Tidy Datasetとは?
Tidy dataset(日本:整然データ (せいぜんデータ))とは、分析が行いやすい形に整理されたデータセットのことです。この概念は、データサイエンティストのHadley Wickham氏によって提唱されました。これは、データを加工、集計、視覚化、モデル化する際に便利な形で整えられたデータセットを作成するフレームワークです。Tidy datasetの構造は、特定の形とルールに従っています。そのため、分析に適したデータセットはすべて同じ構造を有しています。Tidy datasetは、多くのデータ可視化・分析ツールや言語と互換性があります。このようなデータセットは、データの可読性と活用性を向上させるメリットがあります。
なぜTidy Datasetが重要なのか?
- 可視化とEDA(探索的データ分析)を容易に: Tidy Datasetは、可視化や探索的データ分析に適した形式です。 グラフを描いたり、パターンを見つけたり、データを探索するプロセスがより簡単になります。
- データ分析の一般的な標準: Tidy Datasetはデータ分析ツールやパッケージで主に使用される標準です。R、Pythonなど様々なツールでこの構造をベースにした機能が提供されています。
- データ統合の容易さ:様々なデータソースからデータを統合する必要がある場合、Tidy Datasetに変換すると、データ統合作業がはるかに容易になります。
Tidy Datasetの設定方法
Tidy datasetを作るためには次のようなルールに従う必要があります。
1.データセットの行と列の構成
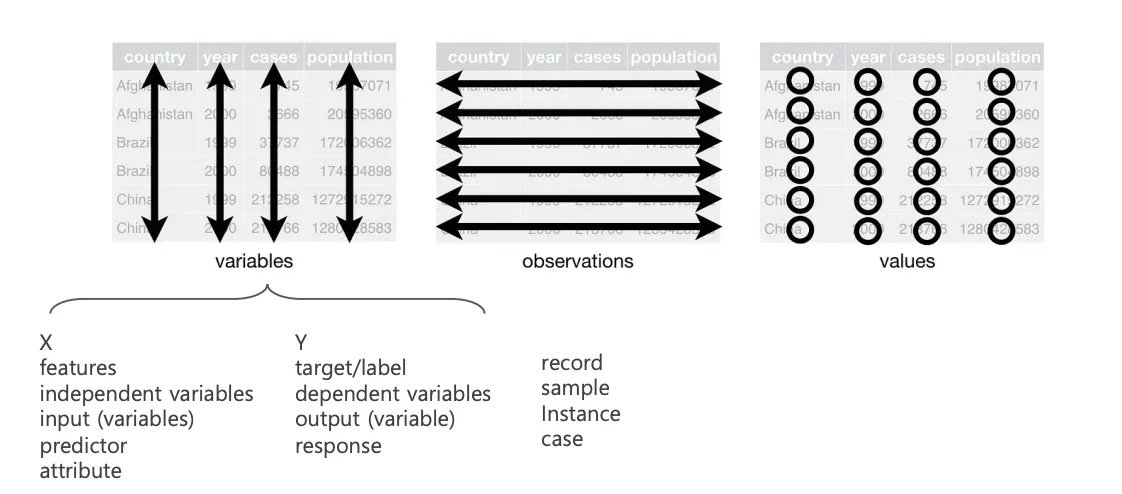
データセットを分析する前に、それぞれの変数が列(column)で構成されなければなりません。 独立した変数はそれぞれ一つの列で存在しなければならず、同じ分析対象に対する観測値は行(row)で構成されなければなりません。
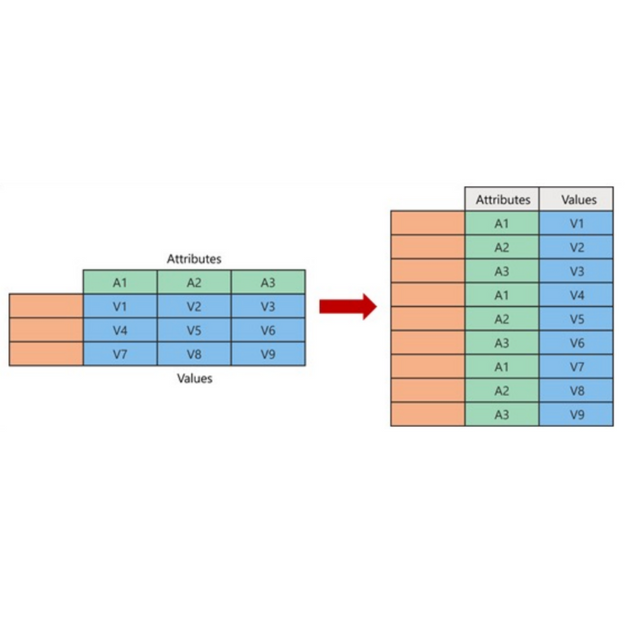
2. 独立した変数の区分
データセットで各変数は独立した意味を持つ必要があります。 例えば、国別に結核で死亡した患者数とその国の全体人口を比較する場合、「国」変数と「結核で死亡した患者数」変数、「全体人口」変数はそれぞれ独立して構成する必要があります。下の図では、「4」番目の表がTidy datasetの文法をよく守っています。
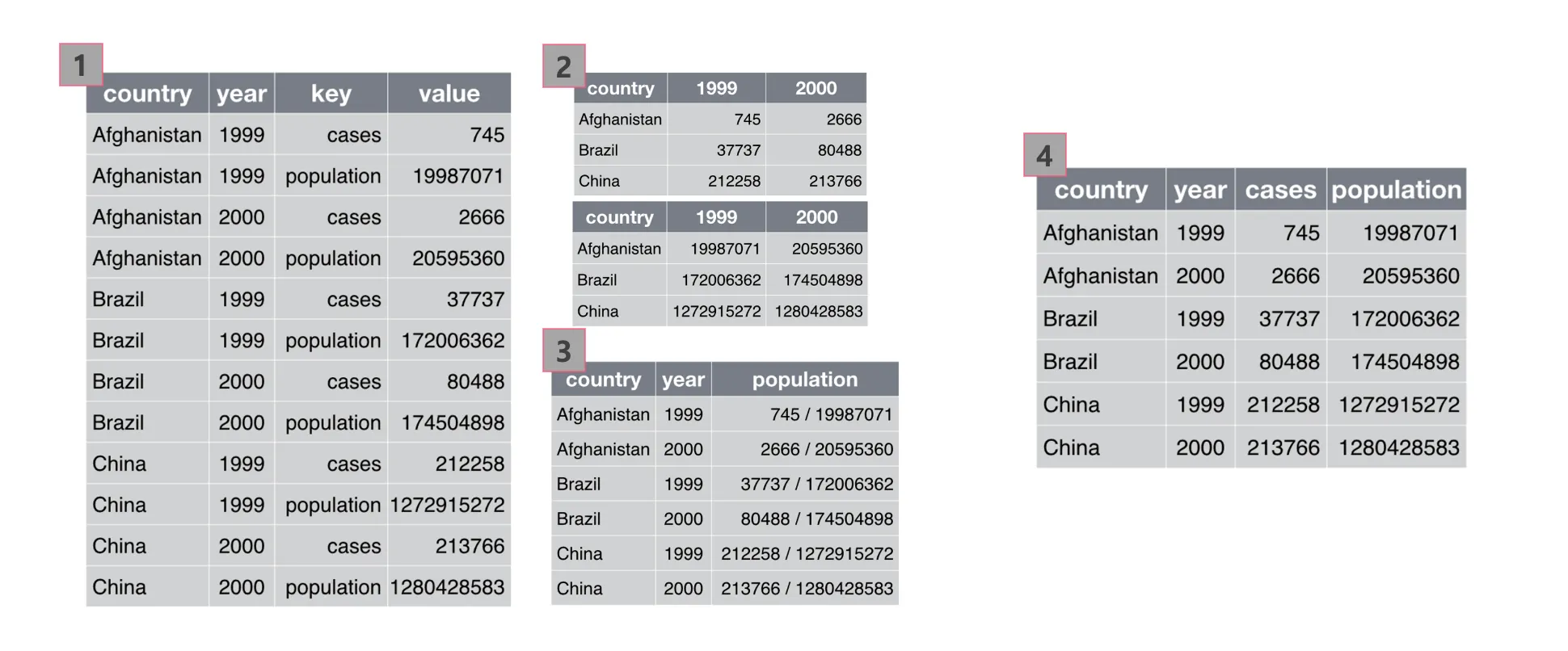
Wide形式のデータセットをLong形式に変える(melting)
下図の左側のようなワイドデータセット(変数値が個別カラムで広く構成されたデータセット)をTidy Dataset形式に従うロングデータセットに変える必要がある場合がよくあります。ロング形式のデータセットは、個々の変数を別の列で構成されるため、データ構造が単純化され、視覚化や分析に容易な形になります。
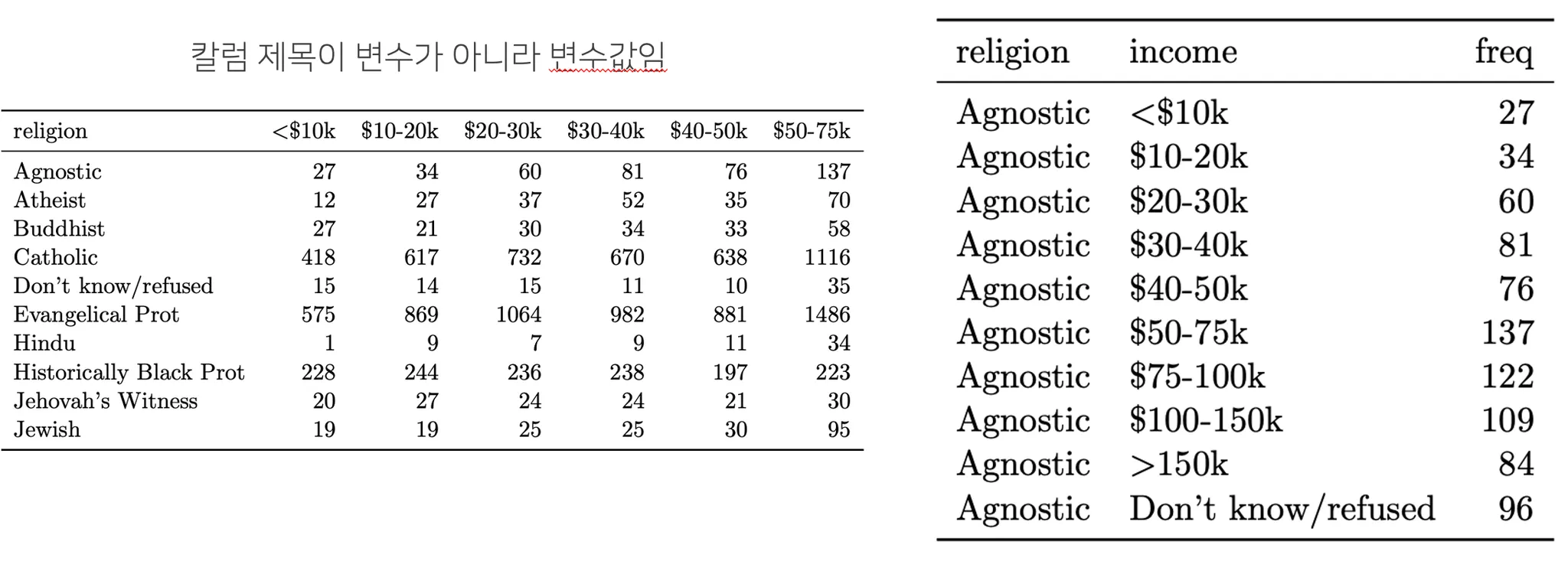
ロング形式に変換する方法
ワイドデータセットをロングデータセットに変換する過程を「メルト(Melting)」といいます。 Pandas(Pandas)ライブラリではmelt()関数を使ってデータフレームをメルトすることができます。この関数を使うと指定した変数を識別子変数(identifier variable)として維持して、残りの変数を値変数(value variable)に変換します。
例えば、次のようなワイドデータセットがあるとします。
| 国 | 1999年の患者数 | 1999年の人口 | 2000年の患者数 | 2000年の人口 |
|---|---|---|---|---|
| 韓国 | 100 | 50000000 | 120 | 51000000 |
| 米国 | 200 | 300000000 | 230 | 310000000 |
| 日本 | 80 | 127000000 | 85 | 128000000 |
上記のようなデータをロング形式に変換すると次のようになります。

| 国 | 年度 | 患者数 | 人口 |
|---|---|---|---|
| 韓国 | 1999 | 100 | 50,000,000 |
| 韓国 | 2000 | 120 | 51,000,000 |
| 米国 | 1999 | 200 | 300,000,000 |
| 米国 | 2000 | 230 | 310,000,000 |
| 日本 | 1999 | 80 | 127,000,000 |
| 日本 | 2000 | 90 | 128,000,000 |
"わかること"、"わからないこと"の把握の大事さ
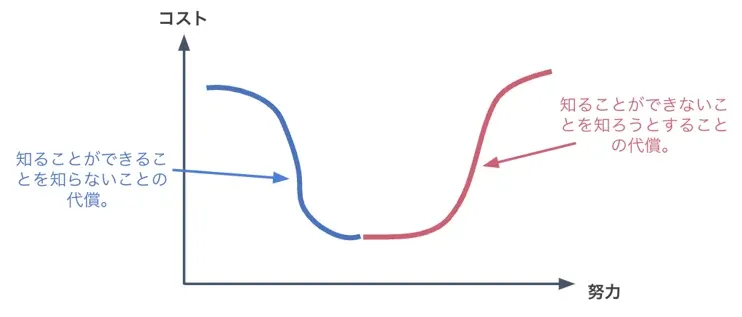
- Tidy datasetが用意されたとしても、すべての問題を解決できるわけではないことを知っておく必要があります。私たちがそのデータセットで言えることは、変数名で構成できる最善の文章を超えることはできません。
- 例えば、「購入時間」と「商品名」、「年齢層」、「キャンセル率」という変数で構成された通販売上データセットであれば、「特定の商品は、特定の時間帯、特定の年齢層のキャンセル率が最も高かった」という文章ができます。データセットに含まれる変数が多いほど、特定の「OOO」のような条件が多くなり、答えられる質問も多くなります。
- データセットに含まれていない現象の原因は、追加の推論、解釈、またはデータ収集が必要な場合があります。この部分は、ドメイン専門家の判断の領域です。
- そのため、データ分析を行う際には、データセットからわかることとわからないこと(限界)をまず認識することが重要です。このように、どのような質問に答えられるかを把握し、それに合った適切な分析方法と視覚化技法を選択します。これにより、データ分析や報告の過程で労力を最小限に抑えるポイントを見つけることができます。