1.テキスト分析(Text Analytics)に関心があり、この分野の基本的な知識と分析手法を理解したい方。
2.ChatGPTを含む大規模言語モデル(LLM)がテキスト分析の自動化にどのように貢献できるかを知りたい方。
3.従来のテキスト分析方法とAIベースの新しいアプローチの違いや長所と短所を理解したい方。
LLMの登場: 時代の変化
2023年はテクノロジー業界にとって画期的な年でした。
すべての専門家が注目した中心には、OpenAI がリリースした ChatGPT がありました。このAIモデルは私たちの日常生活や働き方に大きな影響を与えました。
このような変化の流れの中で、Meta の LLaMa 2 は7月18日に、Google の Gemini は12月6日にそれぞれ公開されました。
これらの革新的な巨大言語モデル(LLM)は、単純なテキスト分析にとどまらず、データ処理や解釈方法を根本的に変えています。
2024年には、どのような技術革新が私たちを驚かせるのか、想像もつきません。
このような状況において、私たちがとるべき最も賢明な行動は何でしょうか?
ふと、アイザック・ニュートンの言葉を思い出します。
"If I have seen further it is by standing on the shoulders of Giants."
「もし私がもっと遠くを見ることができたなら、それは巨人の肩の上に立ったからだ。」
私たちは巨人の肩の上に立つことで、新しい視点で世界を見ることができます。
ChatGPT は従来のテキスト分析方法と比較して、どのような新しい機会を提供するのでしょうか?
今回のブログでは、この質問に対する答えを探ってみたいと思います。
テキスト分析とは
まず、テキスト分析について説明します。
以下のような図を見たことがありますか?

ここで示されているものは、テキストデータを分析して視覚化するために用いられる伝統的な手法です。
左から順に、コードダイアグラムはオブジェクト間の相互関係を視覚的に表現する方法、ワードクラウドは頻繁に出現する単語を大きさと色で区分して表現する方法、共起ネットワークは一緒に出現する単語間の関係をネットワーク形式で視覚化する方法です。
様々なテキスト分析手法
テキスト分析にも様々な分野があります。
この記事では、テキストデータをテーマ別に集約し、キーワードを抽出するいくつかの手法に注目してみたいと思います。
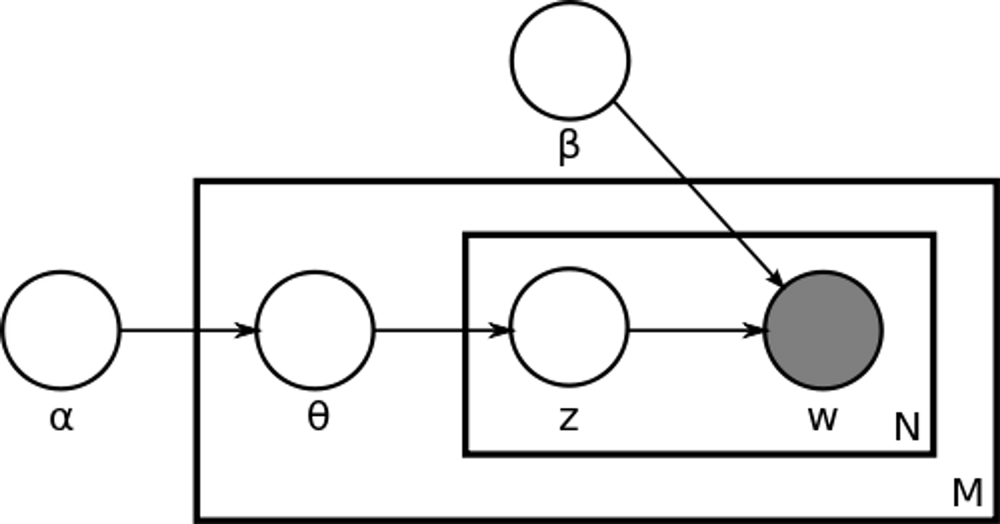
- 潜在的ディリクレ配分法 (LDA: Latent Dirichlet Allocation)
- LDAはトピックモデリングの分野で最も人気のあるアルゴリズムの一つで、文書を複数のトピックの組み合わせとみなし、各トピックが特定の単語で構成される確率分布で表現できると仮定します。
- LDAでは2つのディリクレ(Dirichlet)分布を使用します。各文書について、どのトピックがどれほど重要であるかを示す文書内のトピック分布と、各トピックについて、そのトピックを構成する単語がどれほど重要であるかを示すトピック内の単語分布です。LDAを使用すると、各文書に対するトピックの分布を推定することができ、これに基づいてトピック別のキーワードを抽出することができます。
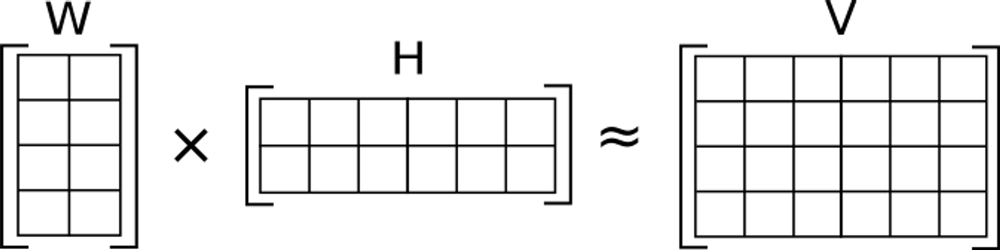
- 非負値行列因子分解 (NMF: Non-negative Matrix Factorization)
- NMFは高次元データをより低い次元の2つの行列に分解する手法で、このプロセスにより文書内のトピックの重要度を決定する重みを導き出すことができます。
- 与えられた V (文書-単語行列)を W (文書-特性行列)と H (特性-単語行列)に分解します。この過程で、V ≈ WHという条件を満たすようにします。分解されるすべての要素は非負(Non-negative)でなければなりません。NMFを通じて各トピックについて識別した代表的な単語をキーワードとして使用することができます。これは Scikit-Learn ライブラリから
NMFを import して実装することができます。
- K-meansクラスタリング
- K-meansは、テキストデータをベクトル空間モデルに変換し、これに基づいてデータポイントをK個のクラスタに分類する一般的なクラスタリングの方法です。
- まず、K個の中心点(centroid)をランダムに設定し、各データポイントを最も近い中心点のクラスタに割り当てます。次に、中心点を再計算し、このプロセスを繰り返します。目標は、クラスタ内の分散を最小化することです。このクラスタリングの結果に基づいて、各クラスタに属する文書から主要なキーワードを抽出することができます。 Scikit-Learn の
KMeansやTfidfVectorizerを使用して実装することができます。
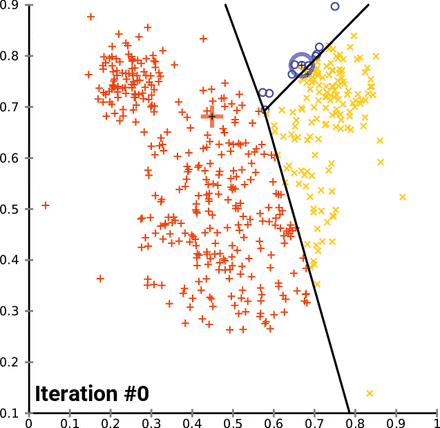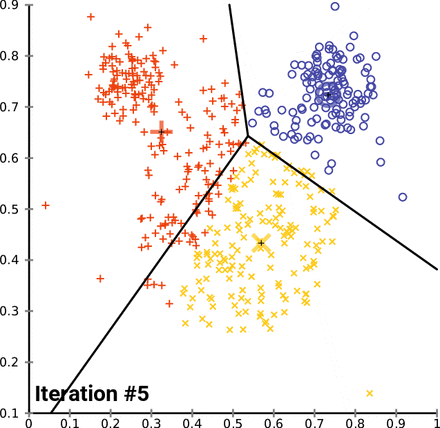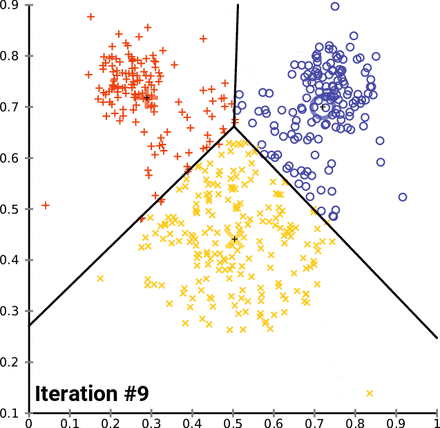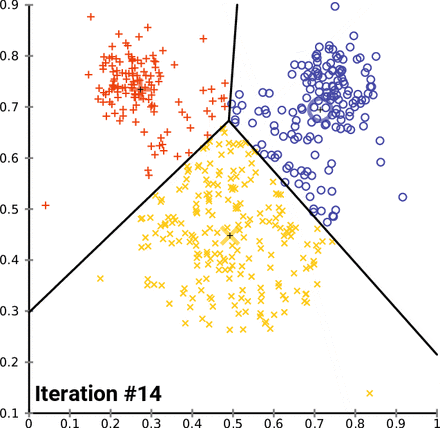
- 単語の埋め込み(Word Embedding)ベースのアプローチ
- Word2Vec や GloVe のような単語の埋め込みモデルは、単語をその共起頻度と文脈に基づいて密なベクトル形式で表現します。つまり、単語間の類似度や意味的な関係を数値的に表現することができます。
- 埋め込まれた単語ベクトルをクラスタリングの手法などを使用して類似の単語をクラスタリングし、これに基づいてトピック別にキーワードを抽出することができます。Word2Vec の場合、Google の
gensimライブラリを使用することができます。
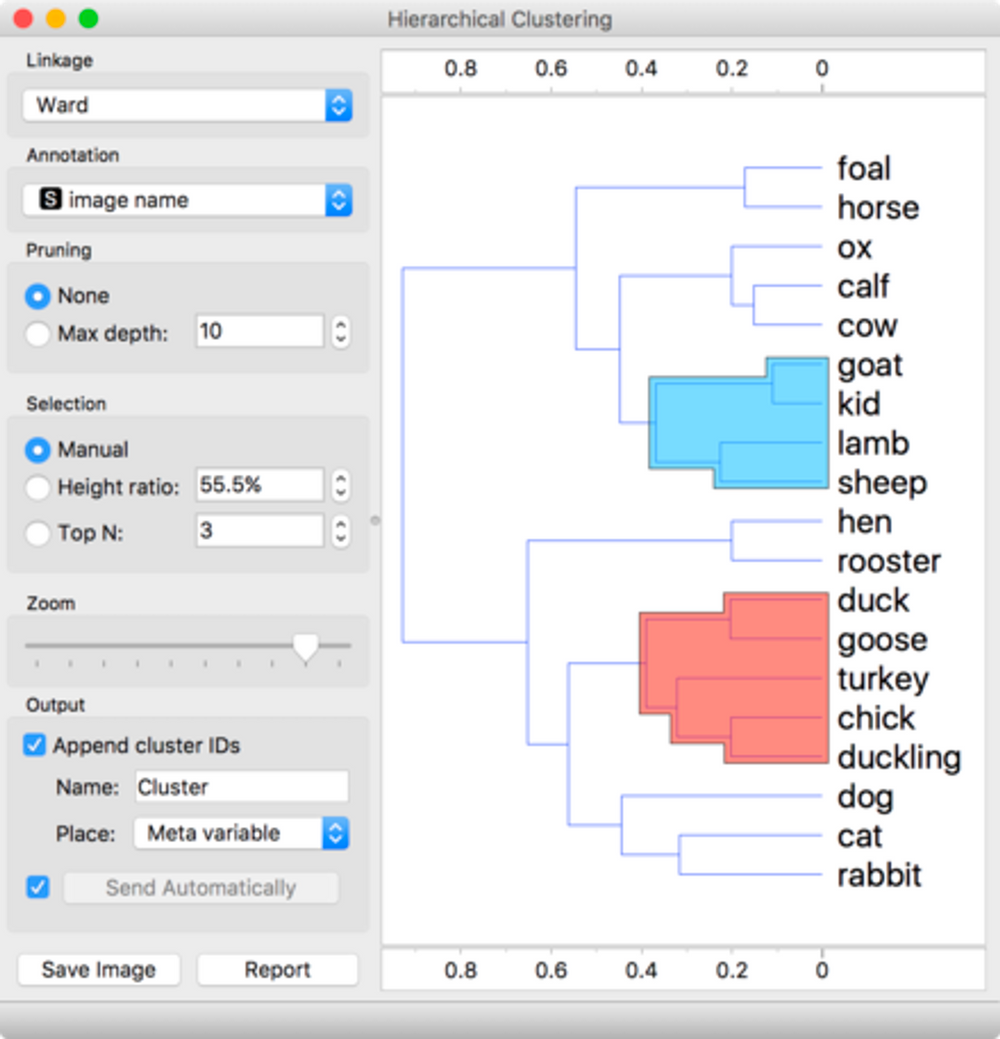
- 階層的クラスタリング (Hierarchical Clustering)
- 階層的クラスタリングの方法は、データポイントをツリー形式の構造にまとめてグループ化するプロセスです。このアルゴリズムは、各データポイントを1つのクラスタとして開始し、最も類似したクラスタを徐々にマージしていきます。また、クラスタの個数を事前に指定する必要はありません。
- 階層的クラスタリングにより、テキストデータを様々なレベルでグループ化し、各グループの代表的なキーワードを抽出することができます。Scikit-Learn の
AgglomerativeClusteringを使用することができます。
テキストデータのトピック別構造を把握し、各トピックの核心のキーワードを識別するのに便利な手法を紹介しました。
実習のための準備
まず、分析のために Kaggle から1つのデータセットを選択してダウンロードしてみましょう。
「News Category Dataset」には Kaggle が提供する2012年から2022年までの Huffington Post のニュース記事約20万件が含まれており、テキスト分類やクラスタリングの実習に適しています。


伝統的なテキスト分析の実習
次に、テキスト処理手法の伝統的な方法である単語の埋め込み(Word Embedding)を実行した後、K-meansクラスタリングを適用するプロセスとその結果を見てみましょう。
- outputファイル (全体)
- データ準備: 分析のためにJSON形式のテキストデータファイルを読み込みます。
- コード
import pandas as pd
import json
# JSONファイルからデータを読み込む
data = []
with open('./News_Category_Dataset_v3.json', 'r') as file:
for line in file:
data.append(json.loads(line))
# データフレームに変換
df = pd.DataFrame(data)- テキストの前処理: 大文字と小文字の一致、特殊文字とストップワードの削除、トークン化など、テキストのクレンジングと標準化を行います。
- コード
import pandas as pd
import gensim
from gensim.parsing.preprocessing import preprocess_string, strip_tags, strip_punctuation, strip_multiple_whitespaces, strip_numeric, remove_stopwords, strip_short
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
# 'headline' と 'short_description' を結合した新規の 'text' 列を作成します。
df['text'] = df['headline'] + ' ' + df['short_description']
CUSTOM_FILTERS = [lambda x: x.lower(), strip_tags, strip_punctuation, strip_multiple_whitespaces, strip_numeric, remove_stopwords, strip_short]
def preprocess_text(text):
return preprocess_string(text, CUSTOM_FILTERS)
# 'text' 列の前処理とトークン化
df['processed_text'] = df['text'].apply(lambda x: preprocess_text(x))- Word2Vecモデルの学習: Word2Vecモデルを使用して、テキストデータ内の単語を固定サイズのベクトルに変換する作業を行います。
- コード
from gensim.models import Word2Vec
# Word2Vecモデルの学習
model = Word2Vec(sentences=df['processed_text'], vector_size=100, window=5, min_count=1, workers=4)- 文書のベクトル化: 文書または文章単位のベクトルを生成するために、単語ベクトルの平均を取る方法を適用します。
- コード
import numpy as np
# 単語ベクトルの平均を利用して文書ベクトルを生成する関数
def document_vector(word2vec_model, doc):
# 辞書にない単語を削除
doc = [word for word in doc if word in word2vec_model.wv]
if len(doc) == 0:
return np.zeros(word2vec_model.vector_size)
return np.mean(word2vec_model.wv[doc], axis=0)
# 各文書に対して関数を適用
df['doc_vector'] = df['processed_text'].apply(lambda x: document_vector(model, x))- K-meansクラスタリング: データをクラスタリングするクラスタの個数 k を決定します(この例では6つのクラスタを選択しました)。その後、ベクトル化されたデータに K-means アルゴリズムを適用してデータポイントを k 個のクラスタに分割します。
- コード
from sklearn.cluster import KMeans
# クラスタの個数を指定 - 比較できるように6個にする
n_clusters = 6
# K-meansクラスタリング
kmeans = KMeans(n_clusters=n_clusters, random_state=0)
kmeans.fit(X)
# データフレームの 'cluster' 列に行ごとにlabelを保存
df['cluster'] = kmeans.labels_- 結果の解釈: クラスタリングの結果をExcelファイルに保存し、各クラスタごとに重要な単語や表現をキーワードとして選定します。
- コード
# クラスタデータを保存するためのリスト初期化
clustered_data = []
# クラスタごとにループして処理
for i in range(6):
cluster = df[df['cluster'] == i]
cluster_texts = cluster['text'].tolist() # Convert text column to list
cluster_headlines = cluster['headline'].tolist() # Convert headline column to list
# クラスタデータをリストに追加
for text, headline in zip(cluster_texts, cluster_headlines):
clustered_data.append({'Cluster': i, 'Headline': headline, 'Text': text})
# リストからDataFrameを生成
clusters_df = pd.DataFrame(clustered_data)クラスタ = 0: 旅行の分野と推定
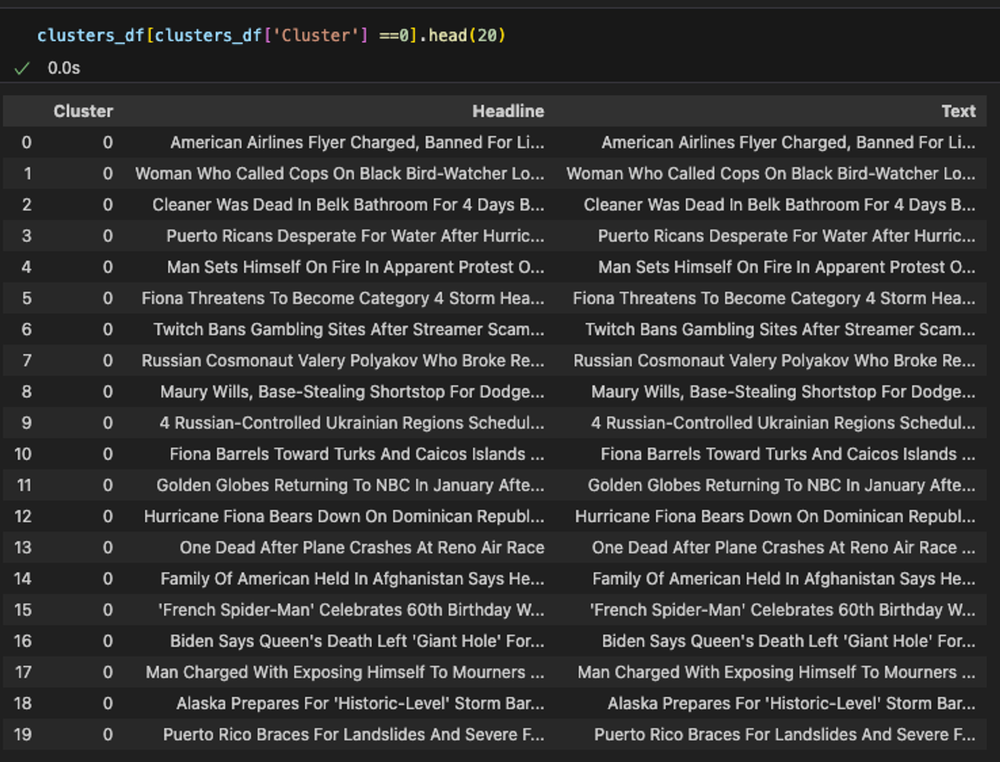
クラスタ = 1: スタイルと美容の分野と推定
クラスタ = 2: 経済の分野と推定
クラスタ = 3: ウェルネスの分野と推定
クラスタ = 4: 政治の分野と推定
クラスタ = 5: エンターテインメントの分野と推定
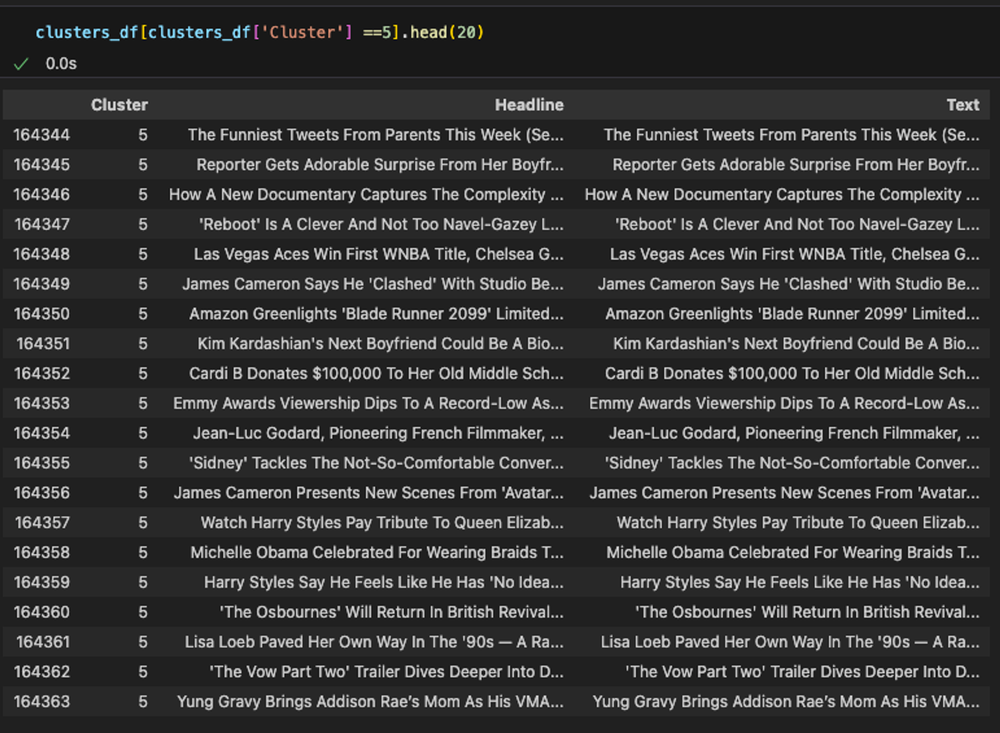
クラスタリングを利用した分析結果
分析結果を見て、
私たちの2つの目標がうまく達成されたように見えますか?
| 目標 | 結果 | |
|---|---|---|
| 1 | テキストデータをテーマ別にクラスタリング | ○ |
| 2 | キーワードを抽出するタスク | ✕ |
ご覧の通り、クラスタリングはトピックを直接抽出するわけではありませんが、類似した文書をグループ化するのに役立ちます。このようなグループ化により、共通のテーマやトピックを把握することができます。
各クラスタが似たようなトピック別によくクラスタリングされていることを確認することができます。しかし、具体的なキーワード(keyword)を決定するためには、各データを個別に調べて決定する必要があります。
このようなプロセスをLLMに委任した場合、どのような結果が出るのでしょうか?
🎬 ネタバレ
従来のテキスト分析ツールは特定のタイプのデータに最適化されているのに対し、ChatGPTは様々な形式やスタイルのテキストデータを柔軟に処理することができます。また、高度な言語理解能力に基づいて複雑な文脈やニュアンスを把握することに強みがあります。
LLM(大規模言語モデル)を使っての実習
逆に、ChatGPT API を使った結果を見てみましょう。(「GPT_6」は、データセットで最も多くのデータを含む上位6つのトピックを基準に分類した結果です。) クラスタごとに上位25個のデータをそれぞれ出力しました。
- コード
# 必要なライブラリ
import os
import time
import openai as ai
import pandas as pd
import numpy as np
import json
# 2023年8月現在、最新のgpt-3.5-turbo-0613を使用 - 16,385 tokens
ai.api_key = '発行された_API_キー'
model="gpt-3.5-turbo-0613"
# データの読み込み
Data =pd.read_json(open("./News_Category_Dataset_v3.json","r",encoding="utf-8"),lines=True)
Data = Data[['category','headline','short_description']]
Data.head(3)
# 各トピックごとに最も多くのデータを持つ上位6つのトピックを選択
topics = list(pd.DataFrame(Data.groupby(['category']).agg(Count = ('category','count'))['Count']\\
.nlargest(6)).reset_index()['category'])
# 選択したトピックに該当するデータのみをフィルタリング
Data = Data[Data['category'].isin(topics)]
# 各カテゴリごとに25個のサンプルを選択
Data = Data.groupby(['category']).sample(25)
# 要求された応答を返す関数
def generate_gpt3_response(user_text, print_output=False):
"""
Query OpenAI GPT-3 for the specific key and get back a response
:type user_text: str the user's text to query for
:type print_output: boolean whether or not to print the raw output JSON
"""
time.sleep(5)
completions = ai.Completion.create(
engine='text-davinci-003',
temperature=0.5,
prompt=user_text,
max_tokens=500,
n=1,
stop=None,
)
# 必要に応じて中間結果を出力
if print_output:
print(completions)
# 最初の応答テキストを返す
return completions.choices[0].text
# より意味のあるトピックを得るために、タイトルと説明を1つの列に追加
Data['Head_Description'] = Data['headline']+" :"+ Data['short_description']
# 各ニュース項目のトピックを抽出するプロンプトエンジニアリング
Data['GPT'] = Data['Head_Description'].apply(lambda x: \\
generate_gpt3_response\\
("I am giving you the title and short description \\
of the news article in the format [Title:Description], \\
give me the Broader category like News, sports, entertainment,\\
wellness or the related high level topics in one word in the \\
format[Topic: your primary topic] for the text '{}' ".format(x)))
# ChatGPTで生成された出力の処理とトピックの抽出
Data['GPT'] = Data['GPT'].apply(lambda x: (x.split(':')[1]).replace(']',''))
# データフレームをExcelファイルとして保存
Data.to_excel('data_output.xlsx', index=False)- output ファイル
- Entertainment (エンターテインメント)

- Parenting (子育て)

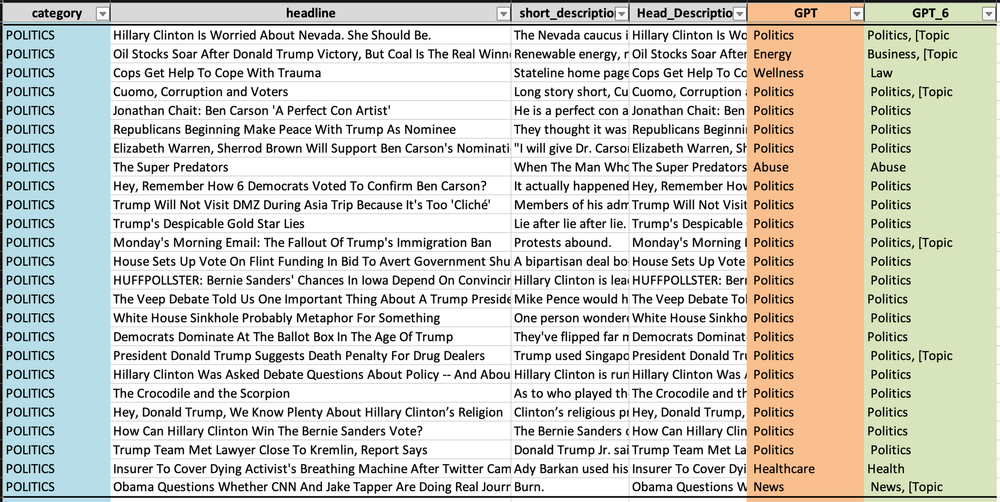
- Politics (政治)
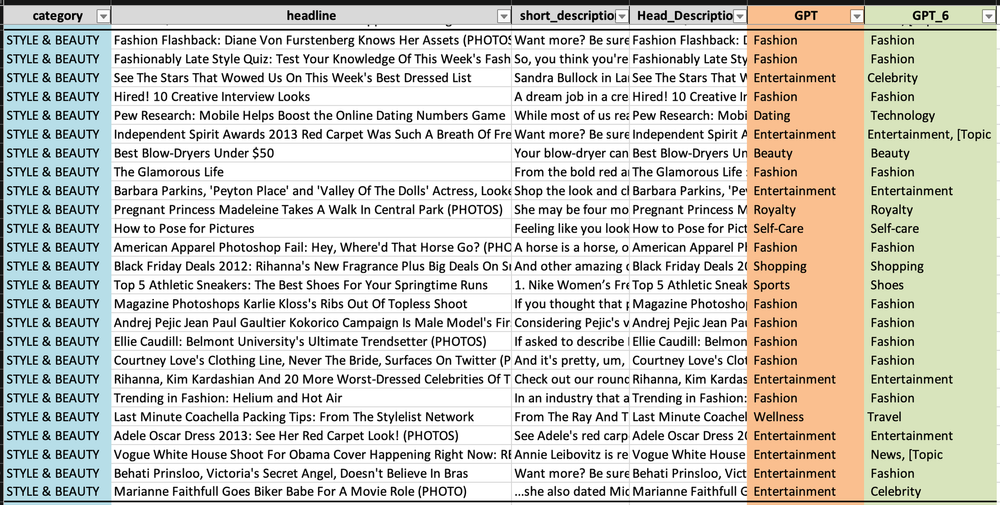
- Style & Beauty (スタイル&美容)
- Travel (旅行)

- Wellness (ウェルネス)

LLMを利用した分析結果
「GPT」列に基づいてまとめると、
- Entertainment (エンターテインメント): 実際のカテゴリでは25件中18件が正しく「エンターテイメント」と予測されました。音楽、法律、健康など他のカテゴリの予測もありますが、数は少ないです。
- Parenting (子育て): 実際のカテゴリでは25件中10件が正しく予測されました。教育、健康、食品など、他の様々な予測もあります。
- Politics (政治): 実際のカテゴリでは25件中21件が正しく予測されました。予測結果の精度が最も高いです。
- Style & Beauty (スタイル&美容): ファッション、美容、エンターテイメントなど様々なカテゴリの予測が混在していますが、「スタイル&美容」と類似のカテゴリーであるファッションを合わせると、最も高い頻度で10件以上を占めています。
- Travel (旅行): 実際のカテゴリは「旅行」であり、25件中14件が正しく予測されました。広告やテクノロジなどのカテゴリの予測もあります。
- Wellness (ウェルネス): 実際のカテゴリは25件中16件が正しく予測されました。健康、スピリチュアル、人間関係、科学などのカテゴリの予測もあります。
ChatGPTを使用した結果を分析した結果、2つの大きな利点がありました。
2.個別のテーマ語抽出の手間を減らすことができます。
Transformerの構造を理解する
ChatGPTはどのようなモデル構造を持っているために、このような満足のいく結果を迅速に導き出すことができるのでしょうか?
自然言語処理に精通している方ならご存知の通り、Transformerモデルがその核心です。
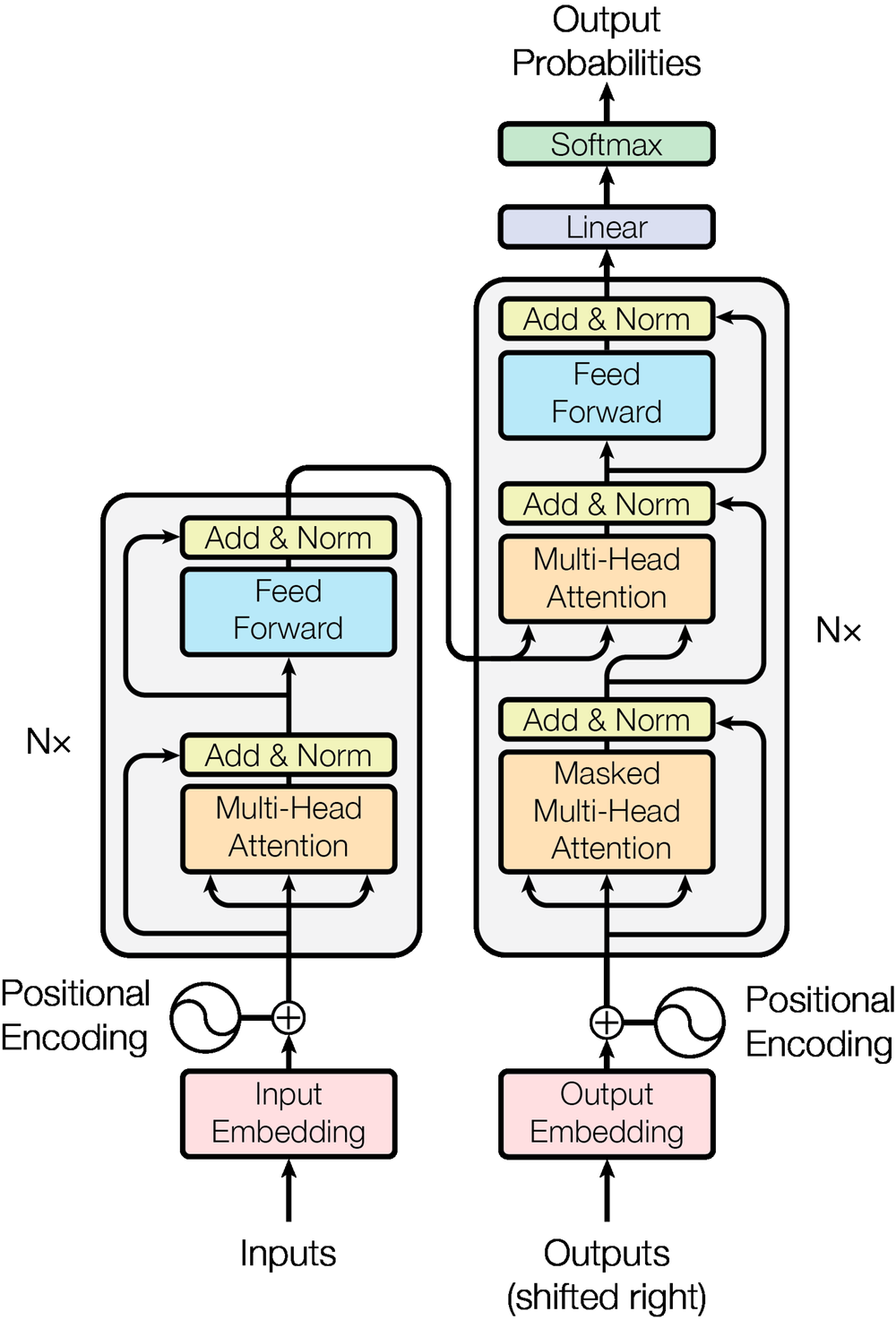
モデル構造が初めての方には複雑に感じられるかもしれません。
すべてを理解しようとするのではなく、この記事をブラックボックスと感じていた人工知能をより身近に理解するための過程として軽く読んでみることをお勧めします。
ChatGPTの構造とテキスト処理プロセス
以下は、ChatGPTの構造とテキストを処理するプロセスについての説明です。
- モデルの基盤である Transformer アーキテクチャ
- Transformerの核心である「注意(Attention)」機構は、私たちが会話を聞く時に重要な部分により集中するのと似ています。モデルは文章の中で特定の単語やフレーズにより多くの「注意」を払い、どの情報がより重要であるかを判断します。「自己注意(Self-Attention)」は、注意の一つの形態で、モデルが文章中の各単語がどのように接続されているかを理解することを可能にします。例えば、「The cat sat on the mat」という文章では、「cat」と「sat」の関係を把握するようなものです。
- Transformerは一般的にエンコーダとデコーダで構成されています。エンコーダは入力された文を処理して理解する役割を果たし、デコーダはこの情報を基に新しい文を生成します。各エンコーダとデコーダは複数の「レイヤー」で構成されており、各レイヤーは Attention とその出力に同じ重みを適用するなど、異なる演算を実行する全結合層(Fully Connected Layer) で構成されています。
- Transformerは、単語が文中のどこに位置するかを直接知ることができないため、「位置エンコーディング(Positional Encoding)」を使用して各単語の位置情報を追加します。これは、各単語の順序と位置が文の意味を理解するために重要であるためです。
- 各レイヤーの出力は「レイヤーの正規化(Layer Normalization)」により正規化され、これはデータを安定した範囲内で処理するのに役立ちます。「残留接続(Residual Connections)」は、入力を各レイヤーの出力に直接加算する構造で、深いネットワークでも情報が失われることなく効果的に伝達されます。
- 最終出力は最初に線形変換を行った後、「Softmax」関数が適用され、各トークンのスコアを確率分布に変換します。このプロセスが連続的に繰り返されることで、文全体を順次完成させます。
- 大規模なデータセットでの事前学習
- ChatGPTは、書籍、Webサイト、ニュース記事など様々なソースから収集された膨大な量のテキストデータを使用して学習します。このような広範な学習プロセスにより、モデルは文法、文脈、様々なトピックに関する知識を習得します。
- ファインチューニングと調整
- 一般的な事前学習の後、モデルは特定のタスク(例えば、質問への回答、テキスト生成など)に合わせてさらに調整されます。また、RLHF (Reinforcement Learning from Human Feedback)方式により、人間のフィードバックに基づいてさらに追加学習を行い、モデルのパフォーマンスを向上させます。
- テキスト処理と応答の生成
- ユーザーからの入力を受けたモデルはこれを分析し、適切な応答を生成するために様々な計算を内部で行います。この時、モデルは事前学習とファインチューニングを通じて習得した知識を活用して応答を生成します。
LLMの効率と限界
精巧に構成された ChatGPT を知れば知るほど、より頼りたくなりませんか?
上記の「News Category Dataset」に対するテキスト分析結果から分かるように、LLMの使用は、従来の統計的なモデリングアプローチに比べて効率の面で優れた利点を示しています。
K-meansはある程度のデータ前処理とモデリングプロセスを必要としますが、ChatGPTは即座に直感的な結果を提供します。
OpenAI の ChatGPT、Google の Gemini などの生成的人工知能(Generative AI)が進化し続け、パフォーマンスが向上するにつれて、このギャップはさらに拡大することが予想されます。
しかし、この高度な言語処理能力を持つAIを肯定的にのみ捉えていいのでしょうか?
光のあるところに必ず闇があるものです。
ChatGPTにその限界について直接質問したところ、次のような答えが返ってきました。


したがって、ChatGPTの無分別な使用と過度の依存は避けなければなりません。
AIを使用する際、文化的、倫理的な感受性に対する理解がまだ十分ではなく、誤った情報に対する責任所在が明確ではないことを認識する必要があります。プロセスを省略して結果のみを追求する傾向は、批判的思考と問題解決能力を低下させ、独立した思考と創造性の発達に障害となる可能性があります。
GPT-4はリリース時にトークン数が128,000まで増えましたが、それでも入力トークンの制限が存在することを認識する必要があります(LangChain、RAGを使用するなどの間接的な解決方法が存在します)。

ChatGPTは迅速で便利な結果を提供しますが、AIのみに頼ることは危険であり、モデルに対する制御を失う可能性があることに注意する必要があります。データアナリスト、エンジニア、科学者は、ChatGPTをデータ関連の作業に使用する際には、責任を持って使用することが重要です。
また、正確な問題定義の重要性がさらに強調されています。分析と開発で求められる能力が、単純なプログラミングスキルから効果的な質問や明確な指示に移行していることは否定できません。
おわりに
もちろん、10年後、5年後、まして1年後にはまたどのように変わっているかわかりません。
技術の発展に対する警戒心を維持することは重要ですが、同時に変化と発展に対する期待感を持つことは、この時代を生きていくために必要不可欠です。
HEARTCOUNTは、ChatGPTのようなAI技術を活用して新たなチャンスを模索する旅に皆さんと共に歩んでいきます。