1. 分析に適したデータセットの条件に関心のある方。
2. データはあるが、フォーマットの問題で分析がうまくできていない方。
3. Excelを活用したデータ前処理に関心のある方。
分析に適していないデータセット
実務でデータ作業をしていると、分析ができない状況に遭遇することがあります。このような状況は様々なタイプと原因が考えられます。私たちは、データが空であったり、異常値を示すなど、データにエラーが含まれている状況に対してはある程度慣れており、それなりの対処ができます。しかし、「分析に適さないデータセットの構造」が原因である場合は、状況把握や原因、解決方法さえ推測できないことが多いです。
データセットとデータセットの構成要素
データセットはデータが集まってできた集合で、通常「テーブル」とも呼ばれます。
Excelではセル(cell)が集まって作られた範囲(range)をデータセットとみなすことができます。
データセットは数字や文字で構成された値(values)の集合であり、全ての値は変数(variable)と観測値(observation)のいずれかに該当します。
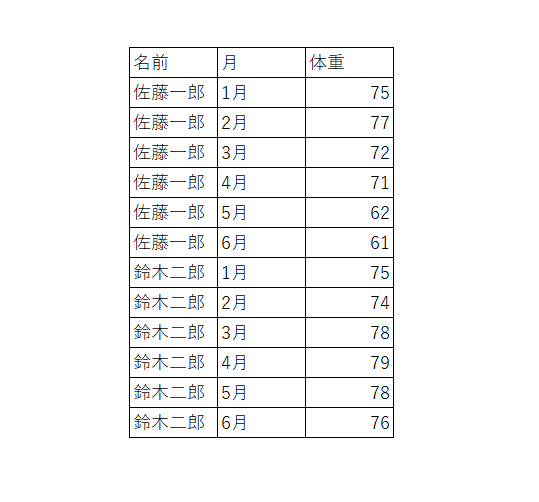
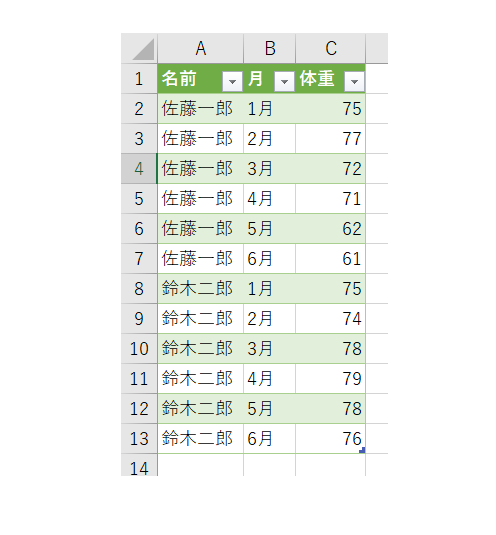
以下のデータセットは6つの値で構成されていますが、「名前」と「体重」は変数で、残りの「佐藤一郎」「70」「鈴木二郎」「65」は観測値に該当するので、このデータセットは合計6つの値を持っていますが、その値は2つの変数、4つの観測値から構成されているとみなすことができます。
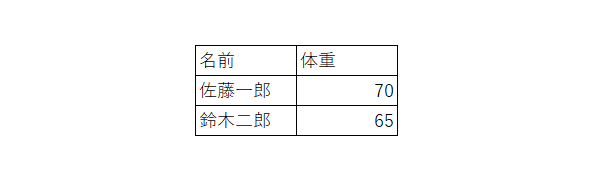
変数: すべての個体(entity)を測定して説明する同じ基本属性(体重など)を意味します。
観測値: すべての個体に対して同じ単位(kg、円、個...)を持つ測定(観察、収集)された値を意味します。
分析に適した標準データセット: Tidy Data (整然データ)
分析に適したデータセットの要件は以下の通りです。
そして、これらの要件に全て合致する分析に適したデータセットをTidy Dataといいます。
- 個々の変数は列を形成します。
- 個々の観測値は行を形成します。
- 個々の観測の構成単位はテーブルを構成します。
列見出しが変数ではなく値であるデータセット
分析に適していないデータセットの構造はいくつかありますが、最も代表的な構造は「列見出しが変数ではない値である場合(Column headers are values, not variable names)」です。これをワイドフォーマット(Wide Format)とも言います(用語は若干異なる場合があります)。
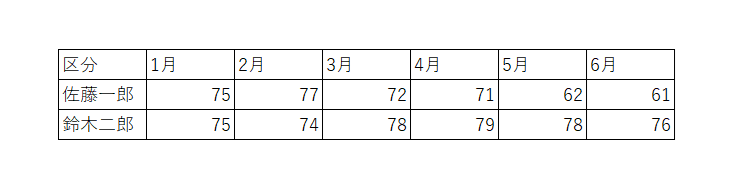
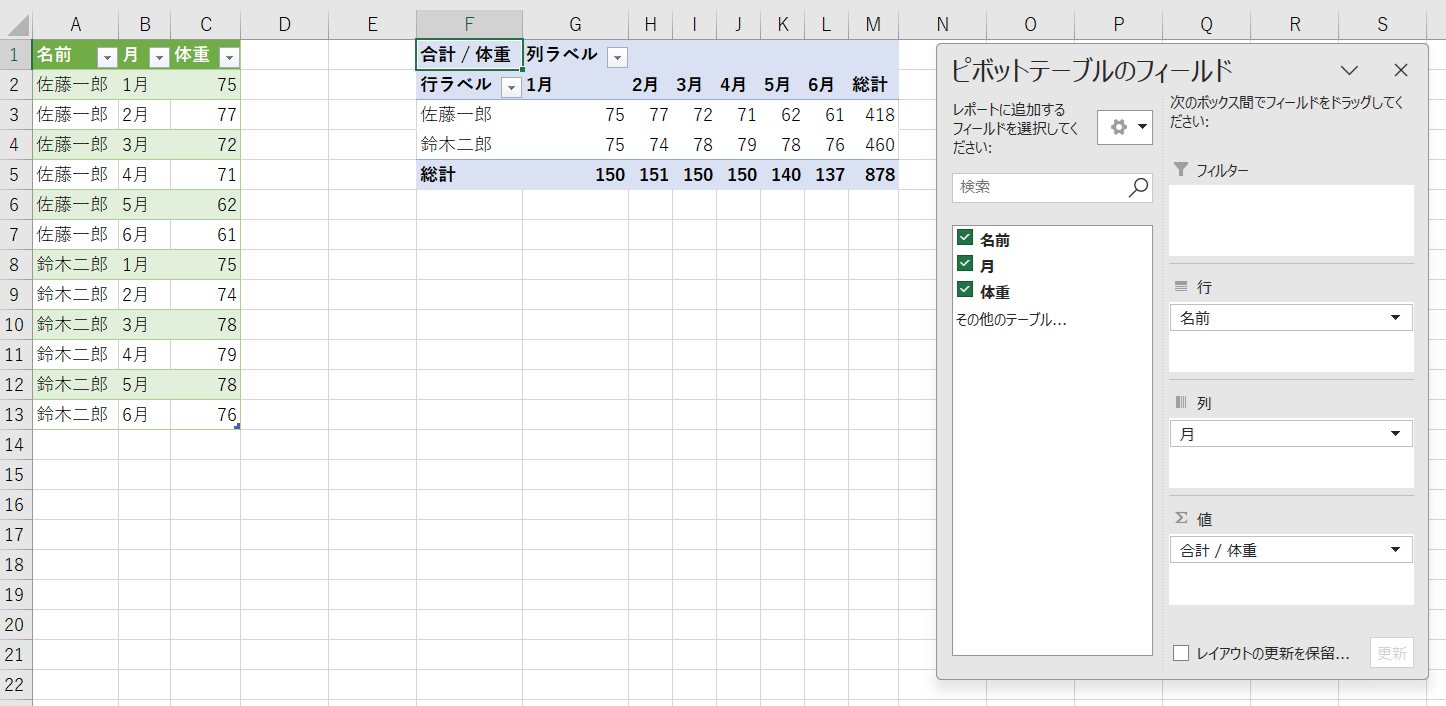
表2のデータセットは私たちに馴染みのある構造です。しかし、このデータセットでピボットテーブルを利用して分析をしようとした瞬間、以下のような画面に直面して戸惑うことになります。月別の体重の変化を分析しようとすると、1月から6月までの6つのフィールドを追加する必要があります。
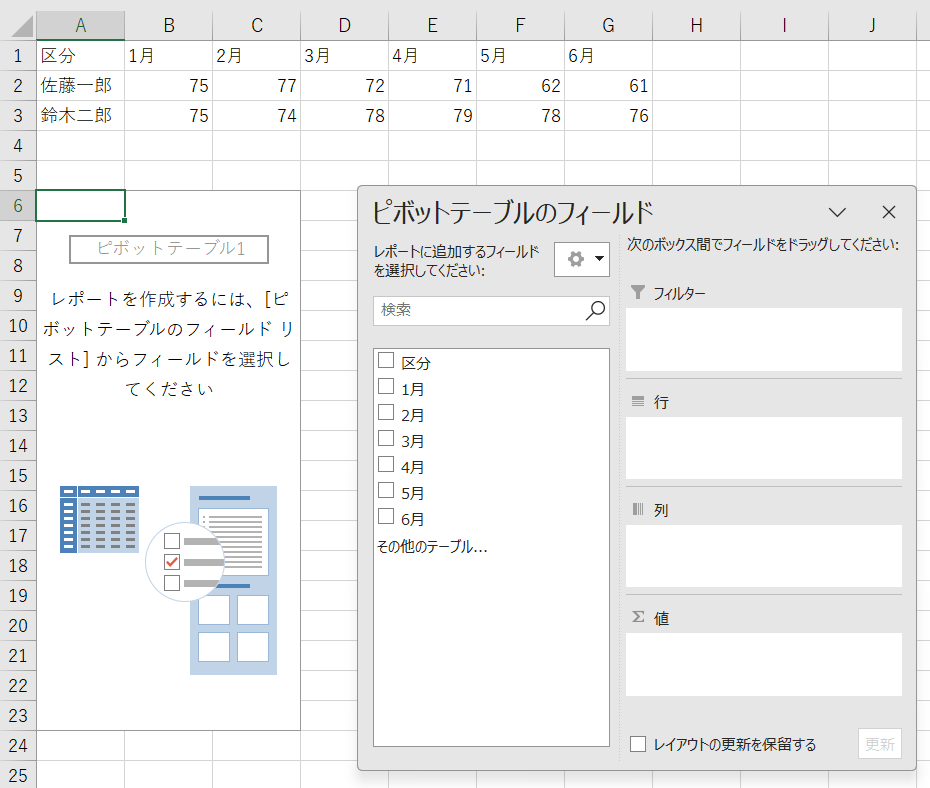
たかが6ヶ月分のデータですが、36ヶ月分のデータならなおのこと、もっと困った状況です。たとえ「私のマウスコントロールは、昔はプロゲーマとしてー級だった!」と言いながら、6回ドラッグ&ドロップしてピボットテーブルを作ったとしても、その結果はちょっとおかしいです。
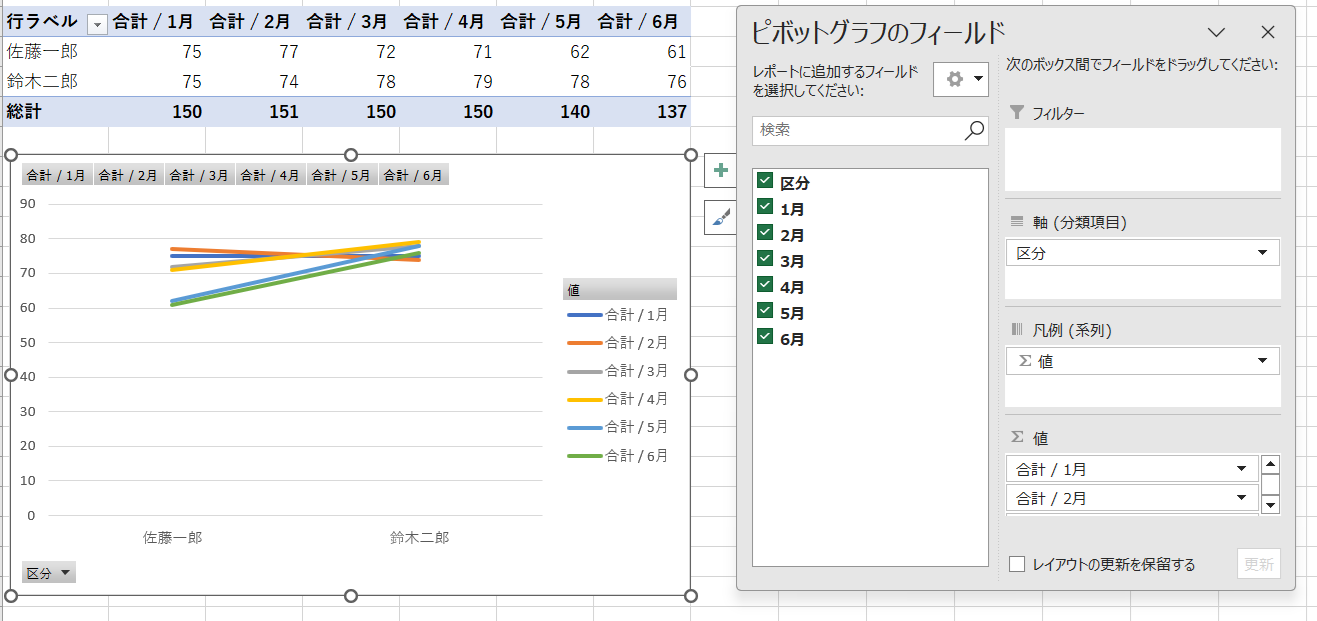
何か変な気がして行/列の切り替えを試してみましたが、結果が合うような気がするし、合わないような気がするし、怪しいです。
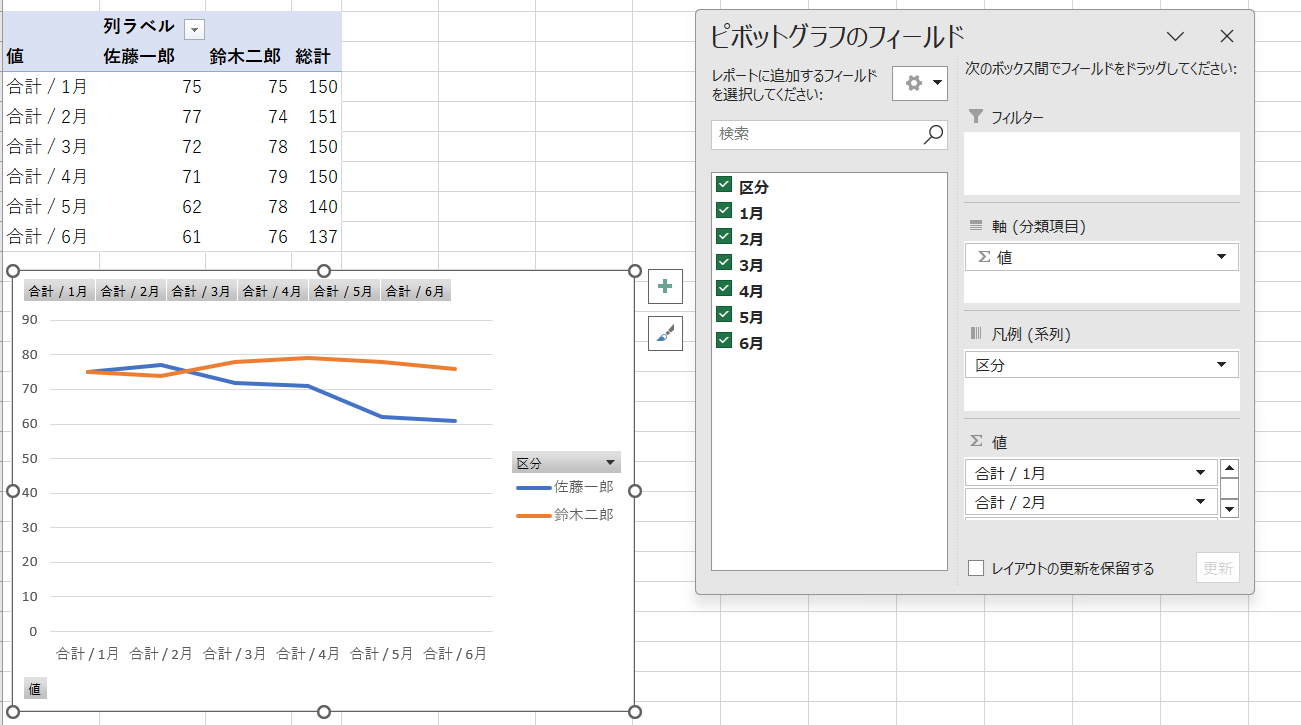
この構造は、前述の分析に適した標準データセットの要件のうち「個々の変数は列を形成する」という最初の要件に反して、変数ではなく値が列を形成したケースです。つまり、元のデータの列見出しである「1月、2月 ... 5月、6月」は、ある変数の測定値(observation)であって、変数そのものを表す値(variable)ではなく、1つの変数で構成されるべきデータセットがまるで6つの変数で観測されたかのように広く(wide)作られた構造です。
このデータセットはレポートや発表の目的で使われるデータセットです。つまり、それ自体が間違っていたり、エラーというよりは分析に適していないデータセットであり、このデータセットで分析作業をするためには構造の変換が必要です。
Unpivot, Melting (ピボット解除、縦変換)
「列見出しが変数ではなく値であるデータセット」を tidy dataに変換する作業を Unpivot もしくは Melting (ピボット解除、縦変換)といいます。<表2> で列ヘッダーである「1月、2月 ... 5月、6月」は「月」という変数の値として1つの列で設定する必要があるため、現在のように月ごとに6つの列ではなく1つの列に値として構成しなければなりません。
これはまるで現在の列見出しが時計回りに90度回転して行が列に切り替わるように見えます。ただし、単純な行/列の切り替え(Transpose)ではなく、「A」の行も1月から6月、「B」の行も1月から6月までの値をそれぞれ持つ必要があるため、全体の行数は現在の行数(2)に縦変換の対象列の数(6)を乗じた値(12)に増加することになります。
Excelの列のピボット解除(Power Query)
Excelで列のピボット解除(Unpivot)をする方法を説明します。
Excelのピボット解除の操作は、Excelの Power Queryエディターで簡単かつ迅速に実行することができます。
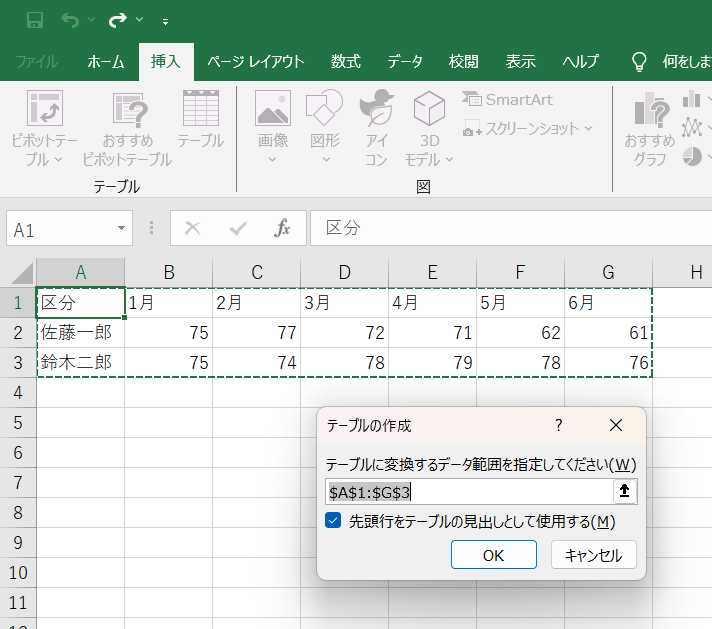
① テーブルの変換
ピボット解除したい範囲をテーブルに変換します。ショートカットキー [Ctrl + T] を使用するか、[挿入] タブ > [テーブル] グループ > [テーブル] を選択します。範囲が正しく選択され、先頭行を含めることがチェックされていることを確認し、[OK] ボタンを押します。
② データのインポート
変換されたテーブルを Power Queryエディターにインポートします。変換されたテーブルを選択し、[データ] タブ > [データの取得と変換] グループ > [テーブルまたは範囲から] ボタンを選択します。
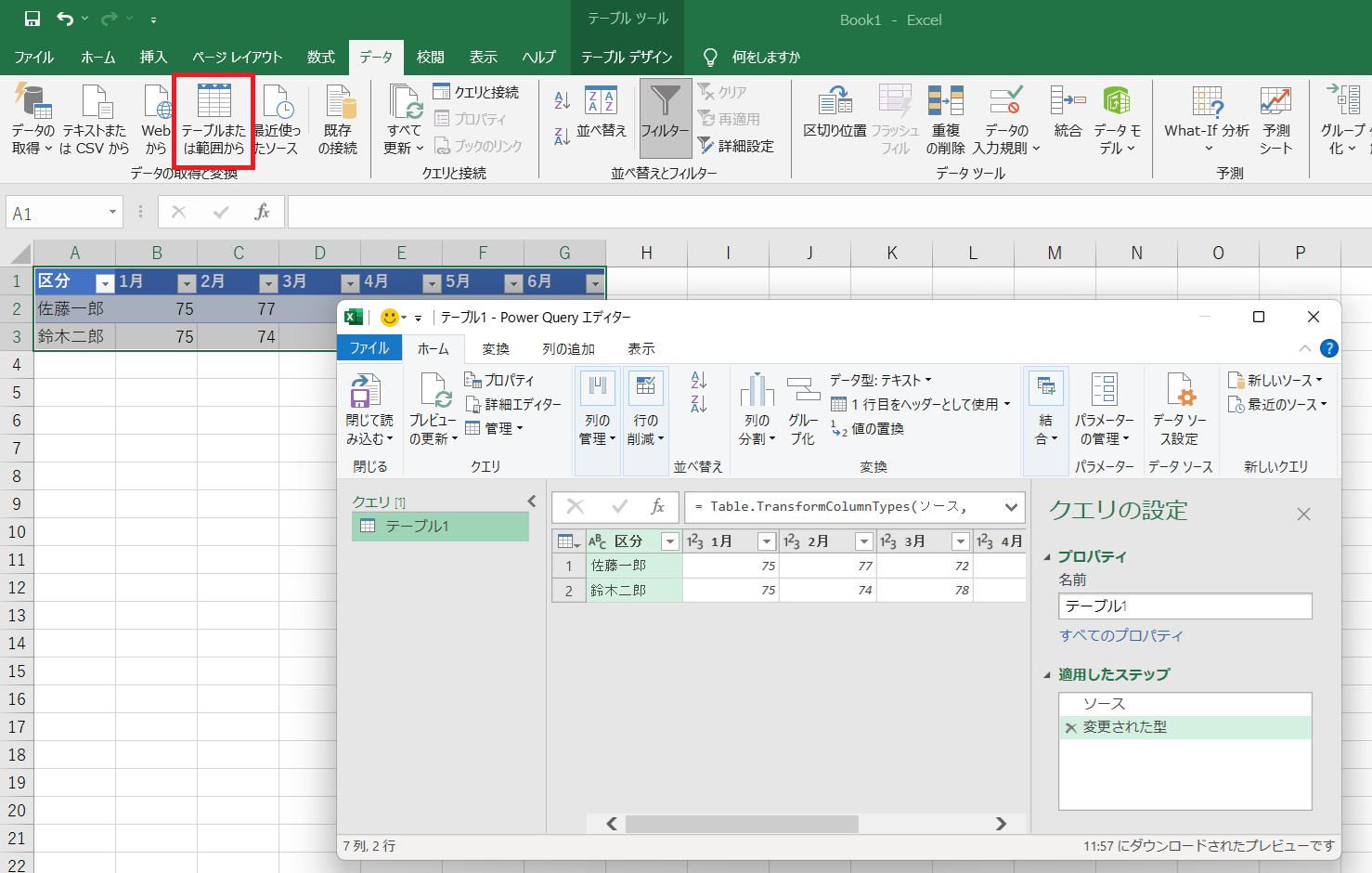
③ 列のピボット解除
[区分] 列の列を選択(列見出しの「区分」をクリック)し、[変換] タブ > [任意の列] グループ > [列のピボット解除] ボタンの右側にある三角形のメニューボタンをクリックして、[その他の列のピボット解除] を選択します。現在選択している [区分] 列を除き、残りの列(1月から6月まで)をピボット解除、つまり、列を行に変換する必要があるためです。
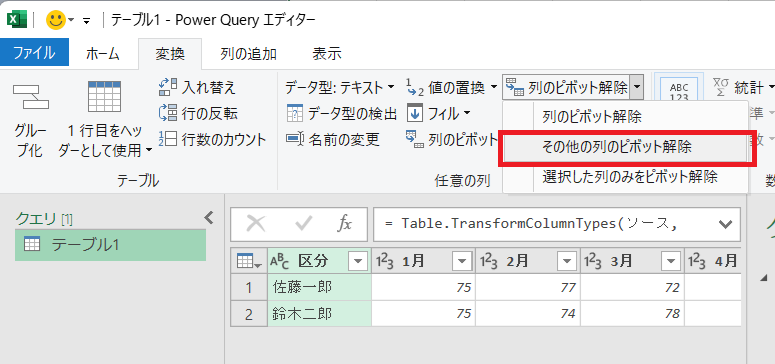
④ 列ヘッダーを変更する
列のピボット解除が実行された結果が確認することができます。新しく作成された列見出しは [区分] [値] [属性] という値で設定されています。列見出しを変更します。現在の列見出しをダブルクリックすると、列見出しを変更することができます。左から順に名前、月、体重に変更します。この段階で必要に応じてデータ型も変更しますが、今回はデータ型について変更する型はありません。
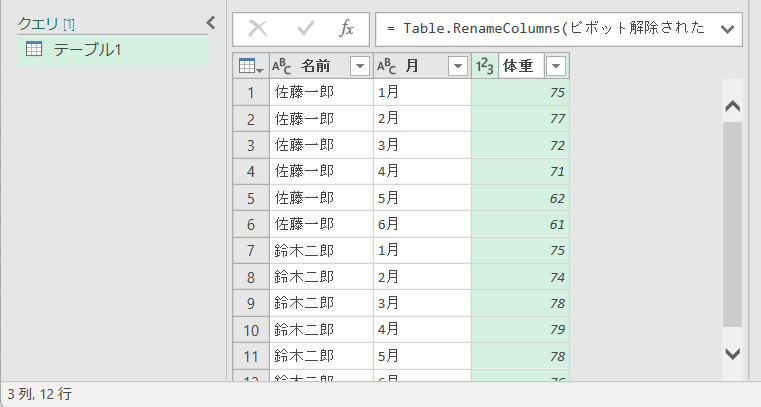
⑤ 閉じて読み込む
Power Queryエディターは Excelの背後で実行され、実行中は Excelシートを選択したり、操作することはできません。Power Queryエディターでの作業の完了後、エディターを閉じて、クエリ結果を Excelに読み込む必要があります。[ホーム] タブ > [閉じる] グループ > [閉じて読み込む] ボタンを押してロードを行います。
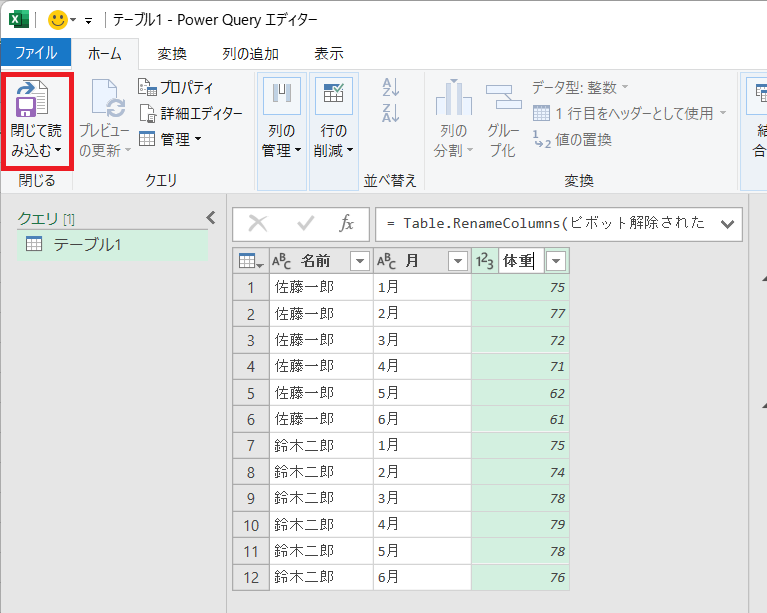
以下のように新しいシートに列がピボット解除されたデータセットがテーブルの形式で読み込まれたことを確認することができます。
ロングフォーマット(Long Format)の効用
列のピボット解除されて作られたデータセットはロングフォーマット(Long Format)です。このデータセットでピボットテーブルを作成すると、先ほどのワイドフォーマット(Wide Format)で1月から6月までの6つのフィールドが「月」という1つのフィールドに統合されたことが分かります。そして、行エリアに [名前]、列エリアに [月]、値エリアに [体重] フィールドをそれぞれ追加すると、列のピボット解除前のワイドフォーマットと同じ形を作成することができます。
ワイドフォーマットはロングフォーマットのデータセットをピボットで作成することができる構造で、ワイドフォーマットのデータセットは列のピボット解除を実行して再びロングフォーマットに戻ることができる関係であることが分かります。
ワイドフォーマットが間違っているとか、間違ったデータセットであるという意味ではありません。ワイドフォーマットは人が認識しやすいので、レポートや発表に適しています。また、手書きや入力で観測値を記録する必要がある状況にも適しています。
ロングフォーマットのデータセットは、Tidy Data (整然データ)の要件に合致する構造であり、データベースの基本形式で、Excelに限らず、ほぼすべての分析ツールでデータ分析を実行するのに適しています。今回の例は6ヶ月のデータでしたが、もし36ヶ月のデータであった場合、既存のワイドフォーマットのデータセットでは、年単位、四半期単位の分析は困難です。したがって、与えられたデータがTidy Dataであるかどうかを認識するために不可欠であり、重要な要素は「列見出しが変数ではない値であるか」を判断することです。