
前書き
全部読むのが面倒な文章を要約したり、内容が乏しい文章を長くしたりする用途でChatGPTが活用されているのが現実です。企業がそれにお金を払うには少し物足りません。だからこそ、AIエージェントが活発に議論されているのです。

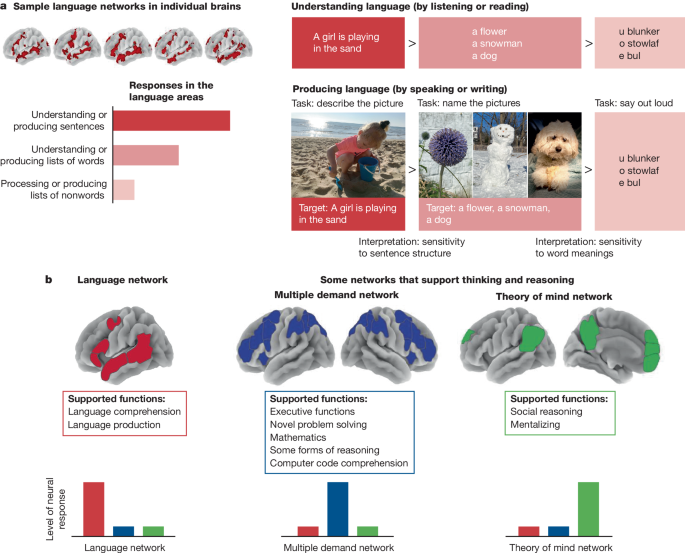
以下の図は、人間の脳の進化過程を通じてAIの未来について語る「A Brief History of Intelligence」という本から引用した図です。

私がこの図を通じて共有したい著者のメッセージは、「言語能力と知能は密接に関連しているが、同じ概念ではない」ということです。言語能力は主に脳の特定の領域(左側の新皮質にあるブローカ野とウェルニッケ野)が担当しており、これらの領域が損傷すると言語の生成や理解に問題が生じる可能性がありますが、その他の知的機能は正常に維持されることもあるそうです。
知能は、言語の理解や生成能力だけでなく、問題解決能力、推論と抽象化、記憶(エピソード記憶)など、さまざまな認知機能を含む包括的な概念です。
AIエージェントも結局のところ、LLMの既存の言語理解と生成能力に追加の能力(計画と推論)を加え、外部ツール(メモリや検索など)と組み合わせることで、より有用なツール(より速い結果や新しい結果)を作ろうとする試みだと考えられます。
人間の言語と脳:ブローカとウェルニッケの発見
以下は、『A Brief History of Intelligence』の「Language in the Brain」章から抜粋した内容を、ChatGPTで翻訳したものです。
- ブローカ野と言語産生
1830年、フランス人のルイ・ヴィクトール・ルボルヌは、話すことができなくなったが、知的能力は正常だった。彼はただ一言、「タン(tan)」しか繰り返せず、後に「タン」というあだ名で呼ばれるようになった。20年後、神経学者のポール・ブローカが彼の脳を解剖したところ、左前頭葉の特定の部位に損傷があることを発見した。ブローカは、言語を司る特定の脳領域があると仮定し、同様の患者を研究した結果、この領域が言語産生を担うことを証明した。この部位は今日「ブローカ野」と呼ばれ、損傷すると話すことができなくなるブローカ失語が発生する。 - ウェルニッケ野と言語理解
ブローカの研究の後、ドイツの医師カール・ウェルニッケは、正反対の症状を示す患者を発見した。彼らは流暢に話すことはできたが、文章の意味がまったく成り立っていなかった。例えば、「スムードル・フィンカードが必要だから、世話をしてあげたい」といった意味不明な発話が見られた。ウェルニッケは、これらの患者の脳を調べ、左後方の新皮質に損傷があることを確認した。その後、この部位は「ウェルニッケ野」と名付けられ、損傷すると言語理解が困難になるウェルニッケ失語が発生することが分かった。 - 言語の普遍的機能と独立性
ブローカ野とウェルニッケ野は、特定の言語形式(話し言葉、書き言葉、手話など)に限定されず、言語そのものを処理する。例えば、ブローカ野が損傷した聴覚障害者は、手話を流暢に使えなくなり、ウェルニッケ野が損傷すると、音声だけでなく文字の理解もできなくなる。つまり、人間の言語は特定の脳領域によって処理され、知能全体とは別に機能することが分かる。 - 人間と類人猿の違い
人間は喉頭や声帯の動きを直接制御できる独特な神経構造を持っているが、それが言語を可能にした決定的な要因ではない。人間は音声だけでなく、手話のような非音声的な手段でも言語を習得できるためである。つまり、言語は単なる身体的適応ではなく、特定の脳機能の結果である。 - 言語は脳の独立した機能
ブローカとウェルニッケの研究により、言語は左新皮質の特定のネットワークによって処理されることが明らかになった。これは、言語能力が他の認知能力とは独立して存在し得ることを示している。例えば、1995年の研究では、重度の知的障害を持つクリストファーという少年が15以上の言語を話せることが確認された。これは、言語が単なる脳容量の増加によるものではなく、進化の過程で独立して発達した機能であることを示唆している。 - まだ終わらない物語
言語の起源は、ブローカ野とウェルニッケ野の発達によるものだと言えるのだろうか? 一見するとそう思えるが、進化のプロセスが単純でないように、言語の起源も単純な問題ではない。人類がどのようにして言語を獲得したのかを完全に解明するには、さらなる研究が必要である。
この論文をダウンロードするには、ここをクリックしてください。
AIエージェントの概念と核心技術
Goldilocks Introduction to AIエージェント
長すぎず短すぎない(Goldilocks)AIエージェントの紹介から始めます。
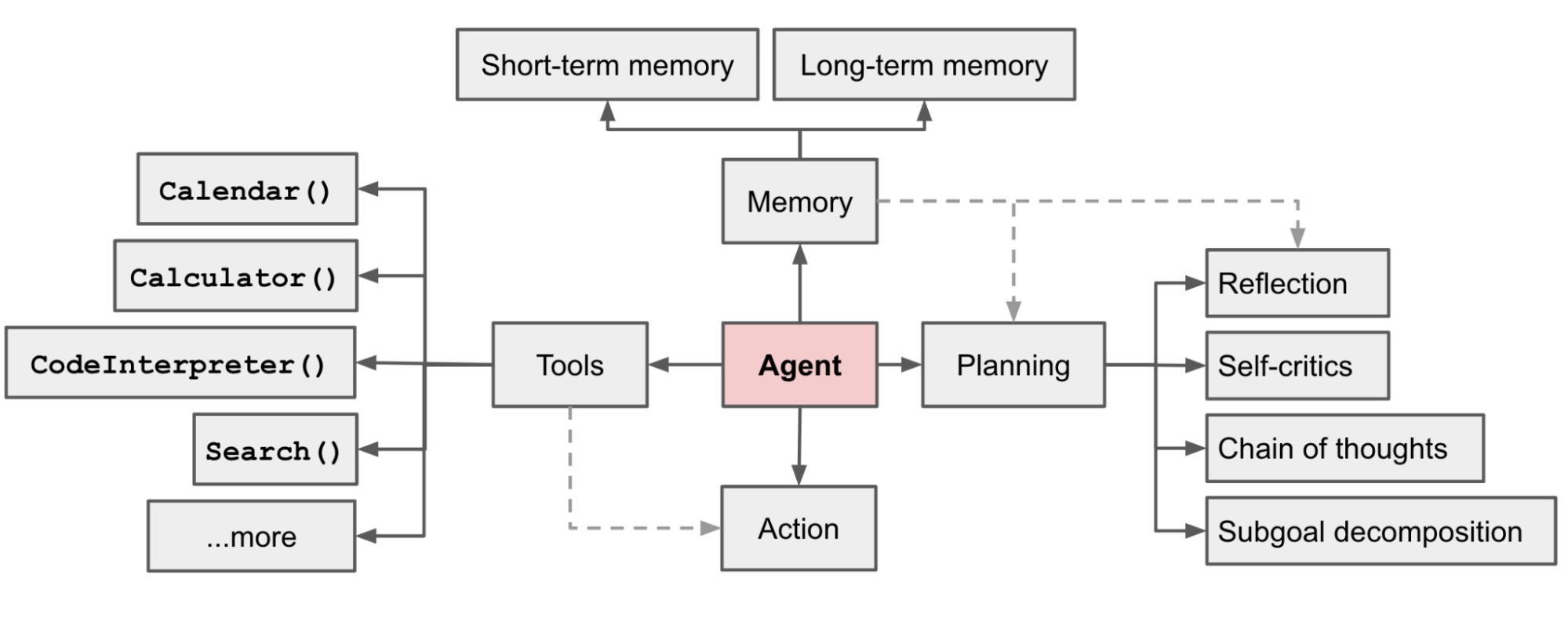
LLMベースの自律型AIエージェントシステムにおいて、LLMは言語や文脈の理解・生成能力に加えて、推論や計画(Planning)能力を備えます。その上で、過去の記憶(Memory)やさまざまなツール(Tool)を活用し、より知的で能動的な行動(Action)を実行できるようになります。
計画(Planning)
- サブゴールの設定: 複雑な問題を、小さく管理しやすいサブゴールに分解する(プロンプト例: 「XYZを達成するためのサブゴールは何か?」)
- 内省(Self-reflection): 過去の行動を自己評価し、反省することで、失敗から学び次のステップで改善する(ReACTプロンプト例: 「Thought: ... Action: ... Observation: ... をN回繰り返す」)
記憶(Memory)
- 短期メモリ(Working Memory): プロンプト内で具体的な指示や例(few-shot/in-context learning)を提供すること
- 長期メモリ(Long-term Memory): 過去のすべての情報を保存(記憶)し、文脈に応じて適切な記憶を取り出すこと

ツールの使用(Tool Use)
未知の情報(モデルの重みに含まれない最新・追加・内部情報)を取得し、コードの実行や外部環境との相互作用を行うためにツールを使用(主にAPI呼び出し)する。
参考)DeepSeekはどのようにReasoningモデルを構築したのか - (この記事を参考にしました。)
以下の引用のように、ベースモデルが十分に優れていれば、人間の(大きな)介入なしでも推論能力を引き出せることをDeepSeek R1が証明しました。
“「R1が示したのは、十分に強力なベースモデルがあれば、人間の監督なしでも強化学習によって言語モデルから推論能力を引き出すことが可能だということです」と、Hugging Faceの科学者であるLewis Tunstall-sanは述べています。”
DeepSeek-R1モデルの基盤となったDeepSeek-R1 Zeroモデルの構築方法を簡単に見てみましょう。
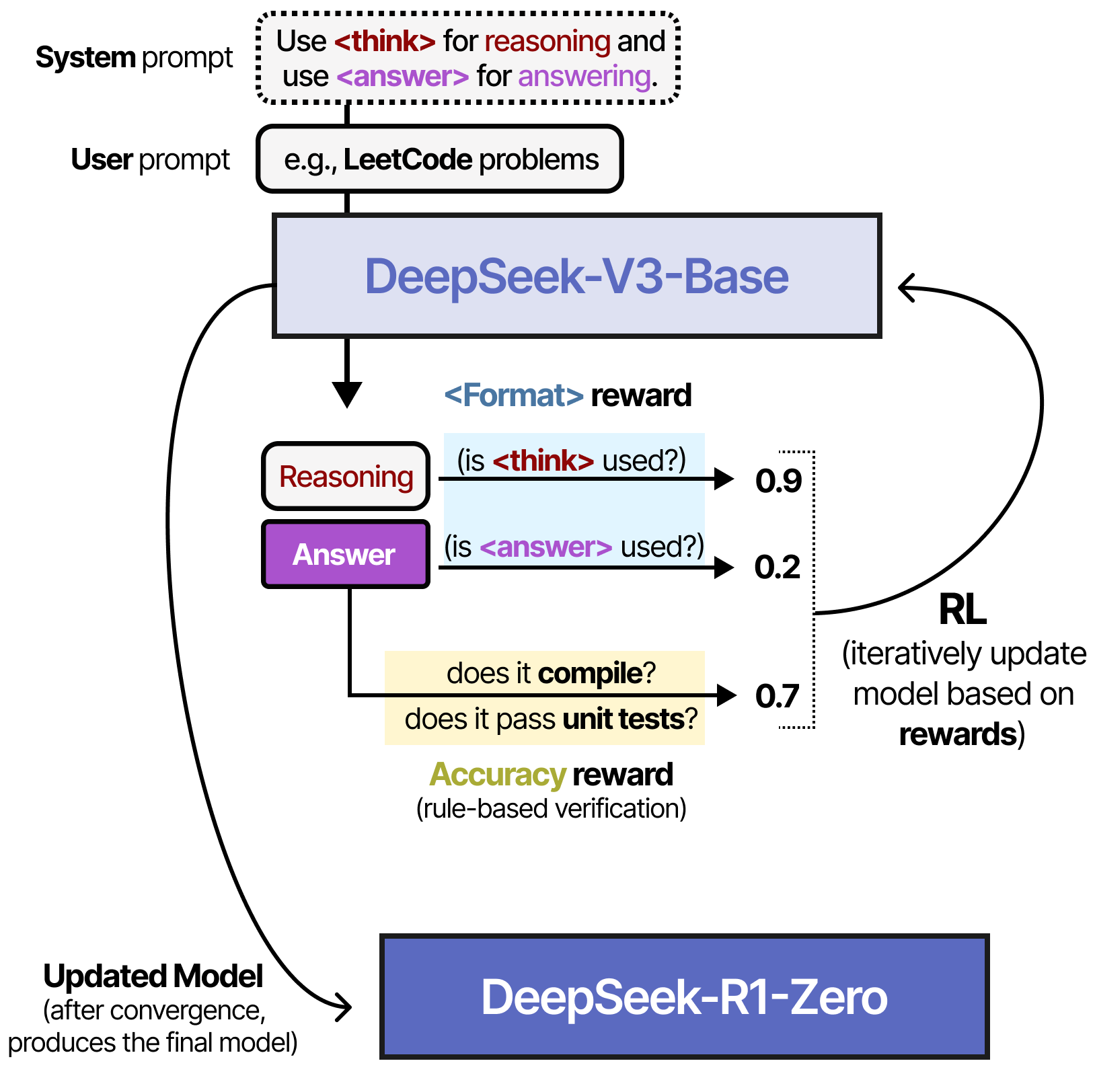
DeepSeek-V3-Baseモデルを基盤とし、大量の推論学習データによるSupervised Fine-Tuningを行う代わりに、強化学習(RL)のみを使用して推論能力を学習させました。
推論モデルの開発に使用された以下のプロンプトを見ると、「推論プロセスを実行する必要がある」とだけ明示されており、実際の推論プロセスがどのように行われるべきかについての具体的な指示は提供されていません。

強化学習のプロセスには、2つのルールベースの報酬システムが導入されました。
- 正確性の報酬(Accuracy Rewards): 正解をテストし、正しい回答を提供すると報酬を与える。
- 形式の報酬(Format Rewards): タグを正しく使用すると追加の報酬を与える。
推論プロセスに関する具体的なガイドや例を与えなくても、単にタグを使用する行動に報酬を与えたところ、モデルが自ら学習し、以下のチャートのように、より複雑で長い推論(Chain-of-Thought)を行うほど正解率が向上することを理解しました。
 David Gu
David Gu
Google AIエージェント白書の紹介
これから、Googleの白書を基にAIエージェントの基本概念と構造を見ていきましょう。
AIエージェントとは?
AIエージェントは、世界を観察し、ツールを活用して世界に介入しながら、特定の目的を達成しようとします。具体的な目的が与えられると、人間の介入なしでも自律的かつ能動的に行動できます。
ある目的を達成するために、世界を観察し、利用可能なツールを使って行動を起こすアプリケーション。エージェントは自律的に動作し、特に適切な目標や目的が与えられた場合、人間の介入なしで独立して行動できる。また、エージェントは目標達成のために積極的に取り組むことも可能である。明確な指示が人間から与えられなくても、エージェントは自ら推論し、最終目標を達成するために次に何をすべきかを判断できる。
エージェントの核心構成要素
以下の図のように、3つの要素で構成されています。
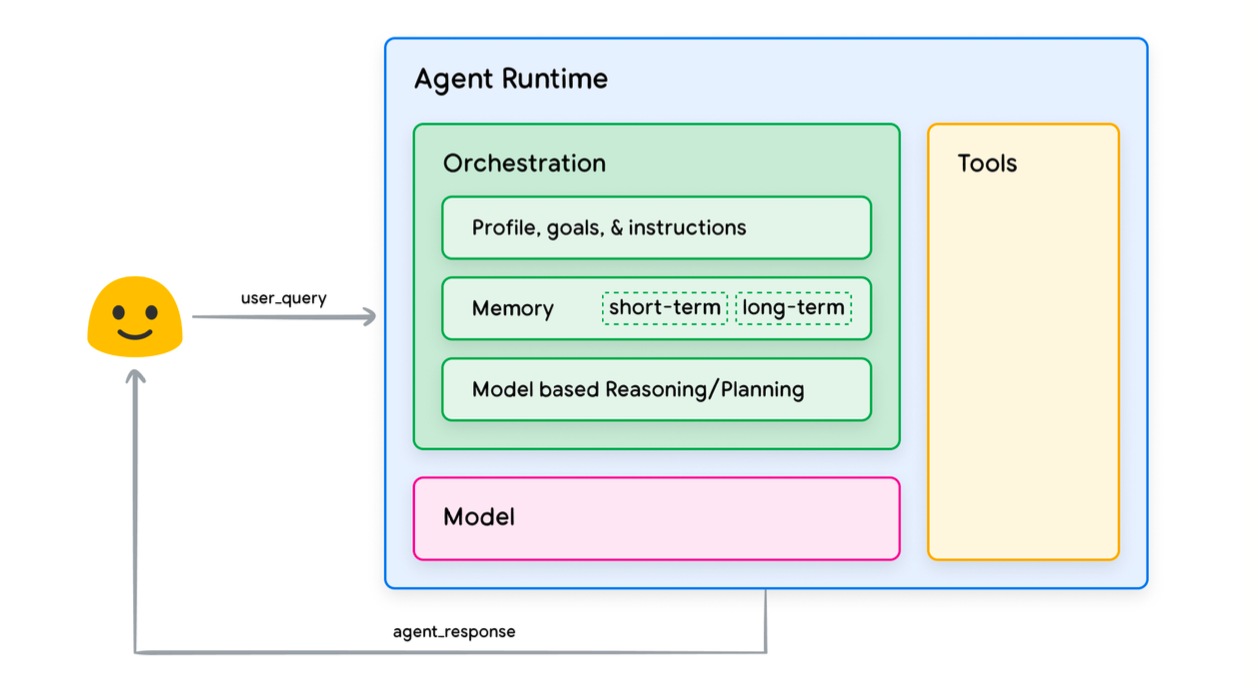
- モデル(Model): 言語モデル(Language Model)として、論理的推論プロセス(ReAct、Chain-of-Thought)を実行し、意思決定を担当する。
- ツール(Tools): API呼び出しを通じて、言語モデルが外部世界(データ、サービスなど)と相互作用できるようにする。
- オーケストレーター(Orchestrator): モデルが推論プロセスとツールを活用し、モデル外の世界と相互作用しながら目的を達成する過程を制御・調整する役割を果たす。
エージェント vs. 言語モデル
以下の表を通じて、言語モデルとエージェントの違いを見てみましょう。
- エージェントは、言語モデルとは異なり、外部システムと連携することで知識を拡張できる。
- エージェントは、セッション内の過去の対話履歴を管理し、多段階(multi-turn)の推論作業が可能。
- エージェントは、外部ツールと連携できる。
- CoTやReActのような推論フレームワークが内蔵されており、ユーザーが直接複雑なプロンプトを作成する必要がない。
エージェントと⾔語モデル(LLM)の違い
| モデル(Models) | エージェント(Agents) |
|---|---|
| トレーニングデータに含まれる知識のみを扱う。 | 外部システムとの接続(ツール)を通じて知識を拡張できる。 |
| ユーザーのクエリに基づいた単一の推論/予測のみ。モデルに明示的な実装がない限り、セッション履歴(チャット履歴)などは管理されない。 | セッション履歴を管理し、マルチターンの推論/予測が可能。やりとりの文脈や判断に基づいて処理を行う。「ターン」とは、1つの入力イベント/クエリと、それに対する1つのエージェント応答を指す。 |
| ネイティブなツールの実装はない。 | ツールはエージェントのアーキテクチャ内にネイティブに統合されている。 |
| ネイティブの論理層は持たない。ユーザーはCoT(Chain of Thought)、ReActなどの推論フレームワークをプロンプトで活用し、複雑な指示を与える必要がある。 | CoT、ReAct、LangChainなどの事前構築されたエージェントフレームワークを活用する、ネイティブな認知アーキテクチャを備えている。 |
推論フレームワーク(Reasoning Framework)
代表的な推論フレームワークである ReAct(Reasoning + Acting) の動作方式を見てみましょう。
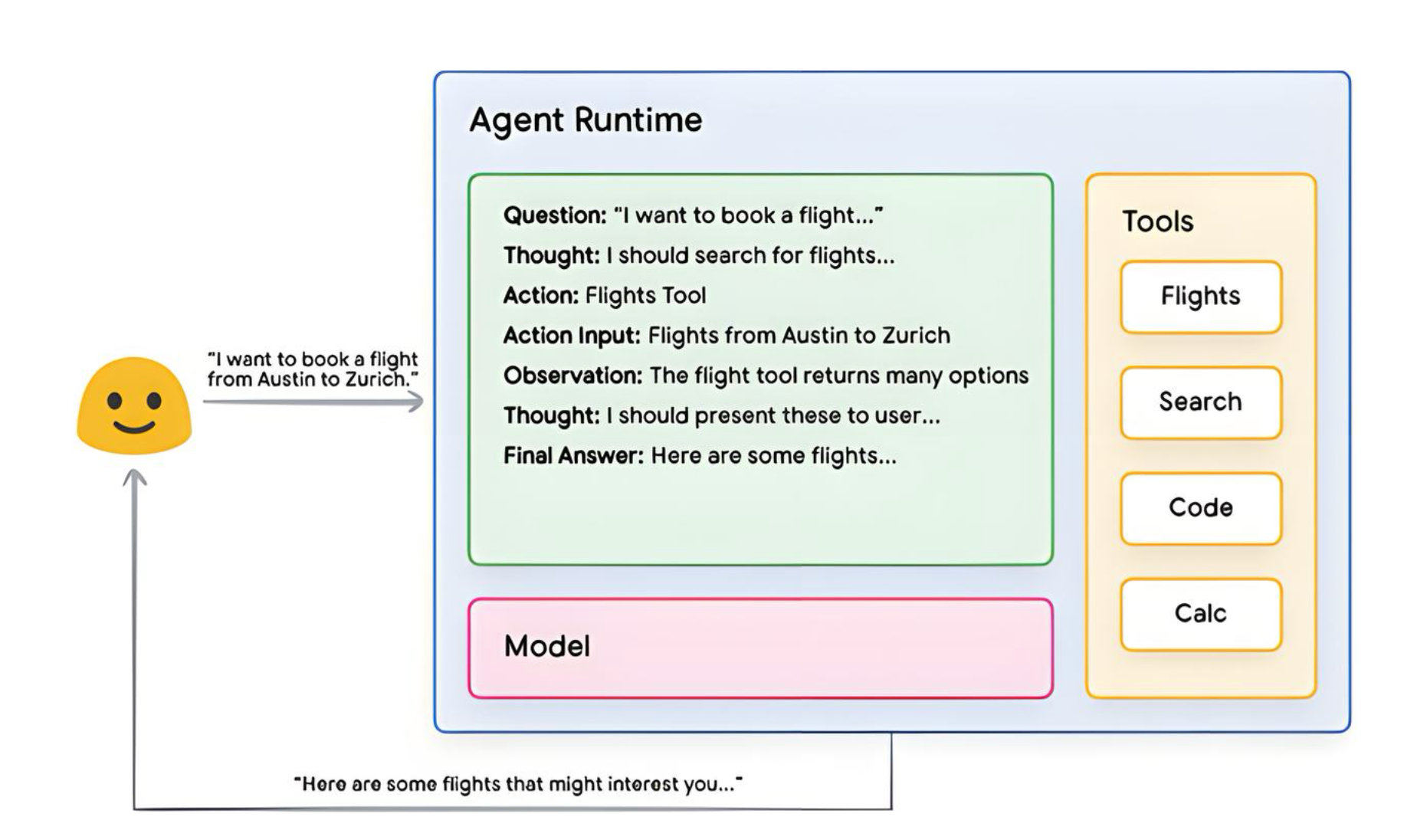
- ユーザー: エージェントに質問をする。
- エージェント: ReActシーケンスを開始 – モデルにプロンプトを提供し、以下のReActのステップを実行。
- 質問(Question): ユーザーの入力クエリを含むプロンプト。
- 思考(Thought): 次に何をすべきかを考える。
- 行動(Action): モデルが次に取るべき行動を決定。この段階で、ツール [Flights, Search, Code, None] の選択と、ツールに提供する値が決定される。
- 観察(Observation): 行動の結果を観察。
- 思考 → 行動 → 観察 のプロセスを繰り返し、最終的な回答を生成。
- ReActループが終了し、最終的な回答がユーザーに提供される。
また、Chain-of-Thought(CoT) や Tree-of-Thoughts(ToT) などの推論フレームワークも存在する。
ツール - データストア
上記のReActの例では、APIベースのツール(フライト検索など)が使用されましたが、ここではデータストアをツールとして活用する例を説明します。
AIエージェントの文脈において、データストア(Data Store)は ベクターデータベース の形で実装されます。ベクターデータベースは、データを高次元のベクター(埋め込み / embedding)として保存します。
ベクター形式のデータストアを活用する代表的な例として、RAG(Retrieval-Augmented Generation, 検索拡張生成) ベースのアプリケーションがあります。
RAGベースのアプリケーションがアクセスできるデータ形式には、以下のようなものがあります。
- ウェブサイト(ブログなど)
- CSV/Excel などの構造化データ
- Wordドキュメント などの非構造化ドキュメント

ユーザーの質問に対してエージェントが回答する処理の流れは以下のとおりです。
- ユーザーの質問(Query)からクエリ埋め込み(ベクトル)を生成
- クエリ埋め込みを用いて、ベクターデータベース内の類似コンテンツを検索
- 抽出された類似コンテンツをエージェントに提供
- エージェントが回答を生成
- 最終的な回答をユーザーに提供
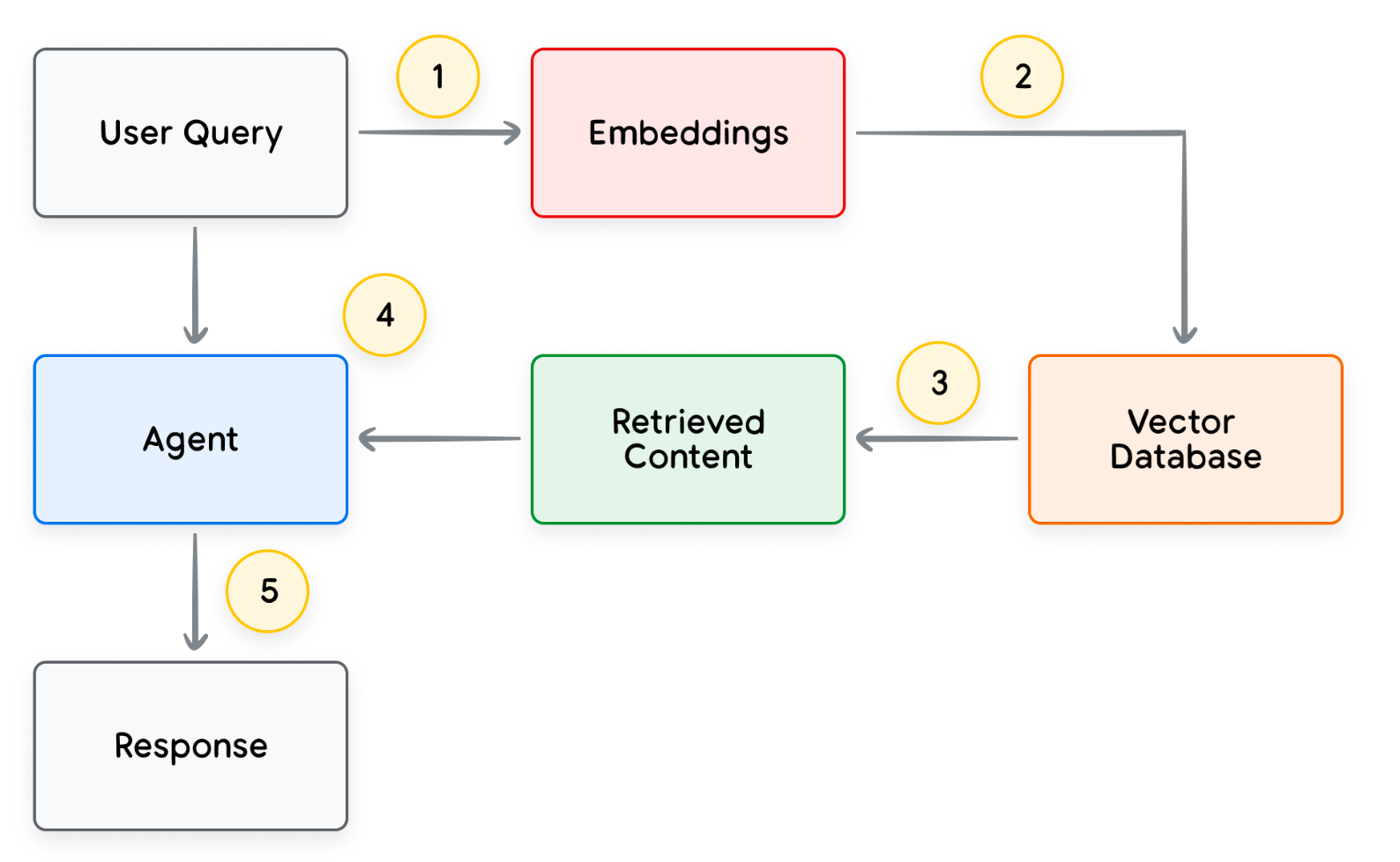
以下の図は、RAGベースの社内文書検索システムの例です。
参考)効果的なエージェントの作り方 by Anthropic
Anthropicの社員が執筆した「効果的なエージェントの作り方」についても簡単に見てみましょう。主要な内容を以下に抜粋しました。
LLMを活用して複雑な業務を自動化するアプリを作る際、一貫性があり正確な結果 を期待するのであれば、現時点では あらかじめ定義された手順を直線的に実行するワークフロー方式 が最適です。
RAG方式で インコンテキストの例を適切に提供すること が、正確な回答を生成するための最良の方法です。
より複雑な処理が求められる場合、ワークフローは予測可能性と一貫性を提供 するため、明確に定義されたタスクには適しています。一方で、大規模な運用において 柔軟性やモデル主導の意思決定 が必要な場合は、エージェントの方が適した選択肢となります。
しかし、多くのアプリケーションでは、RAG(検索拡張生成)やインコンテキスト例を活用した単一のLLM呼び出しを最適化するだけで十分な場合が多い です。
私たちは エージェントシステム(AIエージェント) を、その構造に基づいて以下の2つのカテゴリに分類しています。
- ワークフロー(Workflows) は、LLMとツールが あらかじめ定義されたコードの流れ に沿ってオーケストレーションされるシステムです。
- 一方、エージェント(Agents) は、LLMが 自らのプロセスやツールの使用方法を動的に決定し、タスクの遂行方法を制御 するシステムです。
上記の内容を図式化すると、以下のようになります。
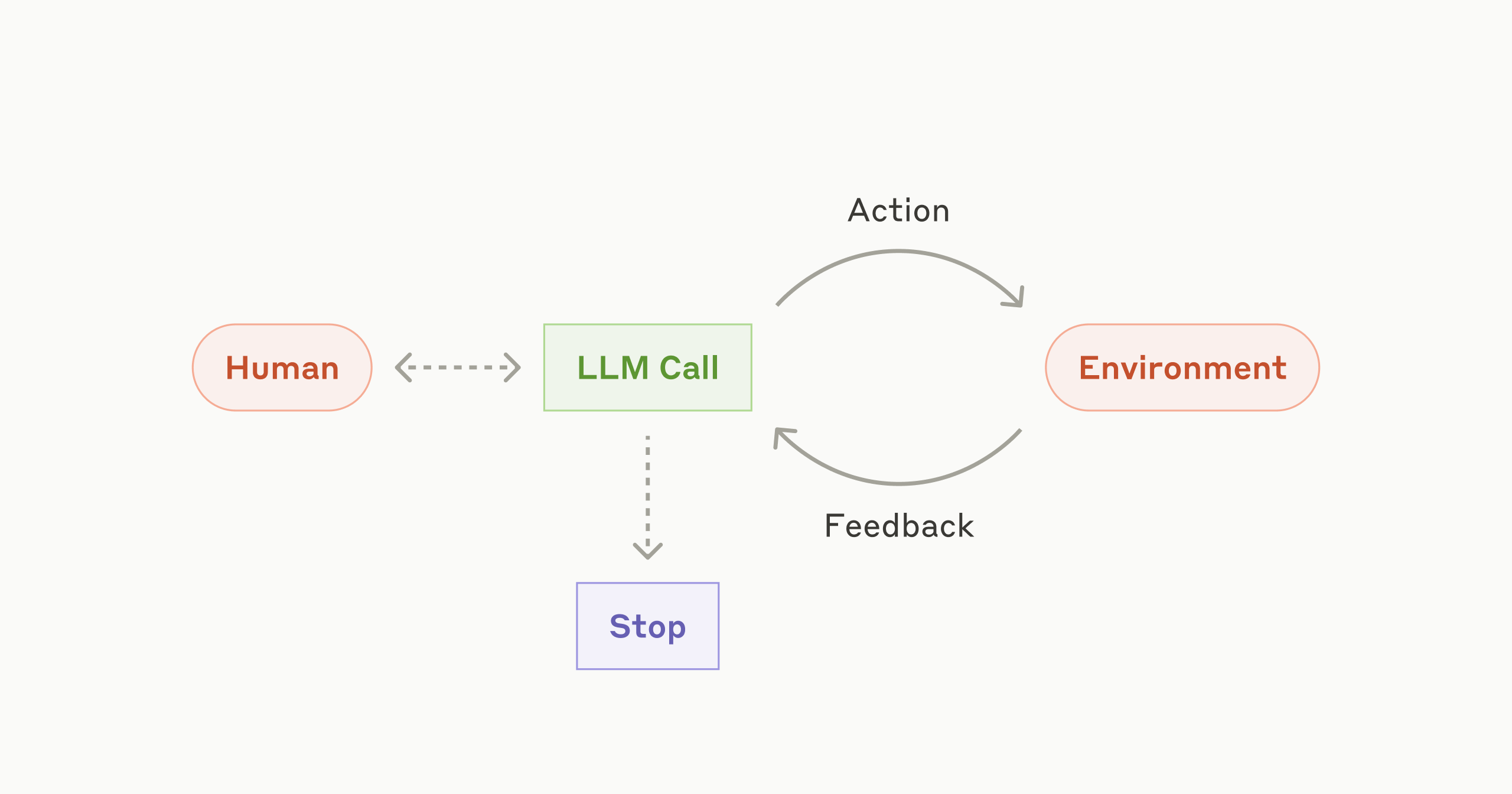
・これは、AIエージェントのビルディングブロック(構成要素)の図です:
- ビルディングブロック(LLMコール) を利用して設計された ワークフローの図 です。この構造では、前のステップのLLMコールの結果が、次のステップのLLMコールに 順次渡される仕組み になっています。また、プロセスが正常に進行しているかを確認する ゲート(Gate) のステップを途中に追加することも可能です。
Chain Workflowのコード例 - データ抽出後にフォーマットを行う処理
# Example 1: Chain workflow for structured data extraction and formatting
# Each step progressively transforms raw text into a formatted table
data_processing_steps = [
"""Extract only the numerical values and their associated metrics from the text.
Format each as 'value: metric' on a new line.
Example format:
92: customer satisfaction
45%: revenue growth""",
"""Convert all numerical values to percentages where possible.
If not a percentage or points, convert to decimal (e.g., 92 points -> 92%).
Keep one number per line.
Example format:
92%: customer satisfaction
45%: revenue growth""",
"""Sort all lines in descending order by numerical value.
Keep the format 'value: metric' on each line.
Example:
92%: customer satisfaction
87%: employee satisfaction""",
"""Format the sorted data as a markdown table with columns:
| Metric | Value |
|:--|--:|
| Customer Satisfaction | 92% |"""
]
report = """
Q3 Performance Summary:
Our customer satisfaction score rose to 92 points this quarter.
Revenue grew by 45% compared to last year.
Market share is now at 23% in our primary market.
Customer churn decreased to 5% from 8%.
New user acquisition cost is $43 per user.
Product adoption rate increased to 78%.
Employee satisfaction is at 87 points.
Operating margin improved to 34%.
"""
print("\nInput text:")
print(report)
formatted_result = chain(report, data_processing_steps)
print(formatted_result)
------------------------------------------------------------------------
Input text:
Q3 Performance Summary:
Our customer satisfaction score rose to 92 points this quarter.
Revenue grew by 45% compared to last year.
Market share is now at 23% in our primary market.
Customer churn decreased to 5% from 8%.
New user acquisition cost is $43 per user.
Product adoption rate increased to 78%.
Employee satisfaction is at 87 points.
Operating margin improved to 34%.
Step 1:
92: customer satisfaction points
45%: revenue growth
23%: market share
5%: customer churn
8%: previous customer churn
$43: user acquisition cost
78%: product adoption rate
87: employee satisfaction points
34%: operating margin
Step 2:
92%: customer satisfaction
45%: revenue growth
23%: market share
5%: customer churn
8%: previous customer churn
43.00: user acquisition cost
78%: product adoption rate
87%: employee satisfaction
34%: operating margin
Step 3:
Here are the lines sorted in descending order by numerical value:
92%: customer satisfaction
87%: employee satisfaction
78%: product adoption rate
45%: revenue growth
43.00: user acquisition cost
34%: operating margin
23%: market share
8%: previous customer churn
5%: customer churn
Step 4:
| Metric | Value |
|:--|--:|
| Customer Satisfaction | 92% |
| Employee Satisfaction | 87% |
| Product Adoption Rate | 78% |
| Revenue Growth | 45% |
| User Acquisition Cost | 43.00 |
| Operating Margin | 34% |
| Market Share | 23% |
| Previous Customer Churn | 8% |
| Customer Churn | 5% |
| Metric | Value |
|:--|--:|
| Customer Satisfaction | 92% |
| Employee Satisfaction | 87% |
| Product Adoption Rate | 78% |
| Revenue Growth | 45% |
| User Acquisition Cost | 43.00 |
| Operating Margin | 34% |
| Market Share | 23% |
| Previous Customer Churn | 8% |
| Customer Churn | 5% |
- 以下のモデルは オーケストレーター(Orchestrator)モデル の図です。中央のLLMが 複雑な作業を細分化し、各サブタスクをワーカー(Worker)LLMに割り当て た後、それぞれの作業結果を統合して最終的な結果を生成する構造になっています。
オーケストレーター構造でAIエージェントを実装したコード例を見たい方は、こちらを参考にしてください。
AIエージェントに対して依然として否定的な立場であり、自分と似た考えを持つ人の意見を読みたい方は、こちらを参考にしてください。
ツール使用に関するプロンプトエンジニアリングの注意点について言及した内容を引用し、本セクションを締めくくります。
モデルの視点に立って考えてみましょう。
このツールの説明やパラメータを見て、直感的に使い方が分かるでしょうか? それとも慎重に考える必要がありますか?もしそうなら、おそらくモデルにとっても同じことが言えます。良いツールの定義には、以下の要素が含まれていることが多いです。使用例(Example Usage)、境界ケース(Edge Cases)、入力フォーマットの要件(Input Format Requirements)他のツールとの明確な違い(Clear Boundaries from Other Tools)
ツールではなく、成果を売れ
サービスとしてのソフトウェア - AIデジタルワーカー
現在、AIエージェント分野で(現時点では)成功を収めながら成長している代表的な米国のスタートアップ企業です。
- 業務自動化プラットフォーム「Glean」 は、設立から4年も経たずに 年間売上4,000万ドル を達成。
- AI弁護士「Harvey」 は、3年で 年間売上5,000万ドル を記録。
- AIコーディングツール「Cursor」 は、月間売上が6カ月で35万ドルから400万ドルへ増加。
- デジタルワーカーを開発するスタートアップ「11x」 は、2023年末にサービスをリリース(以下の図)し、2024年には 年間売上(ARR)1,000万ドル を達成。

しかし、強力な営業基盤を持つ SalesforceのAgentforce と比較すると、これらのスタートアップが今後も継続的に差別化を図れるかは疑問です。

メールを自動送信するエージェントは、果たして将来も有用だろうか?
メールマーケティングキャンペーンの主な目的は、人々が実際にメールを開封し、内容を読み、リンクをクリックするよう促すこと です。しかし、もしエージェントが メールを代わりに確認し、主要な内容を要約し、簡単な返信まで自動で処理してくれる としたらどうなるでしょうか?パーソナライズドマーケティングエージェントの存在意義が問われるポイント です。

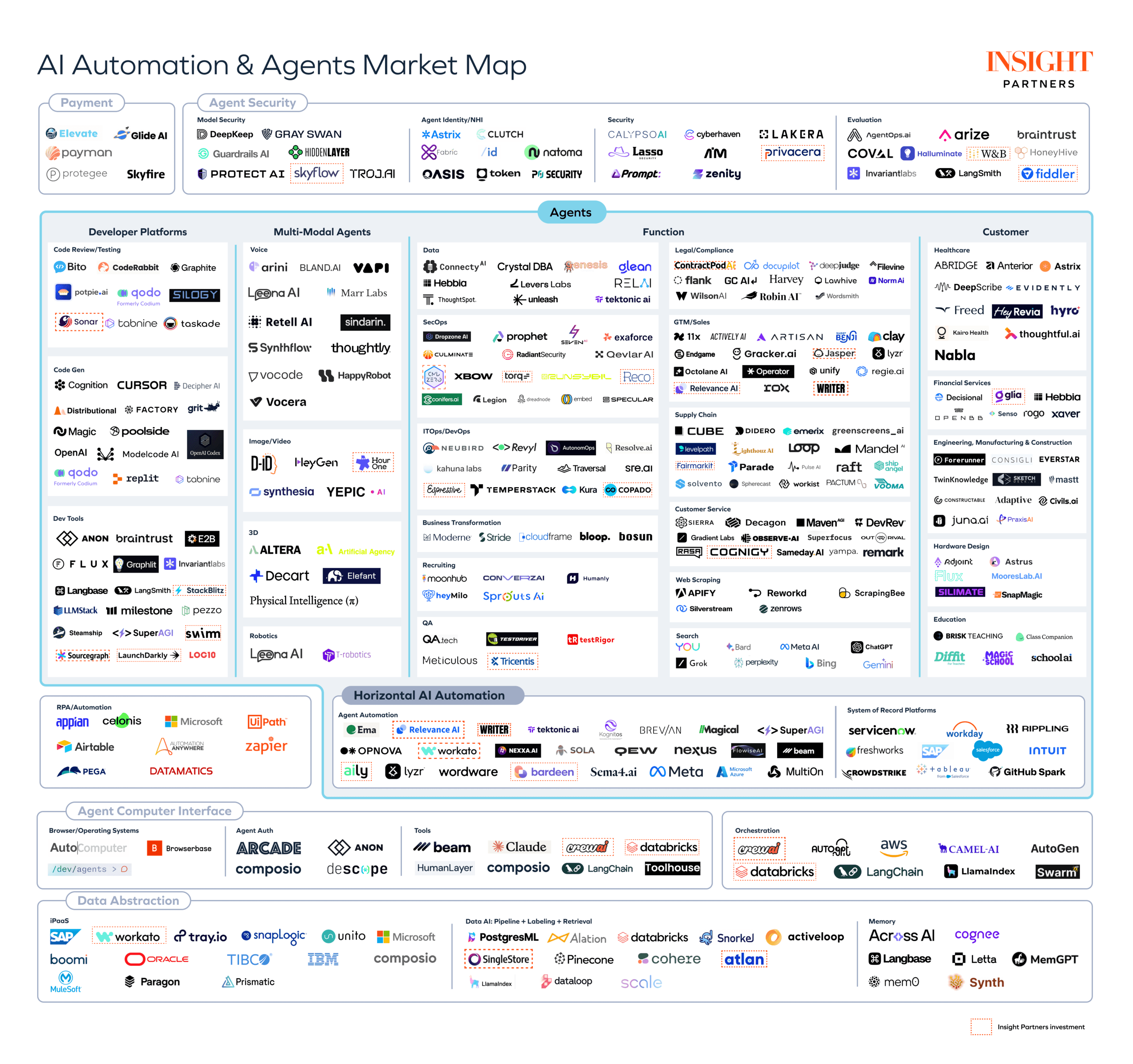
参考) AI Agent Market Map

HEARTCOUNT 分析型AIエージェント
「実務担当者にとってのデータ分析とは、指標に関するその時々の質問(アドホックな質問)に対して、構造化データを使って迅速かつ正確に回答すること」であり、「HEARTCOUNTが実務担当者のこの業務を支援する便利なツール」だと初めて話したのが、もう3年前のことになります。
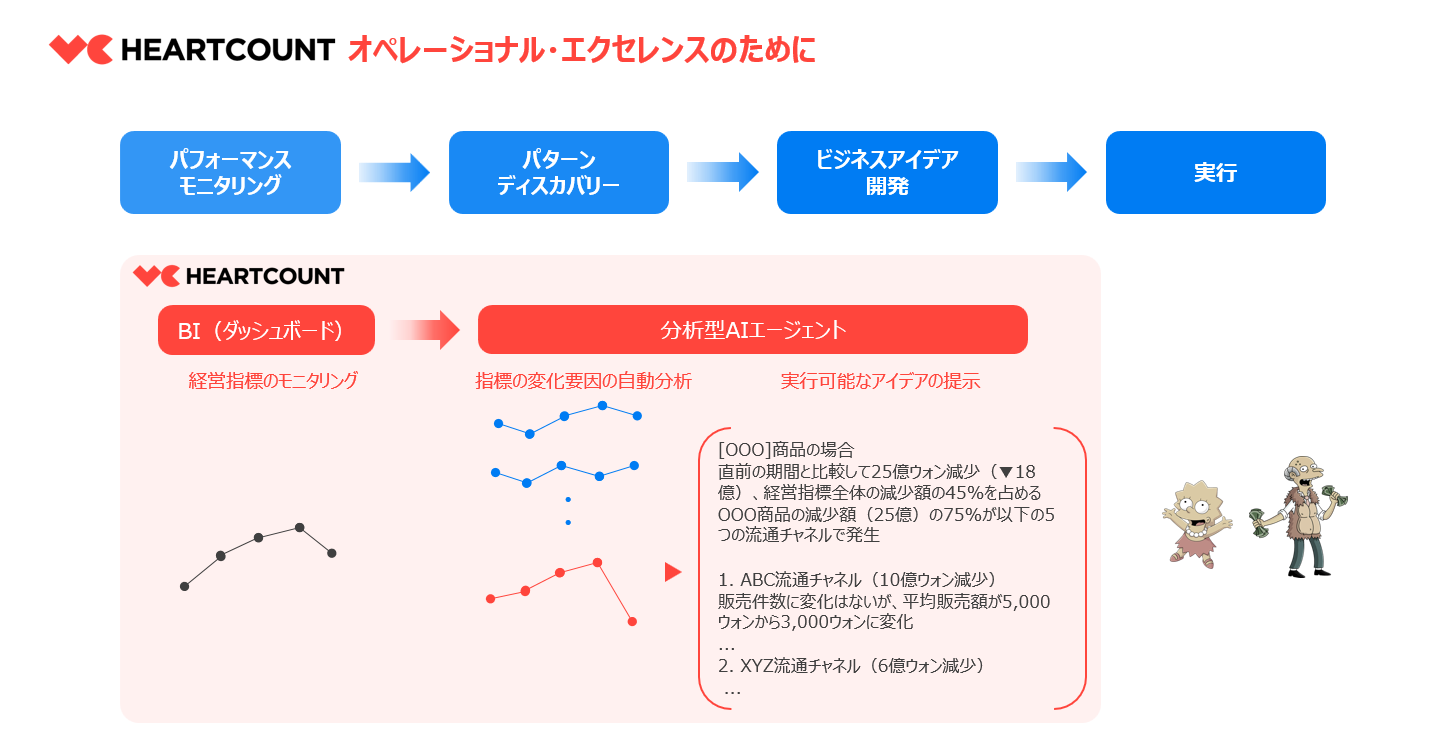
最近になって考えるのは、私たちの前に提示される「回答」が、その質問に対して構造化データが提供できる最善の回答であり、その事実を信頼できるなら、「回答」が生成されるプロセスは知らなくてもよく、むしろ知りたくもないことなのではないか ということです。
データ分析が すべての実務担当者が習得すべきスキル(データリテラシー)ではなく、AIが代替できる退屈な機械的プロセスに過ぎないのかもしれない と思うこともあります。
実務担当者を支援する(Augmentation)データツール と 実務担当者の仕事を代替する(Automation)データツール の境界は、現時点ではまだ曖昧です。しかし、テクノロジーと産業の発展は 私たちの生産性ではなく、企業の生産性を向上させる方向 に進むでしょう。そして、実務担当者が従来の方法でデータを分析し、レポートを作成する仕事は、いずれ消えていく はずです。
ただし、「回答」が生成されるプロセスに無関心なまま、その結果だけを消費するようになったとき、私たちが支払うことになる代償が何なのかは、まだよく分かりません。それでも、私たちはどうにか適応していくのでしょう。
データ分析の質問に自動で回答するAIツールを、最近流行しているAIエージェントに「Analytical」の要素を加え、「Analytical AI Agent」 と呼んでみることにします。
AIエージェントに白紙委任状(Carte Blanche)のような全権を託すには、まだ時間が必要 でしょう。しかし、唯一の正解がない複雑で困難な質問(Hard Question)を、サブクエスチョンに分解(Planning/Reasoning)し、外部ツール(SQL、分析アルゴリズムなど)を活用して回答を生成するAIエージェントは、すでに実現可能な技術となっています。
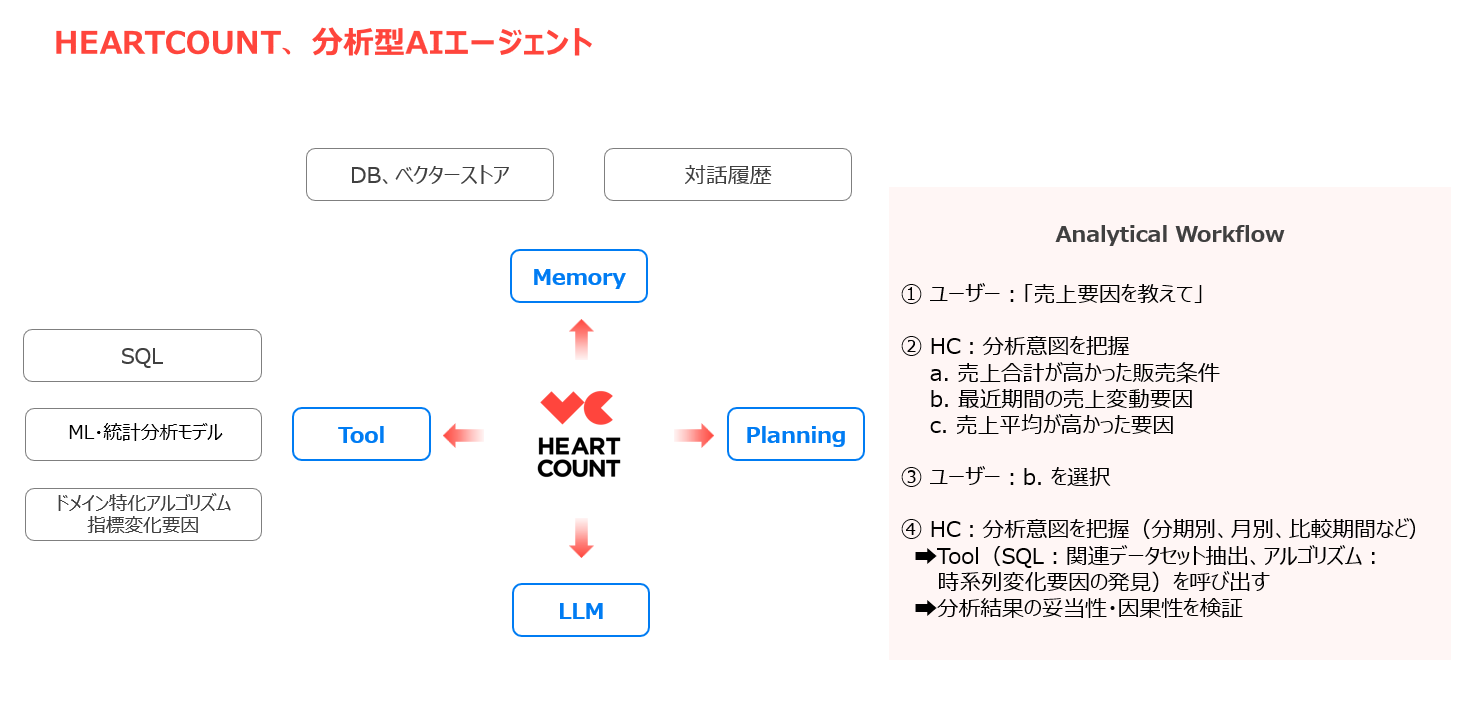
HEARTCOUNTには、すでに以下のような Analytical AI Agent の機能が実装されています。
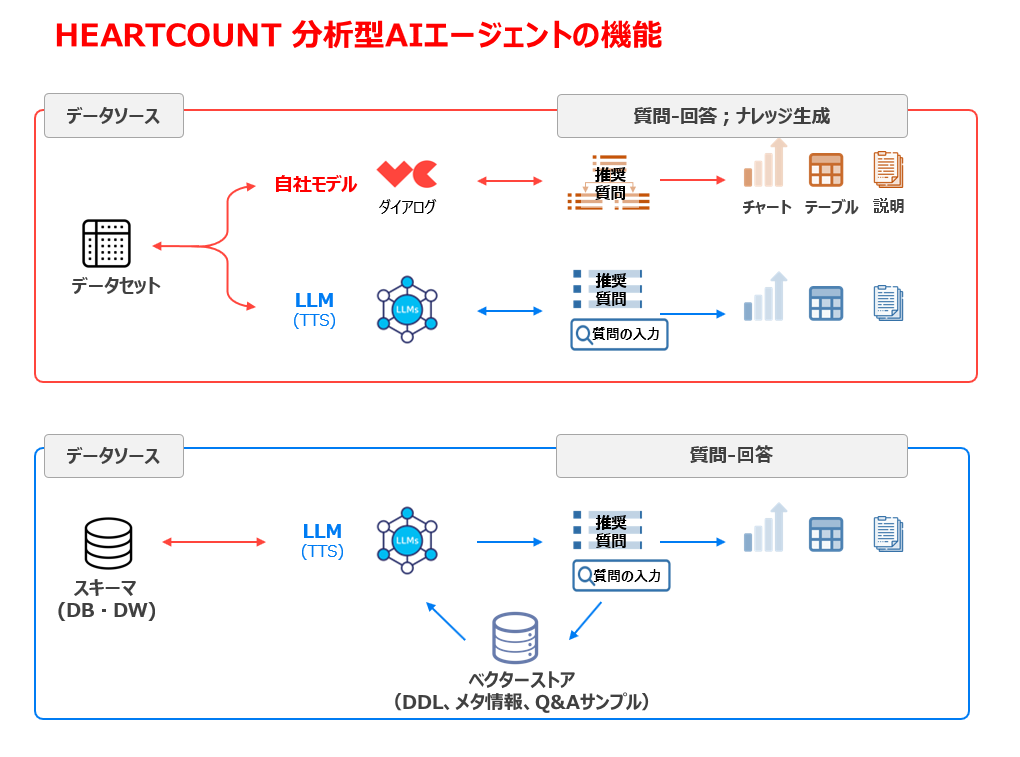
データセット(Excel、CSV)を連携する場合
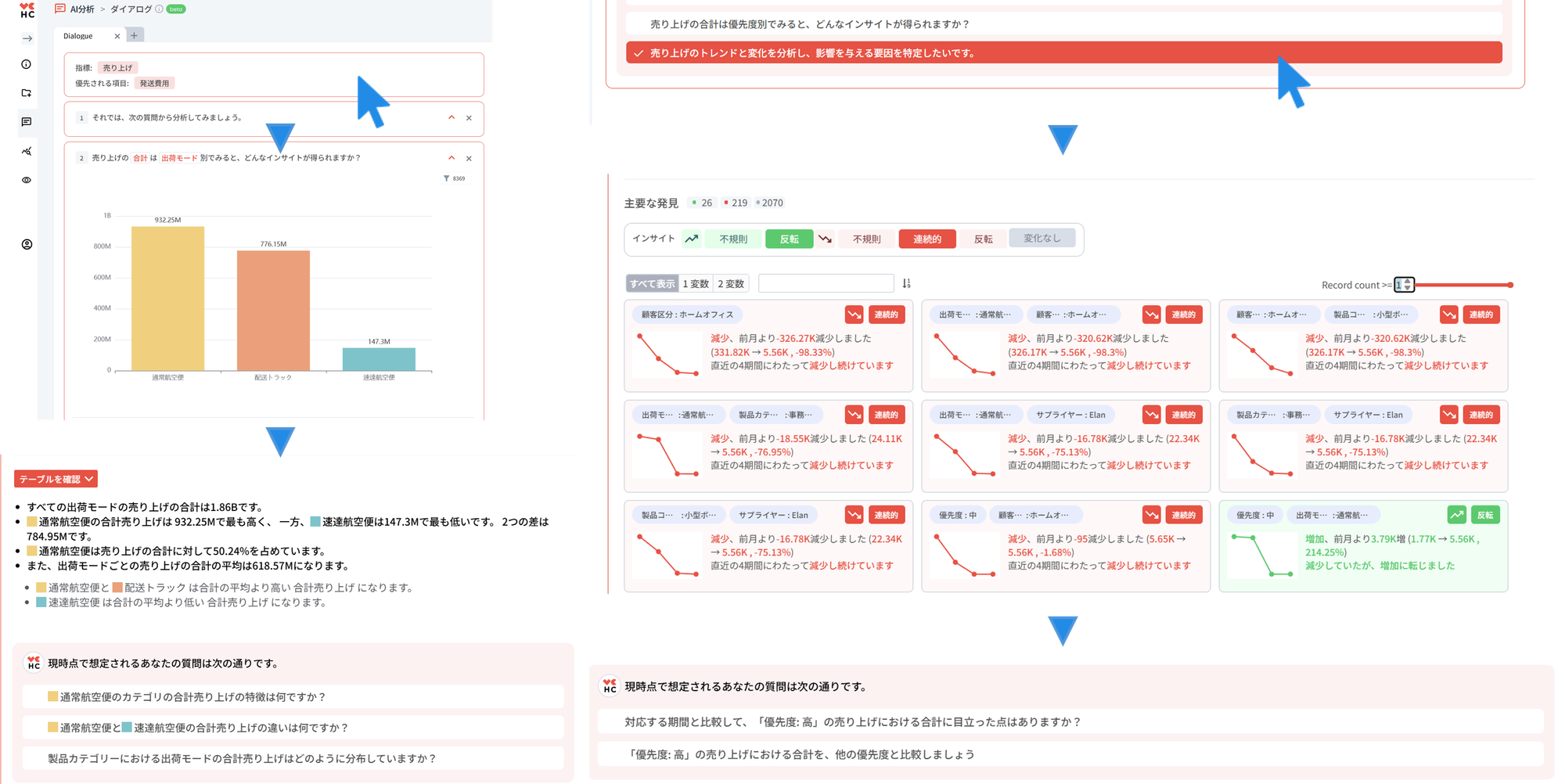
- Data Q&A:
- 簡単な集計系の質問(記述的分析 / Descriptive Analytics)に対する回答を自動化。
- 開放型の質問を理解し、文脈に適した質問を提案するために、LLMとTTS(Text-to-SQL)技術 を使用。
- Dialogue:
- 「なぜ」「どのように」など、唯一の正解がない Hard Question に回答するための機能。
- 分析意図を把握し、分析目的に適した最適なパターンを提供するために、ML(機械学習)や独自の統計分析アルゴリズム を活用。
データウェアハウス(DB)と連携する場合(ABI顧客向け)
- RAG-based TTS:
- 複雑なスキーマに対する開放型の質問に対応できるSQL生成の精度向上 のため、RAG技術 を活用。
- Data Q&A for Schema:
- RAGベースのTTSエンジン を活用し、特定のスキーマ(関連するDBテーブルの集合)に関する開放型質問に対し、チャート・結果テーブル・説明 を提供する機能。
- 2025年3月に正式リリースしました。
今すぐ始めてみましょう!関連するお問い合わせがございましたら、support@heartcount.co.jp までご連絡ください。
【その他の参考資料】


