前回の記事では、データベースの意思決定が上手くいかない理由について、以下の2点に焦点を当てて説明いたしました。
"A. 使用可能なデータが存在しない。"と "B. 分析結果が意味をなさない。"の2点について、詳しく解説いたしました。
さて、今回はデータベースの意思決定がうまくいかない理由の第三点、「忙しくて難しい」という問題についてお話いたします。
C. 忙しくて難しい
忙しくて大変だからできないというのは、その仕事の優先順位が低いということ。
忙しさや難しさが理由で特定の業務が進まない場合、その業務は重要でないと見なされることが多いです。データ分析が本業ではない現業部門においては、データ分析は業務の優先順位になりにくいのが一般的です。データ分析を「学び、時折実践する」ことは確かに喜ばしい事象ですが、他の重要な業務に忙殺されている状況では、新しい業務をしっかりと遂行する時間が確保できないのが現実です。
データ分析が主業務でない組織では、どのように働くべきか?
解決策として、一部の従業員にデータ分析を正式な業務またはタスクとして割り当てる方法があります。また、より大規模な分析が必要な場合は、専門の分析チームを設置することも一つの選択肢です。
既存の従業員に分析業務を追加で割り当てることは絶対にしてはいけない。
データ分析のためのTF組織図の例
下の図は、HR部門内で人事データ分析を行うPeople Analytics Teamを新設すると仮定した場合、そのチームの役割と他のチームとの関係をまとめたものです。 最初はリソースの30~50%程度を使用する1~2人で構成して運営し、うまくいけばチームを量的、質的に成長させていくのが良いと考えられます。
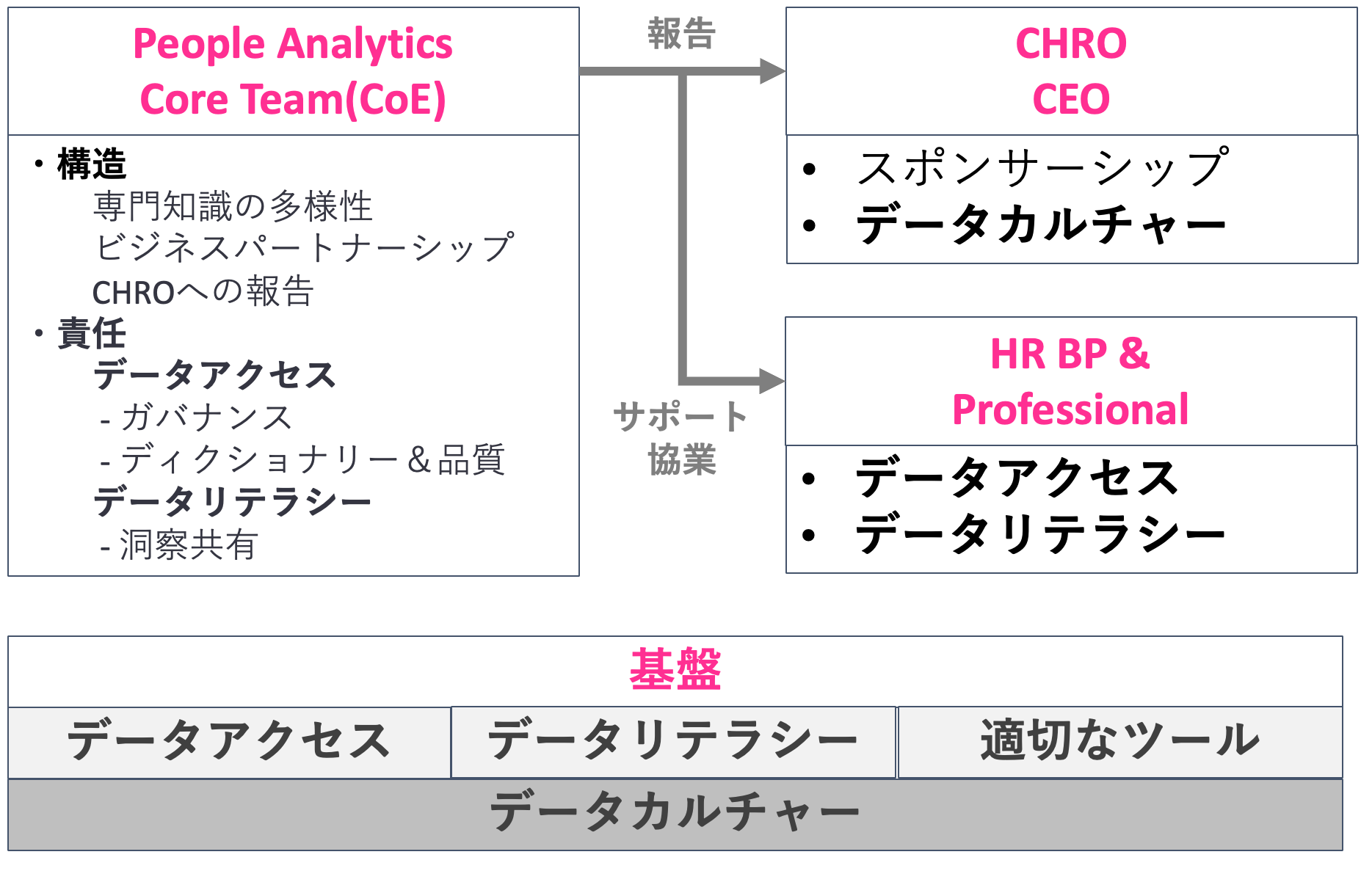
上記のPeople Analytics Core Team(データ分析TFチーム)の主な役割と構造
- データアクセス: 部署内の他のメンバーに最新かつ信頼できるデータを提供するのが、この役割の主な責任です。Data Accessの役割は、次の3つの詳細な役割に分類することができます。
a) データディクショナリー(カタログ):部署内で収集および管理しているデータ(変数)の種類、データのソース(例:勤怠システム、採用システム、HRISなど)、オーナーシップといった情報を管理する役割です。
b) データ品質:データの品質を改善し、維持する役割です。
c) データガバナンス:データ(変数)の機微や重要度に応じて、アクセス権限や活用に関する原則を設定し、それを守る役割です。
上記のData Governanceは、技術的な統制やセキュリティ、またはRegulatory Complianceに関連する政策を策定するものではなく、データ使用に関する透明な原則を設定することにより近い役割です。以下のリンクを参考にしていただければと思います。

- データリテラシー: 意思決定のための分析活動は、社会的な相互作用であると言えます。良い本を読む人がいなければ、良い本を書く人が存在できないように、分析する人(Producer)と分析結果を活用する人(Consumer)は有機的に一緒に存在しなければならないのです。Core Teamは、同僚やマネージャーが分析結果を実用的に活用できるように、データ活用に関する基本的な教育にも一定の責任があります。Core Teamは直接講義をすることも可能ですし、外部のコンテンツをキュレーションしてカリキュラムを組むこともできます。(参考: Airbnbの事例)
- 洞察の共有:分析結果を第一線の担当者や意思決定権者と共有し、実用的に活用されるようにする役割です。概念的には簡単に同意できるような言葉であることが多いですが、実際にはそれが難しいことです。以下の「分析結果が役に立つためには」というセクションで、もう少し具体的な考えを共有します。
- レポーティング構造:分析の独立性を保つためには、CHROや必要に応じてCEOに直接報告することが望ましいです。報告ラインが長くなると、最初に得られたデータや事実に基づいた淡白な報告内容に恣意的な解釈が加わることが多く、結局は「彼が」見たい、聞きたいことを洗練された方法で報告することになり、現実から一歩も進まない場合が多いからです。残念ながら、CHRO直属の組織としてPeople Analyticsチームが運営されている事例は、ほとんどありません。
データ分析とは、データの使い道(有用性)を見つけること
データ分析とは何かと問われた場合、「データの使い道を見つけること」と答えるでしょう。データを通じて、世界や物、人に対する認識はより正確で深まることができます。しかし、企業内のデータ分析の主な目標は、私の認識を豊かにしたり、精緻化することではありません。役に立つということは、ビジネスの問題を解決することです。役に立つ分析が行われれば、組織は物心両面で惜しみない支援をしてくれるでしょう。
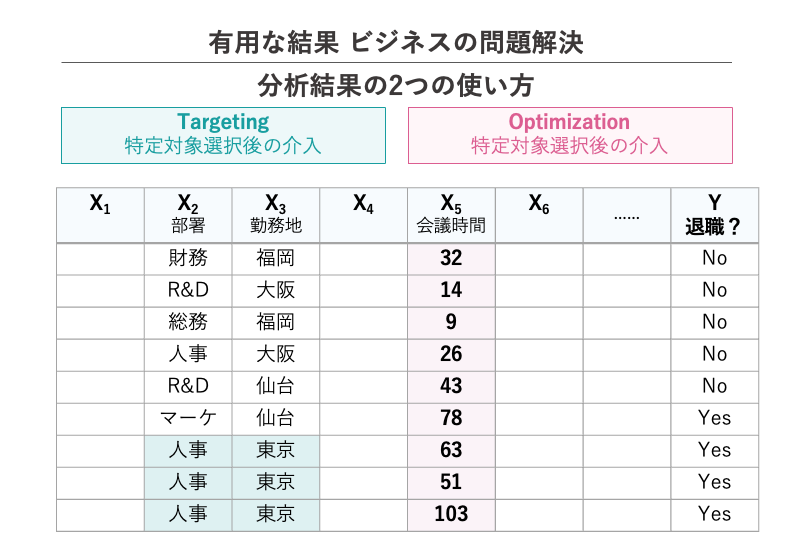
組織に有用なデータ分析を行うには、特定のセグメント(集団)をターゲットにし、最適化方法を見つける必要があります
データベースの意思決定の文脈において、分析結果の有用性は大きく2つに分類されます。
Targeting
特定の行動や特性を示す人(レコード)が密集している集団(セグメント)を見つけることが一つの大きな目的です。例えば、下の表に示されているように、日本で勤務している人事部員の離職率が他の集団に比べて格段に高い場合、そのセグメントをターゲットとして適切な措置を取ることができるでしょう。このように、Targetingが分析の目標である場合、なぜ退職したのか(Why)という点は必ずしも重要ではありません。特定の行動や特性を示した人が密集している集団を見つけることが主な目標です。
Optimization(Intervention)
最適化(介入)は、目標変数(Y)の原因(X)を探し出し、Xに介入してYを改善することが目的です。この場合、XとYの間に因果性(Causality)が必ず必要になります。例えば、下の表において、X(会議時間)とY(離職率)の間に何らかのパターンが見つかった場合、Xに介入することでYを改善することが可能です。
因果関係 vs 相関関係
最近まで、統計やデータ分析を行う人々の間でタブー視されていた言葉が「因果性(Causality)」です。これは、統計学の基礎を築いた先人たちが「因果性を問うのは科学的でない」と教え、相関関係(Correlation)のみを考慮すべきだという立場を取っていたためです。一方で、因果関係を明示的に表現するための普遍的な言語(数学的表記法)がまだ開発されていないことも、この状況に影響を与えています。
先程、会議時間と離職率の間の因果関係について断定的な結論を出しましたが、因果関係に関する詳細は別の記事でご紹介いたします。
Judea Pearl(ジュデア・パール)のような研究者たちは、データから因果性を科学的に見つけ出し、その内容を記述する方法を確立するために多くの努力をしています。
残念ながら、因果性の検証に使われる代表的な方法であるCRT(Controlled Randomization Trial、制御されたランダム化試験)について詳しく知りたい方は、別の資料をご参照いただくことをお勧めします。
 Amy Gallo
Amy Gallo
XとYの間に因果性が存在すると(社会通念上、または別の実験を通じて証明された)仮定した場合、Xに介入してYを改善するためには、さらに2つの条件が必要です。
- Xに介入(Intervention)が可能であること:例えば、認知スコア(X1)が高く、未使用の休暇日数(X2)が少ない人が営業成果(Y)が良いと仮定した場合、X1には人為的に介入することが難しいかもしれません。しかし、X2については意志さえあれば介入が可能です。
- Yの改善を測定(Monitoring)できること:例えば、営業職の方々を対象に、目立たないように自由に休暇を使わせる(X2に介入)と仮定します。その後、営業成果(Y:売上、新規顧客誘致など)が実際に向上したかどうかをモニタリングすることが必要です。もし、Yが相対評価に基づいた成果等級やスコアであった場合、介入によるYの改善度を測定することは難しいでしょう。
データ主導の意思決定 vs データ主導の問題解決
データ分析をより良い意思決定のために行う場合、分析の最終的な目標はビジネスの問題解決であると考えられます。データドリブンの意思決定は、問題解決の手段や方法であって、それ自体が目標ではありません。もし問題解決が一つもされないまま、ひたすらデータに基づいて意思決定を行うだけであれば、最終的には自分自身が一番苦労することになるでしょう。
改善や最適化が必要な指標やKPIがない組織はほぼ存在しないでしょう。したがって、分析対象のデータから目標変数(Y)を見つけるのは、一般的には難しいケースは稀です。また、なぜ(Why)ではなく、誰(Who)をターゲットとするかを探る「ターゲティング分析」においても、入力変数(X)を組み合わせてターゲティングする対象を探すのは特に難しくありません。
確かに、既に保有しているデータから目標変数(Y)の原因であり、かつ介入も可能な入力変数(X)を見つけるのは非常に難しい課題です。特定の分析プロジェクトでの目標が、介入可能な原因変数を見つけることである場合、分析を始める前に、既存のデータにそのような変数が存在するかどうかを最初に確認することが重要です。もし存在しない場合には、アンケートや実験を通じてそのデータを補完する手段も考えられます。
「データ!データ!データ!」と彼は焦った。
「粘土がなければレンガは作れない。」