AI 생각하면 슬픈데 웃음이 나요.
슬픈 상황의 원인이 나에게 있는 경우 슬프면서도 화가 납니다. 반대로, 그 원인이 어쩔 수 없는 것이라면 슬픈데 웃음이 납니다.
AI가 몰고 온 변화, 우리 기술과 제품이 언제 쓸모없어질지 모를 상황을 마주하면 슬픈데 어쩔 도리가 없어 헛웃음이 납니다.
하지만, 기업 내 데이터 분석과 관련해, 그동안 풀리지 않았던 모든 문제가 AI로 해결될 수는 없습니다. 특히 서버 자원을 활용한 데이터 분석은 데이터 민주화의 큰 걸림돌이었습니다. 이 글에서 서버 자원을 활용한 데이터 분석의 문제점을 짚고, In-Broswer Analytics이 왜 그 해결책이 될 수 있는지 이야기합니다.
컴퓨팅 패러다임의 회귀
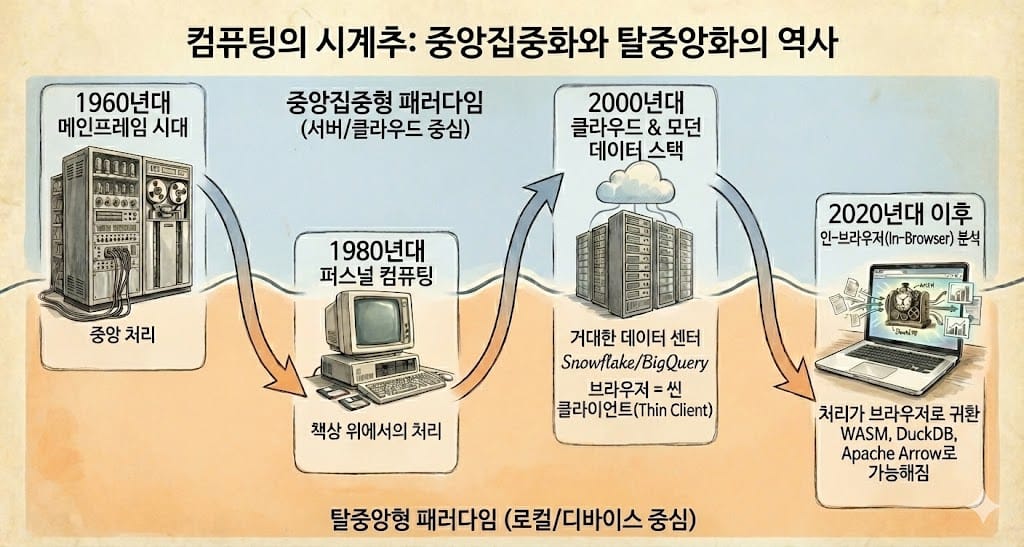
컴퓨팅의 역사는 시계추처럼 중앙집중화와 탈중앙화 사이를 오가며 발전해 왔습니다. 1960년대 메인프레임 시대의 중앙 처리는 1980년대 퍼스널 컴퓨터의 등장으로 개인의 책상 위로 이동했고, 2000년대 클라우드 컴퓨팅의 부상과 함께 다시 거대한 데이터 센터로 무게중심이 옮겨갔습니다.
지난 10년간 데이터 분석 업계의 만트라였던 '모던 데이터 스택(Modern Data Stack)'은 데이터와 연산을 Snowflake, BigQuery 같은 클라우드 데이터 웨어하우스에 집중시켜 왔습니다. 이 모델에서 사용자의 브라우저는 서버에서 미리 계산된 결과물을 표시해주는 역할, 즉 Thin Client에 불과했습다.
하지만, WebAssembly(WASM), 고성능 컬럼형 데이터베이스(DuckDB), 초고속 데이터 전송 포맷(Apache Arrow) 같은 기술이 성숙하면서, 데이터 처리의 무게 중심이 다시금 사용자의 로컬 디바이스, 즉 브라우저로 이동하고 있습니다.
데이터 분석 아키텍처의 진화
현재의 변화를 보다 더 잘 이해하기 위해 데이터 분석 아키텍처의 역사를 살펴보겠습니다.
1세대: 데스크탑 기반 분석 (Excel의 시대)
초기 데이터 분석은 로컬 머신의 성능에 전적으로 의존했습니다. Excel이나 Access 같은 도구는 데이터가 사용자의 하드 드라이브에 존재하고, 연산 역시 로컬 CPU에서 수행되는 전형적인 Thick Client 모델이었습니다.
장점은 즉시성(Immediacy)이었습니다. 네트워크 지연이 없었기 때문에 반응이 즉각적이었습니다. 다만 로컬 메모리 크기한계가 분석할 수 있는 데이터 크기의 한계였습니다.
2세대: 서버 사이드 컴퓨팅과 엔터프라이즈 BI
데이터 규모가 커지면서 Tableau Server, MicroStrategy 같은 도구들이 등장했습니다. 강력한 서버에서 쿼리를 처리하고, 결과만 클라이언트로 전송하는 방식이 표준으로 자리잡았습니다. 이 과정에서 클라이언트의 역할은 점점 축소되었습니다.
3세대: 클라우드 네이티브와 SaaS (Modern Data Stack)
Snowflake, Redshift의 등장은 스토리지와 컴퓨팅을 분리하고 무한한 확장성을 제공했습니다. Looker, Mode 같은 BI 도구들은 100% 웹 기반으로 동작하며, 브라우저는 순수하게 시각화 레이어로만 기능했습니다.
이 모델은 페타바이트 규모의 데이터 처리를 가능하게 했지만, 상호작용의 지연(Interaction Latency)이라는 새로운 문제를 낳았습니다. 대시보드의 필터 하나 변경할 때마다 무한히 도는 로딩 스피너를 바라봐야 하는 경험은 분석가(실무자)의 인지적 몰입을 방해하는 주요 요인이 되었습니다.
4세대: In-Browser Analytics의 부상
이제 우리는 4세대로 진입하고 있습니다. 최신 맥북의 M 시리즈 칩셋은 웬만한 서버 인스턴스보다 강력한 단일 코어 성능을 보여줍니다. 동시에 브라우저 기술, 특히 WASM의 발전은 "데이터를 저 멀리 서버로 떠나 보내는 대신, 분석 엔진을 데이터가 있는 바로 그 곳(브라우저)에서 제공하는" 일을 현실로 만들고 있습니다.
| 구분 | 1세대 (Desktop) | 2세대 (Server BI) | 3세대 (Cloud SaaS) | 4세대 (In-Browser) |
|---|---|---|---|---|
| 대표 도구 | Excel | Tableau Server | Looker, Snowflake UI | HEARTCOUNT, DuckDB-WASM |
| 연산 위치 | 로컬 CPU | 사내 서버 | 클라우드 클러스터 | 로컬 브라우저 (WASM) |
| 장점 | 반응 속도, 프라이버시 | 데이터 거버넌스 | 무한한 확장성 | 반응 속도, 프라이버시, 무설치 |
| 단점 | 공유 어려움, 용량 제한 | 인프라 비용 | 네트워크 지연, 클라우드 비용 | 메모리 제한 |
왜 In-Browser Analytics인가?

업로드·적재 대기 없이, 바로 돌려볼 수 있습니다.
전통적인 데이터 분석에서는 데이터를 서버에 올리고 권한 설정하고 쿼리 날리고 기다려야 합니다. 반면, 브라우저 기반 분석은 다릅니다. 사용자가 접근할 수 있는 데이터셋에서 바로 쿼리와 탐색을 시작할 수 있습니다.
서버 병목과 비용을 줄일 수 있습니다.
동시 사용자가 늘어날수록 서버 분석 시스템은 쿼리 부하가 빠르게 증가합니다. 브라우저에서 분석을 처리하면 서버는 공유, 정책, 복구 같은 '관리 기능'에 집중할 수 있고, 분석 연산은 사용자 컴퓨팅 환경(브라우저)으로 분산할 수 있습니다.
왜 In-Browser Analytics이 가능해졌나?
WebAssembly (WASM)
자바스크립트가 갖는 인터프리터 실행 모델, 동적 타이핑, 가비지 컬렉션 등 언어 특성상 수백만 건의 데이터를 브라우저에서 직접 집계, 분석하는 작업이 과거에는 쉽지 않았습니다.
WebAssembly는 흔히 브라우저 안에서 돌아가는 초고속 엔진으로 설명됩니다. 기존에는 데스크톱 애플리케이션에서만 가능하다고 여겨졌던 무거운 연산을, 브라우저 환경에서도 수행할 수 있게 해줍니다.
실제로 Figma 같은 디자인 도구처럼 고성능이 필요한 애플리케이션이 브라우저에서 동작할 수 있는 배경에도 WASM이 있습니다. 그리고 이 흐름이 이제 데이터 분석 영역으로 확장되고 있습니다.
보안 측면에서도 WASM은 브라우저가 제공하는 샌드박스(안전한 실행 환경) 안에서 실행되며, 사용자의 파일 시스템이나 다른 프로그램에 임의로 접근할 수 없습니다.
DuckDB: 분석을 위한 임베디드 SQL 엔진
브라우저에는 이미 IndexedDB나 sql.js(SQLite의 WASM 포팅) 같은 DB 기능을 제공하는 기술이 존재해 왔습니다. 다만, 이들은 기본적으로 OLTP(Online Transaction Processing) 사용 패턴에 최적화되어 있어, 대규모 집계, 분석 쿼리를 처리하기에는 한계가 있었습니다.
DuckDB는 "분석 전용 경량 데이터베이스"입니다. 브라우저 안에서도 수백만 건의 데이터를 빠르게 집계할 수 있게 해줍니다. 왜 빠를까요? 데이터 저장 방식이 다릅니다.
일반 데이터베이스는 데이터를 "행(row)" 단위로 저장합니다. 한 사람의 정보(이름, 나이, 주소, 가격)가 한 줄에 묶여 있는 식이죠. 그래서 "전체 고객의 평균 가격"을 구하려면 모든 행을 읽으면서 가격만 쏙쏙 골라내야 합니다.
DuckDB는 데이터를 "열(column)" 단위로 저장합니다. 가격은 가격끼리, 이름은 이름끼리 모아두는 방식입니다. 평균 가격을 구할 때 가격 데이터만 읽으면 되니, 불필요한 데이터를 건너뛸 수 있습니다. 읽는 양이 줄어드니 당연히 빠릅니다.
DuckDB-WASM이 브라우저에 로드되는 순간, 사용자의 브라우저는 완전한 기능의 SQL 기반 OLAP 실행 환경을 갖추게 됩니다.
Apache Arrow: Zero-Copy(불필요한 복사 없이) 데이터 전송
데이터 분석을 하다 보면 CSV나 Excel 파일을 데이터베이스에 import(적재) 하는 과정이 필요합니다. 파일을 읽고, 타입을 맞추고, 테이블로 변환해 저장하는 단계가 따라오며, 데이터가 크면 이 과정만으로도 시간이 꽤 걸릴 수 있습니다.
하지만 Parquet를 지원하는 분석 엔진(DuckDB 등)을 사용하면, 파일을 별도로 적재하지 않고도 Parquet를 그대로 스캔해 SQL로 바로 조회할 수 있습니다. 즉, “파일 → 변환 → 테이블 → 쿼리”가 아니라 “파일 → 쿼리”로 흐름이 단순해집니다.
SELECT region, AVG(price)
FROM 'sales.parquet'
GROUP BY region;Python에서도 Parquet는 곧바로 읽어 사용할 수 있습니다.
import pandas as pd
df = pd.read_parquet("sales.parquet")여기서 Apache Arrow는 Parquet와 역할이 다릅니다. Parquet가 “디스크에 저장된 파일 포맷”이라면, Arrow는 “메모리에서 데이터를 주고받기 위한 표준 포맷”입니다. Arrow를 사용하면 쿼리 엔진의 결과를 시각화 레이어나 Python 등으로 전달할 때 불필요한 변환·복사를 줄여 더 빠르고 효율적인 데이터 전달(때로는 zero-copy에 가까운 방식)이 가능해집니다.
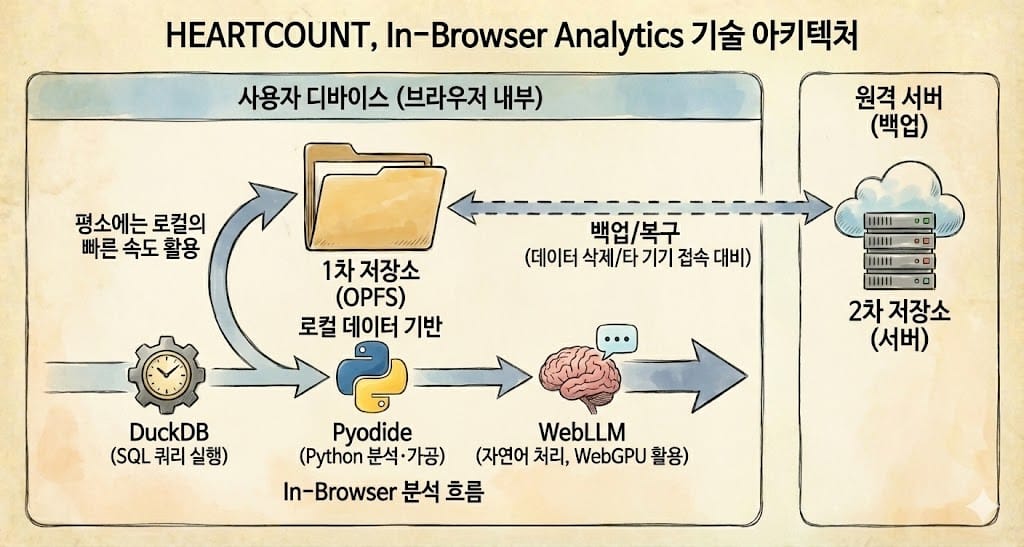
HEARTCOUNT, In-Browser Analytics 기술 아키텍처
| 기술 | 역할 |
|---|---|
| DuckDB-WASM | 브라우저에서 돌아가는 분석용 데이터베이스. 수백만 건 데이터도 SQL로 빠르게 집계 |
| OPFS | 브라우저 전용 저장 공간. 데이터를 로컬에 저장해 빠르게 불러오고, 분석 상태를 유지 |
| Pyodide | 브라우저에서 Python 실행. pandas, NumPy 등 데이터 분석 라이브러리 사용 가능 |
| WebLLM | 브라우저에서 AI 모델 실행 (실험 중) |
HEARTCOUNT는 데이터를 두 곳에 저장합니다.
- 1차 저장소 (OPFS): 브라우저 내부의 전용 저장 공간입니다. 내 컴퓨터에 있으니 읽고 쓰는 속도가 빠릅니다.
- 2차 저장소 (서버): 브라우저 데이터가 삭제되거나 다른 기기에서 접속할 때를 대비한 백업용입니다.
평소에는 로컬(OPFS)의 빠른 속도를 누리고, 문제가 생기면 서버에서 복구합니다.
로컬에 저장된 데이터로 브라우저 안에서도 할 수 있는 일이 빠르게 넓어지고 있습니다. 예를 들어 DuckDB로는 SQL 쿼리를 바로 실행할 수 있고, Pyodide(Python WASM)를 활용하면 별도 서버 없이 브라우저에서 Python을 실행해 분석·가공을 이어갈 수 있습니다.
여기에 WebLLM까지 더하면, 브라우저에서 LLM을 직접 구동해(대개 WebGPU 등 브라우저의 가속 기능을 활용) 자연어 질문을 해석하거나 요약·분류·쿼리 생성 같은 보조 작업을 공짜로 수행할 수도 있습니다. 로컬 데이터 기반으로 SQL → Python → LLM까지 하나의 in-browser 분석 흐름으로 묶을 수 있습니다.
돈이 되는, 최소 낭비는 없는, 데이터 분석
클라우드나 온프레미스 기반의 분석 시스템을 운영하면, 사용 빈도나 동시 사용자 수가 늘어날수록 인프라 비용도 함께 증가하는 경우가 많습니다. 서버는 더 많은 쿼리를 처리해야 하고, 그만큼 컴퓨팅 자원을 확장해야 하기 때문입니다.
반면 In-Browser Analytics 모델에서는 분석 연산의 상당 부분이 서버가 아니라 사용자의 로컬 디바이스(노트북/브라우저)에서 수행됩니다. 고객 입장에서는 “사용이 늘수록 비용이 늘어나는 구조”가 크게 완화될 수 있습니다.
특히 BigQuery나 Snowflake처럼 Compute 사용량에 따라 과금되는 환경에서는, 비효율적인 쿼리 한 번이 예상치 못한 비용으로 이어질 수 있습니다. 반면 In-Browser 환경에서 생각할 수 있는 ‘최악의 시나리오’는 요금 폭탄이 아니라, 브라우저 탭이 느려지거나 멈추는 정도입니다.
아주 큰 데이터는 브라우저에서 분석 못 하지 않나요?
맞습니다. 브라우저가 무한한 컴퓨팅 자원을 제공하지는 않습니다. 예를 들어 Chrome은 환경에 따라 차이가 있지만, 메모리 사용량이 수 GB 수준을 넘어가면 성능 이슈가 발생할 수 있습니다. 관건은 브라우저가 모든 걸 감당할 수 있느냐가 아니라, 필요한 만큼의 데이터만 가져와 로컬에서 빠르게 처리하도록 데이터의 흐름을 바꾸는 것입니다.
즉, "서버를 없애자"는 이야기가 아닙니다. 서버에 몰려 있던 분석 부담을 사용자 측으로 분산하고, 서버는 공유, 권한, 정책, 복구 같은 관리 기능에 집중하는 구조입니다.
HEARTCOUNT AI Analytics 제품 역시 테라바이트급 원천 데이터를 통째로 브라우저에서 처리하지 못합니다. 현업이 손에 쥔 "작지만 중요한 수백 MB ~ 수십 GB 규모의 데이터를 사용자가 주체적으로 깊게 탐색하는 상황에 더 잘 맞습니다.
맺으며: 가이사의 것, AI의 것, 내 것
페라리타고 편의점 가지 말기
모든 분석 작업을 비싼 에너지와 자원을 들여 서버나 LLM이 수행하도록 할 필요는 없습니다. 어떤 일은 서버가 맡는 것이 합리적이고, 어떤 일은 AI가 보조하는 것이 더 생산적이며, 또 어떤 일은 사용자의 PC에서 처리하는 편이 더 빠르고 효율적일 수 있습니다.
Sovereign Analyst
저는 주체적으로, 그리고 지속가능한 방식으로 데이터 분석을 수행하는 실무자들을 "Sovereign Analyst(주권적 분석가)"라고 명명해 보았습니다. Sovereign Analyst에게 필요한 것은 데이터 분석 역량만이 아닙니다. 이제, 분석을 위한 지속 가능한 컴퓨팅 자원의 확보 또한 중요하다고 생각합니다.
데이터를 활용하는 실무자가 더 이상 중앙 서버의 자원을 배정받기를 기다리는 수동적 사용자가 아니라, 온전히 자신의 것인 PC 안에서 데이터를 자유롭게 분석하고 활용하는 주체적 분석가로 진화하길 기대합니다.
HEARTCOUNT가 만들어가는 자유로운 분석 경험이 궁금하다면 지금 바로 살펴보세요. 시각화/AI 자동 분석 도구를 무료로 이용할 수 있습니다.
함께 읽으면 좋은 글
 Sidney Yang
Sidney Yang Sidney Yang
Sidney Yang David Gu
David Gu