Wide-Dataset으로 구성하면 상담 업무가 훨씬 쉬워지겠죠?
| 문의 ID | 고객명 | 연락처 | 문의 유형 | 주문번호 | 주문일자 | 주문 상품 | 배송 상태 |
|---|---|---|---|---|---|---|---|
| 1 | 김영희 | 010-1234-5678 | 상품 문의 | 20230415-001 | 2023-04-15 | A 상품 | 배송 준비 중 |
| 2 | 박철수 | 010-9876-5432 | 배송 문의 | 20230410-002 | 2023-04-10 | B 상품 | 배송 완료 |
| 3 | 김영희 | 010-1234-5678 | 반품 문의 | 20230415-001 | 2023-04-15 | A 상품 | 배송 준비 중 |
이처럼 Wide-Dataset을 활용하면 상담원이 문의 처리에 필요한 모든 정보를 한 눈에 파악할 수 있습니다. 고객의 문의 내용과 함께 주문 정보, 배송 상태 등을 즉시 확인할 수 있어 신속하고 정확한 응대가 가능해집니다.
또한 Wide-Dataset은 업무에 특화된 데이터 구조로 인해, 해당 부서의 KPI(Key Performance Indicator) 관리에도 효과적입니다.
가령 고객 서비스 부서의 주요 KPI가 '평균 문의 처리 시간'이라면, Wide-Dataset에 문의 접수 시간과 처리 완료 시간을 함께 저장해 둠으로써 손쉽게 KPI를 측정하고 모니터링 할 수 있습니다.
| 문의 ID | 고객명 | 문의 유형 | 접수 시간 | 처리 완료 시간 | 처리 소요 시간(분) |
|---|---|---|---|---|---|
| 1 | 김영희 | 상품 문의 | 2023-04-15 10:30 | 2023-04-15 10:55 | 25 |
| 2 | 박철수 | 배송 문의 | 2023-04-15 11:10 | 2023-04-15 11:20 | 10 |
| 3 | 김영희 | 반품 문의 | 2023-04-15 13:40 | 2023-04-15 14:00 | 20 |
이런 식으로 Wide-Dataset을 구성하면 부서의 성과 지표를 실시간으로 파악하고, 업무 프로세스 개선에 필요한 인사이트를 얻을 수 있게 됩니다.
이렇듯 DM에서 Wide-Dataset을 활용하면 업무에 최적화된 데이터 구조를 구현할 수 있습니다. 이는 단순히 데이터 조회 성능을 높이는 것을 넘어, 업무 효율성 향상과 KPI 관리 강화 등 실질적인 비즈니스 가치 창출로 이어질 수 있습니다.
부서별 업무 특성을 깊이 이해하고 이에 맞는 Wide-Dataset을 설계하는 것이 DM 구축의 핵심 포인트라 할 수 있겠습니다.

Wide-Dataset의 단점: 데이터 중복과 일관성 유지의 어려움
Wide-Dataset은 데이터 마트에서 많은 이점을 제공하지만, 몇 가지 단점도 존재합니다. 가장 큰 문제는 데이터 중복과 일관성 유지의 어려움입니다.
1. 데이터 중복으로 인한 저장 공간 낭비
Wide-Dataset은 하나의 테이블에 많은 속성을 포함하기 때문에, 데이터 중복이 발생할 가능성이 높습니다. 특히 여러 테이블에서 공통으로 사용되는 속성의 경우, Wide-Dataset에서 중복되어 저장될 수 있습니다.
예를 들어 이커머스 회사의 DM을 구축한다고 가정해 봅시다. 주문 정보를 담은 Wide-Dataset을 아래와 같이 구성했다면,
| 주문 ID | 주문일자 | 고객명 | 고객 이메일 | 상품명 | 상품 가격 | 구매 수량 | 총 주문 금액 | 배송 주소 | 배송 상태 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2023-04-01 | 김영희 | mailto:yh.kim@email.com | A 상품 | 10,000 | 2 | 20,000 | 서울시 강남구 | 배송 완료 |
| 2 | 2023-04-03 | 박철수 | mailto:cs.park@email.com | B 상품 | 20,000 | 1 | 20,000 | 경기도 성남시 | 배송 중 |
| 3 | 2023-04-05 | 김영희 | mailto:yh.kim@email.com | C 상품 | 15,000 | 3 | 45,000 | 서울시 강남구 | 배송 준비 중 |
고객명, 고객 이메일, 배송 주소 등의 정보가 중복되어 저장되는 것을 확인할 수 있습니다. 이런 중복 데이터는 저장 공간을 비효율적으로 사용하게 만듭니다.
특히 대용량 데이터를 다루는 경우, 중복 데이터로 인한 저장 공간 낭비는 더욱 심각해질 수 있습니다. 데이터가 증가할수록 중복 데이터도 함께 늘어나므로, 스토리지 비용 증가와 관리 부담으로 이어질 수 있습니다.
2. 데이터 변경 시 일관성 유지의 어려움
Wide-Dataset의 또 다른 단점은 데이터 변경 시 일관성을 유지하기 어렵다는 것입니다.
Wide-Dataset에서는 여러 속성이 하나의 테이블에 함께 존재하므로, 특정 속성 값이 변경되면 해당 속성을 포함한 모든 레코드에 동일한 변경이 반영되어야 합니다.
앞서 예시로 든 주문 정보 Wide-Dataset에서, 만약 '김영희' 고객의 이메일 주소가 변경되어야 한다면 어떻게 될까요?
| 주문 ID | 주문일자 | 고객명 | 고객 이메일 | 상품명 | 상품 가격 | 구매 수량 | 총 주문 금액 | 배송 주소 | 배송 상태 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2023-04-01 | 김영희 | mailto:yh.kim@email.com | A 상품 | 10,000 | 2 | 20,000 | 서울시 강남구 | 배송 완료 |
| 2 | 2023-04-03 | 박철수 | mailto:cs.park@email.com | B 상품 | 20,000 | 1 | 20,000 | 경기도 성남시 | 배송 중 |
| 3 | 2023-04-05 | 김영희 | mailto:yh.kim@newemail.com | C 상품 | 15,000 | 3 | 45,000 | 서울시 강남구 | 배송 준비 중 |
'김영희' 고객의 모든 주문 레코드에 대해 이메일 주소를 일괄 업데이트해야 합니다.
간단한 예시에서는 크게 문제될 것이 없어 보이지만, 실제 비즈니스 환경에서는 수십, 수백만 건의 레코드를 다루는 경우가 많습니다.
이럴 때는 데이터 변경 작업이 매우 복잡해지고 오류 발생 위험도 높아집니다.
또한 데이터 변경 과정에서 일관성을 보장하기 위해 복잡한 업데이트 로직과 트랜잭션 관리가 필요합니다. 모든 관련 레코드에 대한 변경이 동시에, 정확하게 이루어져야 하므로, 데이터 관리 측면에서 많은 주의와 노력이 요구됩니다.

그럼에도 불구하고 데이터 마트에서 Wide-Dataset을 사용하는 이유?
데이터 중복과 일관성 유지 문제라는 단점에도 불구하고,
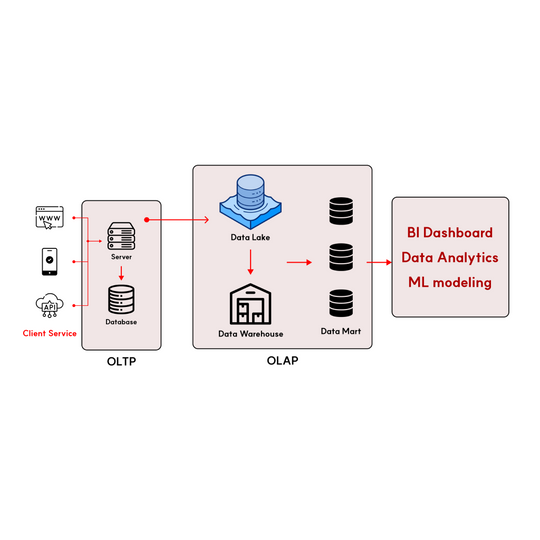
DM에서 Wide-Dataset을 사용하는 이유는 OLTP(Online Transaction Processing)와 OLAP(Online Analytical Processing)의 역할 차이에서 찾을 수 있습니다.
이 두 개념은 데이터베이스 시스템의 활용 목적과 방식에 따라 구분되는데, 각각의 특성을 이해하는 것이 Wide-Dataset의 활용 맥락을 파악하는 데 도움이 될 것입니다.
OLTP: 실시간 트랜잭션 처리에 최적화된 시스템
OLTP(Online Transaction Processing)는 비즈니스 운영 과정에서 발생하는 트랜잭션을 실시간으로 처리하는 시스템을 말합니다.
트랜잭션이란 데이터베이스의 상태를 변화시키는 하나의 논리적인 작업 단위로, 예를 들어 이커머스 플랫폼에서 고객의 주문, 결제, 배송 등이 모두 트랜잭션에 해당합니다.
OLTP 시스템은 이러한 트랜잭션을 빠르고 안정적으로 처리하는 데 초점을 둡니다. 고객이 웹사이트에서 주문을 플랫폼에 넣으면 즉시 처리되어야 하며, 재고 관리, 결제 승인, 배송 요청 등 후속 프로세스도 신속하게 진행되어야 합니다.
따라서 OLTP 시스템은 짧은 응답 시간, 높은 동시성 처리 능력, 그리고 데이터 무결성 보장이 핵심 요구 사항입니다.
이를 위해 OLTP 시스템에서는 일반적으로 정규화된 데이터 모델을 사용합니다. 정규화란 데이터 중복을 최소화하고 독립성을 높이는 데이터 구조화 과정으로, 여러 개의 관련 테이블로 데이터를 분산 저장하는 것이 특징입니다.
이는 데이터 일관성 유지에 유리하고 저장 공간도 효율적으로 활용할 수 있지만, 복잡한 조인 연산으로 인해 쿼리 성능이 떨어질 수 있다는 단점이 있습니다.
하지만 OLTP 시스템에서는 단순한 구조의 쿼리가 대부분이고, 데이터 무결성이 매우 중요하므로 정규화된 데이터 모델이 적합합니다.
예를 들어 고객 정보를 Customer 테이블에, 주문 정보를 Order 테이블에, 상품 정보를 Product 테이블에 따로 저장하고, 각 테이블 간의 관계를 키(Key)로 정의하는 것이 일반적인 OLTP 데이터 모델링 방식입니다.
OLAP: 대량 데이터 분석에 최적화된 시스템
반면 OLAP는 의사 결정 지원을 위해 대량의 데이터를 다양한 각도에서 신속하게 분석하는 시스템을 말합니다. DW(Data Warehouse)나 DM(Data Mart)이 OLAP 시스템의 대표적인 예로, 여러 운영 시스템(OLTP)의 데이터를 추출, 변환, 적재(ETL)하여 분석에 용이한 형태로 저장합니다.
OLAP 시스템의 주된 목적은 경영진이나 비즈니스 사용자들이 데이터 기반의 전략적 의사 결정을 내릴 수 있도록 지원하는 것입니다. 이를 위해 매출 추이 분석, 고객 세그먼테이션, 상품 선호도 분석 등 다양한 분석 쿼리를 수행하게 되는데, 이때는 대량의 데이터를 복잡한 조건으로 조회하고 집계하는 것이 일반적입니다.
따라서 OLAP 시스템에서는 쿼리 성능과 사용자 편의성이 가장 중요한 고려 사항입니다. 수억, 수십억 건의 데이터를 대상으로 복잡한 분석 쿼리를 수행해야 하므로, 빠른 응답 속도와 사용자 친화적인 데이터 구조가 필수적입니다.
이를 위해 OLAP 시스템에서는 주로 비정규화된 데이터 모델, 특히 스타 스키마(Star Schema)나 눈송이 스키마(Snowflake Schema) 같은 다차원 모델을 사용합니다.
다차원 모델은 팩트(Fact) 테이블과 차원(Dimension) 테이블로 구성되는데, 팩트 테이블은 측정 가능한 수치 데이터를 담고, 차원 테이블은 팩트를 설명하는 속성 정보를 담습니다. 이 둘을 조인하여 다양한 분석 쿼리를 수행하게 되는데, 이때 Wide-Dataset을 활용하면 쿼리 성능을 크게 향상시킬 수 있습니다.
Wide-Dataset은 팩트 테이블과 차원 테이블을 미리 조인하여 하나의 넓은 테이블로 구성한 것입니다. 이렇게 하면 분석 쿼리 수행 시 테이블 간의 조인 연산을 줄일 수 있어 쿼리 속도가 빨라집니다.
예를 들어 매출 분석을 위한 다차원 모델을 생각해 봅시다. 팩트 테이블인 Sales에는 제품, 고객, 지역, 시간 등 각 차원에 대한 외래 키와 매출액, 수량 등의 측정 값이 저장됩니다.
[팩트 테이블]
Sales:
| sales_id | product_id | customer_id | region_id | date_id | sales_amount | quantity |
|---|---|---|---|---|---|---|
| 1 | 101 | 1001 | 201 | 20230101 | 1000 | 10 |
| 2 | 102 | 1002 | 202 | 20230101 | 1500 | 15 |
| 3 | 101 | 1003 | 201 | 20230102 | 2000 | 20 |
[차원 테이블]
Product:
| product_id | product_name | category | price |
|---|---|---|---|
| 101 | 상품A | 카테고리1 | 100 |
| 102 | 상품B | 카테고리2 | 150 |
Customer:
| customer_id | customer_name | age | gender |
|---|---|---|---|
| 1001 | 고객1 | 25 | 남 |
| 1002 | 고객2 | 30 | 여 |
| 1003 | 고객3 | 40 | 남 |
Region:
| region_id | region_name |
|---|---|
| 201 | 서울 |
| 202 | 부산 |
Date:
| date_id | year | month | day |
|---|---|---|---|
| 20230101 | 2023 | 1 | 1 |
| 20230102 | 2023 | 1 | 2 |
이제 "2023년 1월의 지역별, 카테고리별 매출 합계"를 구하는 쿼리를 생각해 보겠습니다.
SELECT
r.region_name,
p.category,
SUM(s.sales_amount) AS total_sales
FROM
Sales s
JOIN Product p ON s.product_id = p.product_id
JOIN Region r ON s.region_id = r.region_id
JOIN Date d ON s.date_id = d.date_id
WHERE
d.year = 2023 AND d.month = 1
GROUP BY
r.region_name,
p.category;
위 쿼리는 4개의 테이블(Sales, Product, Region, Date)을 조인하고 있습니다. 데이터 량이 클수록 조인으로 인한 부하가 증가하여 쿼리 성능이 저하될 수 있습니다.
이때 Wide-Dataset을 활용하면 이러한 문제를 해결할 수 있습니다. 팩트 테이블과 모든 차원 테이블을 미리 조인하여 하나의 Wide-Dataset을 생성해 두는 것입니다.
[Wide-Dataset]
Sales_Wide:
| sales_id | product_id | product_name | category | price | customer_id | customer_name | age | gender | region_id | region_name | date_id | year | month | day | sales_amount | quantity |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 101 | 상품A | 카테고리1 | 100 | 1001 | 고객1 | 25 | 남 | 201 | 서울 | 20230101 | 2023 | 1 | 1 | 1000 | 10 |
| 2 | 102 | 상품B | 카테고리2 | 150 | 1002 | 고객2 | 30 | 여 | 202 | 부산 | 20230101 | 2023 | 1 | 1 | 1500 | 15 |
| 3 | 101 | 상품A | 카테고리1 | 100 | 1003 | 고객3 | 40 | 남 | 201 | 서울 | 20230102 | 2023 | 1 | 2 | 2000 | 20 |
Sales_Wide 테이블을 활용하면 조인 없이 간단한 쿼리로 결과를 얻을 수 있습니다.
SELECT
region_name,
category,
SUM(sales_amount) AS total_sales
FROM
Sales_Wide
WHERE
year = 2023 AND month = 1
GROUP BY
region_name,
category;
실행 계획을 살펴보면 조인이 사라져 쿼리 속도가 빨라진 것을 확인할 수 있습니다. 특히 대용량 데이터를 다룰 때 Wide-Dataset의 성능 개선 효과는 더욱 두드러집니다.
결론
OLAP 시스템에서 Wide-Dataset은 ad-hoc 분석과 대시보드 구축에 있어 매우 유용하고 효과적인 데이터 구조입니다. 특히 비즈니스 사용자들이 데이터를 탐색하고 즉각적인 통찰을 얻는 ad-hoc 분석 시나리오에서 Wide-Dataset의 진가가 극대화됩니다.
Ad-hoc 분석은 사전에 정의된 쿼리나 리포트가 아닌, 사용자의 spontaneous한 질문에 따라 그때그때 데이터를 탐색하고 분석하는 방식을 말합니다. 이때 분석 대상과 관점이 수시로 변경되므로, 데이터 구조의 유연성과 쿼리의 간결성이 매우 중요한 요소로 작용합니다.
바로 이 지점에서 Wide-Dataset의 장점이 부각됩니다. Wide-Dataset은 특정 주제 영역의 모든 주요 정보를 하나의 테이블에 모아두기 때문에, 사용자는 복잡한 조인 없이도 다양한 각도에서 데이터를 손쉽게 탐색할 수 있습니다. 관심 있는 측정값과 차원을 선택하여 간단한 필터링과 집계만으로도 원하는 정보를 즉시 추출할 수 있는 것이죠. 이는 ad-hoc 분석의 민첩성과 유연성을 크게 높여줍니다.
또한 Wide-Dataset은 비즈니스 용어 기반의 컬럼 구조를 가지므로, 사용자들이 데이터의 의미를 직관적으로 이해할 수 있습니다. 이는 ad-hoc 분석 과정에서 사용자의 자율성과 참여도를 높이는 요인으로 작용합니다. 데이터에 대한 이해도가 높아질수록 사용자들은 더욱 다양하고 심도 있는 질문을 던지게 되고, 이는 곧 새로운 인사이트 발견으로 이어질 수 있습니다.
Analytics Engineer(관련 글 참고)는 이러한 Wide-Dataset의 설계와 구현을 책임집니다. 비즈니스 요구사항과 사용자 관점을 깊이 이해하고, 이를 데이터 구조에 반영하는 것이 핵심 역할이죠. 나아가 구축된 Wide-Dataset을 활용하여 실제 분석을 수행하고 대시보드로 구현하는 전 과정을 주도합니다. 따라서 Analytics Engineer에게는 데이터 분석과 시각화 역량이 고루 요구됩니다.
![[Monthly Webinar VOD] 노션과 하트카운트로 100점짜리 보고서 쓰기](/ko/content/images/size/w360/2024/04/4---_---------------------1080_1080.png)