はじめに
マレーシアのスターバックスサーベイを使った資料について、マレーシアにおけるスターバックスのサービススコアの要因を分析したいと思います。きめ細かく需要層に対して分析することで、質問項目に対する結果の値が肯定的に評価されたグループや、その逆のグループで不足していると評価されるニーズを綿密に検討した後、これをターゲティングしてマーケティングを行うことができるという考えでアンケートを分析したいと思います。今後、同じルートで国内のデータセットを使って分析をしてみたいと考えています。
データセット
- スターバックスの顧客アンケートに関するアンケートデータ分析
公開されているアンケートデータをHEARTCOUNTを使って分析してみましょう。
スターバックスでの購買行動に関する100人以上の回答者のアンケート質問で構成されています。金額はマレーシア・リンギット(RM)で表わされ、分析に使用するデータは、2019年度にマレーシアのスターバックスの顧客に対してアンケートを実施した結果です。合計で20の質問から構成されており、大部分は5点満点(Strongly disagree (強く同意しない): 1点、Strongly agree (強く同意する); 5点)のいずれかを選択するように設計されています。
質問を構成する主な項目は以下の通りです。
- 顧客に関する人口統計情報 - 性別、年齢、雇用形態、所得
- スターバックスでの現在の購入行動
- 行動に影響を与えるスターバックスの施設や機能
元のデータを確認するには以下を参照ください:
HEARTCOUNTでの分析
スモールマルチプル: 全体を一目で見る
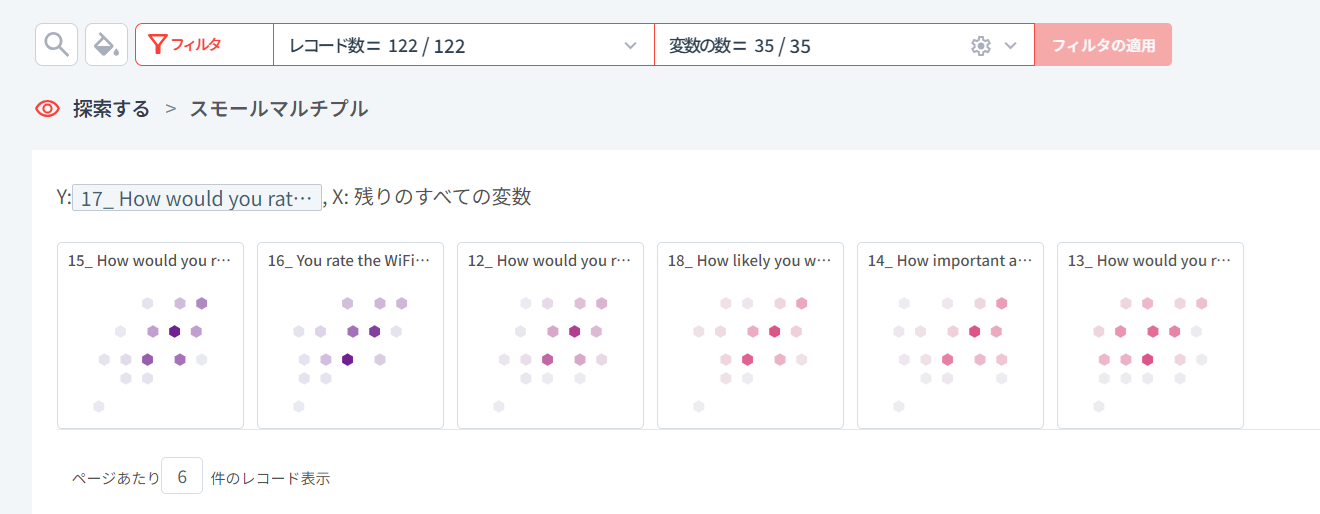
まず、下図のようにスモールマルチプルで「サービススコア」の質問項目(17. How would you rate the service at Starbucks? (Promptness, friendliness, etc..))の回答スコア(5点満点)と他の質問項目の回答スコアとの相関関係(Correlation)を降順で確認してみました。
<手順>
分析したい変数をY軸に設定すると、相関係数が高い順に結果が表示されます。
絶対値が1に近ければ近いほど、2つの変数は高い線形関係をもつ
線形関係
x値とy値が直線的に互いに比例(一方が増加すると、もう一方も増加(正の相関関係)したり、または減少(負の相関関係)したりする)
<分析結果の解釈>
相関係数の絶対値の大きさで上位4つを見ると:
- 1位: 「雰囲気スコア: 15. How would you rate the ambiance at Starbucks? (lighting, music, etc...)」と最も大きな正の相関関係(+0.6)
- 2位: 「WiFiスコア: 16. You rate the WiFi quality at Starbucks as..」 と2番目に大きな正の相関関係(+0.58)。
- 3位: 「他ブランドに対する品質スコア: 12. How would you rate the quality of Starbucks compared to other brands (Coffee Bean, Old Town White Coffee..) to be:」と正の相関関係 (+0.45)
- 4位: 「ビジネス利用やプライベート利用の可能性スコア: 18. How likely you will choose Starbucks for doing business meetings or hangout with friends?」 と正の相関関係(+0.43)
ここで「雰囲気スコア」と「WiFiスコア」は満足度(サービススコア)の原因(Cause)に近いです。相関関係の高い他の項目を要因(Cause)と見なすこともできます。
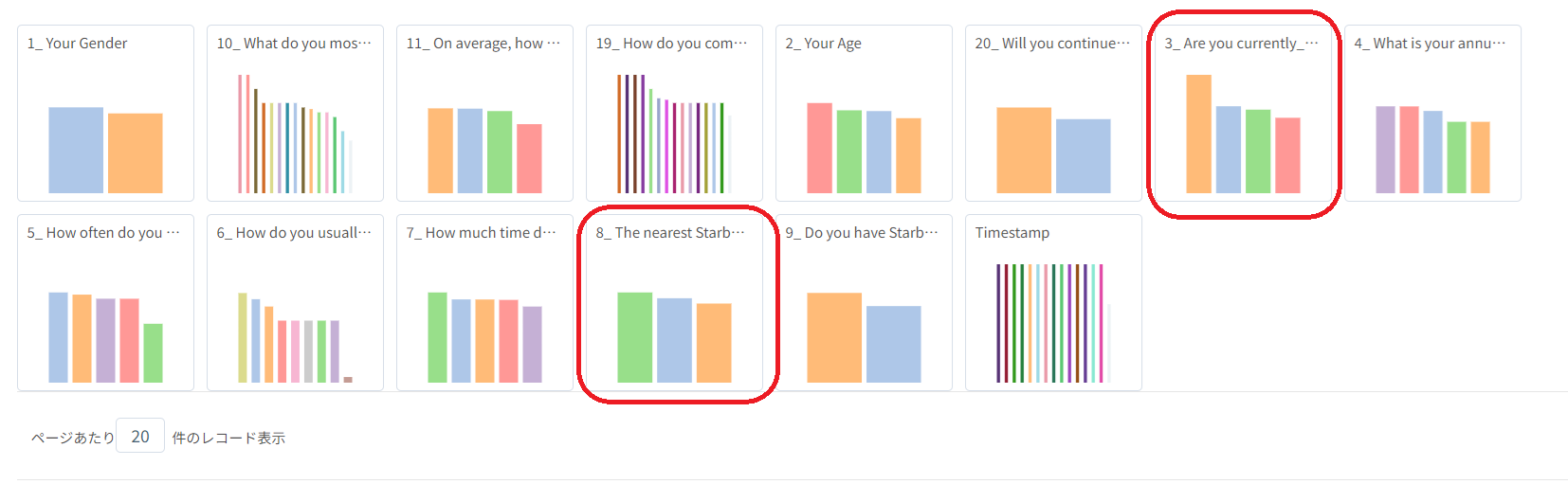
5点満点以外の複数選択式の質問項目のうち、現在の状態(3. Are you currently....?) / アクセシビリティ(8. The nearest Starbucks's outlet to you is...?)に関する回答のタイプ別に満足度のスコア(サービススコア)を比較してみると、以下のことが分かります。
(満足度全体の平均スコア: 3.75)
- 現在の状態: Housewife (平均: 5) > Employed (3.89) > Self-Employed (3.76) > Student (3.48)
- アクセシビリティ: within 1km (平均: 4) > 1km - 3km (3.79) > more than 3km (3.61)
ドリルダウン: 変数の組み合わせによるランキング
スモールマルチプルでは、高いアクセシビリティ、現在の状態が「主婦(Housewife)」のグループが高い満足度(サービススコア)を示した結果に促され、ドリルダウンメニューからアクセシビリティと現在の状態によるサービススコア(満足度)を比較してみました。
<手順>
- ドリルダウンで平均を比較したい変数を選択します。
- 3つの形式の中から3番目の形式を選択すると、「全体平均」の基準で平均から遠い順に一目で確認することができます。
- より有意義な分析のために、以下の例のように最小レコード数を設定することができます。
- ドリルダウンする条件(変数の組み合わせ)を引き続き追加することができます。
<分析結果の解釈>
- 驚くべきことに、現在の状態が「Housewife」で、アクセシビリティが「more than 3km」であるグループが5点で一番サービス満足度が高くなります(右側の1行目)。
- 一方、現在の状態が「Student」で、アクセシビリティが「more than 3km」のグループが3.35点で最もサービス満足度が低いことが分かります(左側の1行目)。
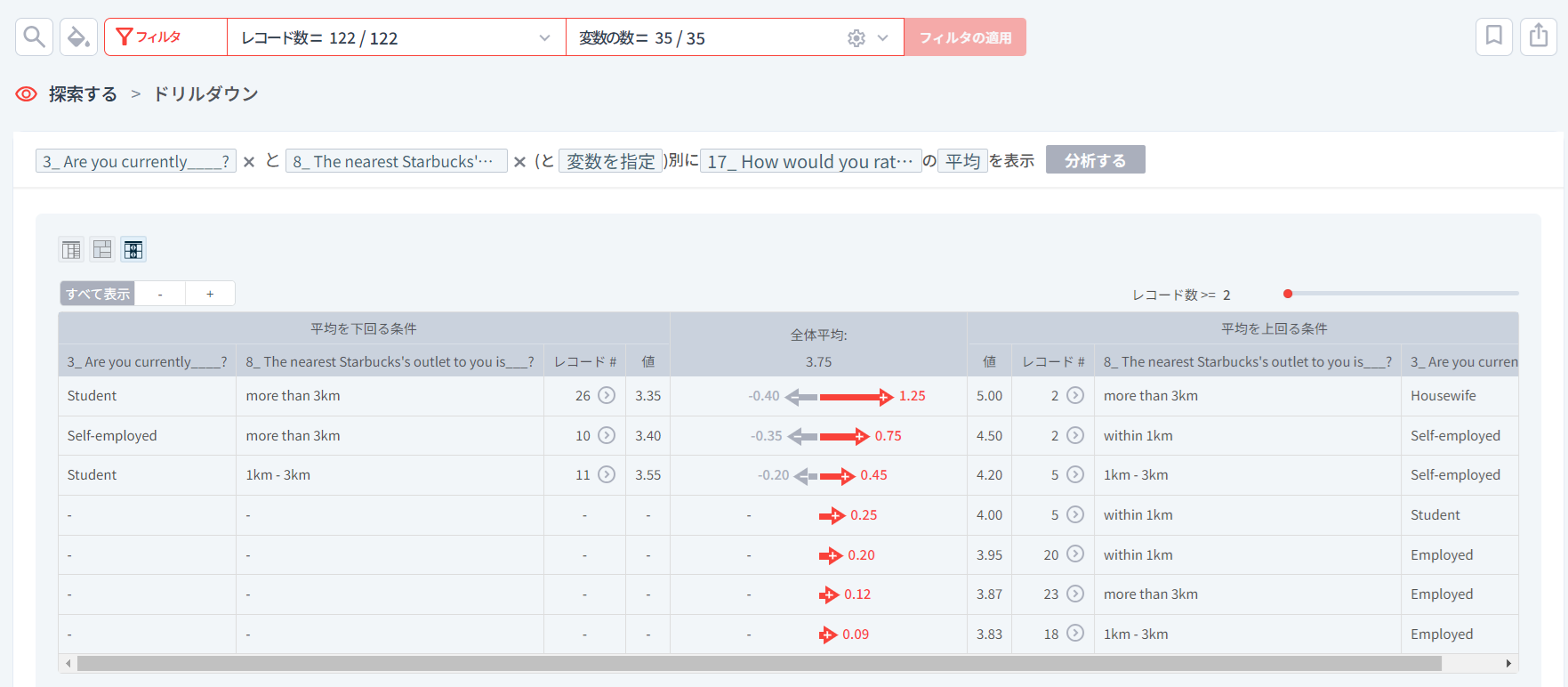
現在の状態とアクセシビリティそれぞれについて1つの観点(次元、変数)でサービススコア(満足度)の平均を比較した時と結果があまりにも異なることがわかりますよね?
納得がいかないので、性別(1. Your Gender)の変数を追加して、3つの観点の組み合わせで満足度スコアを分割(ドリルダウン)してみました。
- 現在の状態が「Housewife」、アクセシビリティが「more than 3km」である女性(Female)の場合、サービススコア(満足度)が5で非常に高い(右側の1行目)
- 現在の状態が「Employed」、アクセシビリティが「within 1km」である男性(Male)の場合、サービススコア(満足度)が3.54で平均を少し上回る(左側の最終行)
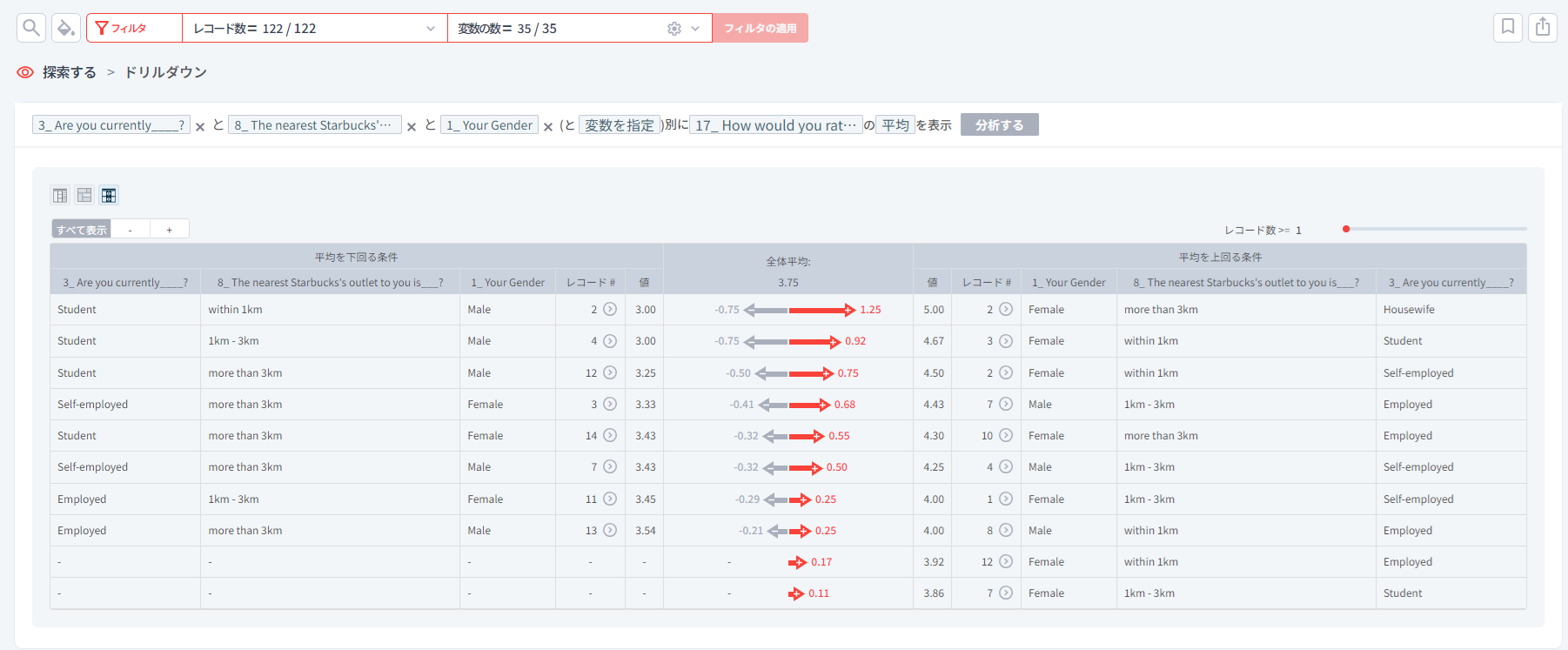
上の手順ので性別を区別せず、現在の状態とアクセシビリティの2つの観点の組み合わせのみで比較した場合、現在の状態が「Housewife」でアクセシビリティが「more than 3km」であるグループの満足度が最も高かったのは女性の影響が大きいことが分かりました。
3つの組み合わせで比較した場合、男性は
- 現在の状態が「Employed」で、アクセシビリティが「1km - 3km」の男性が最も満足度が高い。
- 次いで、現在の状態が「Self-Employed」で、アクセシビリティが「1km - 3km」の男性が満足している。
要因分析: ドライバー (統計的に有意な要因)
次に、要因分析メニューから「サービススコア」の質問項目と残りの19の質問項目との間で回帰分析を行ってみましょう。
<手順>
要因分析で、違いをもたらした要因を分析したい数値型のKPI(サービススコア)を選択して [分析する] ボタンをクリックします。
HEARTCOUNTが自動的に加工して追加した変数を除き、元のデータに含まれている変数のみを使用して回帰分析を行うには、画面上部のフィルタの「変数の数」メニューの歯車アイコンをクリックした後、「派生変数を含む」のチェックを外してください。
<分析結果の解釈>
個々の変数の重要度による回帰分析の結果のランキングを見ると、スマートマルチプルの画面で見た相関関係の大きさの順番と同じであることが確認できます。これは個々の独立変数と従属変数との間の関係を分析する単回帰分析の場合、回帰分析結果の重要度である決定係数(R²)が数学的には相関係数(r)を二乗した値であるためです。(* 雰囲気スコア(15. How would you rate the ambiance at Starbucks? (lighting, music, etc...)の相関係数である0.6を二乗すると0.36)
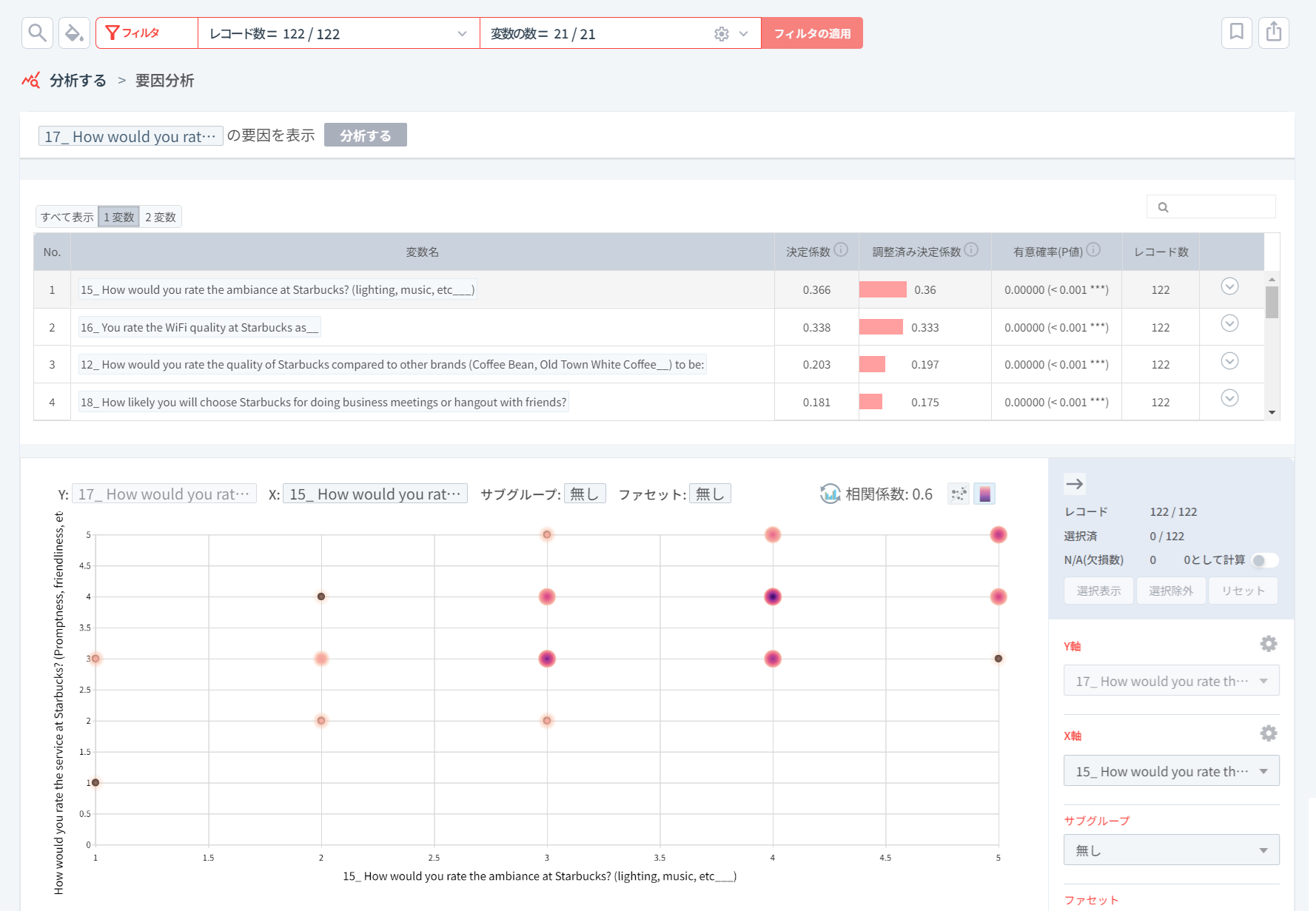
- しかし、現在の状態やアクセシビリティは要因分析の結果の表には出てきませんでした。現在の状態やアクセシビリティによる満足度のスコアの差が統計的に有意ではないためです。
統計的有意性について簡単に説明すると、グループ内(「Housewife」であり、アクセシビリティが「more 3km」のグループ)の満足度の差よりもグループ間の差が大きくなければ、統計的に有意な差が存在すると主張することができますが、下の図のように個々のグループごとに平均スコアは異なりますが、95%の信頼区間の平均スコアを比較すると信頼区間が互いに重なり合い、グループ間の差が統計的に有意ではないと判断されたためです。
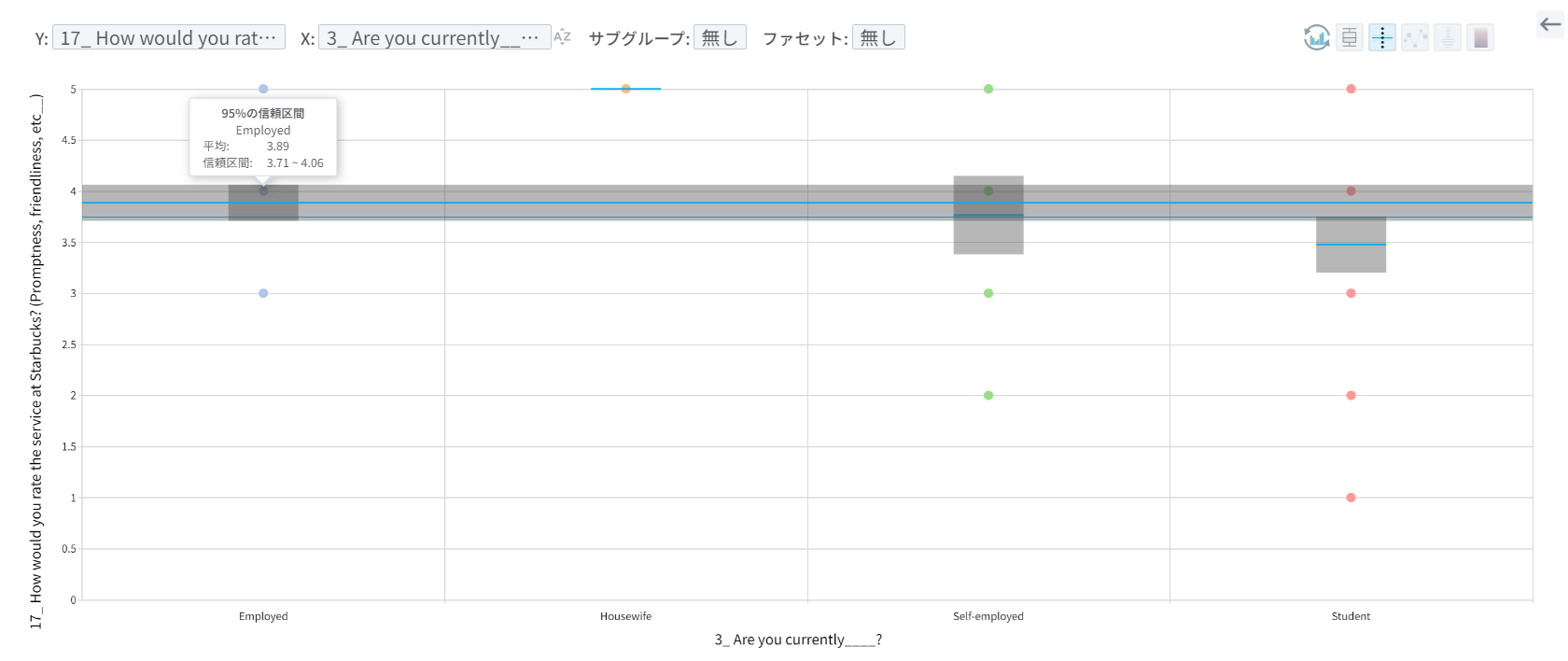
統計的に有意なもの(Statistical Significance)よりも、実務的な観点から有意なもの(Practical Significance)が会社に利益をもたらすという趣旨からデータを分析することが、現場の立場ではより重要です。
セグメンテーション: 両極端を比較する非常に良い習慣
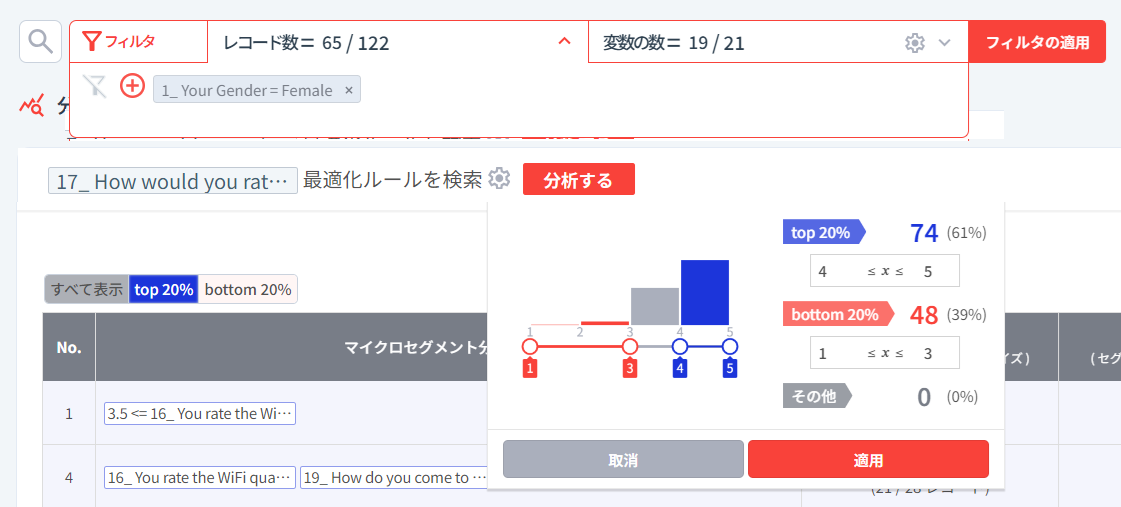
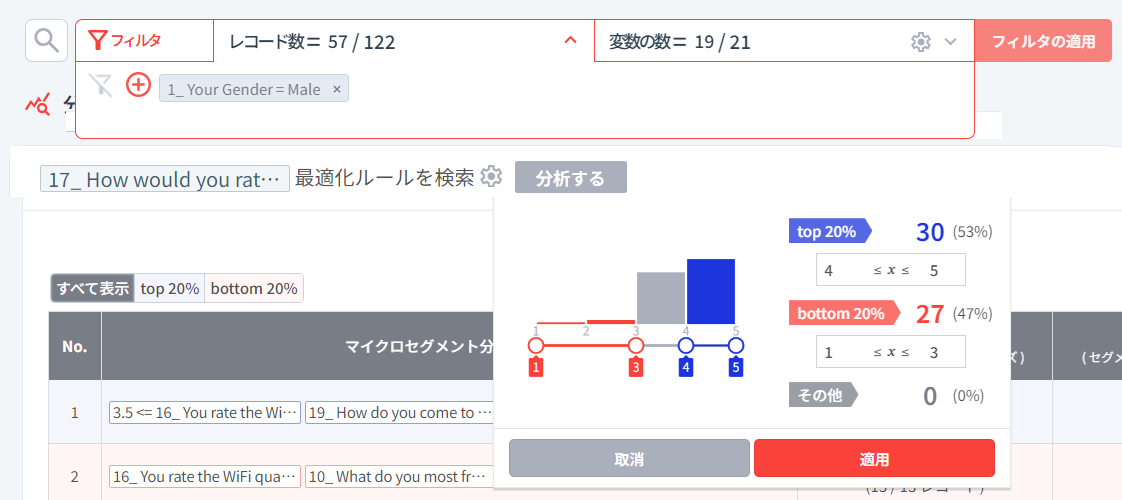
最後に、セグメンテーションを使って、男性と女性それぞれのサービススコア(満足度)を最大化できる条件を探してみましょう。
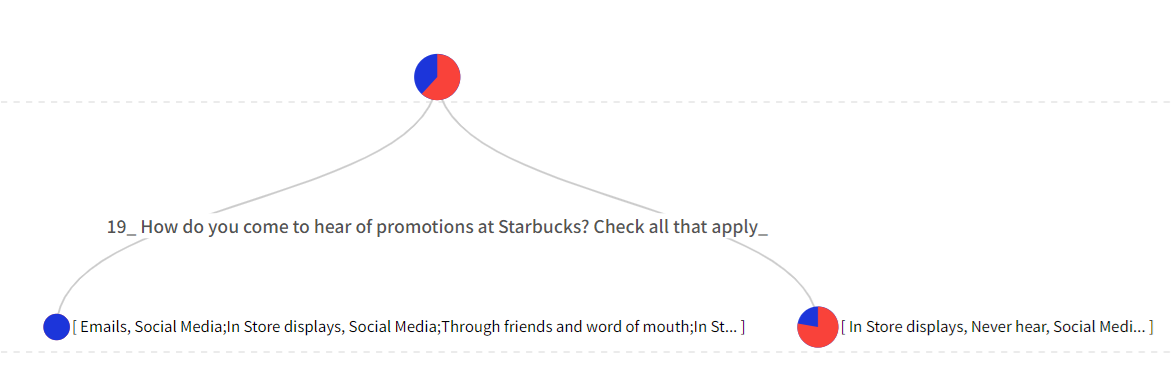
「サービススコア」に5点と回答した確かにサービスを満足したグループ(30人)と、1~2点と回答した確かに不満足なグループ(27人)をターゲットとし、2つのグループ(セグメント)を区分する論理的なルールを見つけようとします。
<手順>

- まず、HEARTCOUNTの共通機能であるフィルタリング機能を利用して、以下のように分析条件を設定しました。
- 性別については、男性のみ分析する
- 分析に使用する合計19個の変数のうち、サービススコア(満足度)の原因というよりは結果に近い、「ビジネス利用やプライベート利用の可能性スコア(18. How likely you will choose Starbucks for doing business meetings or hangout with friends?)」と「継続利用の有無(20. Will you continue buying at Starbucks?)」は除外する
- 最適化のルールを探す変数として「サービススコア(満足度)(17. How would you rate the service at Starbucks? (Promptness, friendliness, etc..))」を選択し、詳細設定で直接ターゲットをカスタマイズしました。
- デフォルト値: 数値型変数の場合、top 20% (上位20%)グループ vs bottom 20% (下位20%)グループの分類ルール分析
<分析結果の解釈>
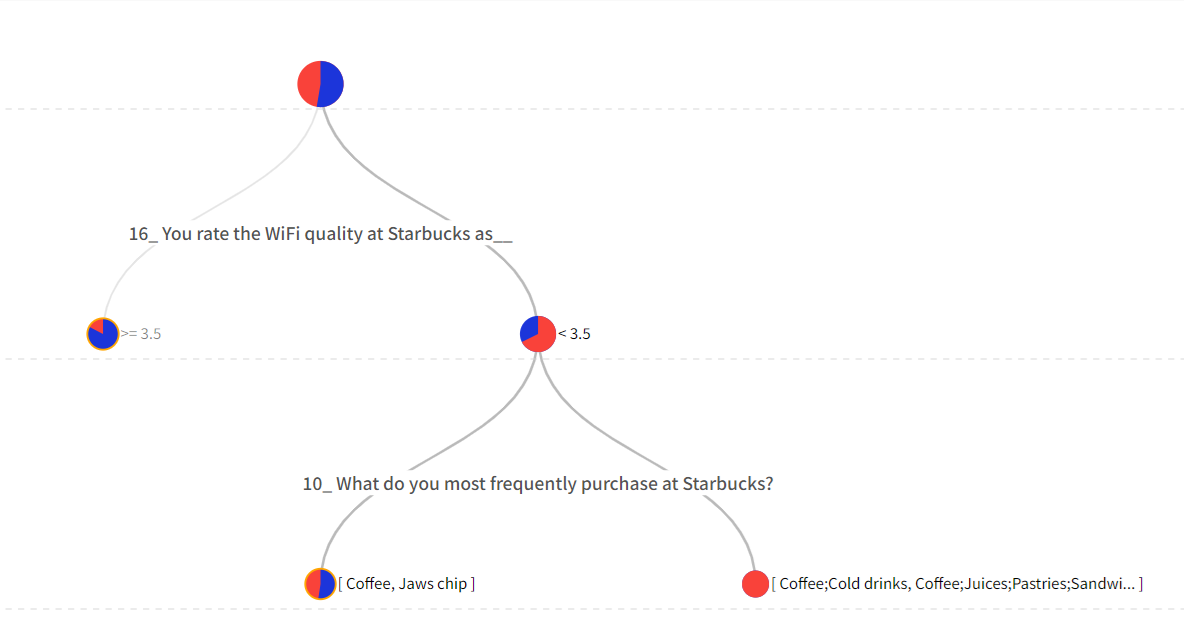
決定木の結果を見ると、男性の場合、
- WiFiスコアが高い場合(4点以上の回答)は無条件に高いサービススコア(満足度): 4.17
- WiFiスコアがあまり高くない(3点以下の回答)が、頻繁に購入する商品が「Coffee,Jaws chip」(2点以下)の場合はサービススコア(満足度): 3.52
- WiFiスコアがあまり高くない(3点以下の回答)が、頻繁に購入する商品が「Coffee;Cold drinks」(3点以上)の場合はサービススコア(満足度): 2.85

同様に女性についても、サービススコア(満足度)の高いグループとサービススコア(満足度)の低いグループが高い純度で密集しているセグメントの条件を探しました。
女性の場合、
- プロモーション経路が「Emails, Never her, Social Media」の場合、無条件に高いサービススコア(満足度): 5.0
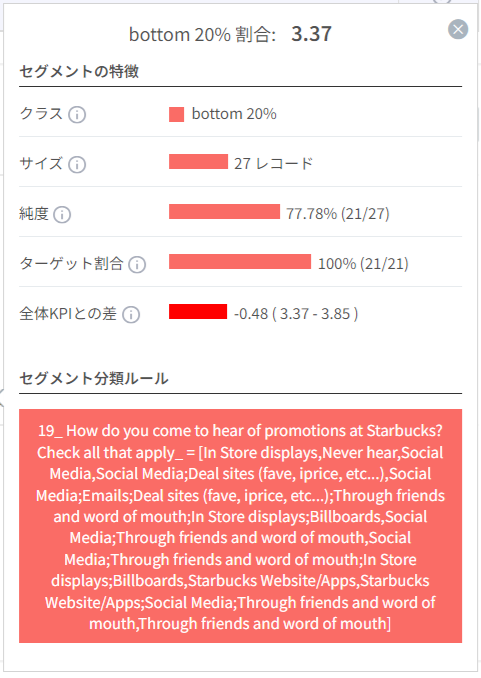
- プロモーション経路が「In Store displays, Social Media, Emails, Deal sites」(2点以下の回答)であれば、サービスについては不満足のサービススコア(満足度): 3.37点。