集計値(平均)ではなく、個々のレコードレベルで分析する必要がある理由
残念ながら、私たちは個々のレコードレベルの視覚化に慣れていません。棒グラフ、折れ線グラフなど、データを平均や合計で要約・集計して表示するダッシュボードチャートに慣れすぎてしまったからです。
平均の理解を超えて
平均、合計などの集計値のみで分析/視覚化することが危険な理由は、外れ値(outlier)などのデータの分布の形状や個別データの特殊性が埋もれてしまうためです。例えば、1つまたは2つの異常値(大部分の値の範囲から外れて極端に大きかったり小さかったりする値)が全体の平均値を歪める可能性があり、このような異常値は個々のレコードレベルの視覚化によってのみ確認が可能です。
不確実性を直視する
カテゴリ(部門、商品グループ、日付など)を用いて数字(売上など)を集計せずに、データを個々のレコードレベルで視覚化すると、集計されて抽象化された数字(売上平均、売上合計など)の確定的な感覚がなくなり、必然的に不確実性が現れます。データ分析をするということは、このような不確実性にもかかわらず、何らかの主張をすることです。
平均や合計で集計された抽象化された情報に頼って意思決定を行うことから一歩進んで、データに内在する不確実性の中から実用的なパターンを見つけ、現実に適用する方法を理解し、そのような態度を身につけることが必要です。
今回は、個々のレコードを視覚化する代表的な方法である分布と散布図(scatter plot)を見てみましょう。
以下の内容を直接確認するには、HEARTCOUNTにログイン → キャンペーン生成 → サンプルデータ → 「Employee (HR) Dataset」を選択してください。
分布の視覚化の実習
(1) カテゴリ間の違いは意味がありますか? 比較してみる
まず、HEARTCOUNTのスマートプロットのメニューから、以下の動画を参考にしながら一緒にやってみましょう。
平均の比較: 右上の棒グラフのアイコンと「Team (チーム区分)」の横の並べ替えアイコンを順番にクリックして、「Engagement_Score (従業員満足度)」の平均が高いチーム順に棒グラフを並べ替えてみましょう。
箱ひげ図(ボックスプロット)による分布形状の比較: チーム内の個々の観測値の分布の形状を見てみましょう。右上の箱ひげ図(左から2番目)のアイコンを選択して、分布(チーム内の従業員満足度スコアの広がり具合)を見てみましょう。個々のチーム内で満足度スコアがより広く、もしくは狭く分布しているか、中央値から大きく離れた外れ値(outlier)があるかどうかを確認することができます。
データの5つの代表値を箱で表したグラフで、最小値、最大値、第1~3四分位数を確認することができます。最小値と最大値を超える位置にある値を外れ値(Outlier)として認識されます。
- 平均の信頼区間の比較: 今回は、チーム間の従業員満足度の差が有意かどうか(偶然ではなく本質的な差)を見てみましょう。上の動画で確認できるように、[スマートプロット] - [X軸にカテゴリー型変数] - [右上の6つのグラフタイプのアイコンのうち左から3番目のアイコンをクリック] すると、チーム別平均値の95%信頼区間が表示されます。
上記の例では、従業員満足度平均の95%信頼区間が互いに重ならない場合、グループ間に統計的に有意な差(差が偶然ではなく、実際に存在する)があると言えます。一番 右端の「Tech Support」チームの場合、他のどのチームと比較しても統計的に有意に低い満足度を示すことが確認できます。
95%信頼区間の数学的定義は、私たちが常識的に理解している概念(標本ではなく、母集団の平均値がその信頼区間内に存在する確率が95%)とは少し異なります。実際のまたは仮想の集団(全従業員)から同じ方法で100回標本を抽出して求めた100個の信頼区間のうち95個程度が母平均を含むという意味です。(私が今見ている信頼区間が母集団の平均を含まない確率が5%!)
現実のデータは標本(サンプル)ではなく、全体データであることが多いです。従業員データも全体から抽出したサンプルではなく、従業員全体(=母集団)を対象にしている可能性が高いです。この場合、現実に存在しない仮想の母集団を想定して、母集団の平均を含む信頼区間を計算することが有効で妥当なことなのか、考えてみる必要があると思います。実務的な観点からは、該当するグループの信頼区間が比較的広い場合は、「該当のグループ内の観測値の差が比較的大きく、レコード数も少ない」程度に理解すればよいと思います。
(2) 変数間の関係を個々のレコードレベルで視覚化する
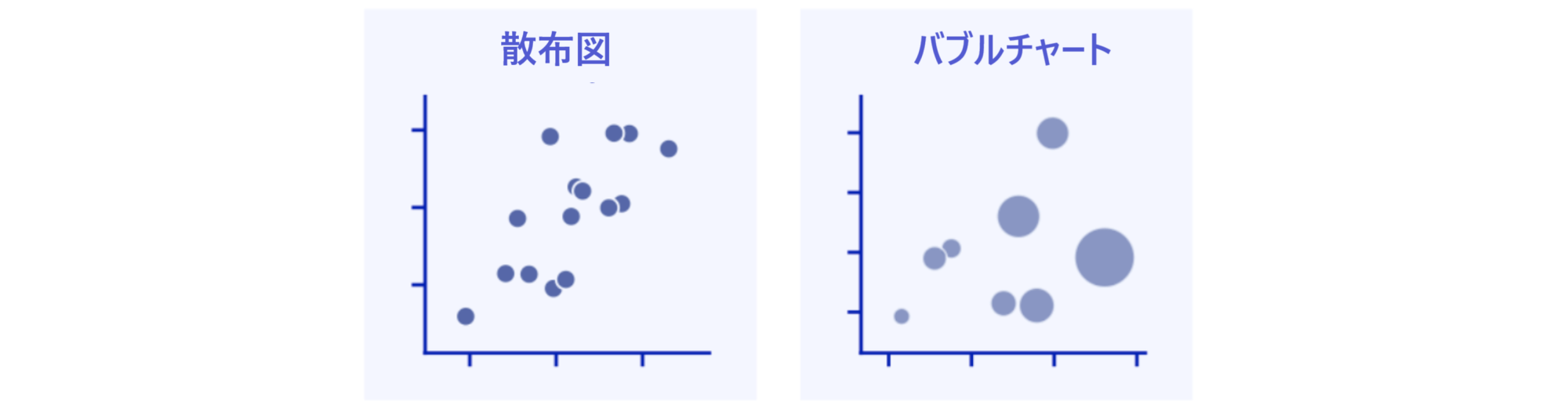
2つの数値型変数間の関係(x-y relationships)を視覚化する方法には、散布図(Scatter plot)とバブルチャート(Bubble chart)の2つがあります。
散布図が個々のレコードが持つ x, y値を図形(通常点)を使用して座標平面上に表示する方法であるのに対し、バブルチャートは個々のレコードを第3のカテゴリー型変数にまとめて異なるサイズ(通常はレコード件数を用いる)を持つ円で表現します。
HEARTCOUNTのスマートプロットのメニューから、同じ従業員(HR)データセット(Employee (HR) Dataset)を使って、バブルチャートと散布図の違いを確認してみましょう。
バブルチャート (Bubble chart)
Y軸に「Engagement_Score (従業員満足度)」、X軸に「Manager_Communication (マネージャーコミュニケーションのスコア)」をそれぞれ選択した後、サブグループに「Team (チーム区分)」を選択すると、個々のチームがバブル(サイズは各チームに属するレコード件数)で表現されます。
チームレベルで平均的な従業員満足度とマネージャーコミュニケーションのスコアが同じ方向に動く関係があることが分かります。(個々のレコードではなく、サブグループとして集計したバブルチャートで相関関係という用語を使うのは適切ではありません)
次に、個々のレコードレベルで2つの変数(X,Y)の関係を見てみましょう。
散布図 (Scatter plot)
「サブグループ: なし」に変更すると、個々のレコードレベルで2つの変数の関係を確認できる散布図が表示されます。
右側の [カラー] の凡例(Legend)で特定のチームを選択すると、そのチームに属する個々のレコードからYとXの変数の間にどの程度の大きさの相関関係があるかを確認することができます。「ファセット: Team」と設定すると、各チームレベルの相関関係を個別ウィンドウを通じて確認することができます。
私たちが実務でデータを視覚化する理由は、Excelやダッシュボードのグラフを通じて慣れ親しんだ平均や合計が示す要約された確定的な、しかし不確かな数字の裏側の世界を見るためであって、よりきれいなグラフを作るためではないと思います。
平均や合計として要約された値の背後には、様々な分布を持つ個々のレコードがあることを覚えておきましょう。個々のレコードレベルの視覚化を通じて、平均/合計の背後に隠された不確実性をきちんと確認し、そのような不確実性があるにもかかわらず、有意義で実用的な差と関係性を発見することは、趣味の分析とそうではない分析を分ける重要な基準です。