
ChatGPTやGeminiのように命令を正確に理解して実行する生成系AIの性能が向上し、意図に応じてタスクをこなすAIエージェントが数多く登場する中で、まるで魔法のように仕事を代わりにやってくれるAIへの幻想や期待が高まっています。
実際に、ある程度完璧にこなせる仕事もありますよね。では、データ分析の分野でも、AIデータ分析はAIさえ優れていればうまくいくのでしょうか?

AIから有用なインサイトを引き出すためには、学習・分析するための「データ」が適切に構造化されている必要があり、そのデータをきちんと理解したユーザーが投げる「質問」も明確でなければなりません。
結局のところ、データ分析の基本を理解してこそ、AIを活用することで得られる効果や達成感を実感できるのです。これは、部下が業務指示を的確に遂行するためには、上司が仕事を把握し、適切なガイドラインを示し、フィードバックする必要があるのと同じです。
本記事では、データをどう理解し、どう構造化し、どのように分析に活用できるのかといった基本的な概念をわかりやすく解説します。この記事を通じて、自分が持っているデータはどんな種類なのか、何ができるのか、どのようなアウトプットを期待してAIデータ分析を始めるべきか、そのヒントをぜひ見つけてみてください :)
データ分析の始まり:目的と全体の流れを理解する
データ分析、なぜ行うのでしょうか?それは「YをXで説明するため」です!
「それで、なぜデータ分析をしなければならないのですか?」と聞かれたら、大きく2つの答えがあります。
- 気になる現象(Y)をデータ(X)でよりよく説明したり予測したりするため
例:どの顧客が私たちの商品をより多く購入するのか?
[Y:購入量、X:顧客の特性] - 説明変数(X)を変えることで、結果変数(Y)を改善するため
例:どんなプロモーションをすれば売上が上がるのか?
[Y:売上額、X:プロモーションの種類]
Excel、データ可視化ツール、統計、機械学習(ML)などのツールは、すべてこの2つの目的のために存在しています。
データ分析、どうやって始めればいいのでしょうか?
一般的に、データは「収集 → 状態の記述(記述)→ 隠れたパターンの発見 → 未来の予測 → 実際の活用」という段階を経て進んでいきます。
このプロセスで用いられる主な分析手法は以下の通りです。
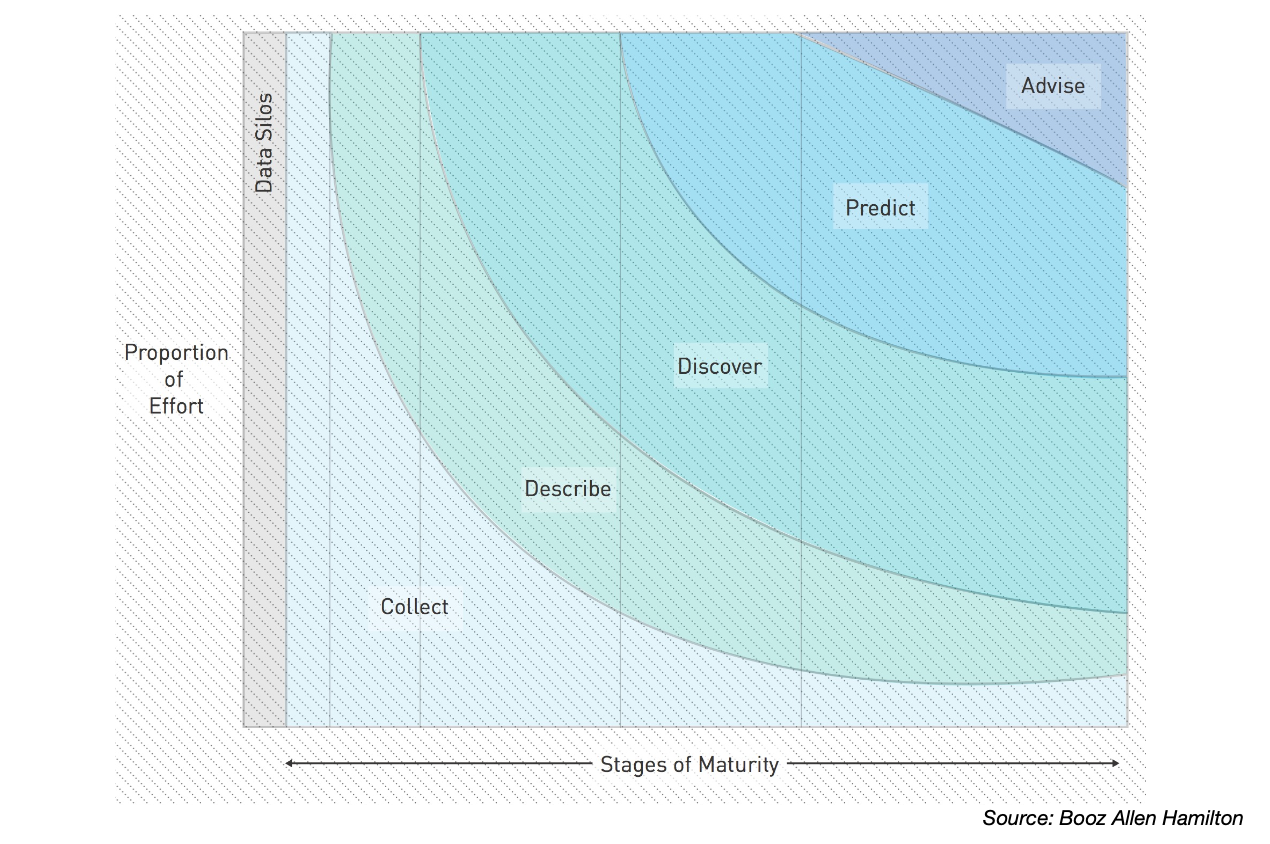
- 記述的分析(Descriptive Analytics)
「それで、何がわかったの?」
データの現在の状態や特徴を要約する分析です。Excelのようなツールで最もよく行われる基本的な分析で、「記述分析」とも呼ばれます。
- 探索的データ分析(EDA - Exploratory Data Analysis)
「え?これはどうしてこうなってるの?」
データを隅々まで掘り下げて、疑問を投げかけながらパターンを探していくプロセスです。データの可視化に近い作業です。
- 予測・推論的分析(Predictive/Inferential Analytics)
「これからどうなるんだろう?」
見つけたパターンを使って未来を予測したり、全体の傾向を推測したりします。統計や機械学習が活用される段階です。
難しい技術を使うことが最良の分析とは限りません。高度な技術を追い求めるのではなく、「いまの自分の問い」に合った分析をすることが大切です。
データにはどんな種類があるのでしょうか?
構造化データ VS 非構造化データ
データを理解する最も基本的な方法のひとつは、「構造化されているかどうか」で分類することです。
整然とした表形式で構成された「構造化データ」と、形式が定まっていない「非構造化データ」に大きく分けることができます。
| 区分 | 構造化データ(Structured Data) | 非構造化データ(Unstructured Data) |
|---|---|---|
| 形式 | 列(column)と行(row)が明確に定義された表形式 | 固定された形式のない自由な形(テキスト、画像、音声など) |
| 例 | Excelシート、SQLテーブル、CRM顧客リスト | メール本文、レビュー文、コールセンター録音、画像、動画 |
| 保存方法 | リレーショナルDB、CSV、スプレッドシート | ファイルシステム、NoSQL、クラウドストレージなど |
| 分析のしやすさ | 比較的分析が簡単(統計、SQL、BIツールなどが利用可能) | 分析が複雑(自然言語処理、画像認識、音声認識技術が必要) |
| 適用技術 | SQL、統計分析、可視化ツール | NLP、コンピュータビジョン、ディープラーニングなどの高度技術 |
この記事では、HEARTCOUNTのようなデータ分析ツールが主に対象としている「構造化データ」について説明します。
このあと紹介する数値型/カテゴリ型データ、分析に適したデータ(Tidy Data)、変数(Variable)や観測値(Observation)といった概念も、主にこの構造化データを前提としている点にご留意ください。
数値型(Quantitative)とカテゴリ型(Qualitative)
先ほど「構造化データ」(表のように整理されたデータ)を紹介しましたが、
「数値型/カテゴリ型データ」とは、その構造化データの各列(変数)がどのような種類の値(数値、文字など)を持つのかを説明する、より細かい“データタイプ”のことです。
構造化データという大きな枠の中で、属性の詳細を分類して見る方法です。
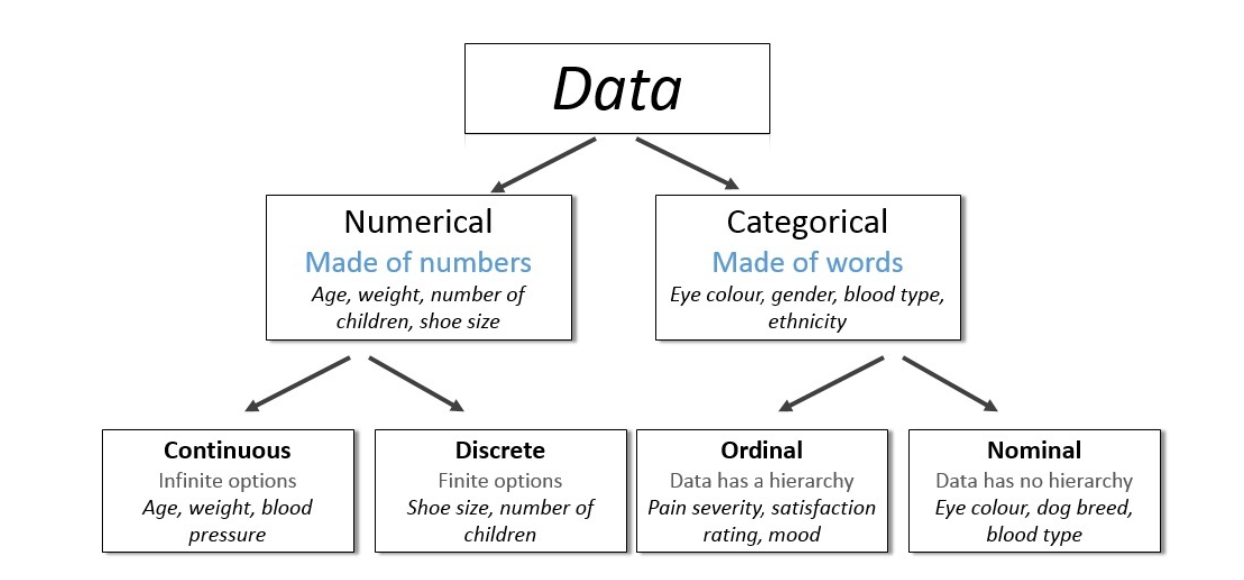
数値型データ(Quantitative Data)
- 離散型(Discrete):値がパキッと区切られており、主に整数です。
例:購入した商品の個数、家族の人数 - 連続型(Continuous):値が連続的につながっており、小数も含まれます。
例:身長、体重、温度、血圧
カテゴリ型データ(Qualitative / Categorical Data)
- 名義型(Nominal):順序のないラベル的なカテゴリ。
例:性別(男/女)、血液型(A/B/O/AB)、好きな色 - 順序型(Ordinal):意味のある順番や等級があるカテゴリ。
例:満足度(高/中/低)、成績(A/B/C)、服のサイズ(S/M/L)
データのタイプによって、使うべき分析手法やグラフの種類が異なるため、タイプを正しく理解することは非常に重要です。
変数の種類を正確に区別できれば、データ分析に必要な適切な要約方法や比較方法をより簡単に選ぶことができます。
分析しやすいデータ:整ったデータ(Tidy Data)の条件
どれだけ大量のデータがあっても、分析しづらい状態であればインサイトを得ることはできません。
分析しやすいデータは「整ったデータ(Tidy Dataset)」と呼ばれ、重要なポイントは次の2つだけです。
- 各変数(Variable)は列(Column)に該当します。
- 私たちが測定または観察する属性のことです。
- 分析の対象(Y, ターゲット、従属変数)になったり、説明のための材料(X, 特徴量、独立変数)になったりします。
- 例としては、年齢、性別、購入金額などが挙げられます。
- 各観測値(Observation)は行(Row)に該当します。
- 個別のデータ項目1つひとつを意味します。
- たとえば「顧客1人」「製品1点」「取引1件」などが該当します。
- 「レコード」「サンプル」と呼ばれることもあります。
このような構造になっていることで、AIデータ分析ツールがデータを正しく理解し、分析を行うことができます。
生データ vs. 集計データ、どちらを使うべき?
- 生データ(Raw Data)
加工されていない、ありのままのデータです。
掘り下げれば掘り下げるほど、新しい問いへの答えを見つけることができます。
- 集計データ(Aggregated Data)
元のデータを特定の基準でまとめたり、平均を取ったりして要約されたデータです。特定の問い(例:2001年の男女別の購買比率は?)にはすぐに答えられます。
ただし、一度集計されると元に戻すのが難しく、別の質問には対応しづらくなります。
そのため、より多様な分析結果を得るには、基本的には生データから分析を始めるのが望ましいです。
EDA(探索的データ分析)でデータを理解する
EDA(探索的データ分析)は、先に述べた記述的分析と探索的分析の両方を含む概念であり、データを深く理解するための最初かつ最も重要なプロセスです。
EDAで必ず確認すべきポイント
- データ構造の把握(Inspect data structure):どんな情報が含まれているか?
- データ品質の確認(Data quality):欠損値や異常値はないか?
- 主要指標の要約(Summarize):平均値は?データはどこに集中しているか?
- 可視化によるパターン発見(Visualize data):グラフにしてみると何か見えてくるか?
- 仮説の立案(Hypothesis generation):「もしかしてこうじゃない?」という問いを立てる
「うわ、これ完全に手作業じゃん……」と思うほど手間のかかるステップですが、
このようなEDAプロセスをHEARTCOUNTのようなAIデータ分析ツールが自動化してくれることで、大きな助けになります。
データの記述(Descriptive Data Analysis):3つの視点
EDAの重要な要素である「データの記述」は、データをありのままに説明する方法です。
大きく以下の3つの観点で見ることができます。
1. 要約(Description)
変数1つについて、代表値(平均、中央値など)や値のばらつき(分布)を確認します。
例:「うちの顧客の平均年齢は35歳で、30代が一番多いな」といった気づき。
2. 比較(Comparison)
グループ(X)ごとに、値(Y)がどう異なるかを比較します。
例:「男性顧客よりも女性顧客の平均購入金額が高いね」など。
3. 関係(Relationship)
ある変数(Y)が変化したときに、別の変数(X)とどのように関連しているかを見ます。
例:「広告費(X)を増やしたら、訪問者数(Y)も増えたね」といった関係性の把握。
特徴量(Feature)と特徴量エンジニアリング(Feature Engineering)

- 特徴量(Feature)
特徴量とは、予測したい結果(Y:ターゲット)を説明したり予測したりするために使う入力変数(X)のことです。
良い特徴量を見つけることが、分析の成否を大きく左右すると言っても過言ではありません。
たとえば果物を分類する場合、リンゴとオレンジを「種の数」や「熟し具合」で分けるより、「色」や「重さ」で分けたほうが精度が高いのは想像しやすいですよね。
- 徴量エンジニアリング(Feature Engineering)
特徴量エンジニアリングとは、既存の変数をそのまま使うのではなく、分割したり、組み合わせたり、計算したりして、より効果的な新しい特徴量を作り出すプロセスです。
たとえば、糖尿病リスクを予測する場合、単に「身長」と「体重」を使うよりも、この2つを組み合わせた BMI(体格指数、Quetelet Index) を使うほうが予測精度が高まる可能性があります。
さあ、いよいよ自分でデータ分析を始めてみましょう!
今日ご紹介した概念をしっかり覚えておけば、どんなデータに出会っても落ち着いて一歩ずつ探索を進めていけるはずです :)
AIに作業を任せるときも、より具体的で的確な指示が出せるようになります。
「これ、自分のデータで試してみたいな」と思った方は、ぜひHEARTCOUNTを使って、今日学んだデータ探索を実際にやってみてください。
実際に手を動かしてみると、「ああ、こういうことか!」と実感できるはずです。
あわせて読みたい記事
 sunhwa jung
sunhwa jung sidney yang
sidney yang sidney yang
sidney yang

