はじめに
こんにちは、HEARTCOUNTチームのSamです。HEARTCOUNT ABIのText to SQL(NL2SQL: Natural Language to SQL)は、SQLに関する専門知識がなくても、自然言語を使ってデータを簡単に照会できる機能です。以前の投稿でも触れたように、この機能はビジネスユーザーとデータベースの間にある障壁を取り除き、より効率的なデータ活用を可能にします。
 sidney yang
sidney yang
しかし、Text to SQL機能が成功裏に動作するためには、単に自然言語をSQLクエリに変換するだけでは不十分です。LLM(大規模言語モデル)は優れた言語処理能力を基に自然言語を理解しSQLを生成することができますが、データベース構造やビジネス文脈に関する深い理解には依然として限界があります。
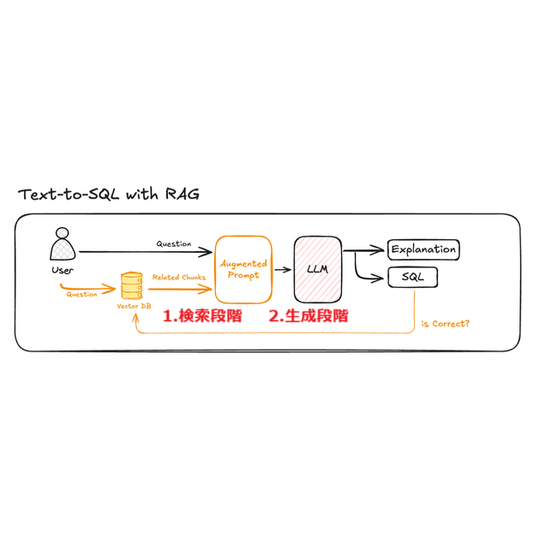
このような限界を克服するためには、メタデータを通じてデータの意味や関係を明確に伝えることが重要です。HEARTCOUNT ABIはText to SQLの性能を最大化するためにRAG(Retrieval-Augmented Generation)技術を導入しました。RAGはLLMとデータベースの間で中間的な役割を果たし、ベクターデータベース(Vector DB)を通じて関連データを効率的に検索し、LLMに提供します。
したがって、ベクターデータベースに保存される情報の質と構造が非常に重要です。RAGの性能は、質問に関連するデータ(メタデータ)をどれだけ適切に保存し、検索できるかにかかっているからです。
今回の投稿では、メタデータの重要性と、HEARTCOUNT ABIのText to SQL 2.0でメタデータをどのように保存し、活用するかについて焦点を当てて解説します。
Text to SQLにおけるメタデータの重要性
HEARTCOUNT ABIのText to SQL機能が正確に動作するためには、RAG(Retrieval-Augmented Generation)が重要な役割を果たします。RAGの核心は「質問に関連するデータをどれだけ適切に見つけ出せるか」です。ユーザーが自然言語で質問を入力すると、ベクターデータベース(Vector DB)から類似したデータを検索し、それをLLMに提供するプロセスを経るからです。
この時、「何を探すべきか」、つまりデータの構造と文脈に関する情報がメタデータとして適切に定義されている必要があります。テーブルの構造、カラムの意味、データ間の関係、計算式といった情報がLLMに提供されることで、質問の意図をより正確に理解し、適切なSQLクエリを生成できるようになります。
メタデータが重要な理由
メタデータは単にテーブルやカラムの名前を提供するだけでなく、データベース構造とビジネス文脈を結びつける重要な架け橋の役割を果たします。これは、LLMがデータの意味を理解し、適切なSQLクエリを生成する上で大きく貢献します。
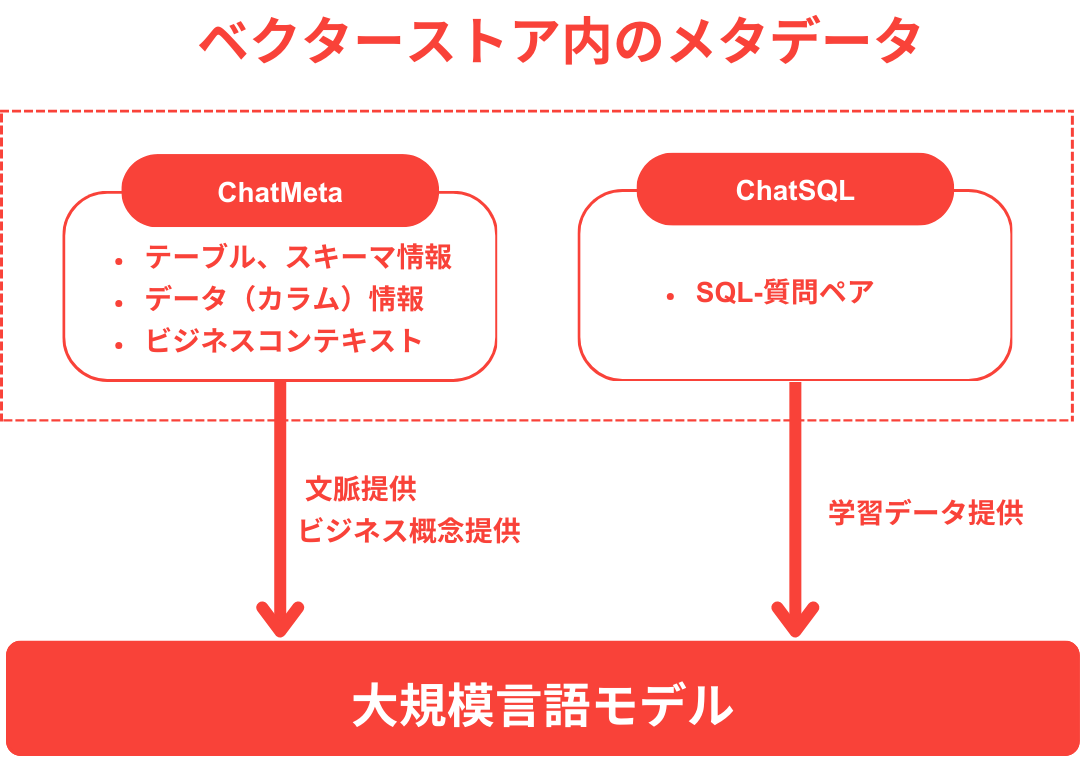
メタデータの役割を次の3つに分けて見ていきます:
1. 文脈の提供(DBスキーマコンテキスト)
メタデータはセマンティックレイヤーの一部として、テーブル、列、指標間の関係と意味を明確に定義します。
これにより、自然言語による質問がデータベース内の適切なテーブルやカラムにマッピングされるよう支援し、結合関係を含む複雑なデータベースクエリを正確に生成することが可能になります。
例:
- 「注文を最も多くした顧客は誰ですか?」という質問が入った場合、次のようなメタデータを参照します。
- 関連テーブル1:
orders- カラム:
customer_id,amount
- カラム:
- 関連テーブル2:
customers- カラム:
id,name
- カラム:
- 結合キー:
orders.customer_id = customers.id
このように、文脈を提供することで、質問の意図とデータの関連性を把握し、LLMがより正確に動作できるようになります。
2. 一貫したビジネス用語の生成(Business Terminology)
KPI、計算式、ビジネス用語などは、メタデータを通じて一貫して定義されます。
これにより、ビジネスユーザーとシステム間のデータ解釈の違いを減らし、信頼性を確保することができます。
例:
「前四半期の純売上はどのくらいですか?」という質問が入った場合、以下のようなメタデータを参照します:
- 関連テーブル:
sales - カラムの定義:
rev: 総売上,discount: 割引金額,returns: 返品金額 - メトリクス計算式: 純売上 = 総売上 - 割引金額 - 返品金額 or 売上 - 割引 - 返品
rev = revenueのように、メタデータは標準化されていないカラム名やビジネス略語を明確にマッピングします。さらに、LLMはメタデータを通じてカラム名とビジネス文脈を正確に理解し、適切なSQLを生成します。
3. 学習データの提供(Few-Shot Learning)
メタデータの拡張された形としてSQLと質問のペアを保存することで、LLMの学習における重要なデータセットとして活用することができます。
RAGベースのシステムでは、SQLと質問のペアをベクトル化して類似度を計算し、適切な例をLLMに提供します。
例:
・質問: 「先月の新規登録顧客数は?」
・SQL: SELECT COUNT(*) FROM customers WHERE signup_date >= '2025-01-01'
このようなSQLと質問のペアを保存することで、モデルは過去の使用例を学習し、より正確で一貫性のある結果を提供できるようになります。
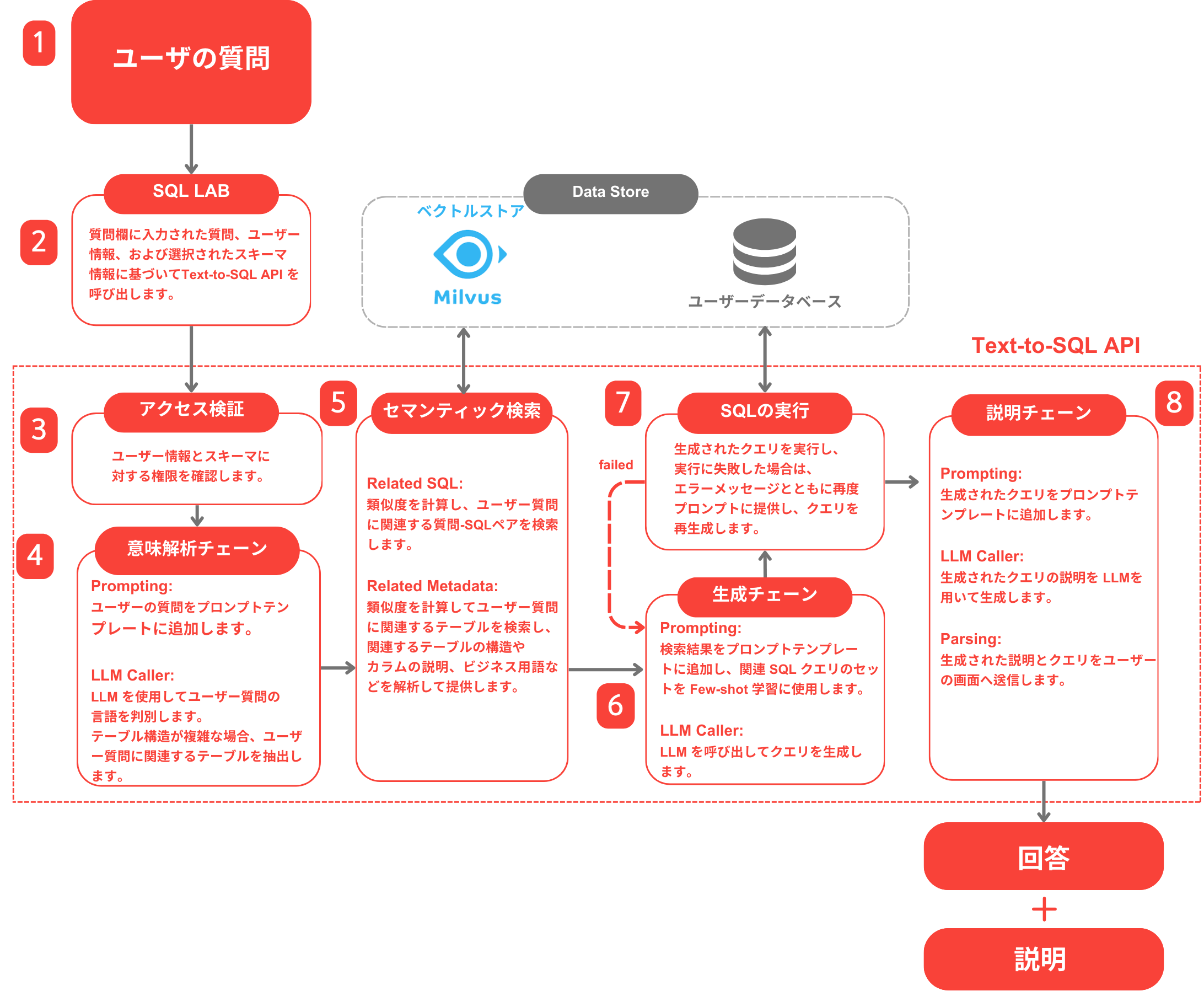
フローに基づく例
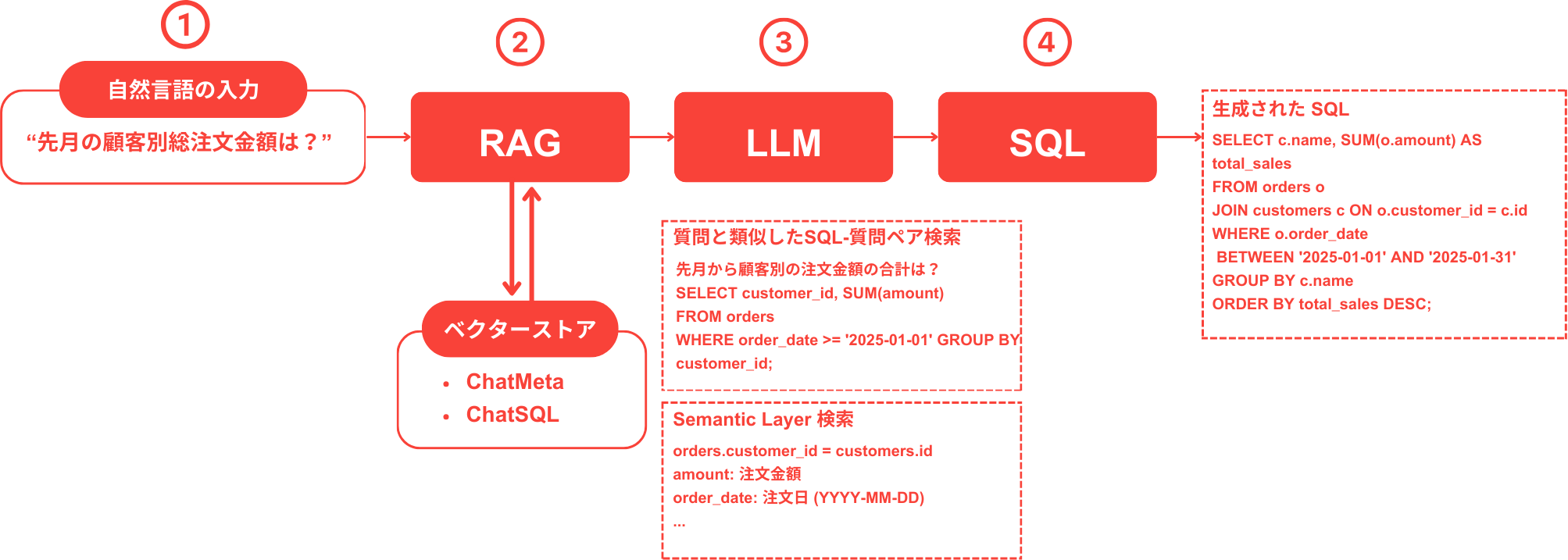
- 自然言語の質問入力
ユーザーが自然言語でデータを照会するための質問を入力します。
例: 「先月の顧客別の総注文金額は?」 - RAG検索
で関連データを検索します。
- ChatMeta: テーブル構造やカラムの説明といったメタデータを検索します。
- ChatSQL: 類似した質問-SQLペアを検索します。
- LLMによるSQL生成
RAGで検索された情報を基に、LLMが適切なSQLクエリを生成します。 - SQLの実行と結果の返却
生成されたSQLを実行し、結果をユーザーに返します。
SQLペアは、ベクターデータベースに保存されるメタデータの一部です。Semantic Layerがデータベース構造とビジネス文脈を整理する基盤情報であるとすれば、質問-SQLペアは過去の使用例として、LLMがより正確なSQLを生成するための例示データとなります。
HEARTCOUNT ABIでは、各情報はその形式に応じてベクターデータベース内の別々のコレクションとして保存され、コレクションごとに主に保存される情報は以下の通りです。
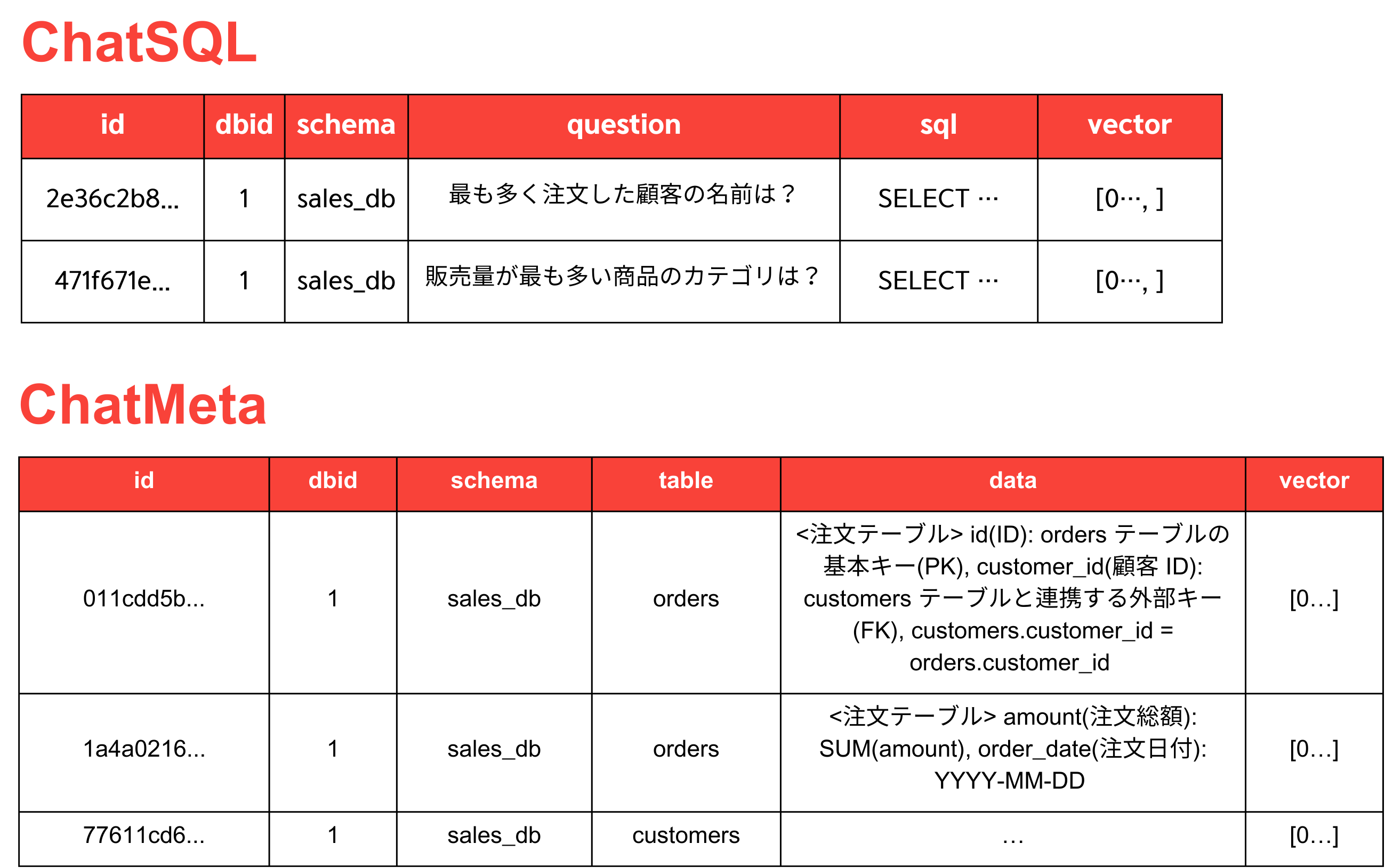
メタデータを保存するさまざまな方法
LLMベースのText to SQLシステムは、メタデータを通じてデータベースの構造と意味を理解し、SQLクエリを生成します。このメタデータをどのように保存および管理するかによって、LLMの性能と精度が大きく左右されます。
ほとんどのサービスは、以下の3つの方法でメタデータを管理しています。

例として挙げられるサービス
Vanna AI
・ユーザーがテーブルやカラムの説明を直接入力することで、ビジネス文脈を強化します。
・ユーザーが提供したDDL(データ定義言語)およびドキュメントデータをベクタDBに保存します。
・初期段階では、ユーザーが提供したスキーマとメタデータを単純に抽出して使用し、質問と回答のデータが蓄積されるにつれてシステムが改善されます。

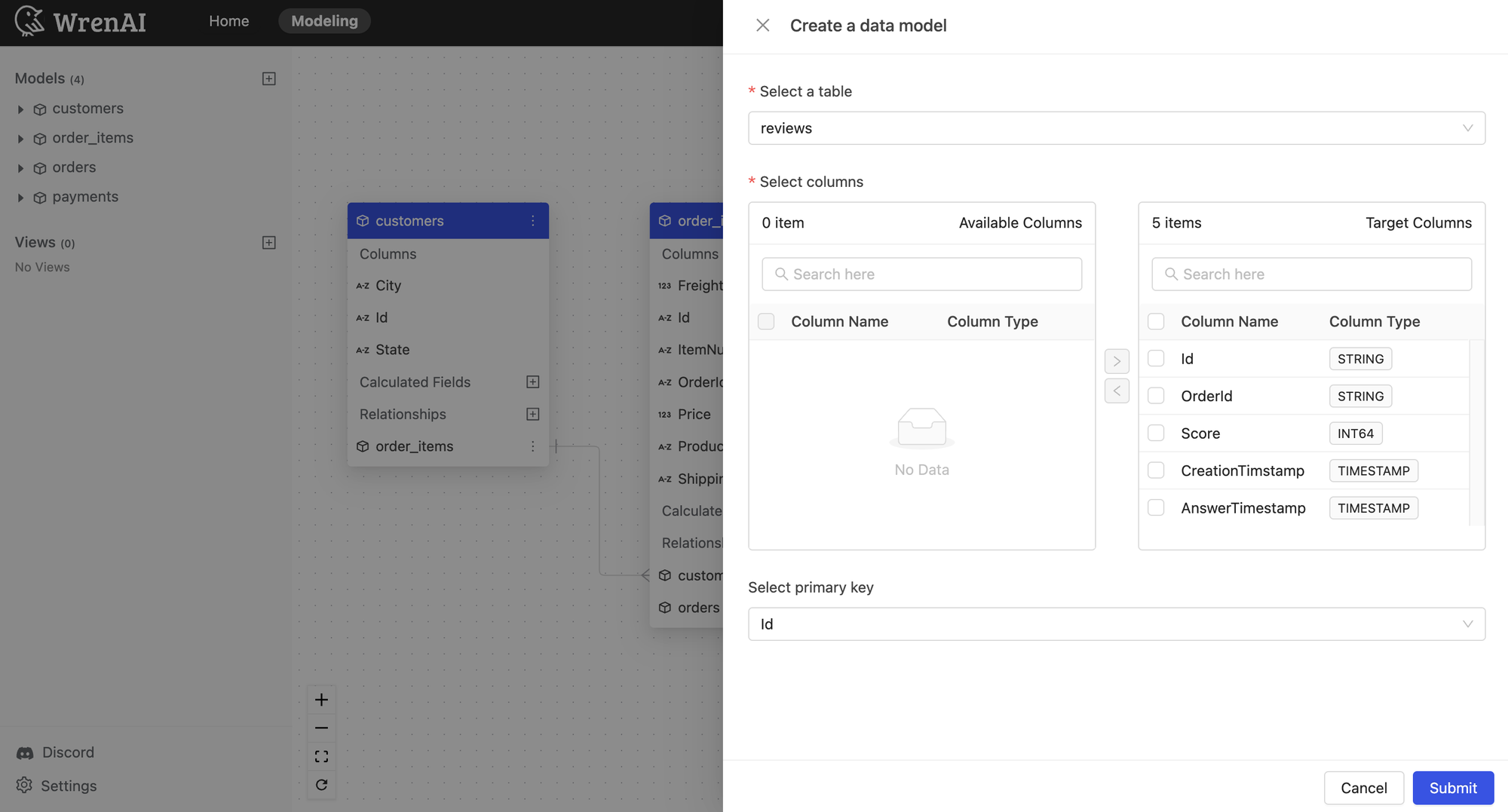
Wren AI
・データモデルをユーザーが直接入力し、メタデータとして保存および活用します。
・複雑なリレーショナルデータベースの構造を自動で分析し、RAGベースの検索性能を強化します。
HEARTCOUNT ABIの差別化ポイント
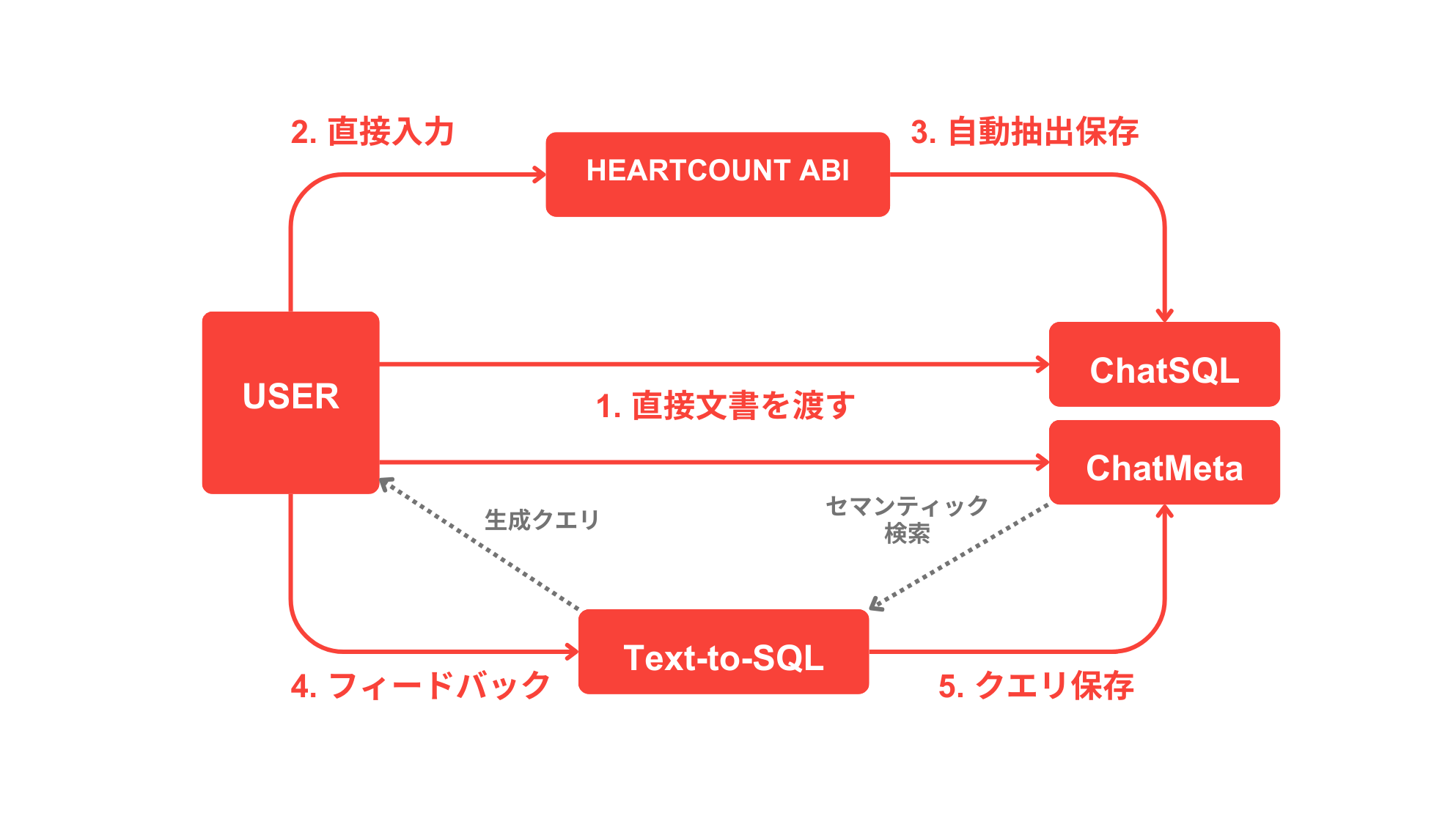
HEARTCOUNT ABIは、従来の3つのメタデータ保存方式の短所を補い、長所を最大限に活用する方法を採用しています。以下の図のように、HEARTCOUNT ABIはユーザーとシステム間のフィードバックループを通じて、継続的にメタデータを拡張し、性能を向上させます。
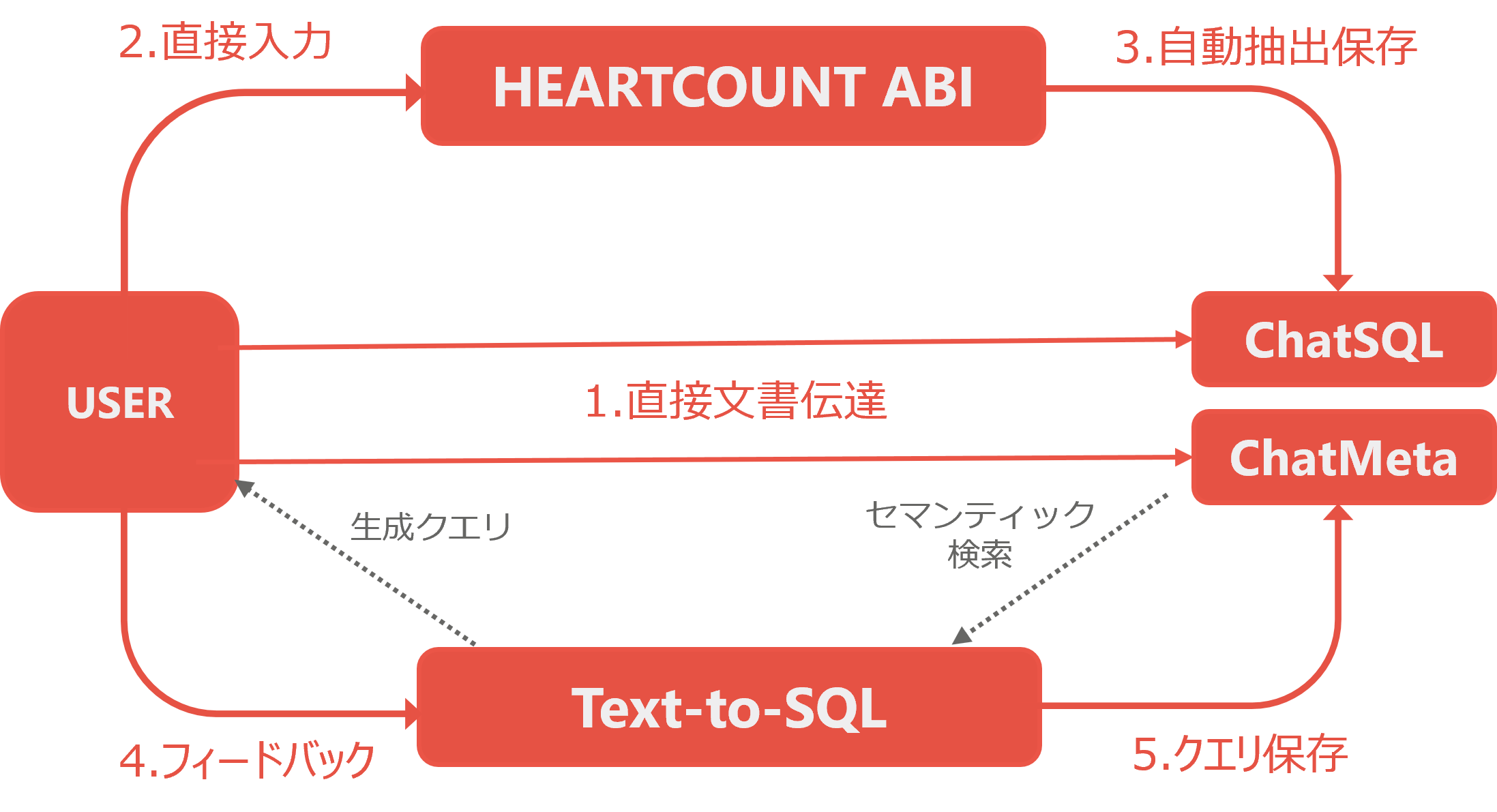
1.ユーザーが直接文書を提供
・企業で使用していた実際のSQLクエリやその説明を提供いただくことで、これを基に初期段階からメタデータを構築できます。
・これにより、システムの初期段階でも高い精度を保証します。
2.ユーザーが直接入力および修正
・ユーザーはABIのUIを通じてテーブル構造やカラムに関する説明を直接入力できます。
・これにより、ビジネス文脈やカスタマイズされたメタデータを簡単に追加できます。
・入力すべき情報が多い場合、指定されたフォーマットに従った文書を提供いただければ迅速にメタデータを構築します。
3.データベースの自動抽出
・設定された周期に応じて企業のデータベースからテーブル構造やスキーマ情報を自動的に読み取り、保存します。
・複雑な設定なしでデータベース構造を簡潔に把握し、メタデータを構成できます。
・ユーザーが入力したメタデータがある場合、それも併せて読み取り、保存します。
4.ユーザーフィードバック
・生成されたクエリは画面を通じてユーザーに提示されます。
・ユーザーは生成されたクエリを直接実行して結果を確認し、生成されたクエリに対するフィードバックをボタンを通じて提供します。
5.クエリの保存
・ユーザーのフィードバックに基づいて、生成されたクエリの結果は削除されるか、学習に使用するためにベクターデータベース(ChatSQL)に保存されます。
・説明や質問の内容を参考に、LLMを通じて質問を生成し、同じクエリに対するデータを増強します。
HEARTCOUNT ABIのアプローチの利点
- 初期からの高精度
企業が提供する実際のSQLクエリとその説明を基に初期メタデータを構築するため、初期段階から優れたパフォーマンスを発揮します。 - カスタマイズされたメタデータの提供
UIを通じて、ビジネス文脈に適した詳細な説明や計算式などを直接入力・管理できます。これにより、特定のニーズに合わせたメタデータの構築が可能です。 - 自動化されたデータベース構造の抽出
テーブル構造やその関係性を自動で把握し保存するだけでなく、必要に応じて追加のメタデータをユーザーに依頼できます。
結果として、HEARTCOUNT ABIは正確性、柔軟性、自動化された管理を組み合わせることで、Text to SQLのパフォーマンスを最大化します。
メタデータ文書作成ガイド
HEARTCOUNT ABIのText to SQL機能を最大限活用するには、正確で体系的なメタデータの作成が重要です。メタデータを適切に作成することで、LLMがデータベースの構造とビジネス文脈をより正確に理解し、正確なSQLクエリを生成できるようになります。以下は、図の「1番(直接文書提供)」方式に基づくメタデータ文書作成ガイドです。
メタデータは次の項目を中心に作成する必要があります:

メタデータ文書作成時の注意事項
- ビジネス用語の使用
- ビジネスユーザーが理解しやすいように、カラムやテーブル名をビジネス用語で説明します。
例: rev → 「総売上」
- ビジネスユーザーが理解しやすいように、カラムやテーブル名をビジネス用語で説明します。
- 関係およびジョイン情報の明記
- テーブル間の関係性とジョイン条件を明確に記述します。
例: orders.customer_id = customers.id
- テーブル間の関係性とジョイン条件を明確に記述します。
- 計算式およびKPIの定義
- カラムに基づく計算式や主要業績指標(KPI)を具体的に記録します。
例: 「純売上 = 売上高 - 割引 - 返品」
- カラムに基づく計算式や主要業績指標(KPI)を具体的に記録します。
- 簡潔で明確な説明
- 説明は重要なポイントを押さえつつ、簡潔に記述します。冗長にならないよう注意してください。
例: revenue → 「製品やサービスの総収益」
- 説明は重要なポイントを押さえつつ、簡潔に記述します。冗長にならないよう注意してください。
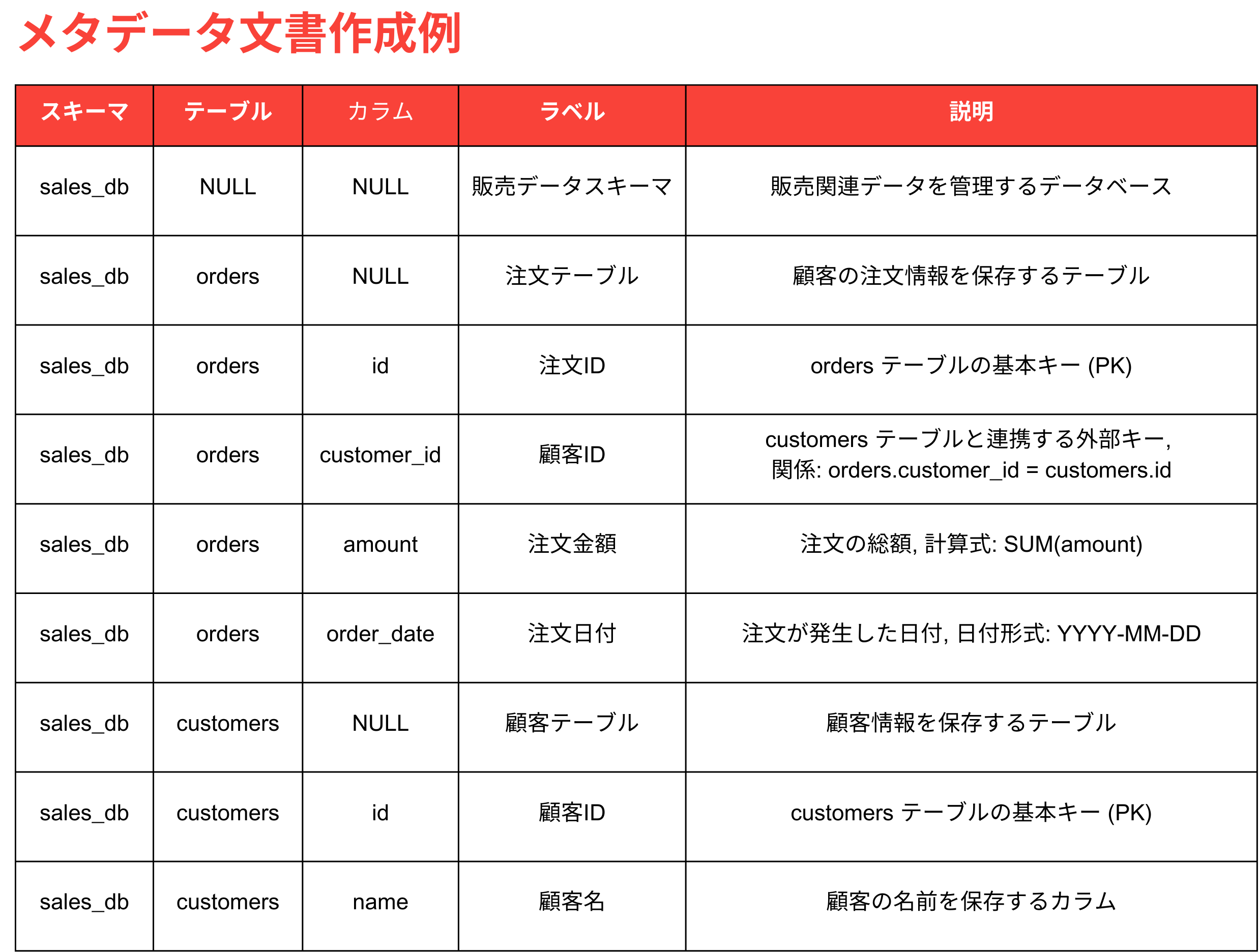
メタデータは単なる構造情報ではなく、ビジネス文脈やデータ間の関係を表現する重要な情報です。
HEARTCOUNT ABIのText to SQL機能は、このメタデータを基にLLMがより正確なクエリを生成できるよう支援します。
メタデータを作成する際には、ビジネス用語、テーブルの関係、計算式を明確に整理することが重要であり、上記の例とガイドを参考にしてExcelファイルやCSV形式で作成して提供してください。
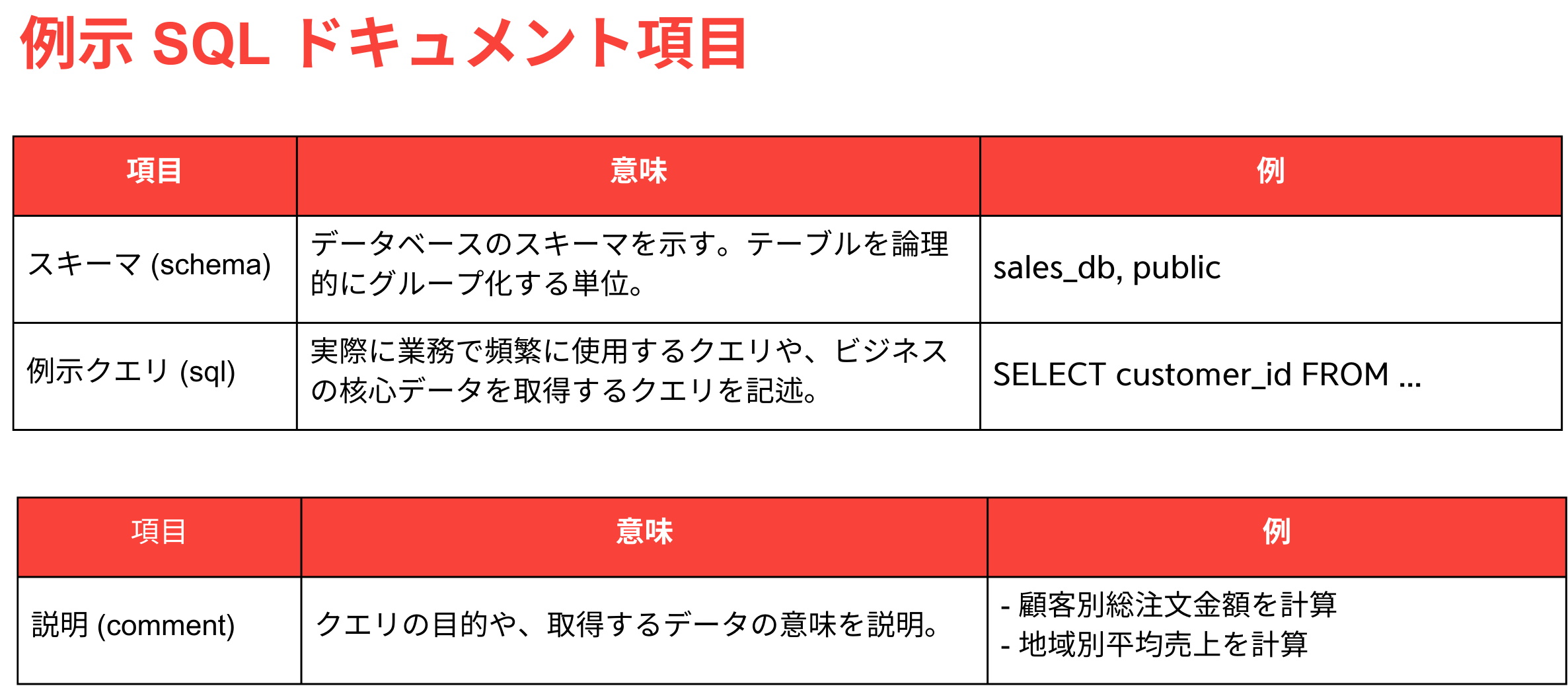
サンプルSQL文書作成ガイド
HEARTCOUNT ABIのText to SQL機能を最大限に活用するためには、LLMに提供するサンプルSQL文書を体系的に作成することが重要です。企業で使用していた実際のSQLクエリと、そのクエリに関する説明を提供することで、初期段階から高い性能と信頼性を持つText to SQL機能を利用できます。
SQL文書の作成は必須ではありませんが、初期性能を向上させ、データベース構造やビジネスの文脈を正確に反映させるために推奨されます。特に頻繁に使用するテーブルや分析クエリに関する最小限の情報を提供することで、LLMが質問に対してより適切なSQLクエリを生成する助けとなります。
文書作成項目
作成したSQL文書はExcelファイル(CSV形式も可能)で提供され、以下の項目を含むように作成します:

結論および期待効果
HEARTCOUNT ABIは、RAG(Retrieval-Augmented Generation)とSemantic Layerを組み合わせ、企業のデータを正確かつ迅速に活用できるText to SQLソリューションを提供します。また、従来のメタデータ保存方式の限界を克服し、企業に特化したメタデータ構築を通じてSQLクエリの正確性と性能を最大化します。
Text to SQL導入時の期待効果
HEARTCOUNT ABIのText to SQL機能を通じて、以下のような効果が期待できます:
- SQLクエリ生成の自動化
・SQLに関する専門知識がなくても、自然言語を使って簡単にデータを照会できます。
・開発者でないユーザーやビジネスユーザーもデータを直接活用することで、意思決定のスピードを向上させることができます。 - 高い正確性と信頼性
・メタデータとRAGベースの検索により、ビジネス文脈やデータの関係を正確に反映したSQLクエリを生成します。
・初期段階から質問-SQLペアを利用することで、高い精度のパフォーマンスを確保します。 - データ活用効率の向上
・テーブルの関係、カラムの意味、計算式を明確に定義したSemantic Layerを基盤に、データベースの複雑な構造を簡略化します。
・データベース構造を理解する必要なく、ビジネス価値を迅速に引き出すことができます。 - 柔軟で拡張可能なメタデータ管理
・ユーザーの入力、スキーマの自動抽出、継続的な学習を通じて、メタデータを拡張し、保守コストを最小化します。 - データ駆動型意思決定の強化
・誰でも簡単にデータを照会・分析できるため、企業のデータ活用度を最大化します。