「誰もが簡単に必要なデータを照会し、必要なデータセットを生成することができれば、どんなに良いでしょうか?」
こんにちは、HEARTCOUNTチームのSamです。 数回クリックするだけでユーザーがデータを直接照会することができるHEARTCOUNT ABIのText-to-SQL機能について以前紹介しました。
 sidney yang
sidney yang
過去には、データ照会のために複雑なSQLクエリを作成しなければならず、これは専門家ではない方にとって大きな障壁となっていました。しかし、最近ではLLMを活用して、専門家ではない方でも簡単にデータにアクセスする道が開かれました。特に、Text-to-SQL機能は、LLMを活用して自然言語の質問を理解し、これをSQLクエリに変換して、ユーザーが望む情報を効率的に提供する代表的な機能です。
それでも、既存のText-to-SQLテクノロジーはいくつかの限界点に直面しており、最近、このような問題を解決するためにRAG (Retrieval-Augmented Generation: 検索拡張生成)という技術が注目されています。今回のブログでは、Text-to-SQLテクノロジーがどのような原理で動作するのか簡単に説明し、既存の問題点とそれを解決するために HEARTCOUNT ABIが RAGを導入することになった理由、そして新しい Text-to-SQL 2.0モデルを皆さんに事前に紹介したいと思います。
Text-to-SQLとは何ですか?
Text-to-SQLとは
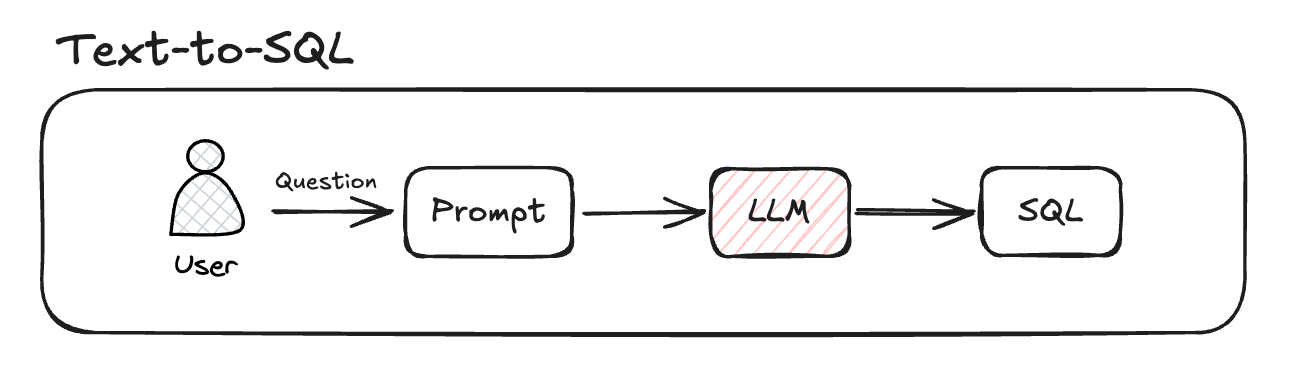
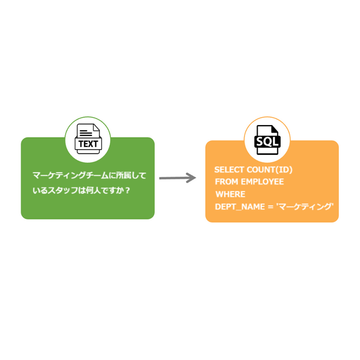
Text-to-SQLは、自然言語で書かれた質問を SQLクエリに自動変換するテクノロジーであり、データベースに対する専門家でない方のアクセシビリティを高める上で重要な役割を果たします。複雑なSQLクエリを作成することなく、ユーザーが「昨年の売上金額が最も高かった月はいつですか?」などの質問を入力すると、この質問をSQL文法に変換して結果を返すことができます。

Text-to-SQL機能は、単にSQLを作成する手間を軽減するだけでなく、ユーザーが直接必要なデータを簡単に見つけて分析できるように支援します。これにより、データ分析プロセスがさらに高速化・効率化され、データチームの業務負担も大幅に軽減されます。
特に、データに基づく迅速な意思決定が重要な現代ビジネス環境では、Text-to-SQL機能は誰でもデータにアクセスしてインサイトを導き出すことができる核心的なツールとして位置付けられています。これにより、企業は全体的なデータ活用度を最大化し、全てのメンバーがデータを活用した戦略的な意思決定を行うことができる環境を構築することができます。
ABI Text-to-SQLの仕組み
既存のHEARTCOUNT ABIのText-to-SQLモデルは次のようなプロセスを経ます。
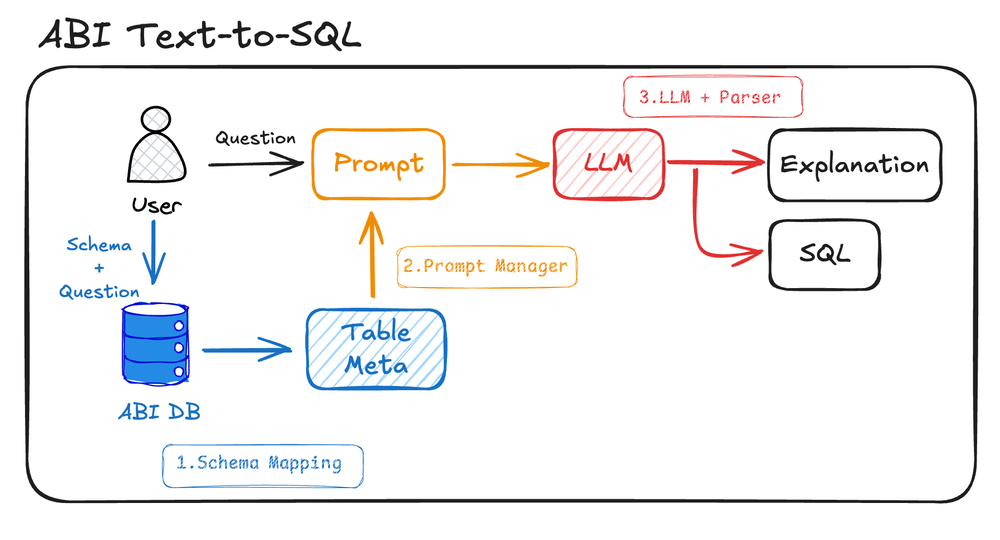
- Schema Mapping (スキーママッピング): データベース内のテーブルと列に関する情報を利用して、質問に関連する特定のテーブルとスキーマをマッピングします。
- Prompt Manager (プロンプトマネージャー): 質問に最適な回答を提供するため、プロンプトを生成して管理するモジュールです。
- LLM + Parser (LLM + パーサー): 作成したプロンプトとLLMに基づいてSQLクエリを生成します。
正確なクエリ生成のためには、データベースの構造と質問の意味を正しく把握することが重要です。ABIのText-to-SQLモデルは、このプロセスを単純なルールベースのプロンプトまたはスキーママッピング方式で処理してきましたが、複雑な質問や特定ドメインに特化した問い合わせでは精度が低下するという問題がありました。
既存のABI Text-to-SQLモデルの問題点
現在、HEARTCOUNT ABIで使用されているText-to-SQLモデルの限界は大きく2つに要約されます。
- 精度の問題
既存のモデルには、特化したドメインに関する質問を処理する際、パフォーマンスが低下する問題がありました。特に、ドメインに特化した用語を使用したり、複雑なクエリ構造が含まれている場合、モデルが正確なSQLを生成できないことがよくありました。これは、データベースのスキーマと質問の間の接続を正確に把握できなかったためです。また、同じルールやプロンプトがすべてのデータベースに適用されるため、few-shot学習のメリットを十分に活用できないという限界もありました。
Few-shot学習は、モデルが新しいタスクを実行する際に、いくつかの例だけでそのタスクの文脈と構造を理解するのに役立つ手法です。特に、言語モデルでは、既存の学習データに加えて、プロンプトに類似の質問と回答をいくつか追加することで、モデルが新しい質問の意図をより正確に把握し、回答の品質を向上させることができます。これにより、モデルが学習されていない新しい状況にもうまく適応できるようになります。
次の例として、医療分野のような特殊なドメインを想定してみましょう。LLMを活用したText-to-SQLモデルは、「心血管疾患」の概念を理解することはできますが、データで「心血管疾患」が疾患コードとしてのみで表現されている場合、関連する疾患コードを見つけてSQLに含めることは容易ではありません。ドメインの専門用語が多くなればなるほど、参照すべきテーブルや列を正確に把握できず、精度が低下する可能性があります。しかし、few-shot学習で心血管疾患関連の質問とSQLの例を追加的に学習させると、モデルが参照する疾患コードと使用されているテーブルや列を把握し、より正確なSQLを生成するのに役立ちます。

- トークン使用量の問題
大規模なデータベースや複雑な質問の処理過程で、モデルは多くのトークンを消費し、非効率的なリソース使用が発生します。この問題は、特に様々なデータベーススキーマと大量のマッピング情報が要求される場合に深刻化し、クエリ全体とデータベース構造をプロンプトとして一緒に提供する場合、プロンプトが長くなるため、モデルのコンテキスト把握が難しくなり、精度の問題 (Lost in the Middle) につながる可能性があります。
プロンプトが長すぎると、モデルが途中にある重要な情報を見逃す現象のことを指します。特に、長いプロンプトでは先頭と末尾の情報だけがよく反映され、中間情報が疎かに処理され、応答の精度が低下する問題が発生するという可能性があります。これは、複雑なデータベーススキーマや複数のマッピング情報を含む場合により顕著になります。

RAGとは何ですか?
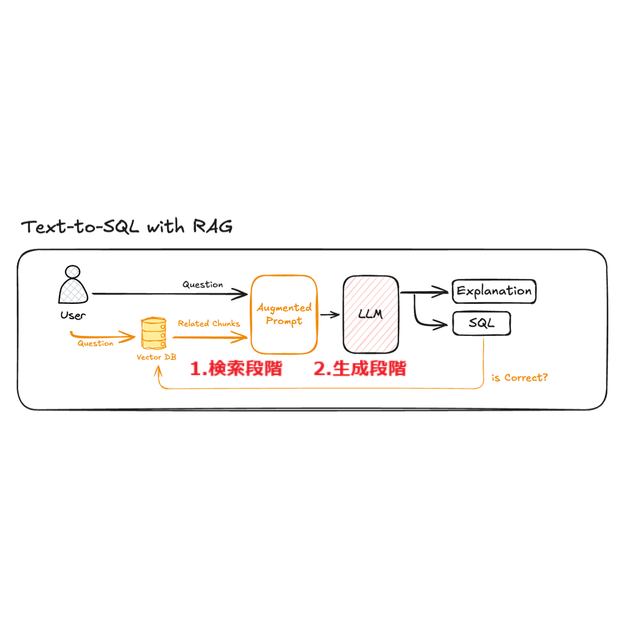
RAG (Retrieval-Augmented Generation: 検索拡張生成)は、大規模言語モデル(LLM)の限界を補完するために考案された方法で、質問に対する外部情報を検索して回答を生成する統合アプローチです。従来のLLMは学習されたデータに依存しているため、最新の情報や学習データに含まれていない特殊なドメインに関する知識が不足することがあります。RAGは、このような問題を解決するために、モデルが特定の質問に対して外部から関連データを検索し、それに基づいて回答を生成できるようにします。
RAGは通常、検索と生成の2つの段階(ステップ)を経ます:
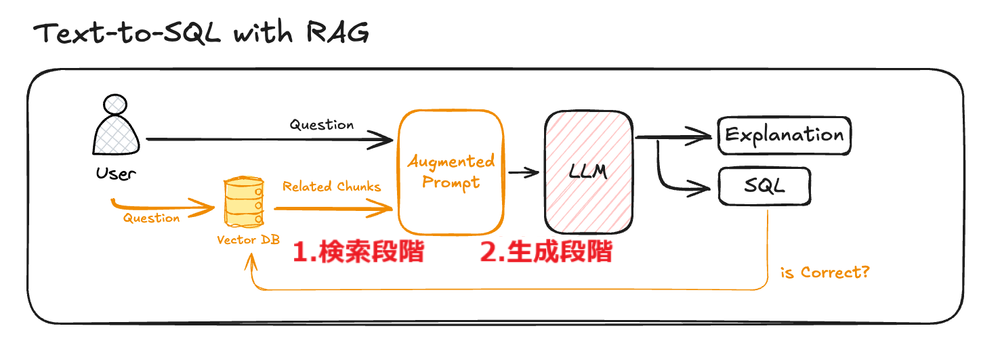
- 検索段階: 質問に関する関連情報をデータベースやナレッジベースから検索し、必要な情報を取得します。
- 生成段階: 検索された情報に基づいて質問に対する回答を生成します。LLMは検索された情報と質問を一緒に入力として受け取り、適切な回答を構成します。
このような統合方式のおかげで、RAGはモデルが学習データに含まれていない最新の情報や特定のドメインに関する質問に対して、より正確で信頼性の高い回答を提供することができます。
目には目を、SQLにはSQLを
RAGの強みは、検索と生成の組み合わせにあります。一般的な生成モデルは学習データのみに依存しますが、RAGはモデルが検索した関連性の高いデータを含めることで、回答の精度を高めます。例えば、ユーザーがText-to-SQLモデルに特化したデータベーススキーマに関連する質問を投げかけると、RAGはそのデータベースに類似した質問を検索してモデルに提供し、より正確なSQLクエリを生成できるようにします。
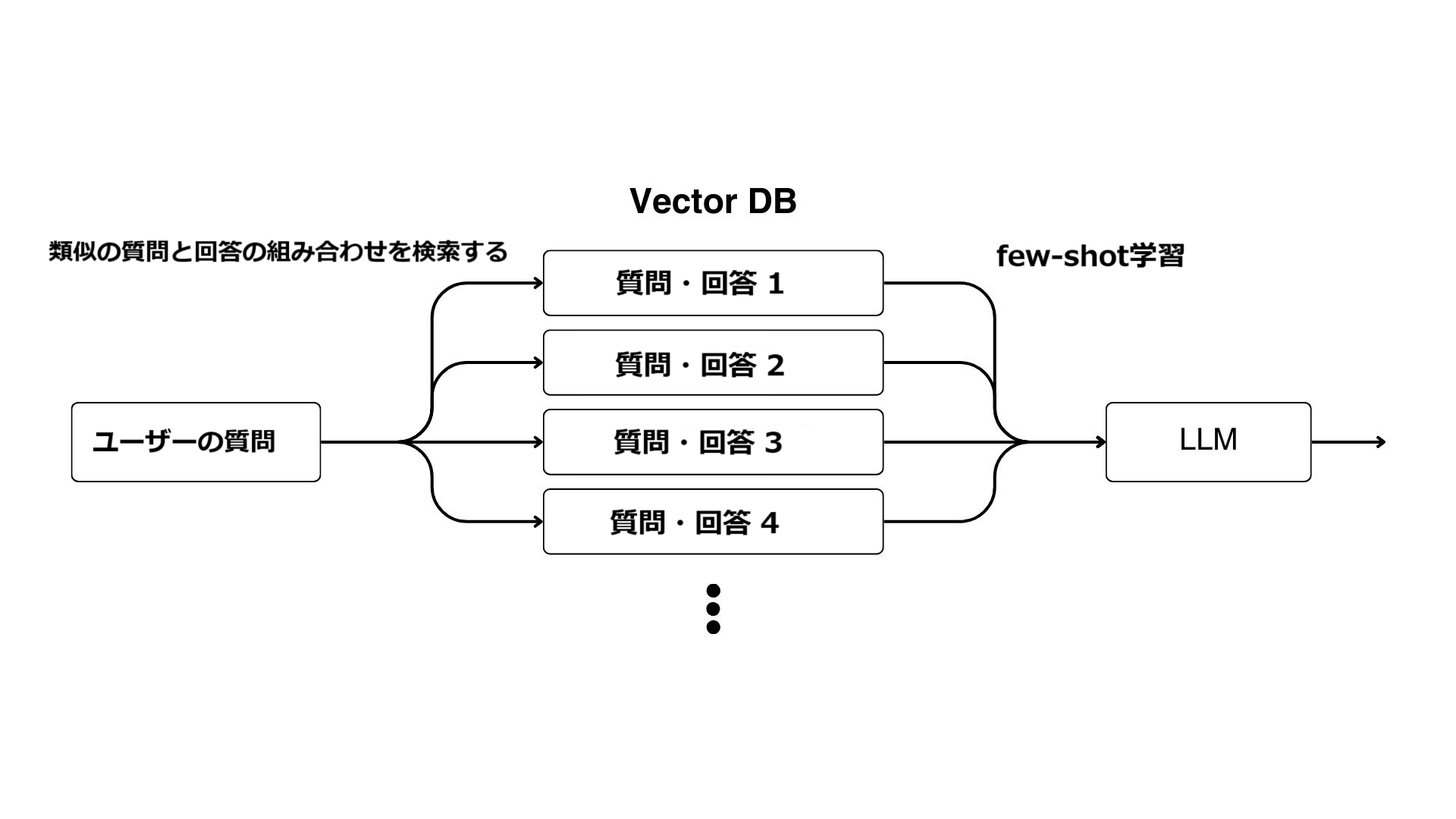
このように検索された情報がモデルの入力に入ることで、few-shot学習のようなテクノロジーの効果が最大化されます。具体的には、RAGは類似の質問とその回答をプロンプトに含めることで、モデルが質問と回答の文脈をよりよく理解し、結果としてより正確なクエリを生成するのに役立ちます。
Text-to-SQL 2.0の紹介
RAGで解決できること
Text-to-SQLモデルにおいて、RAG (Retrieval-Augmented Generation: 検索拡張生成)は従来の限界を克服することに大きく貢献します。以前は、すべての質問に対して同じルールとプロンプトが適用されるため、ドメインや質問の種類によって精度と柔軟性が低下していました。しかし、RAGは類似の質問とデータを検索して、それをモデルのプロンプトとして追加することで、ユーザーが投げかける特定の質問や状況に適応することができます。例えば、ユーザーが「2022年の売上金額が最も多かった月を知りたい」と質問した場合、RAGは類似の売上分析の質問を検索し、これに基づいてSQLクエリを生成することで精度を向上させることができます。
このアプローチにより、RAGはモデルがfew-shot学習の利点をより効果的に活用できるようになります。従来のText-to-SQLモデルが質問の文脈を十分に反映できなかったのに対し、RAGは類似の質問の事例を活用することで、質問の意図をより深く理解することができます。これにより、特定のデータベーススキーマやドメインに特化したクエリにも柔軟に対応できるようになりました。
Text-to-SQL 2.0の主な技術コンポーネント
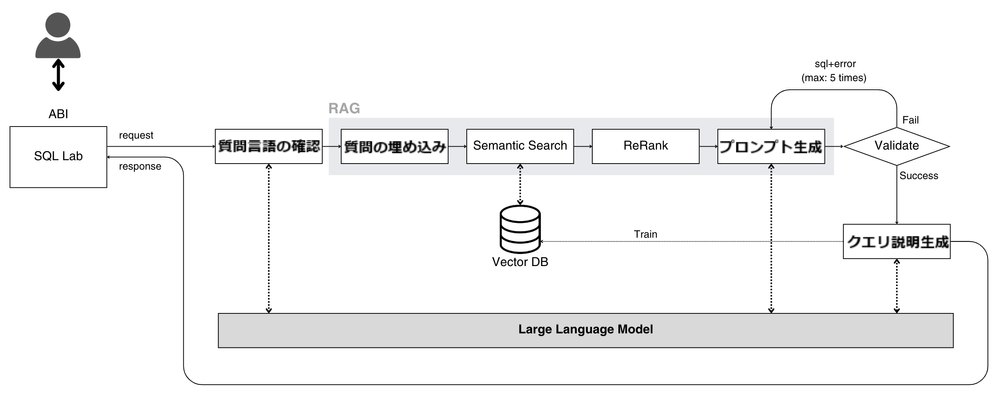
RAGベースのText-to-SQL 2.0モデルは、検索エンジンと大規模言語モデル(LLM)を組み合わせたものです。このプロセスの主なコンポーネントは以下の通りです:
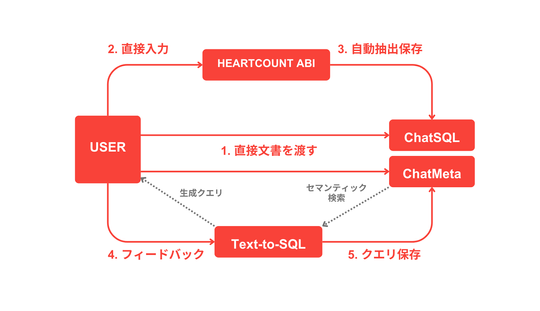
- 質問言語の確認: 入力された質問に使用されている言語をLLMによって把握します。ベクトルストアで情報を言語によって区分して保存するため、質問の言語を確認するプロセスを経ます。
- 質問の埋め込み: 質問をベクトルストアで検索するために質問を埋め込むプロセスを経ます。埋め込みが完了した質問はベクトル形式になり、ベクトルストアで最も類似したベクトルを検索することになります。
- 検索段階(Semantic Search): 入力された質問と類似した質問、テーブル構造、メタ情報などをベクトルストアで検索し、関連性の高い情報を探します。例えば、売上データを求める質問であれば、過去の売上関連のクエリとテーブル構造を参照することで、複雑なデータベース構造を効率的に把握します。
- ReRank: テーブル構造やメタ情報のようなデータは、テキスト形式でプロンプトに追加する場合、トークンが多くなるだけでなく、「Lost in the Middle」問題が発生する可能性があります。これを解決するために、検索されたデータを圧縮して再配置するプロセスが必要です。
- プロンプト生成: 検索された情報(テーブル構造、メタ情報など)はプロンプトに含まれ、検索された似たような質問はfew-shot学習をさせてモデルがより正確なSQLクエリを生成できるようにします。
- クエリ検証段階: LLMモデルを通じて受け取ったクエリが実際に実行可能なクエリかどうかを検証する段階です。もし実行されない場合、間違ったクエリとエラーメッセージをプロンプトに追加して再びLLMから回答を受けるプロセスが実行されます。このプロセスは最大5回までしか行われません。
- クエリ説明の生成: 正常に実行されることが確認されたクエリは、LLMからクエリの説明を応答されます。回答は、質問に使用された言語と同じ言語を使用して提供されます。また、ユーザーのフィードバックにより、ベクトルストアに保存するかどうかを判断します。
Text-to-SQLテクノロジーは、データへのアクセスと活用におけるユーザーエクスペリエンスを大幅に革新する可能性を秘めています。 特に、専門家ではない方が直接データベースにアクセスして必要なデータを自由に照会できる可能性は、企業内の全てのメンバーがデータドリブン型の意思決定を行うことができる環境を構築する上で重要な役割を果たします。
既存のText-to-SQLモデルがドメインの適応性と正確性の面で限界を経験しながらも、最近、RAG (Retrieval-Augmented Generation)テクノロジーが導入されたため、この限界は克服の道を見つけました。RAGを活用したText-to-SQL 2.0は、検索と生成を統合し、類似の質問を検索し、few-shotの形式で学習を適用することで、クエリの文脈をより深く理解し、精度と実行結果の一貫性を高めることができるようになりました。